









RabbitMQ
①Rabbitmq的启动和关闭
rabbitmq-server前台启动服务 rabbitmq-server-detached后台启动服务(常用) rabbitmqctl stop停止服务 端口号是5672 可视化端口15672
Linux中查看正在运行的端口号:netstat -tulpn
②终止与启动应用
Rabbitmqctl start_app启动引用 对消息队列的暂停的恢复
Rabbitmqctl stop_app 终止应用 只是对消息队列进行一个暂停
这两个命令都不会对MQ进程产生影响,只是短暂的对消息队列的操作。
③用户管理

Rabbitmqctl add_user zhongbing 123456
RabbitMQ中有四种用户角色:超级管理员(可查看所有信息,可登录远程访问控制)、监控者(管理rabbitmq节点运行状态的,可登录远程访问控制)、策略制定者(规定节点如何运行的)、普通管理者(仅限登陆管理控制台,无法看到节点信息)
RabbitMQ可以有个可视化控制台,安装好后就可以使用,就像Navicat。
对于角色来说,是对MQ基础组建进行管理,而用户能访问哪些虚拟主机呢,就是根据rabbitmqctl set_permissions –p / user_admin ‘.’’.’’.’,.表示可以进行所有权限,这里是user_admin这个用户可以对默认的/这个虚拟主机进行可读、可配置、可写的操作。虚拟主机就是对应的mysql的数据库,通过虚拟主机可以区别开是什么系统的MQ。
Rabbitmqctl set_permission –p / zhongbing ‘.’’.’’.*’ .
Rabbitmqctl默认的用户名是guest,权限特别大,不能远程访问。如果想要远程操作,就必须创建一个超级管理员才可以用这个超级管理员进行登陆。要进行远程访问,还需要防火墙放行哈。
④AMQP是一个消息队列传递的协议,也就是所有的MQ在实现信息之间传递的时候底层遵从的共同的标准就是AMQP。我们的那些MQ其实都是AMQP的实现者。

虚拟主机:相当于MQ的数据库,例如我有十个消息队列MQ,其中五个服务于这个系统,另外五个服务于这一个系统,那就要建立 2个虚拟主机,存放这两种消息队列。
在使用MQ的时候,要先创建一个虚拟主机,在可视化控制界面建立好Vhost就可以了。例如/test,之后我们把创建的消息队列就放入这个虚拟主机就可以了。
⑤第一次MQ通信
创建好Vhost之后,创建一个maven项目,maven是项目对象模型,类似于docker,可以通过pom.xml配置信息来从仓库中获取以来的文件(jar包),这个仓库就是网上的,也可以是第三方仓库(私人公司的)。然后从官网上找到rabbitmq的客户端配置包信息引入。
创建一个生产者:
第一步:通过配置连接工厂(是哪一台主机进行消息生产)来创建TCP物理连接,得到一个connection对象。

执行到这里后,本地客户端的java程序就和服务器端MQ建立了物理的TCP连接。
第二步:创建通信通道,相当于TCP的虚拟连接。之所以有这一步,是因为物理连接的开启成本开销很大,当有多个任务同时进行的时候就非常慢。所以这里就有了通道的概念,相当于在当前物理连接中开辟多个虚拟的通信管道,通过通道进行传输。
Channel channel = conn.createChannel();
channel.queueDeclare(“helloworld”, false, false, false, null);
创建队列,声明并创建一个队列,如果队列已存在,则使用这个队列
//第一个参数:队列名称ID
//第二个参数:是否持久化,false对应不持久化数据,MQ停掉数据就会丢失
//第三个参数:是否队列私有化,false则代表所有消费者都可以访问,true代表只有第一次拥有它的消费者才能一直使用,其他消费者不让访问
//第四个:是否自动删除,false代表连接停掉后不自动删除掉这个队列
//其他额外的参数, null
第三步:发送数据 BasecPublish是进行数据的发送,他也有四个参数。
String message = “nihaoa”; //要发送的消息
channel.basicPublish("" ,” helloworld” ,null , message.getBytes());
//四个参数
//exchange 交换机,暂时用不到,在后面进行发布订阅时才会用到
//队列名称 必须和上面一样
//额外的设置属性
//最后一个参数是要传递的消息字节数组
创建一个消费者:
第一步:创建链接工厂获得连接,进行TCP物理连接。

第二步:创建通道进行虚拟TCP连接。

第三步:创建一个消息消费者,并签收。
channel.basicConsume(“helloworld”, false, new Reciver(channel));
//第一个参数是消费的是MQ中的哪个通道。
//第二个参数代表是否自动确认收到消息,false代表手动编程来确认消息,这是MQ的推荐做法。
//第三个参数要传入DefaultConsumer的实现类,这里就要创建一个Reciver实现类来对消息进行处理。创建这个Reciver实现类要集成DefaultConsumer,即默认的消费者,他有两个要求:
1.重写传入通道channel的构造方法。
2.重写handleDelivery方法表示消息处理。
class Reciver extends DefaultConsumer{
private Channel channel;
//重写构造函数,Channel通道对象需要从外层传入,在handleDelivery中要用到
public Reciver(Channel channel) {
super(channel);
this.channel = channel;
}
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String messageBody = new String(body); //传入的Body就是从通道中收到的字节数组
System.out.println("消费者接收到:" + messageBody);
//签收消息,确认消息
//envelope.getDeliveryTag() 获取这个消息的TagId,也就是这个通道的ID
//false只确认签收当前的消息,设置为true的时候则代表签收该消费者所有未签收的消息
channel.basicAck(envelope.getDeliveryTag() , false);
}
}
在消费者这端我们不要close通道,因为消费者会一直循环监听消费。
⑥消息的三种状态
Ready:消息已被送入队列,等待被消费
Unacked:消息已经被消费者认领,但是还未被确认已被消费。
Finished:调用basicAck()方法后,表示消息已被消费,从队列中移除。
⑦RabbitMQ六种工作模式
- Hello world
也就是点对点模式,一个生产者对应一个消费者,生产一个消费一个。

- 工作队列
一个生产者生产消息放入工作队列,由多个消费者进行处理。期间可能会按照权重、工作时间等把消息给不同的消费者消费。一般适合于集群。
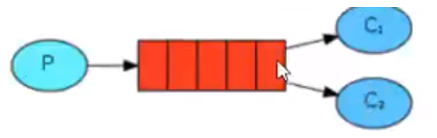
- 发布订阅模式
中间有有一个交换器,他的作用是将我们的数据按照一定的规则分发给多个消费者,他和工作队列的区别是他会把数据产生多个副本发给不同的消费者。例如下面:c1和c2是完全相同的数据。适合于视频网站,当一个发布者发布消息后,所有的消费者接受到的都是相同的消息进行消费。
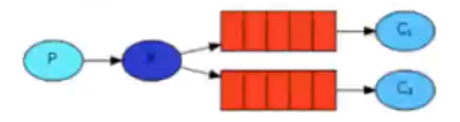
- 路由器模式
和发布订阅模式相比,消费者不再是收到相同的数据,而是数据通过交换机有选择的把数据消息分给不同的消费者。他有个缺点,就是需要对数据进行精准匹配,面对一些模糊查询就没辙了。

- 主题模式
解决了路由器模式的缺点,定义一个表达式规则,让消息根据表达式规则发送给不同的消费者。

- RPC模式
远程过程调用。不是MQ主要负责的东西。
⑧工作队列模式
一个生产者,把信息放到队列里后,被多个消费者消费,每一个消息只能分配给一个消费者。他可以根据消费者处理数据的能力把消息数量适量的分配给不同消费者。

传统的你下单买好火车票后,发送成功的短信是同步的,12306发送购买成功的短信后他会一直等消息返回,期间什么都做不了,造成浪费。对于12306一个短信服务肯定不够,肯定有多个短信服务,例如账号注册、购买成功,而且这些短信其实并不是主要业务,这个短信是否发送成功对业务没有起重要作用(没有发送短信,但是我票还是取到了得不影响乘车),所以针对这些情况,就把要发送的短信包放入RabbitMQ,让服务器从RabbitMQ异步拿消息,12306系统只需要把数据放入MQ就可以执行其他程序操作了。
生产者:发送200个对象给MQ,把对象转成json字符串发送给MQ。
public class OrderSystem {
public static void main(String[] args) throws IOException, TimeoutException {
Connection connection = RabbitUtils.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(RabbitConstant.QUEUE_SMS, false, false, false, null);
for(int i = 100 ; i <= 200 ; i++) {
SMS sms = new SMS("乘客" + i, "13900000" + i, "您的车票已预订成功");
String jsonSMS = new Gson().toJson(sms);
channel.basicPublish("" , RabbitConstant.QUEUE_SMS , null , jsonSMS.getBytes());
}
System.out.println("发送数据成功");
channel.close();
connection.close();
}
}
对象转字符串和字符串转对象,就要用到谷歌的gson这个工具包。我们把生产者生产的对象通过gson转成json格式的字符串发布出去。
消费者(3个,这里就写一个):以前我们是实现一个继承了DefaultConsumer类的类作为参数传入,现在我们直接用DefaultConsumer当内部类来使用。
public class SMSSender1 {
public static void main(String[] args) throws IOException {
Connection connection = RabbitUtils.getConnection();
final Channel channel = connection.createChannel();
channel.queueDeclare(RabbitConstant.QUEUE_SMS, false, false, false, null);
channel.basicQos(1);//处理完一个取一个
channel.basicConsume(RabbitConstant.QUEUE_SMS , false , new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
String jsonSMS = new String(body);
System.out.println("SMSSender1-短信发送成功:" + jsonSMS);
Thread.sleep(10); //本来有try\catch 用这个模拟不同消费者的快慢
channel.basicAck(envelope.getDeliveryTag() , false);
}
});
}
}
如果不写basicQos,则自动MQ会将所有请求平均发送给所有消费者,我们消费者也会有处理速度快慢的说法,为了不让处理快的消费者一直等待,就要加这个。basicQos,MQ不再对消费者一次发送多个请求,而是消费者处理完一个消息后(确认后),在从队列中获取一个新的,如果是basicQos(10)则就是处理完10个再从消息队列里面拿。
⑨发布订阅模式
就像B站订阅,当up主发布一个视频后,所有订阅的人看到的消息都是一样的,都能看到这个视频。在发布订阅模式中新增加一个交换机,让生产者不再和队列绑定,交换机的作用就是将数据按照某种规矩送入与之绑定的队列,在 发布订阅模式中交换机的作用就是把数据进行复制无差别的发送到所有的消息队列中。
该模式适合于数据提供商与应用商。常用的就是中国气象局提供的天气预报送入交换机,网易、新浪、百度、搜狐等门户就可以通过队列绑定到交换机,自动获取气象局推送的气象数据。
第一步:在RabbitMQ的可视化管理控制中新建一个Exchanges。选定交换机绑定的虚拟主机,设置名字weather,类型为fanout(针对于发布订阅的)等等,包括持久化选项等等。
第二步:创建生产者。这里有个区别了,就是在发布订阅模式中,我们basicPublish方法第一个参数之前是空,那是因为没有交换机,现在有交换机了这里就要写交换机的名字。其次第二个参数本来是队列的名称,因为这里我们生产者不是直接和队列进行交互,是和交换机进行交互的,所以这里为空即可。
public class WeatherBureau {
public static void main(String[] args) throws IOException, TimeoutException {
Connection connection = RabbitUtils.getConnection();
String input = new Scanner(System.in).next(); //手动输入天气情况
Channel channel = connection.createChannel();
channel.basicPublish(RabbitConstant.EXCHANGE_WEATHER,"" , null , input.getBytes());
channel.close();
connection.close();
}
}
RabbitConstant.EXCHANGE_WEATHER是之前定义好的常量,即交换机名字weather。所以此时,在生产者这边,就没有创建队列了,直接把生产者和交换机进行绑定。
第三步:创建消费者(百度和新浪,这里只给了百度的例子,新浪是一样的),在消费者中让队列和交换机绑定。
public class Baidu {
public static void main(String[] args) throws IOException {
Connection connection = RabbitUtils.getConnection();
final Channel channel = connection.createChannel();
channel.queueDeclare(RabbitConstant.QUEUE_BAIDU, false, false, false, null);
//queueBind用于将队列与交换机绑定
//参数1:队列名 参数2:交互机名 参数三:路由key(暂时用不到)
channel.queueBind(RabbitConstant.QUEUE_BAIDU,
RabbitConstant.EXCHANGE_WEATHER, "");
channel.basicQos(1);
channel.basicConsume(RabbitConstant.QUEUE_BAIDU , false ,
new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("百度收到气象信息:" + new String(body));
channel.basicAck(envelope.getDeliveryTag() , false);
}
});
}
}
所以发布订阅模式和工作队列的区别如下:1.生产者不再生产队列,也不再和队列进行直接绑定,而是与交换机进行直接绑定。2.数据交给交换机后,交换机会把数据进行复制分发给吓交换机订阅了得队列,也就是每个队列收到的数据都是一样的。3.队列由消费者进行创建,而且由消费者把队列和交换机进行绑定。
而工作队列模式则是生产者创建队列把消息发给队列,生产者拿到队列并从队列里拿消息。
⑩路由模式
是发布订阅模式的变种,发布订阅是无条件的把所有消息发给所有消费者队列,而路由模式则是根据路由key有条件的筛选数据然后发给消费者队列。路由模式下的交换机被叫做direct。
生产者:
这里代码我就写有区别的地方,这里路由模式下,生产者方也不用创建队列,只需要和交换机绑定,但是绑定代码basicPublish有区别:
channel.basicPublish(“weather“,me.getKey() , null , me.getValue().getBytes());
这里的第二个参数不再是null了,而是me.getKey(),其中me是之前定义的一个迭代器,相当于一个map,这里的第二个参数就是数据筛选的条件。
消费者:
区别点在绑定的queueBing里的第三个参数,是路由的key。这里强调一下,就是在生产者这边创建的队列,可以绑定到多个交换机上,同理一个交换机也可以绑定多个队列。
channel.queueBind(RabbitConstant.QUEUE_BAIDU, RabbitConstant.EXCHANGE_WEATHER_ROUTING, "china.shandong.qingdao.20991011");
当然,我们可以在一个消费者中定义多个queueBind,队列和交换机绑定都相同,只是key不同,从而让一个消费者接收不同key的消息。
也就是说,在生产者这边,我们的消息在交换机上都加一个Key,消费者在创建队列的时候让队列和交换机绑定,也必须与与之对应的key相绑定才会受到对应的key的那些数据。
⑪主题Topic模式
因为 路由模式的key必须是精准的,则主题topic模式则是在路由模式的基础上提供了模糊匹配的功能。模糊匹配的规则:
* 匹配单个关键字
#匹配所有关键字
主题模式下交换机的类型为topic。
第一步:还是在可视化控制台中创建topic模式下的交换机。交换机名字设为topic
第二步:生产者。这里只给出区别代码。把生产者和交换机进行绑定。
channel.basicPublish(“topic”,me.getKey() , null , me.getValue().getBytes());
第三步:消费者。进行模糊匹配绑定。
channel.queueBind(RabbitConstant.QUEUE_BAIDU, “topic”, “..*.20991011”);
channel.queueBind(RabbitConstant.QUEUE_SINA, “topic”, “us.#”);
对于解绑,我们可以在可视化控制台中进行解绑,也可以调用queueUnbind()方法。
⑫RabbitMQ消息确认机制
生产者通过消息确认机制得知自己的消息被正确投入到了MQ中。RabbitMQ提供了监听器来接收消息投递的状态,消息确认涉及两种状态:confirm和return。
Confirm:代表生产者将消息送到MQ时产生的状态,后续会出现两种情况(即生产者投递消息给MQ后的结果有两种情况ack和nack)。Ack代表MQ已经将数据接收,nack代表MQ拒绝接收消息,可能是因为队列已满、限流、异常等。
Return:代表消息被MQ正常接收并且ack后,但是MQ没有对应的队列进行投递,消息被退回给生产者。
所以其实消息确认一共会产生三种状况。
Confirm和return两种状态只代表生产者和MQ之间消息投递的情况,与消费者是否接收确认消息无关。
可以在生产者中通过addConfirmListener来实现监听过程:

当然,在消费者这边也需要一个Listener。
⑬RabbitMQ集群架构模式
用RabbitMQ集群架构模式来解决消息队列高可用。RabbitMQ集群包含四种架构模式:(1)主备模式 (2)镜像模式 (3)远程模式 (4)多活模式。
主备模式:实现RabbitMQ的高可用集群,即一主一备,一般用在并发和数据量不高的情况下。即两台MQ服务器,一台在工作,一台在闲置,当一台服务器宕机了另一台服务器接上。他有个缺点就是不均衡,资源浪费严重。
镜像模式:能保证100%数据不丢失,但开销很大,每一个RabbitMQ实例都会拥有一个QUEUE队列,一个RabbitMQ实例对QUEUE队列数据的修改都会同步到所有的RabbitMQ实例的队列中。RabbitMQ实例包括队列和交换机等信息。
远程模式:远程模式就是可以把消息进行不同数据中心的复制工作,跨地域的让两个mq集群互联。北京、上海、成都三个集群同步,任何一个坏了都可以顶上。但是配置很复杂。
多活模式:解决了远程模式的配置复杂,实现异地数据复制的主流模式,依赖插件,可以实现持续的可靠的AMQP数据通信。
⑭搭建镜像集群
(1)准备工作-修改host配置

(2)开放防火墙端口

4369:erlang服务的主机发现端口。
5672:RabbitMQ的端口
15672:可视化控制rabbitMQ的端口
25672:是erlang底层进行消息分配发送的端口
(3)复制erlang.cookie
Erlang.cookie是一种通信证,集群内所有设备要持有相同的erlang.cookie文件才会被允许彼此通信。让所有主机都持有这个通信证文件。
(4)配置镜像集群 在m2服务器上执行命令将与m1服务器进行复制。(也就是把m2加入到m1集群中)
(5)接下来解决镜像模式遇到的问题。现在我们有两台服务器,java客户端发出请求后是交给哪个RabbitMQ服务器去解决呢,就需要用到负载均衡代理服务器haproxy。让客户端不直接与MQ服务器接触,而是通过代理服务器haproxy进行转发。

Haproxy是轮询负载均衡算法,还可以检查哪些MQ服务器出现问题,出现问题就把该节点从集群中剔除出去。Haproxy是四层负载均衡,是基于TCP传输层的。他之所以可以检查出哪些MQ服务器出问题,是因为他每五秒发送一次心跳包,如果连续两次有响应则代表状态良好,如果连续3次没有相应,则视为服务器故障,删除节点。
要使用haproxy负载均衡器,就需要先下载安装。安装好后在haproxy的核心配置文件haproxy.cfg进行编辑配置。包括设置连接的MQ服务器。
CMQ
①CMQ队列消费模式代码
# 从腾讯云官网查看云api的密钥信息
secretId = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
secretKey = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
# 使用地域的消息服务
endpoint = 'xxxxxxxxxxxxxxxxxxxxxxxxxxx'
# Account类对象不是线程安全的,如果多线程使用,需要每个线程单独初始化Account类对象
my_account = Account(endpoint, secretId, secretKey, debug=True)
my_account.set_log_level(logging.DEBUG)
queue_name = "GZ-QualPlat-ThresholdsEvent-Queue"
my_queue = my_account.get_queue(queue_name)
recv_msg = my_queue.receive_message()
print "Receive Message Succeed! MessageBody:%s" % (recv_msg.msgBody)
#register(recv_msg.msgBody) 注册到数据库消费
my_queue.delete_message(recv_msg.receiptHandle)
②CMQ生产模式
代码都千篇一律,无外乎都是先设置CMQ队列的各种属性,包括队列名、消息等待时间、消息最长长度等等,然后创建CMQ队列,然后send_message。
具体的可以参见腾讯云官网API















 877
877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









