










文章目录
一、网络结构
1、总体网络结构
主干网络示意图如下,其实采用的和YoloV3、YoloV4、YoloV5类似的网络结构
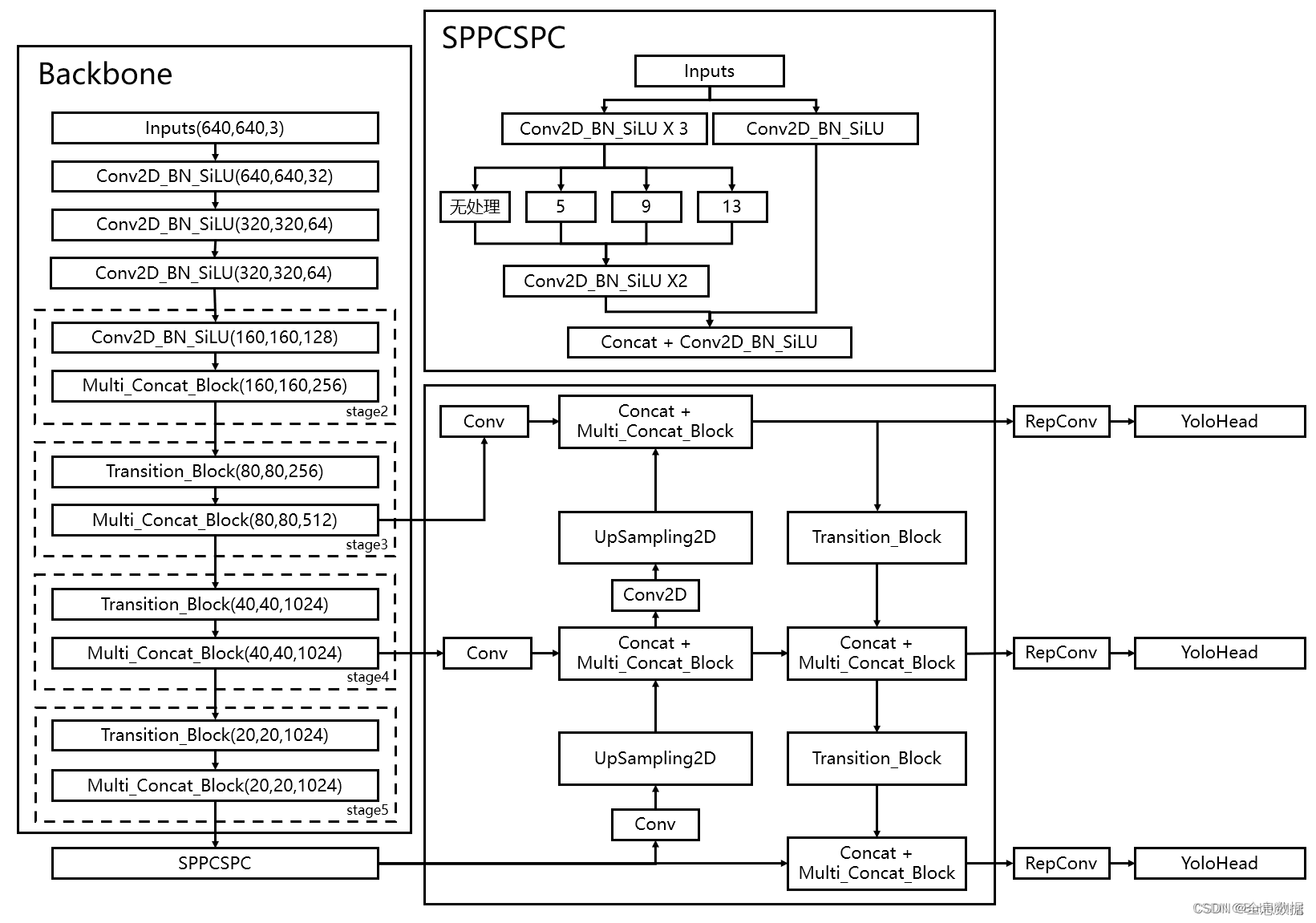
2、主干网络介绍(backbone)
2.1 多分支模块堆叠
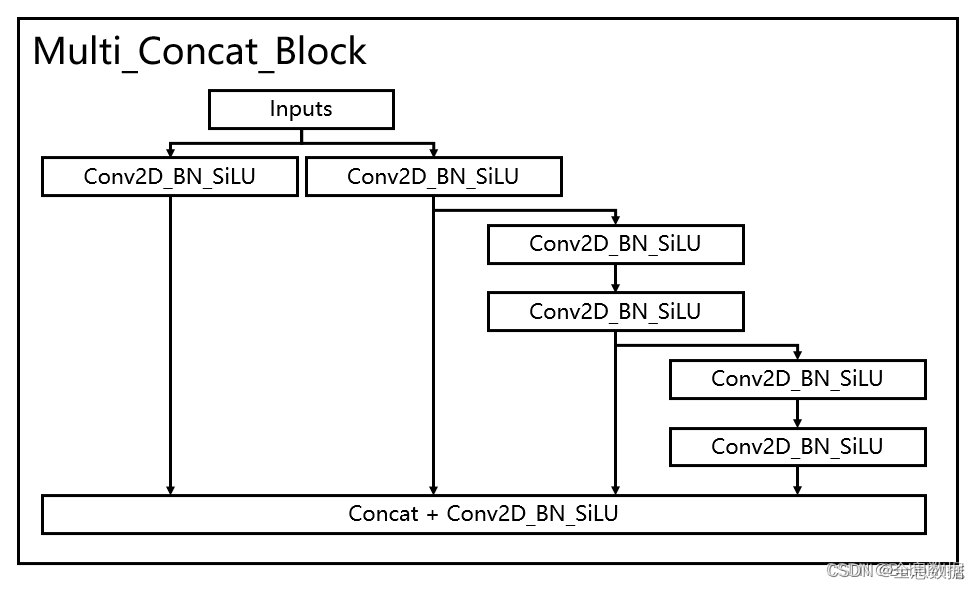
代码如下,多分支模块堆叠的类名为:Multi_Concat_Block
import torch
import torch.nn as nn
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=SiLU()): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)
# 走SiLU
self.act = nn.LeakyReLU(0.1, inplace=True) if act is True else (
act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class Multi_Concat_Block(nn.Module):
def __init__(self, c1, c2, c3, n=4, e=1, ids=[0]):
super(Multi_Concat_Block, self).__init__()
c_ = int(c2 * e)
self.ids = ids
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = nn.ModuleList(
[Conv(c_ if i == 0 else c2, c2, 3, 1) for i in range(n)]
)
self.cv4 = Conv(c_ * 2 + c2 * (len(ids) - 2), c3, 1, 1)
def forward(self, x):
x_1 = self.cv1(x)
x_2 = self.cv2(x)
x_all = [x_1, x_2]
for i in range(len(self.cv3)):
x_2 = self.cv3[i](x_2)
x_all.append(x_2)
out = self.cv4(torch.cat([x_all[id] for id in self.ids], 1)) # 1:在1维拼接, 0:在0维拼接
return out
if __name__ == '__main__':
ids = {
'l': [-1, -3, -5, -6],
'x': [-1, -3, -5, -7, -8],
}['l']
x = torch.randn(2, 3, 5, 5)
print(x.shape)
out = Multi_Concat_Block(3, 3, 5, n=4, ids=ids)(x)
print(out.shape)
输出:
torch.Size([2, 3, 5, 5])
torch.Size([2, 5, 5, 5])
2.2 下采样网络结构
结合了maxpooling和2
×
\times
× 2步长的卷积
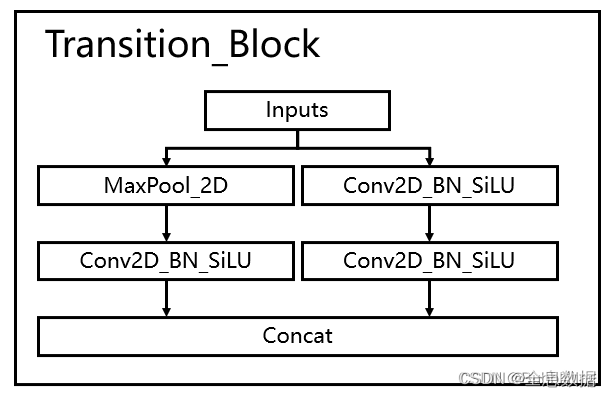
代码如下,下采样结构类名为Transition_Block,
import torch
import torch.nn as nn
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=SiLU()): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)
# 走SiLU
self.act = nn.LeakyReLU(0.1, inplace=True) if act is True else (
act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class MP(nn.Module):
def __init__(self, k=3, t=2):
super(MP, self).__init__()
self.m = nn.MaxPool2d(kernel_size=k, stride=t, padding=1)
def forward(self, x):
return self.m(x)
class Transition_Block(nn.Module):
def __init__(self, c1, c2):
super(Transition_Block, self).__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c1, c2, 1, 1)
self.cv3 = Conv(c2, c2, 3, 2)
self.mp = MP()
def forward(self, x):
x_1 = self.mp(x)
x_1 = self.cv1(x_1)
x_2 = self.cv2(x)
x_2 = self.cv3(x_2)
return torch.cat([x_2, x_1], 1)
if __name__ == '__main__':
x = torch.randn(2, 3, 9, 9)
print(x.shape)
out = Transition_Block(3, 5)(x)
print(out.shape)
输出:
torch.Size([2, 3, 9, 9])
torch.Size([2, 10, 5, 5])
2.3 整个backbone代码
整个主干网络实现代码为:
import torch
import torch.nn as nn
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=SiLU()): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)
# 走SiLU
self.act = nn.LeakyReLU(0.1, inplace=True) if act is True else (
act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class Multi_Concat_Block(nn.Module):
def __init__(self, c1, c2, c3, n=4, e=1, ids=[0]):
super(Multi_Concat_Block, self).__init__()
c_ = int(c2 * e)
self.ids = ids
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = nn.ModuleList(
[Conv(c_ if i == 0 else c2, c2, 3, 1) for i in range(n)]
)
self.cv4 = Conv(c_ * 2 + c2 * (len(ids) - 2), c3, 1, 1)
def forward(self, x):
x_1 = self.cv1(x)
x_2 = self.cv2(x)
x_all = [x_1, x_2]
for i in range(len(self.cv3)):
x_2 = self.cv3[i](x_2)
x_all.append(x_2)
out = self.cv4(torch.cat([x_all[id] for id in self.ids], 1)) # 1:在1维拼接, 0:在0维拼接
return out
class MP(nn.Module):
def __init__(self, k=2):
super(MP, self).__init__()
self.m = nn.MaxPool2d(kernel_size=k, stride=k)
def forward(self, x):
return self.m(x)
class Transition_Block(nn.Module):
def __init__(self, c1, c2):
super(Transition_Block, self).__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c1, c2, 1, 1)
self.cv3 = Conv(c2, c2, 3, 2)
self.mp = MP()
def forward(self, x):
x_1 = self.mp(x)
x_1 = self.cv1(x_1)
x_2 = self.cv2(x)
x_2 = self.cv3(x_2)
return torch.cat([x_2, x_1], 1)
class Backbone(nn.Module):
def __init__(self, transition_channels, block_channels, n, phi, pretrained=False):
super().__init__()
# -----------------------------------------------#
# 输入图片是640, 640, 3
# -----------------------------------------------#
ids = {
'l': [-1, -3, -5, -6],
'x': [-1, -3, -5, -7, -8],
}[phi]
self.stem = nn.Sequential(
Conv(3, transition_channels, 3, 1),
Conv(transition_channels, transition_channels * 2, 3, 2),
Conv(transition_channels * 2, transition_channels * 2, 3, 1),
)
self.dark2 = nn.Sequential(
Conv(transition_channels * 2, transition_channels * 4, 3, 2),
Multi_Concat_Block(transition_channels * 4, block_channels * 2, transition_channels * 8, n=n, ids=ids),
)
self.dark3 = nn.Sequential(
Transition_Block(transition_channels * 8, transition_channels * 4),
Multi_Concat_Block(transition_channels * 8, block_channels * 4, transition_channels * 16, n=n, ids=ids),
)
self.dark4 = nn.Sequential(
Transition_Block(transition_channels * 16, transition_channels * 8),
Multi_Concat_Block(transition_channels * 16, block_channels * 8, transition_channels * 32, n=n, ids=ids),
)
self.dark5 = nn.Sequential(
Transition_Block(transition_channels * 32, transition_channels * 16),
Multi_Concat_Block(transition_channels * 32, block_channels * 8, transition_channels * 32, n=n, ids=ids),
)
if pretrained:
url = {
"l": 'https://github.com/bubbliiiing/yolov7-pytorch/releases/download/v1.0/yolov7_backbone_weights.pth',
"x": 'https://github.com/bubbliiiing/yolov7-pytorch/releases/download/v1.0/yolov7_x_backbone_weights.pth',
}[phi]
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", model_dir="./model_data")
self.load_state_dict(checkpoint, strict=False)
print("Load weights from " + url.split('/')[-1])
def forward(self, x):
x = self.stem(x)
x = self.dark2(x)
# -----------------------------------------------#
# dark3的输出为80, 80, 512,是一个有效特征层
# -----------------------------------------------#
x = self.dark3(x)
feat1 = x
# -----------------------------------------------#
# dark4的输出为40, 40, 1024,是一个有效特征层
# -----------------------------------------------#
x = self.dark4(x)
feat2 = x
# -----------------------------------------------#
# dark5的输出为20, 20, 1024,是一个有效特征层
# -----------------------------------------------#
x = self.dark5(x)
feat3 = x
return feat1, feat2, feat3
if __name__ == '__main__':
x = torch.randn(16, 3, 640, 640)
print("x.shape:", x.shape)
out1, out2, out3 = Backbone(3, 5, n=4, phi='l')(x)
print("out1.shape:", out1.shape, '\n', "out2.shape:", out2.shape, '\n', "out3.shape:", out3.shape)
输出:
x.shape: torch.Size([16, 3, 640, 640])
out1.shape: torch.Size([16, 48, 80, 80])
out2.shape: torch.Size([16, 96, 40, 40])
out3.shape: torch.Size([16, 96, 20, 20])
3、FPN特征金字塔
3.1 RepVGG结构
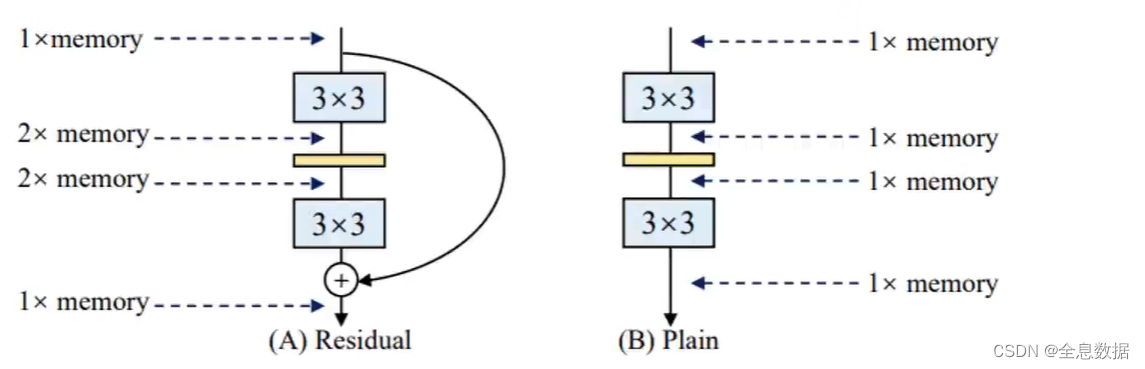
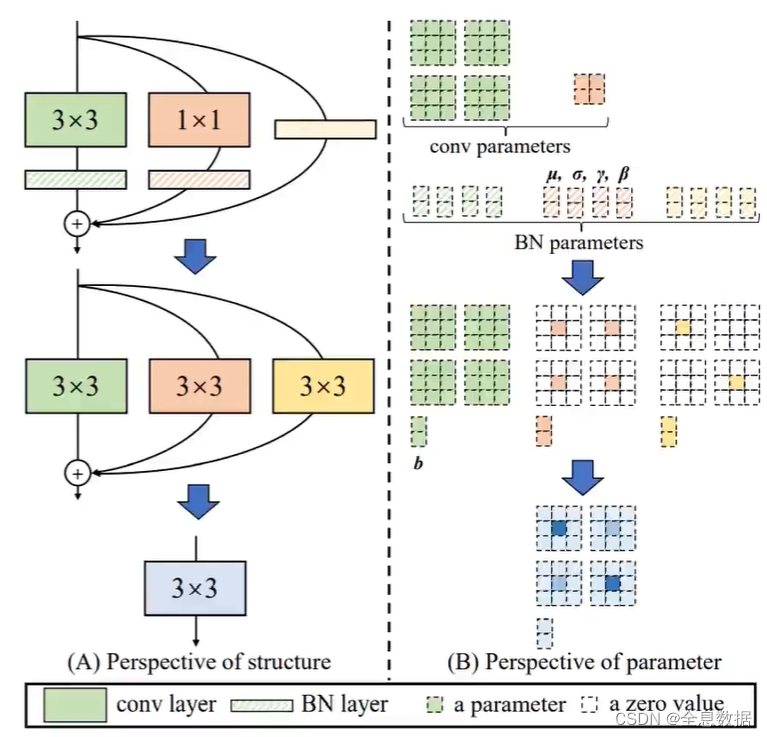
YoloV7使用了RepVGG结构,为什么使用RepVGG结构呢,VGG网络结构有如下优点:
- VGG在2014年就告诉我们一件事,3*3的卷积是最好的,其他的谁也不好使,
- 应该与英伟达优化相关,并不是纯卷积核大小的问题,3*3的卷积优化的最好,计算速度最快,所以现在都用3*3,
- 所以我们就得想想了能不能把多分支的,多种不同卷积核的,以及那些带BN的,全部都转换成3*3的卷积,然后叠加在一起呢,核心就是万物都是3*3,大一统了,
- 来算账了,VGG就一条路,走自己的路谁都不用管,就一倍显存,
- 只要带有分支了,首先就得互相等,然后一会要相加,中间那就得翻倍,如下图所示,
要完成的任务
输入输出都是2个特征图,
- 卷积和BN的合并
- 全部转成3*3的卷积
- 多个卷积核再合并
注意: 该操作只在预测时执行,
如下图,把1×1的卷积和输入 x x x 都转成3×3的卷积,然后再合并成一个3×3的卷积,
3.1.1 Conv+BN的操作
一个batch数据,
x
1
,
x
2
,
.
.
.
,
x
n
x_1,x_2,...,x_n
x1,x2,...,xn对它们来进行归一化操作:
x
^
i
=
γ
x
i
−
μ
σ
2
+
ϵ
+
β
\hat x_i=\gamma\frac{x_i-\mu}{\sqrt {\sigma^2+\epsilon}}+\beta
x^i=γσ2+ϵxi−μ+β
对上面的公式进行拆分,得:
x
^
i
=
γ
x
i
σ
2
+
ϵ
+
β
−
γ
μ
σ
2
+
ϵ
\hat x_i=\frac{\gamma x_i}{\sqrt {\sigma^2+\epsilon}}+\beta-\frac{\gamma\mu}{\sqrt {\sigma^2+\epsilon}}
x^i=σ2+ϵγxi+β−σ2+ϵγμ
注意均值和方差都是每个channel单独计算, β \beta β是平移系数, γ \gamma γ是缩放系数,其中均值和方差都是可以求出来的, β \beta β和 γ \gamma γ是学出来的, ϵ \epsilon ϵ是防止除 0 0 0 错误,
特征图 F F F,归一化后的结果也就相当于一个1 ∗ \ast ∗ 1 ∗ \ast ∗ C的卷积( w x + b wx+b wx+b)

合并方法(用一个卷积代替原来的卷积+BN):
- Let,
W
B
N
∈
R
C
×
C
W_{BN}\in \mathbb{R}^{C\times C}
WBN∈RC×C and
b
B
N
∈
R
C
b_{BN}\in \mathbb{R}^{C}
bBN∈RC - are parameters of the BN,
- W B N W_{BN} WBN是 C × C C\times C C×C的矩阵,如上面公式所示, b B N b_{BN} bBN 是 C × 1 C\times 1 C×1 的矩阵,
-
W
c
o
n
v
∈
R
C
×
(
C
p
r
e
v
⋅
K
2
)
W_{conv}\in \mathbb{R}^{C\times (C_{prev} \cdot K^2)}
Wconv∈RC×(Cprev⋅K2) and
b
c
o
n
v
∈
R
C
b_{conv}\in\mathbb{R}^C
bconv∈RC - are parameters of the Convolutional layer that precede BN
- W c o n v W_{conv} Wconv是卷积核大小为 K K K,输入通道数为 C C C,输出通道数为 C C C的矩阵, b c o n v b_{conv} bconv 是 C × 1 C\times 1 C×1 的矩阵,
- F p r e v F_{prev} Fprev - input to the convolutional
- C p r e v C_{prev} Cprev - the number of channels of the input layer
- k k k - is the filter size
- k × k k \times k k×k part of F p r e v F_{prev} Fprev reshaped into a k 2 ⋅ C p r e v k^2\cdot C_{prev} k2⋅Cprev vector f i , j f_{i,j} fi,j, so the resulting formula will be:
f
^
i
,
j
=
W
B
N
⋅
(
W
c
o
n
v
⋅
f
i
,
j
+
b
c
o
n
v
)
+
b
B
N
\hat{f}_{i,j}=W_{BN}\cdot (W_{conv}\cdot f_{i,j}+b_{conv})+b_{BN}
f^i,j=WBN⋅(Wconv⋅fi,j+bconv)+bBN
展开得:
f
^
i
,
j
=
W
B
N
⋅
W
c
o
n
v
⋅
f
i
,
j
+
W
B
N
⋅
b
c
o
n
v
+
b
B
N
\hat{f}_{i,j}=W_{BN}\cdot W_{conv}\cdot f_{i,j}+W_{BN}\cdot b_{conv}+b_{BN}
f^i,j=WBN⋅Wconv⋅fi,j+WBN⋅bconv+bBN
所以,conv和BN结合后,新的filter weights为:
W
B
N
⋅
W
c
o
n
v
W_{BN}\cdot W_{conv}
WBN⋅Wconv,新的偏置bias:
W
B
N
⋅
b
c
o
n
v
+
b
B
N
W_{BN}\cdot b_{conv}+b_{BN}
WBN⋅bconv+bBN,
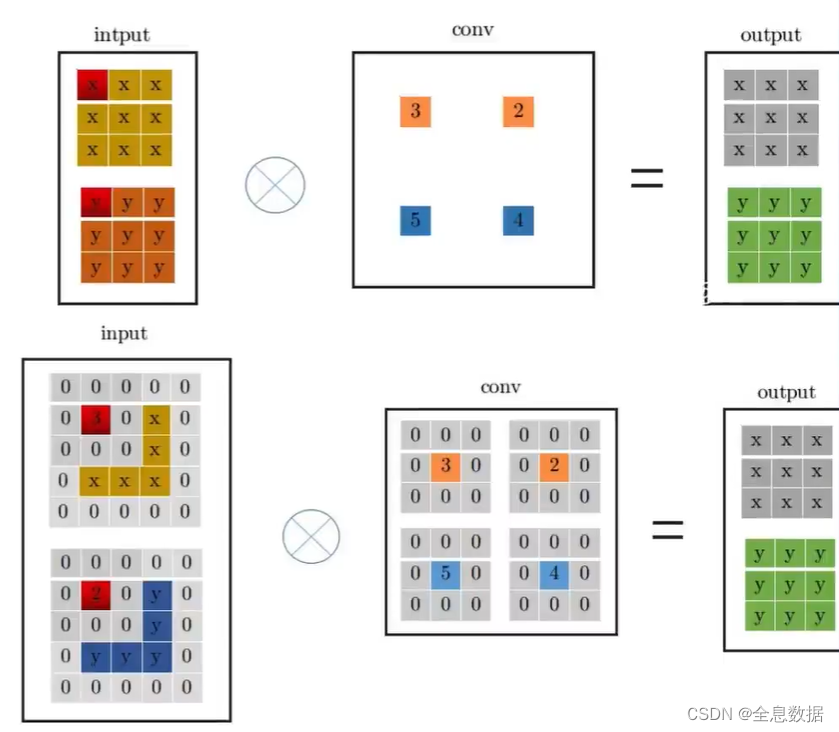
3.1.2 1 ∗ \ast ∗ 1卷积变换到3 ∗ \ast ∗ 3卷积
- 其实计算方式没变
- 只不过需要pad卷积核
- 但是要注意原始输入也要pad
- 这样1 ∗ \ast ∗ 1的就可以用3 ∗ \ast ∗ 3替代
如下图所示,
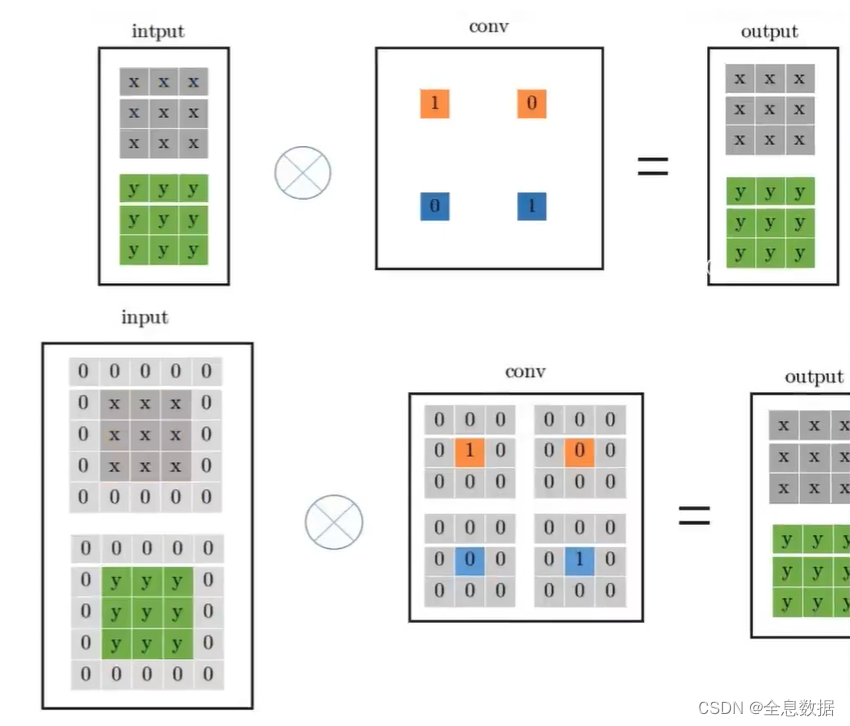
3.1.3 resnet残差链接转换为 3 ∗ 3 3\ast 3 3∗3的卷积
- 不就直接拿过来就得了嘛
- 跟我念:一乘以一得一
- 但是要拼成卷积核的形式
- 全剧终,都变成3*3的了
如下图所示,
backbone与FPN以及head代码:
import os
import sys
import numpy as np
import torch
import torch.nn as nn
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from nets.backbone import Backbone, Multi_Concat_Block, Conv, SiLU, Transition_Block, autopad
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))
class RepConv(nn.Module):
# Represented convolution
# https://arxiv.org/abs/2101.03697
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, act=SiLU(), deploy=False):
super(RepConv, self).__init__()
self.deploy = deploy
self.groups = g
self.in_channels = c1
self.out_channels = c2
assert k == 3
assert autopad(k, p) == 1
padding_11 = autopad(k, p) - k // 2
self.act = nn.LeakyReLU(0.1, inplace=True) if act is True else (
act if isinstance(act, nn.Module) else nn.Identity())
if deploy:
self.rbr_reparam = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=True)
else:
self.rbr_identity = (
nn.BatchNorm2d(num_features=c1, eps=0.001, momentum=0.03) if c2 == c1 and s == 1 else None)
self.rbr_dense = nn.Sequential(
nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False),
nn.BatchNorm2d(num_features=c2, eps=0.001, momentum=0.03),
)
self.rbr_1x1 = nn.Sequential(
nn.Conv2d(c1, c2, 1, s, padding_11, groups=g, bias=False),
nn.BatchNorm2d(num_features=c2, eps=0.001, momentum=0.03),
)
def forward(self, inputs):
if hasattr(self, "rbr_reparam"):
return self.act(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.act(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return (
kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid,
bias3x3 + bias1x1 + biasid,
)
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch[0].weight
running_mean = branch[1].running_mean
running_var = branch[1].running_var
gamma = branch[1].weight
beta = branch[1].bias
eps = branch[1].eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, "id_tensor"):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros(
(self.in_channels, input_dim, 3, 3), dtype=np.float32
)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def repvgg_convert(self):
kernel, bias = self.get_equivalent_kernel_bias()
return (
kernel.detach().cpu().numpy(),
bias.detach().cpu().numpy(),
)
def fuse_conv_bn(self, conv, bn):
std = (bn.running_var + bn.eps).sqrt()
bias = bn.bias - bn.running_mean * bn.weight / std
t = (bn.weight / std).reshape(-1, 1, 1, 1)
weights = conv.weight * t
bn = nn.Identity()
conv = nn.Conv2d(in_channels=conv.in_channels,
out_channels=conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
dilation=conv.dilation,
groups=conv.groups,
bias=True,
padding_mode=conv.padding_mode)
conv.weight = torch.nn.Parameter(weights)
conv.bias = torch.nn.Parameter(bias)
return conv
def fuse_repvgg_block(self):
if self.deploy:
return
print(f"RepConv.fuse_repvgg_block")
self.rbr_dense = self.fuse_conv_bn(self.rbr_dense[0], self.rbr_dense[1])
self.rbr_1x1 = self.fuse_conv_bn(self.rbr_1x1[0], self.rbr_1x1[1])
rbr_1x1_bias = self.rbr_1x1.bias
weight_1x1_expanded = torch.nn.functional.pad(self.rbr_1x1.weight, [1, 1, 1, 1])
# Fuse self.rbr_identity
if (isinstance(self.rbr_identity, nn.BatchNorm2d) or isinstance(self.rbr_identity,
nn.modules.batchnorm.SyncBatchNorm)):
identity_conv_1x1 = nn.Conv2d(
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=1,
stride=1,
padding=0,
groups=self.groups,
bias=False)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.to(self.rbr_1x1.weight.data.device)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.squeeze().squeeze()
identity_conv_1x1.weight.data.fill_(0.0)
identity_conv_1x1.weight.data.fill_diagonal_(1.0)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.unsqueeze(2).unsqueeze(3)
identity_conv_1x1 = self.fuse_conv_bn(identity_conv_1x1, self.rbr_identity)
bias_identity_expanded = identity_conv_1x1.bias
weight_identity_expanded = torch.nn.functional.pad(identity_conv_1x1.weight, [1, 1, 1, 1])
else:
bias_identity_expanded = torch.nn.Parameter(torch.zeros_like(rbr_1x1_bias))
weight_identity_expanded = torch.nn.Parameter(torch.zeros_like(weight_1x1_expanded))
self.rbr_dense.weight = torch.nn.Parameter(
self.rbr_dense.weight + weight_1x1_expanded + weight_identity_expanded)
self.rbr_dense.bias = torch.nn.Parameter(self.rbr_dense.bias + rbr_1x1_bias + bias_identity_expanded)
self.rbr_reparam = self.rbr_dense
self.deploy = True
if self.rbr_identity is not None:
del self.rbr_identity
self.rbr_identity = None
if self.rbr_1x1 is not None:
del self.rbr_1x1
self.rbr_1x1 = None
if self.rbr_dense is not None:
del self.rbr_dense
self.rbr_dense = None
def fuse_conv_and_bn(conv, bn):
fusedconv = nn.Conv2d(conv.in_channels,
conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
groups=conv.groups,
bias=True).requires_grad_(False).to(conv.weight.device)
w_conv = conv.weight.clone().view(conv.out_channels, -1)
w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
return fusedconv
# ---------------------------------------------------#
# yolo_body
# ---------------------------------------------------#
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, phi, pretrained=False):
super(YoloBody, self).__init__()
# -----------------------------------------------#
# 定义了不同yolov7版本的参数
# -----------------------------------------------#
transition_channels = {'l': 32, 'x': 40}[phi]
block_channels = 32
panet_channels = {'l': 32, 'x': 64}[phi]
e = {'l': 2, 'x': 1}[phi]
n = {'l': 4, 'x': 6}[phi]
ids = {'l': [-1, -2, -3, -4, -5, -6], 'x': [-1, -3, -5, -7, -8]}[phi]
conv = {'l': RepConv, 'x': Conv}[phi]
# -----------------------------------------------#
# 输入图片是640, 640, 3
# -----------------------------------------------#
# ---------------------------------------------------#
# 生成主干模型
# 获得三个有效特征层,他们的shape分别是:
# 80, 80, 512
# 40, 40, 1024
# 20, 20, 1024
# ---------------------------------------------------#
self.backbone = Backbone(transition_channels, block_channels, n, phi, pretrained=pretrained)
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
self.sppcspc = SPPCSPC(transition_channels * 32, transition_channels * 16)
self.conv_for_P5 = Conv(transition_channels * 16, transition_channels * 8)
self.conv_for_feat2 = Conv(transition_channels * 32, transition_channels * 8)
self.conv3_for_upsample1 = Multi_Concat_Block(transition_channels * 16, panet_channels * 4,
transition_channels * 8, e=e, n=n, ids=ids)
self.conv_for_P4 = Conv(transition_channels * 8, transition_channels * 4)
self.conv_for_feat1 = Conv(transition_channels * 16, transition_channels * 4)
self.conv3_for_upsample2 = Multi_Concat_Block(transition_channels * 8, panet_channels * 2,
transition_channels * 4, e=e, n=n, ids=ids)
self.down_sample1 = Transition_Block(transition_channels * 4, transition_channels * 4)
self.conv3_for_downsample1 = Multi_Concat_Block(transition_channels * 16, panet_channels * 4,
transition_channels * 8, e=e, n=n, ids=ids)
self.down_sample2 = Transition_Block(transition_channels * 8, transition_channels * 8)
self.conv3_for_downsample2 = Multi_Concat_Block(transition_channels * 32, panet_channels * 8,
transition_channels * 16, e=e, n=n, ids=ids)
self.rep_conv_1 = conv(transition_channels * 4, transition_channels * 8, 3, 1)
self.rep_conv_2 = conv(transition_channels * 8, transition_channels * 16, 3, 1)
self.rep_conv_3 = conv(transition_channels * 16, transition_channels * 32, 3, 1)
self.yolo_head_P3 = nn.Conv2d(transition_channels * 8, len(anchors_mask[2]) * (5 + num_classes), 1)
self.yolo_head_P4 = nn.Conv2d(transition_channels * 16, len(anchors_mask[1]) * (5 + num_classes), 1)
self.yolo_head_P5 = nn.Conv2d(transition_channels * 32, len(anchors_mask[0]) * (5 + num_classes), 1)
def fuse(self):
print('Fusing layers... ')
for m in self.modules():
if isinstance(m, RepConv):
m.fuse_repvgg_block()
elif type(m) is Conv and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn)
delattr(m, 'bn')
m.forward = m.fuseforward
return self
def forward(self, x):
# backbone
feat1, feat2, feat3 = self.backbone.forward(x)
P5 = self.sppcspc(feat3)
P5_conv = self.conv_for_P5(P5)
P5_upsample = self.upsample(P5_conv)
P4 = torch.cat([self.conv_for_feat2(feat2), P5_upsample], 1)
P4 = self.conv3_for_upsample1(P4)
P4_conv = self.conv_for_P4(P4)
P4_upsample = self.upsample(P4_conv)
P3 = torch.cat([self.conv_for_feat1(feat1), P4_upsample], 1)
P3 = self.conv3_for_upsample2(P3)
P3_downsample = self.down_sample1(P3)
P4 = torch.cat([P3_downsample, P4], 1)
P4 = self.conv3_for_downsample1(P4)
P4_downsample = self.down_sample2(P4)
P5 = torch.cat([P4_downsample, P5], 1)
P5 = self.conv3_for_downsample2(P5)
P3 = self.rep_conv_1(P3)
P4 = self.rep_conv_2(P4)
P5 = self.rep_conv_3(P5)
# ---------------------------------------------------#
# 第三个特征层
# y3=(batch_size, 75, 80, 80)
# ---------------------------------------------------#
out2 = self.yolo_head_P3(P3)
# ---------------------------------------------------#
# 第二个特征层
# y2=(batch_size, 75, 40, 40)
# ---------------------------------------------------#
out1 = self.yolo_head_P4(P4)
# ---------------------------------------------------#
# 第一个特征层
# y1=(batch_size, 75, 20, 20)
# ---------------------------------------------------#
out0 = self.yolo_head_P5(P5)
return [out0, out1, out2]
if __name__ == '__main__':
x = torch.randn(16, 3, 640, 640)
print("x.shape:", x.shape)
anchors_mask = [[[12, 16], [19, 36], [40, 28]], [[36, 75], [76, 55], [72, 146]], [[142, 110], [192, 243], [459, 401]]]
out = YoloBody(anchors_mask, 20, 'l')(x)
for item in out:
print(item.shape)
输出:
x.shape: torch.Size([16, 3, 640, 640])
torch.Size([16, 75, 20, 20])
torch.Size([16, 75, 40, 40])
torch.Size([16, 75, 80, 80])
二、预测结果的解码
1、 获得预测框、置信度、种类的数值
在YoloV3和V4时,坐标值的预测遵循以下4行公式,详细了解请参考这个CSDN博文链接,
b
x
=
σ
(
t
x
)
+
c
x
b_x=\sigma(t_x)+c_x
bx=σ(tx)+cx
b
y
=
σ
(
t
y
)
+
c
y
b_y=\sigma(t_y)+c_y
by=σ(ty)+cy
b
w
=
p
w
⋅
e
t
w
b_w=p_w\cdot e^{t_w}
bw=pw⋅etw
b
h
=
p
w
⋅
e
t
h
b_h=p_w\cdot e^{t_h}
bh=pw⋅eth
而在YoloV5和V7中,坐标值预测的公式发生了改变,因为在YoloV5和V7中使用了多样本匹配,所以对于网络预测的
σ
(
t
x
)
\sigma(t_x)
σ(tx)和
σ
(
t
y
)
\sigma(t_y)
σ(ty)的偏移范围是 -0.5
→
\to
→ 1.5之间,而对于网络预测的
σ
(
t
w
)
\sigma(t_w)
σ(tw)和
σ
(
t
h
)
\sigma(t_h)
σ(th)收缩范围是0
→
\to
→ 4之间,因为在正样本匹配中GT的宽高与anchor的宽高最大比值是4,想更多了解详细原因可参考这个链接:https://github.com/ultralytics/yolov5/issues/471,
b
x
=
2
σ
(
t
x
)
−
0.5
+
c
x
b_x=2\sigma(t_x)-0.5+c_x
bx=2σ(tx)−0.5+cx
b
y
=
2
σ
(
t
y
)
−
0.5
+
c
y
b_y=2\sigma(t_y)-0.5+c_y
by=2σ(ty)−0.5+cy
b
w
=
p
w
(
2
σ
(
t
w
)
)
2
b_w=p_w(2\sigma(t_w))^2
bw=pw(2σ(tw))2
b
h
=
p
h
(
2
σ
(
t
h
)
)
2
b_h=p_h(2\sigma(t_h))^2
bh=ph(2σ(th))2
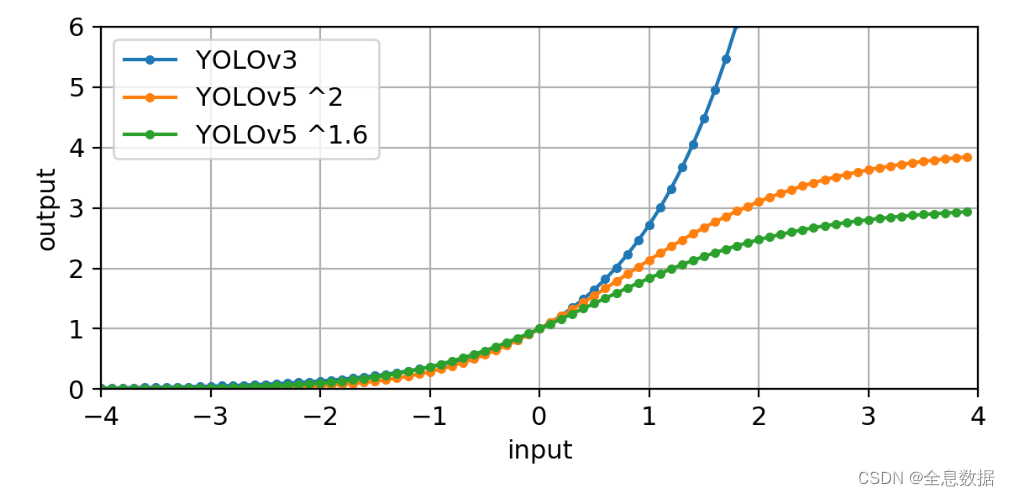
下图中黑色虚线框:anchor,蓝色实线框:gt,
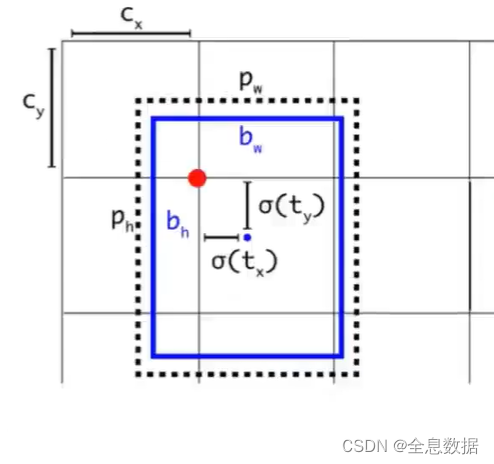
上面公式中 t w t_w tw 外面加 σ \sigma σ 的原因是:
- V3梯度容易爆炸
- V5平方后取值范围0-4
- 也就是倍率不能差异太多
- 咱们选正样本的时候也是要选符合一定范围倍率的(0.25-4),这里用我语文老师的话就是上下文遥相呼应
代码:
def decode_box(self, inputs):
outputs = []
for i, input in enumerate(inputs):
# -----------------------------------------------#
# 输入的input一共有三个,他们的shape分别是
# batch_size, 255, 20, 20
# batch_size, 255, 40, 40
# batch_size, 255, 80, 80
# -----------------------------------------------#
batch_size = input.size(0)
input_height = input.size(2)
input_width = input.size(3)
# -----------------------------------------------#
# 输入为640x640时
# stride_h = stride_w = 32、16、8
# -----------------------------------------------#
stride_h = self.input_shape[0] / input_height
stride_w = self.input_shape[1] / input_width
# -------------------------------------------------#
# 此时获得的scaled_anchors大小是相对于特征层的
# -------------------------------------------------#
scaled_anchors = [(anchor_width / stride_w, anchor_height / stride_h) for anchor_width, anchor_height in
self.anchors[self.anchors_mask[i]]]
# -----------------------------------------------#
# 输入的input一共有三个,他们的shape分别是
# batch_size, 3, 20, 20, 85
# batch_size, 3, 40, 40, 85
# batch_size, 3, 80, 80, 85
# -----------------------------------------------#
prediction = input.view(batch_size, len(self.anchors_mask[i]),
self.bbox_attrs, input_height, input_width).permute(0, 1, 3, 4, 2).contiguous()
# -----------------------------------------------#
# 先验框的中心位置的调整参数
# -----------------------------------------------#
x = torch.sigmoid(prediction[..., 0])
y = torch.sigmoid(prediction[..., 1])
# -----------------------------------------------#
# 先验框的宽高调整参数
# -----------------------------------------------#
w = torch.sigmoid(prediction[..., 2])
h = torch.sigmoid(prediction[..., 3])
# -----------------------------------------------#
# 获得置信度,是否有物体
# -----------------------------------------------#
conf = torch.sigmoid(prediction[..., 4])
# -----------------------------------------------#
# 种类置信度
# -----------------------------------------------#
pred_cls = torch.sigmoid(prediction[..., 5:])
# 暂未看懂?
FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor
# ----------------------------------------------------------#
# 生成网格,先验框中心,网格左上角
# batch_size,3,20,20
# ----------------------------------------------------------#
grid_x = torch.linspace(0, input_width - 1, input_width).repeat(input_height, 1).repeat(
batch_size * len(self.anchors_mask[i]), 1, 1).view(x.shape).type(FloatTensor)
grid_y = torch.linspace(0, input_height - 1, input_height).repeat(input_width, 1).t().repeat(
batch_size * len(self.anchors_mask[i]), 1, 1).view(y.shape).type(FloatTensor)
# ----------------------------------------------------------#
# 按照网格格式生成先验框的宽高
# batch_size,3,20,20
# ----------------------------------------------------------#
anchor_w = FloatTensor(scaled_anchors).index_select(1, LongTensor([0]))
anchor_h = FloatTensor(scaled_anchors).index_select(1, LongTensor([1]))
anchor_w = anchor_w.repeat(batch_size, 1).repeat(1, 1, input_height * input_width).view(w.shape)
anchor_h = anchor_h.repeat(batch_size, 1).repeat(1, 1, input_height * input_width).view(h.shape)
# ----------------------------------------------------------#
# 利用预测结果对先验框进行调整
# 首先调整先验框的中心,从先验框中心向右下角偏移
# 再调整先验框的宽高。
# ----------------------------------------------------------#
pred_boxes = FloatTensor(prediction[..., :4].shape)
pred_boxes[..., 0] = x.data * 2. - 0.5 + grid_x
pred_boxes[..., 1] = y.data * 2. - 0.5 + grid_y
pred_boxes[..., 2] = (w.data * 2) ** 2 * anchor_w
pred_boxes[..., 3] = (h.data * 2) ** 2 * anchor_h
# ----------------------------------------------------------#
# 将输出结果归一化成小数的形式
# ----------------------------------------------------------#
_scale = torch.Tensor([input_width, input_height, input_width, input_height]).type(FloatTensor)
output = torch.cat((pred_boxes.view(batch_size, -1, 4) / _scale,
conf.view(batch_size, -1, 1), pred_cls.view(batch_size, -1, self.num_classes)), -1)
outputs.append(output.data)
return outputs
2、得分筛选与非极大抑制
代码:
def non_max_suppression(self, prediction, num_classes, input_shape, image_shape, letterbox_image, conf_thres=0.5,
nms_thres=0.4):
# ----------------------------------------------------------#
# 将预测结果的格式转换成左上角右下角的格式。
# prediction [batch_size, num_anchors, 85]
# ----------------------------------------------------------#
box_corner = prediction.new(prediction.shape)
box_corner[:, :, 0] = prediction[:, :, 0] - prediction[:, :, 2] / 2
box_corner[:, :, 1] = prediction[:, :, 1] - prediction[:, :, 3] / 2
box_corner[:, :, 2] = prediction[:, :, 0] + prediction[:, :, 2] / 2
box_corner[:, :, 3] = prediction[:, :, 1] + prediction[:, :, 3] / 2
prediction[:, :, :4] = box_corner[:, :, :4]
output = [None for _ in range(len(prediction))]
for i, image_pred in enumerate(prediction):
# ----------------------------------------------------------#
# 对种类预测部分取max。
# class_conf [num_anchors, 1] 种类置信度
# class_pred [num_anchors, 1] 种类
# 0是每列的最大值,1是每行的最大值
# ----------------------------------------------------------#
class_conf, class_pred = torch.max(image_pred[:, 5:5 + num_classes], 1, keepdim=True)
# ----------------------------------------------------------#
# 利用置信度进行第一轮筛选
# ----------------------------------------------------------#
conf_mask = (image_pred[:, 4] * class_conf[:, 0] >= conf_thres).squeeze()
# ----------------------------------------------------------#
# 根据置信度进行预测结果的筛选
# ----------------------------------------------------------#
image_pred = image_pred[conf_mask]
class_conf = class_conf[conf_mask]
class_pred = class_pred[conf_mask]
if not image_pred.size(0):
continue
# -------------------------------------------------------------------------#
# detections [num_anchors, 7]
# 7的内容为:x1, y1, x2, y2, obj_conf, class_conf, class_pred
# -------------------------------------------------------------------------#
detections = torch.cat((image_pred[:, :5], class_conf.float(), class_pred.float()), 1)
# ------------------------------------------#
# 获得预测结果中包含的所有种类
# ------------------------------------------#
unique_labels = detections[:, -1].cpu().unique()
if prediction.is_cuda:
unique_labels = unique_labels.cuda()
detections = detections.cuda()
for c in unique_labels:
# ------------------------------------------#
# 获得某一类得分筛选后全部的预测结果
# ------------------------------------------#
detections_class = detections[detections[:, -1] == c]
# ------------------------------------------#
# 使用官方自带的非极大抑制会速度更快一些!
# ------------------------------------------#
keep = nms(
detections_class[:, :4],
detections_class[:, 4] * detections_class[:, 5],
nms_thres
)
max_detections = detections_class[keep]
# # 按照存在物体的置信度排序
# _, conf_sort_index = torch.sort(detections_class[:, 4]*detections_class[:, 5], descending=True)
# detections_class = detections_class[conf_sort_index]
# # 进行非极大抑制
# max_detections = []
# while detections_class.size(0):
# # 取出这一类置信度最高的,一步一步往下判断,判断重合程度是否大于nms_thres,如果是则去除掉
# max_detections.append(detections_class[0].unsqueeze(0))
# if len(detections_class) == 1:
# break
# ious = bbox_iou(max_detections[-1], detections_class[1:])
# detections_class = detections_class[1:][ious < nms_thres]
# # 堆叠
# max_detections = torch.cat(max_detections).data
# Add max detections to outputs
output[i] = max_detections if output[i] is None else torch.cat((output[i], max_detections))
if output[i] is not None:
output[i] = output[i].cpu().numpy()
box_xy, box_wh = (output[i][:, 0:2] + output[i][:, 2:4]) / 2, output[i][:, 2:4] - output[i][:, 0:2]
output[i][:, :4] = self.yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape, letterbox_image)
return output
三、训练过程
1、正样本匹配过程
YoloV7的正样本匹配策略结合了YoloV5和YoloX,所谓正样本匹配,就是寻找哪些anchor(先验框)被认为有对应的真实框(GT),并且负责这个真实框的预测。
正样本分配策略一:
- 特征图上的每个特征点都会参与预测结果,正样本匹配就是哪些特征点会参与预测正样本,
- 核心思想就是GT的中心点落在哪个点附近,其所对应的anchor就是正样本,
- 但是想一想,咱们任务是缺正样本还是负样本呢?
- 为了正样本能更多,咱们直接threeble-kill(3杀),比之前多出3倍的正样本,
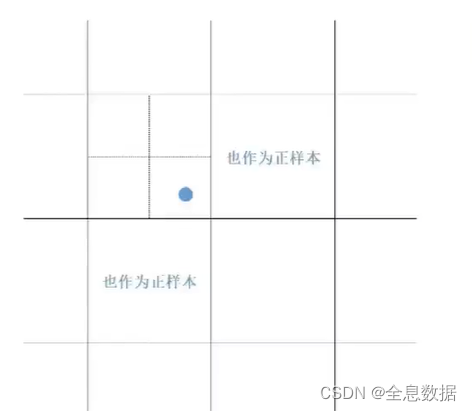
如下图所示,GT(Ground Truth)的中心点是下图中的蓝色圆点,以这个蓝点为中心上下左右各平移0.5个网格(grid),平移后如果落在新的网格中,则新的网格的左上角对应的点也负责正样本的训练,所以在YoloV7中有3个网格点负责正样本的训练,通过这个策略可以提升召回率(recall),
正样本分配策略二:
- 这里要根据差异来选择了
- 肯定不能都把全部的anchor算成正样本,
- 主要根据anchor和GT的长宽差异筛选anchor、类别预测差异判别是否为正样本,
步骤如下:
- (1)初步筛选适配的anchor:0.25< g t a n c h o r 长宽比例 \frac{gt}{anchor长宽比例} anchor长宽比例gt<4;
- (2)计算筛选后的anchor和GT之间的IOU;
- (3)计算类别预测损失;
- 第一次筛选是上面的(1)步骤,根据上面(2)和(3)的损失排名,再进行第二次筛选,
正样本分配之IOU损失计算
例如当前有3个GT,候选框(筛选后的anchor)经过筛选后共有13个,可以得到[3,13]的矩阵,每个候选框都要与3个GT做IOU损失,如下图,

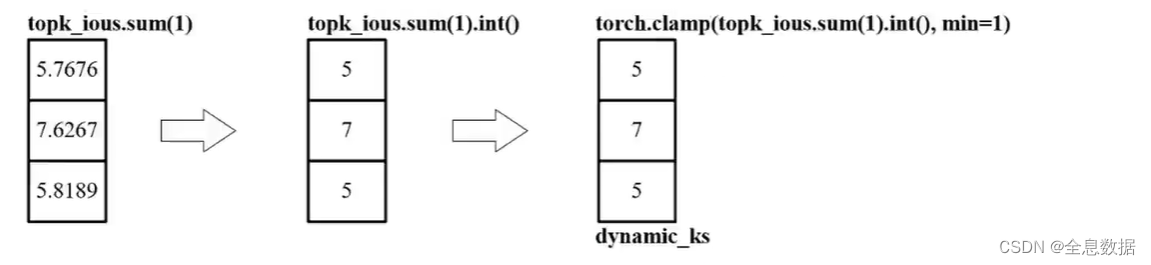
接下来TOPK,假定一个GT最多有10个先验框需要匹配,得到[3,10]矩阵,然后再计算每个GT与10个先验框的IOU之和,然后取整选出最优个数的先验框,比如计算IOU之和为5.9,则TOPK为5,IOU之和为5.1,TOPK也为5,如下图,

- 得到每一个GT所对应的候选框数量,最少也得一个,
- sum我觉得可以当作有一些IOU都比较小,虽然排在前10,但是可能也没啥用,
- 求和就相当于,这些里面我根据IOU大小来看到底取几个合适,不是固定的,所以叫自适应匹配,
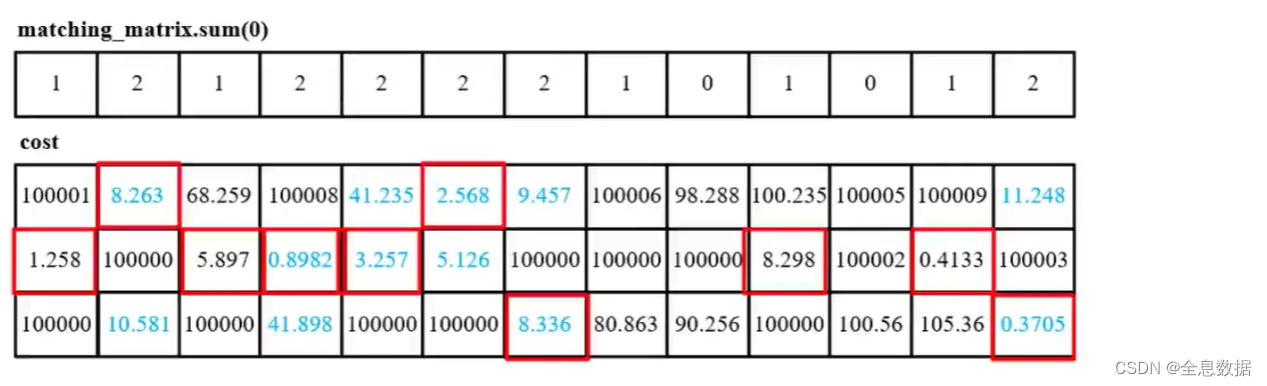
但是在计算的时候有些候选框可能会对应多个GT,在Yolo里一个候选框最多只能对应一个GT,这就得做筛选了,下图第一个表格中为2的就表示当前候选框对应2个GT,就得选其中损失最小的那一个,
AUX辅助输出
- 如果输入feature map更大,比如输入1280 ∗ \ast ∗ 1280,需要对1280 ∗ \ast ∗ 1280进行下采样,通过切片操作变成4个640 ∗ \ast ∗ 640的feature map,把1280 ∗ \ast ∗ 1280的宽高信息转为channel信息,
- 4个输出层,每层还是3个anchor,这回一共得4 ∗ \ast ∗ 2=8个输出层了(带辅助),
- 但是辅助头在选择正样本时仍使用主头的预测结果(主的才是重要的),
- 为了增加召回率,辅助头选择了周围5个区域,也就是偏移量由0.5 → \to → 1,
1.1 匹配anchor与特征点
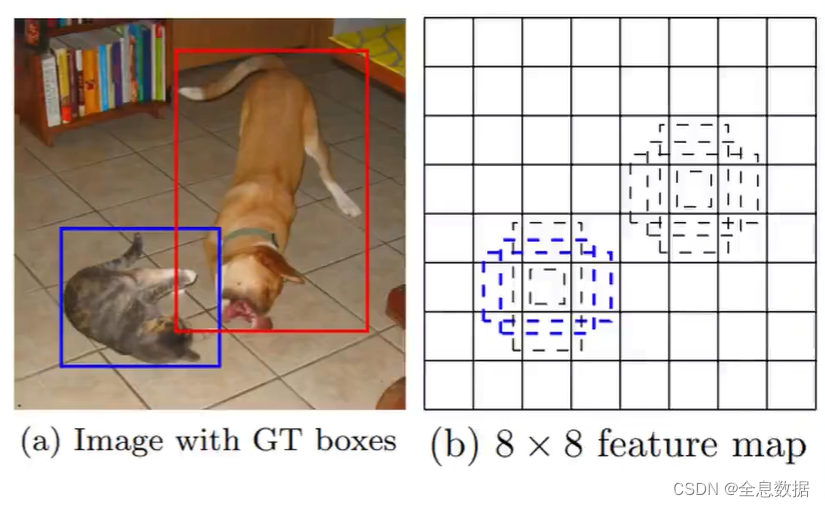
已知GT/标签,如何通过GT去匹配预测输出的哪一特征层的哪一个特征点呢?
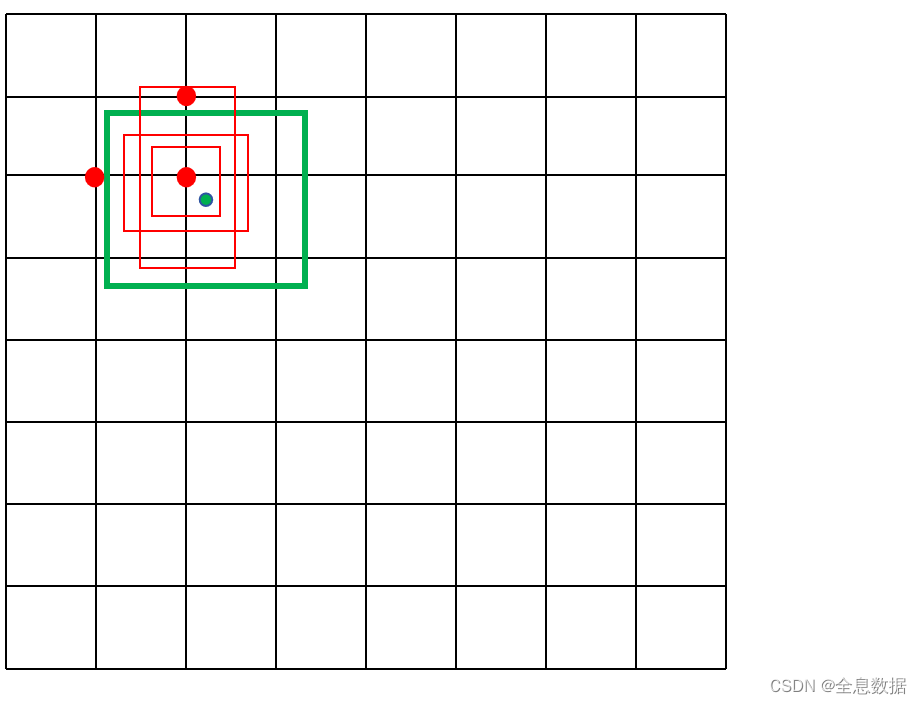
- 如下图,是3个输出层中的某一层,假设特征层大小为8 ∗ \ast ∗ 8,绿色矩形框为GT,绿色点为绿色矩形框GT的中心点,则绿色点所在网格(grid)的左上角,以及绿色点上下左右各平移0.5个单位,如果落在其他的网格,那么这个网格的左上角也负责预测这个GT,所以一共有3个网格点负责预测GT,如下图的红色点所示,
- 每一个红色点都有3个anchor,那么哪些红色点上的哪个anchor负责预测GT呢?可以通过以下策略
- 1、先根据每个GT的长宽与anchor的长宽相除,如果不满足长宽比在1/4到4之间,则去除该特征层的GT;
- 2、然后根据GT选出除了GT中心点所在网格的附近的多个(1 → \to → 2)正样本,
- 3、然后根据选出的正样本得到对应的特征点,以及对应的imgs_idx,class,anchor_idx,
- 上述步骤可能会比较笼统模糊,具体请细看下面的源码 find_3_positive(self, p, targets),
代码:
predictions: [[batch, 3, 80, 80 ,(cls+5)], [batch, 3, 40, 40, (cls+5)], [batch, 3, 20, 20, (cls+5)]]
targets.shape:[nt, 6],6包含图片索引,类别id, x,y,w,h;nt是一个batch图片中有多少个GT,
下面的代码主要实现一个batch中的GT应该去匹配哪个特征层上的哪个特征点上的哪个anchor
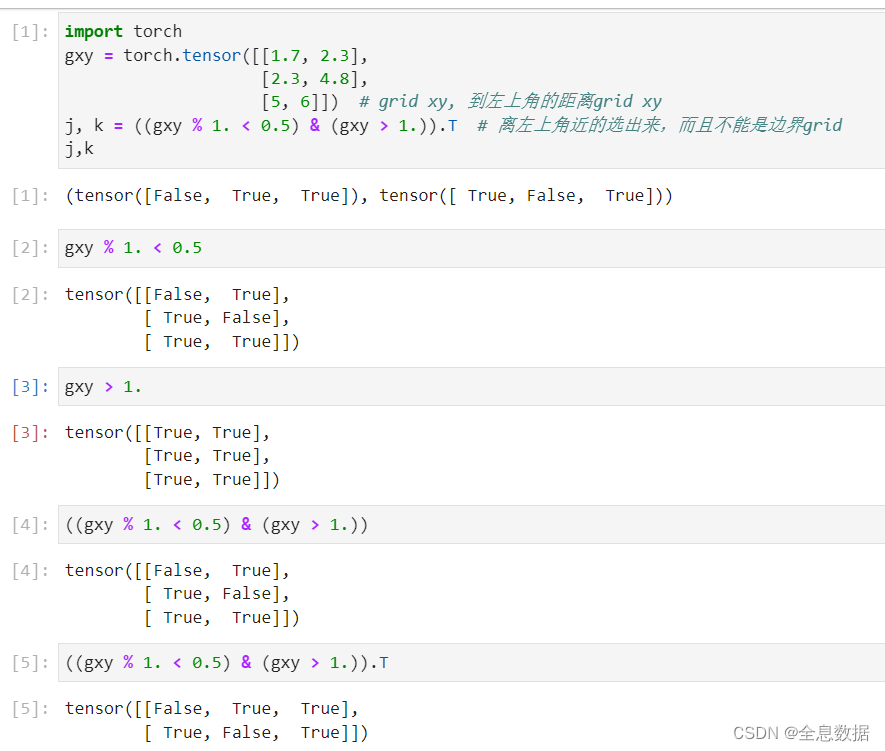
下面的代码中几行可参考下图,
def find_3_positive(self, p, targets):
"""
目的:目的:根据每个特征层上的每个特征点, 是否需要分配GT
"""
# Build targets for compute_loss(), input targets(image, class, x, y, w, h),
# input p(3,)=[[batch,3,80,80,(cls+5)], [batch,3,40,40,(cls+5)], [batch,3,20,20,(cls+5)]]
na, nt = self.na, targets.shape[0] # number of anchors,不指定就默认为3, nt: targets的个数
indices, anch = [], []
# gain: tensor([1, 1, 1, 1, 1, 1, 1], device='cuda:0')
gain = torch.ones(7, device=targets.device).long() # 7表示原标签6个+anchorID(属于哪个大小的anchor), normalized to gridspace gain
"""
ai.shape:[3,nt],这里假定nt=42,
tensor([
[0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0..0.,0.,0.,0.,0.,0.,0..0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.,0.],
[1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1..1..1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.,1.],
[2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.,2.]],
device='cuda:0')
"""
# ai.shape:[na*1, 1*nt]
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
'''
targets.shape: [nt,6]
targets.repeat(na, 1, 1).shape: [na=3,nt,6]
ai[:, :, None].shape: [3,nt,1]
torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2).shape: [3,nt,7]
'''
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # 就是最后加了一个维度,表示anchorID, append anchor indices
g = 0.5 # bias 一会要玩漂移
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets
for i in range(self.nl): # 有3个输出层,分别做
anchors = self.anchors[i] # 当前输出层对应anchor, self.anchors.shape:[3,3,2]
'''
gain[2:6] = (Tensor: [7,], tensor[1, 1, 80/40/20, 80/40/20, 80/40/20, 80/40/20, 1], device='cuda:0')
p[i]:shape:[batch, 3, 80, 80, cls+5]
作用:防止正样本有越界现象
'''
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # 赋值,一会用,xyxy gain
# Match targets to anchors 这块在遍历看看这些GT到底放在哪个输出层合适,
# t.shape:[3, nt, 7], 假定nt=42
t = targets * gain # 归一化的标签映射到相应的特征图(80*80, 40*40, 20*20)上
if nt:
# Matches
# r.shape:[3, nt, 2]
r = t[:, :, 4:6] / anchors[:, None] # wh ratio, 每一个GT与anchor大宽高比大小
# j.shape:[3, nt], 每一个GT都会和3个anchor作比较,
j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare, 0.25<比例<4才会被保留
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
# t.shape:[39, 7], 原来是42*3, 减少了42*3-39,
"""
t原先的shape为[3, nt, 7],也就是每个GT都要与3个anchor作除法,不满足条件的被删去,
"""
t = t[j] # filter
# Offsets
# gxy.shape: [39, 2], gxi.shape: [39, 2],
gxy = t[:, 2:4] # grid xy, 到左上角的距离grid xy
gxi = gain[[2, 3]] - gxy # inverse, 到右下角的距离
j, k = ((gxy % 1. < g) & (gxy > 1.)).T # 离左上角近的选出来,而且不能是边界grid
l, m = ((gxi % 1. < g) & (gxi > 1.)).T # 离右下角近的选出来,而且不能是边界grid
# j.shape: [5, 39]
j = torch.stack((torch.ones_like(j), j, k, l, m)) # 5个,因为自己所在的实际位置一定为true
# t.shape: [39*3=117, 7]
# t.repeat((5, 1, 1)):在多样本匹配中,GT除了中心点所在的网格的左上角需要参与预测,其余上下左右相邻的特征点也可能会参与预测
t = t.repeat((5, 1, 1))[j] # 相当于原来就1个, 现在还要考虑2个邻居, target必然增多, 应该是多出1-2个正样本/邻居, by wdb备注
# offsets.shape: [117, 2]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j] # 对应区域玩对应漂移的大小, 都是0.5个单位
else:
t = targets[0]
offsets = 0
# Define
# b.shape:[117,], c.shape:[117,]
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long() # 漂移后, 整数部分就是格子的索引
gi, gj = gij.T # grid xy indices
# Append
# a.shape:[117,]
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
anch.append(anchors[a]) # anchors, anchors的大小
return indices, anch
本段代码注释来自参考链接:
def find_3_positive(self, predictions, targets):
# ------------------------------------#
# 获得每个特征层先验框的数量
# 与真实框的数量
# ------------------------------------#
num_anchor, num_gt = len(self.anchors_mask[0]), targets.shape[0]
# ------------------------------------#
# 创建空列表存放indices和anchors
# ------------------------------------#
indices, anchors = [], []
# ------------------------------------#
# 创建7个1
# 序号0,1为1
# 序号2:6为特征层的高宽
# 序号6为1
# ------------------------------------#
gain = torch.ones(7, device=targets.device)
# ------------------------------------#
# ai [num_anchor, num_gt]
# targets [num_gt, 6] => [num_anchor, num_gt, 7]
# ------------------------------------#
ai = torch.arange(num_anchor, device=targets.device).float().view(num_anchor, 1).repeat(1, num_gt)
targets = torch.cat((targets.repeat(num_anchor, 1, 1), ai[:, :, None]), 2) # append anchor indices
g = 0.5 # offsets
off = torch.tensor([
[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g
for i in range(len(predictions)):
# ----------------------------------------------------#
# 将先验框除以stride,获得相对于特征层的先验框。
# anchors_i [num_anchor, 2]
# ----------------------------------------------------#
anchors_i = torch.from_numpy(self.anchors[i] / self.stride[i]).type_as(predictions[i])
# -------------------------------------------#
# 计算获得对应特征层的高宽
# -------------------------------------------#
gain[2:6] = torch.tensor(predictions[i].shape)[[3, 2, 3, 2]]
# -------------------------------------------#
# 将真实框乘上gain,
# 其实就是将真实框映射到特征层上
# -------------------------------------------#
t = targets * gain
if num_gt:
# -------------------------------------------#
# 计算真实框与先验框高宽的比值
# 然后根据比值大小进行判断,
# 判断结果用于取出,获得所有先验框对应的真实框
# r [num_anchor, num_gt, 2]
# t [num_anchor, num_gt, 7] => [num_matched_anchor, 7]
# -------------------------------------------#
r = t[:, :, 4:6] / anchors_i[:, None]
j = torch.max(r, 1. / r).max(2)[0] < self.threshold
t = t[j] # filter
# -------------------------------------------#
# gxy 获得所有先验框对应的真实框的x轴y轴坐标
# gxi 取相对于该特征层的右小角的坐标
# -------------------------------------------#
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
# -------------------------------------------#
# t 重复5次,使用满足条件的j进行框的提取
# j 一共五行,代表当前特征点在五个
# [0, 0], [1, 0], [0, 1], [-1, 0], [0, -1]
# 方向是否存在
# -------------------------------------------#
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
# -------------------------------------------#
# b 代表属于第几个图片
# gxy 代表该真实框所处的x、y中心坐标
# gwh 代表该真实框的wh坐标
# gij 代表真实框所属的特征点坐标
# -------------------------------------------#
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices
# -------------------------------------------#
# gj、gi不能超出特征层范围
# a代表属于该特征点的第几个先验框
# -------------------------------------------#
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
anchors.append(anchors_i[a]) # anchors
return indices, anchors
1.2 SimOTA自适应匹配
- 遍历1张图片,比如有3个GT,13个正样本(anchor),分别将3个GT对13个正样本计算IOU,维度是[3,13],然后再取TOPK,取IOU从大到小的前10个,不够10个的话能取几个取几个,此时维度是[3,10],然后再对[3,10]的矩阵做累加,然后再做累加和的截断,累加和分别是5,7,5,
- 然后根据IOU损失和类别损失做一个cost代价矩阵,选出每一个GT对应的最佳的正样本,
- 有可能会出现一个正样本匹配到了多个GT的情况,根据该正样本跟哪个GT损失最小,则就选择哪个GT,
避免同一个正样本匹配2个GT,
代码:
def build_targets(self, p, targets, imgs):
# indices, anch = self.find_positive(p, targets)
indices, anch = self.find_3_positive(p, targets)
# indices, anch = self.find_4_positive(p, targets)
# indices, anch = self.find_5_positive(p, targets)
# indices, anch = self.find_9_positive(p, targets)
device = torch.device(targets.device)
matching_bs = [[] for pp in p] # [[], [], []]
matching_as = [[] for pp in p] # [[], [], []]
matching_gjs = [[] for pp in p] # [[], [], []]
matching_gis = [[] for pp in p] # [[], [], []]
matching_targets = [[] for pp in p] # [[], [], []]
matching_anchs = [[] for pp in p] # [[], [], []]
nl = len(p) # nl:3
for batch_idx in range(p[0].shape[0]): # 对每张图片进行遍历,
b_idx = targets[:, 0] == batch_idx # 得到该张图片专属的GT
this_target = targets[b_idx] # 当前图像里的标注框GT, 如this_target.shape:[2, 6], targets.shape:[42, 6]
if this_target.shape[0] == 0:
continue
txywh = this_target[:, 2:6] * imgs[batch_idx].shape[1] # 得到实际大小
txyxy = xywh2xyxy(txywh) # 变成左上角和右下角
pxyxys = []
p_cls = []
p_obj = []
from_which_layer = []
all_b = []
all_a = []
all_gj = []
all_gi = []
all_anch = []
for i, pi in enumerate(p):
b, a, gj, gi = indices[i]
idx = (b == batch_idx)
# len(b):该特征层anchor的个数,
b, a, gj, gi = b[idx], a[idx], gj[idx], gi[idx]
all_b.append(b)
all_a.append(a)
all_gj.append(gj)
all_gi.append(gi)
all_anch.append(anch[i][idx])
# 当前GT来自哪个输出层,
# 例如from_which_layer:[tensor([]), tensor([]), tensor([2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])]
from_which_layer.append((torch.ones(size=(len(b),)) * i).to(device))
fg_pred = pi[b, a, gj, gi] # 取对应target位置的预测结果
p_obj.append(fg_pred[:, 4:5])
p_cls.append(fg_pred[:, 5:])
grid = torch.stack([gi, gj], dim=1)
pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i] # 中心点在当前格子偏移量,-0.5到1.5之间,再还原, / 8.
# pxy = (fg_pred[:, :2].sigmoid() * 3. - 1. + grid) * self.stride[i]
pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i] # 之前是考虑四倍, 这也得同步, / 8.
pxywh = torch.cat([pxy, pwh], dim=-1)
pxyxy = xywh2xyxy(pxywh)
pxyxys.append(pxyxy)
pxyxys = torch.cat(pxyxys, dim=0)
if pxyxys.shape[0] == 0:
continue
p_obj = torch.cat(p_obj, dim=0)
p_cls = torch.cat(p_cls, dim=0)
from_which_layer = torch.cat(from_which_layer, dim=0)
all_b = torch.cat(all_b, dim=0)
all_a = torch.cat(all_a, dim=0)
all_gj = torch.cat(all_gj, dim=0)
all_gi = torch.cat(all_gi, dim=0)
all_anch = torch.cat(all_anch, dim=0)
# 例如,txyxy.shape:[2,4], pxyxys.shape:[18,4]
# pair_wise_iou.shape:[2,18]
pair_wise_iou = box_iou(txyxy, pxyxys) # 计算GT与所有候选正样本的IOU
pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8) # IOU损失
# top_k.shape:[2,10]
top_k, _ = torch.topk(pair_wise_iou, min(10, pair_wise_iou.shape[1]), dim=1) # 多的话选10个,少的话有几个算几个
# 动态匹配,例如dynamic_ks=[2,3],也就是说第1个GT匹配2个正样本,第2个GT匹配3个正样本
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1) # 累加,相当于有些可能太小的我不需要,宁缺毋滥
# gt_cls_per_image.shape:[2,18,6]
gt_cls_per_image = (
F.one_hot(this_target[:, 1].to(torch.int64), self.nc)
.float()
.unsqueeze(1)
.repeat(1, pxyxys.shape[0], 1) # onehot后重复候选框数量次
)
num_gt = this_target.shape[0] # num_gt:2
# 预测类别情况,是物体可能的前提下,再做预测类别
# cls_preds_.shape:[2,18,6]
cls_preds_ = (
p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
* p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
)
y = cls_preds_.sqrt_()
# 类别差异
pair_wise_cls_loss = F.binary_cross_entropy_with_logits(
torch.log(y / (1 - y)), gt_cls_per_image, reduction="none"
).sum(-1)
del cls_preds_
# 候选框里要开始选了,要看他们的IOU情况和分类情况,综合考虑
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_iou_loss
)
matching_matrix = torch.zeros_like(cost, device=device)
for gt_idx in range(num_gt):
# pos_idx:tensor([4,8])
_, pos_idx = torch.topk(
cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False
)
matching_matrix[gt_idx][pos_idx] = 1.0
del top_k, dynamic_ks
anchor_matching_gt = matching_matrix.sum(0) # 竖着加
if (anchor_matching_gt > 1).sum() > 0: # 一个正样本匹配到了多个GT的情况
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0) # 那就比较跟哪个一个损失最小,删除其他
matching_matrix[:, anchor_matching_gt > 1] *= 0.0 # 其他删除
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0 # 最小的那个保留
fg_mask_inboxes = (matching_matrix.sum(0) > 0.0).to(device) # 哪些是正样本
# matched_gt_inds:tensor([0,1,0,1,1])
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0) # 每个正样本对应的真实框索引
from_which_layer = from_which_layer[fg_mask_inboxes]
all_b = all_b[fg_mask_inboxes] # 对应的batch索引
all_a = all_a[fg_mask_inboxes] # 对应的anchor索引
all_gj = all_gj[fg_mask_inboxes]
all_gi = all_gi[fg_mask_inboxes]
all_anch = all_anch[fg_mask_inboxes]
this_target = this_target[matched_gt_inds] # 匹配到正样本的GT
for i in range(nl): # 得到每一层的正样本
layer_idx = from_which_layer == i
matching_bs[i].append(all_b[layer_idx])
matching_as[i].append(all_a[layer_idx])
matching_gjs[i].append(all_gj[layer_idx])
matching_gis[i].append(all_gi[layer_idx])
matching_targets[i].append(this_target[layer_idx])
matching_anchs[i].append(all_anch[layer_idx])
for i in range(nl): # 合并
if matching_targets[i] != []:
matching_bs[i] = torch.cat(matching_bs[i], dim=0)
matching_as[i] = torch.cat(matching_as[i], dim=0)
matching_gjs[i] = torch.cat(matching_gjs[i], dim=0)
matching_gis[i] = torch.cat(matching_gis[i], dim=0)
matching_targets[i] = torch.cat(matching_targets[i], dim=0)
matching_anchs[i] = torch.cat(matching_anchs[i], dim=0)
else:
matching_bs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_as[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_gjs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_gis[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_targets[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
matching_anchs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
return matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs
该代码来自参考链接:
def build_targets(self, predictions, targets, imgs):
#-------------------------------------------#
# 匹配正样本
#-------------------------------------------#
indices, anch = self.find_3_positive(predictions, targets)
matching_bs = [[] for _ in predictions]
matching_as = [[] for _ in predictions]
matching_gjs = [[] for _ in predictions]
matching_gis = [[] for _ in predictions]
matching_targets = [[] for _ in predictions]
matching_anchs = [[] for _ in predictions]
#-------------------------------------------#
# 一共三层
#-------------------------------------------#
num_layer = len(predictions)
#-------------------------------------------#
# 对batch_size进行循环,进行OTA匹配
# 在batch_size循环中对layer进行循环
#-------------------------------------------#
for batch_idx in range(predictions[0].shape[0]):
#-------------------------------------------#
# 先判断匹配上的真实框哪些属于该图片
#-------------------------------------------#
b_idx = targets[:, 0]==batch_idx
this_target = targets[b_idx]
#-------------------------------------------#
# 如果没有真实框属于该图片则continue
#-------------------------------------------#
if this_target.shape[0] == 0:
continue
#-------------------------------------------#
# 真实框的坐标进行缩放
#-------------------------------------------#
txywh = this_target[:, 2:6] * imgs[batch_idx].shape[1]
#-------------------------------------------#
# 从中心宽高到左上角右下角
#-------------------------------------------#
txyxy = self.xywh2xyxy(txywh)
pxyxys = []
p_cls = []
p_obj = []
from_which_layer = []
all_b = []
all_a = []
all_gj = []
all_gi = []
all_anch = []
#-------------------------------------------#
# 对三个layer进行循环
#-------------------------------------------#
for i, prediction in enumerate(predictions):
#-------------------------------------------#
# b代表第几张图片 a代表第几个先验框
# gj代表y轴,gi代表x轴
#-------------------------------------------#
b, a, gj, gi = indices[i]
idx = (b == batch_idx)
b, a, gj, gi = b[idx], a[idx], gj[idx], gi[idx]
all_b.append(b)
all_a.append(a)
all_gj.append(gj)
all_gi.append(gi)
all_anch.append(anch[i][idx])
from_which_layer.append(torch.ones(size=(len(b),)) * i)
#-------------------------------------------#
# 取出这个真实框对应的预测结果
#-------------------------------------------#
fg_pred = prediction[b, a, gj, gi]
p_obj.append(fg_pred[:, 4:5])
p_cls.append(fg_pred[:, 5:])
#-------------------------------------------#
# 获得网格后,进行解码
#-------------------------------------------#
grid = torch.stack([gi, gj], dim=1).type_as(fg_pred)
pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i]
pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i]
pxywh = torch.cat([pxy, pwh], dim=-1)
pxyxy = self.xywh2xyxy(pxywh)
pxyxys.append(pxyxy)
#-------------------------------------------#
# 判断是否存在对应的预测框,不存在则跳过
#-------------------------------------------#
pxyxys = torch.cat(pxyxys, dim=0)
if pxyxys.shape[0] == 0:
continue
#-------------------------------------------#
# 进行堆叠
#-------------------------------------------#
p_obj = torch.cat(p_obj, dim=0)
p_cls = torch.cat(p_cls, dim=0)
from_which_layer = torch.cat(from_which_layer, dim=0)
all_b = torch.cat(all_b, dim=0)
all_a = torch.cat(all_a, dim=0)
all_gj = torch.cat(all_gj, dim=0)
all_gi = torch.cat(all_gi, dim=0)
all_anch = torch.cat(all_anch, dim=0)
#-------------------------------------------------------------#
# 计算当前图片中,真实框与预测框的重合程度
# iou的范围为0-1,取-log后为0~inf
# 重合程度越大,取-log后越小
# 因此,真实框与预测框重合度越大,pair_wise_iou_loss越小
#-------------------------------------------------------------#
pair_wise_iou = self.box_iou(txyxy, pxyxys)
pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8)
#-------------------------------------------#
# 最多二十个预测框与真实框的重合程度
# 然后求和,找到每个真实框对应几个预测框
#-------------------------------------------#
top_k, _ = torch.topk(pair_wise_iou, min(20, pair_wise_iou.shape[1]), dim=1)
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
#-------------------------------------------#
# gt_cls_per_image 种类的真实信息
#-------------------------------------------#
gt_cls_per_image = F.one_hot(this_target[:, 1].to(torch.int64), self.num_classes).float().unsqueeze(1).repeat(1, pxyxys.shape[0], 1)
#-------------------------------------------#
# cls_preds_ 种类置信度的预测信息
# cls_preds_越接近于1,y越接近于1
# y / (1 - y)越接近于无穷大
# 也就是种类置信度预测的越准
# pair_wise_cls_loss越小
#-------------------------------------------#
num_gt = this_target.shape[0]
cls_preds_ = p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() * p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
y = cls_preds_.sqrt_()
pair_wise_cls_loss = F.binary_cross_entropy_with_logits(torch.log(y / (1 - y)), gt_cls_per_image, reduction="none").sum(-1)
del cls_preds_
#-------------------------------------------#
# 求cost的总和
#-------------------------------------------#
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_iou_loss
)
#-------------------------------------------#
# 求cost最小的k个预测框
#-------------------------------------------#
matching_matrix = torch.zeros_like(cost)
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False)
matching_matrix[gt_idx][pos_idx] = 1.0
del top_k, dynamic_ks
#-------------------------------------------#
# 如果一个预测框对应多个真实框
# 只使用这个预测框最对应的真实框
#-------------------------------------------#
anchor_matching_gt = matching_matrix.sum(0)
if (anchor_matching_gt > 1).sum() > 0:
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
matching_matrix[:, anchor_matching_gt > 1] *= 0.0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
#-------------------------------------------#
# 取出符合条件的框
#-------------------------------------------#
from_which_layer = from_which_layer[fg_mask_inboxes]
all_b = all_b[fg_mask_inboxes]
all_a = all_a[fg_mask_inboxes]
all_gj = all_gj[fg_mask_inboxes]
all_gi = all_gi[fg_mask_inboxes]
all_anch = all_anch[fg_mask_inboxes]
this_target = this_target[matched_gt_inds]
for i in range(num_layer):
layer_idx = from_which_layer == i
matching_bs[i].append(all_b[layer_idx])
matching_as[i].append(all_a[layer_idx])
matching_gjs[i].append(all_gj[layer_idx])
matching_gis[i].append(all_gi[layer_idx])
matching_targets[i].append(this_target[layer_idx])
matching_anchs[i].append(all_anch[layer_idx])
for i in range(num_layer):
matching_bs[i] = torch.cat(matching_bs[i], dim=0) if len(matching_bs[i]) != 0 else torch.Tensor(matching_bs[i])
matching_as[i] = torch.cat(matching_as[i], dim=0) if len(matching_as[i]) != 0 else torch.Tensor(matching_as[i])
matching_gjs[i] = torch.cat(matching_gjs[i], dim=0) if len(matching_gjs[i]) != 0 else torch.Tensor(matching_gjs[i])
matching_gis[i] = torch.cat(matching_gis[i], dim=0) if len(matching_gis[i]) != 0 else torch.Tensor(matching_gis[i])
matching_targets[i] = torch.cat(matching_targets[i], dim=0) if len(matching_targets[i]) != 0 else torch.Tensor(matching_targets[i])
matching_anchs[i] = torch.cat(matching_anchs[i], dim=0) if len(matching_anchs[i]) != 0 else torch.Tensor(matching_anchs[i])
return matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs
2、Loss的组成
代码:
def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
# return positive, negative label smoothing BCE targets
return 1.0 - 0.5 * eps, 0.5 * eps
class YOLOLoss(nn.Module):
def __init__(self, anchors, num_classes, input_shape, anchors_mask = [[6,7,8], [3,4,5], [0,1,2]], label_smoothing = 0):
super(YOLOLoss, self).__init__()
#-----------------------------------------------------------#
# 13x13的特征层对应的anchor是[142, 110],[192, 243],[459, 401]
# 26x26的特征层对应的anchor是[36, 75],[76, 55],[72, 146]
# 52x52的特征层对应的anchor是[12, 16],[19, 36],[40, 28]
#-----------------------------------------------------------#
self.anchors = [anchors[mask] for mask in anchors_mask]
self.num_classes = num_classes
self.input_shape = input_shape
self.anchors_mask = anchors_mask
self.balance = [0.4, 1.0, 4]
self.stride = [32, 16, 8]
self.box_ratio = 0.05
self.obj_ratio = 1 * (input_shape[0] * input_shape[1]) / (640 ** 2)
self.cls_ratio = 0.5 * (num_classes / 80)
self.threshold = 4
self.cp, self.cn = smooth_BCE(eps=label_smoothing)
self.BCEcls, self.BCEobj, self.gr = nn.BCEWithLogitsLoss(), nn.BCEWithLogitsLoss(), 1
def bbox_iou(self, box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
box2 = box2.T
if x1y1x2y2:
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else:
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps
iou = inter / union
if GIoU or DIoU or CIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
if DIoU:
return iou - rho2 / c2 # DIoU
elif CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
else: # GIoU https://arxiv.org/pdf/1902.09630.pdf
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU
else:
return iou # IoU
def __call__(self, predictions, targets, imgs):
#-------------------------------------------#
# 对输入进来的预测结果进行reshape
# bs, 255, 20, 20 => bs, 3, 20, 20, 85
# bs, 255, 40, 40 => bs, 3, 40, 40, 85
# bs, 255, 80, 80 => bs, 3, 80, 80, 85
#-------------------------------------------#
for i in range(len(predictions)):
bs, _, h, w = predictions[i].size()
predictions[i] = predictions[i].view(bs, len(self.anchors_mask[i]), -1, h, w).permute(0, 1, 3, 4, 2).contiguous()
#-------------------------------------------#
# 获得工作的设备
#-------------------------------------------#
device = targets.device
#-------------------------------------------#
# 初始化三个部分的损失
#-------------------------------------------#
cls_loss, box_loss, obj_loss = torch.zeros(1, device = device), torch.zeros(1, device = device), torch.zeros(1, device = device)
#-------------------------------------------#
# 进行正样本的匹配
#-------------------------------------------#
bs, as_, gjs, gis, targets, anchors = self.build_targets(predictions, targets, imgs)
#-------------------------------------------#
# 计算获得对应特征层的高宽
#-------------------------------------------#
feature_map_sizes = [torch.tensor(prediction.shape, device=device)[[3, 2, 3, 2]].type_as(prediction) for prediction in predictions]
#-------------------------------------------#
# 计算损失,对三个特征层各自进行处理
#-------------------------------------------#
for i, prediction in enumerate(predictions):
#-------------------------------------------#
# image, anchor, gridy, gridx
#-------------------------------------------#
b, a, gj, gi = bs[i], as_[i], gjs[i], gis[i]
tobj = torch.zeros_like(prediction[..., 0], device=device) # target obj
#-------------------------------------------#
# 获得目标数量,如果目标大于0
# 则开始计算种类损失和回归损失
#-------------------------------------------#
n = b.shape[0]
if n:
prediction_pos = prediction[b, a, gj, gi] # prediction subset corresponding to targets
#-------------------------------------------#
# 计算匹配上的正样本的回归损失
#-------------------------------------------#
#-------------------------------------------#
# grid 获得正样本的x、y轴坐标
#-------------------------------------------#
grid = torch.stack([gi, gj], dim=1)
#-------------------------------------------#
# 进行解码,获得预测结果
#-------------------------------------------#
xy = prediction_pos[:, :2].sigmoid() * 2. - 0.5
wh = (prediction_pos[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
box = torch.cat((xy, wh), 1)
#-------------------------------------------#
# 对真实框进行处理,映射到特征层上
#-------------------------------------------#
selected_tbox = targets[i][:, 2:6] * feature_map_sizes[i]
selected_tbox[:, :2] -= grid.type_as(prediction)
#-------------------------------------------#
# 计算预测框和真实框的回归损失
#-------------------------------------------#
iou = self.bbox_iou(box.T, selected_tbox, x1y1x2y2=False, CIoU=True)
box_loss += (1.0 - iou).mean()
#-------------------------------------------#
# 根据预测结果的iou获得置信度损失的gt
#-------------------------------------------#
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio
#-------------------------------------------#
# 计算匹配上的正样本的分类损失
#-------------------------------------------#
selected_tcls = targets[i][:, 1].long()
t = torch.full_like(prediction_pos[:, 5:], self.cn, device=device) # targets
t[range(n), selected_tcls] = self.cp
cls_loss += self.BCEcls(prediction_pos[:, 5:], t) # BCE
#-------------------------------------------#
# 计算目标是否存在的置信度损失
# 并且乘上每个特征层的比例
#-------------------------------------------#
obj_loss += self.BCEobj(prediction[..., 4], tobj) * self.balance[i] # obj loss
#-------------------------------------------#
# 将各个部分的损失乘上比例
# 全加起来后,乘上batch_size
#-------------------------------------------#
box_loss *= self.box_ratio
obj_loss *= self.obj_ratio
cls_loss *= self.cls_ratio
bs = tobj.shape[0]
loss = box_loss + obj_loss + cls_loss
return loss
def xywh2xyxy(self, x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2]
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def box_iou(self, box1, box2):
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
box1 (Tensor[N, 4])
box2 (Tensor[M, 4])
Returns:
iou (Tensor[N, M]): the NxM matrix containing the pairwise
IoU values for every element in boxes1 and boxes2
"""
def box_area(box):
# box = 4xn
return (box[2] - box[0]) * (box[3] - box[1])
area1 = box_area(box1.T)
area2 = box_area(box2.T)
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)
def build_targets(self, predictions, targets, imgs):
#-------------------------------------------#
# 匹配正样本
#-------------------------------------------#
indices, anch = self.find_3_positive(predictions, targets)
matching_bs = [[] for _ in predictions]
matching_as = [[] for _ in predictions]
matching_gjs = [[] for _ in predictions]
matching_gis = [[] for _ in predictions]
matching_targets = [[] for _ in predictions]
matching_anchs = [[] for _ in predictions]
#-------------------------------------------#
# 一共三层
#-------------------------------------------#
num_layer = len(predictions)
#-------------------------------------------#
# 对batch_size进行循环,进行OTA匹配
# 在batch_size循环中对layer进行循环
#-------------------------------------------#
for batch_idx in range(predictions[0].shape[0]):
#-------------------------------------------#
# 先判断匹配上的真实框哪些属于该图片
#-------------------------------------------#
b_idx = targets[:, 0]==batch_idx
this_target = targets[b_idx]
#-------------------------------------------#
# 如果没有真实框属于该图片则continue
#-------------------------------------------#
if this_target.shape[0] == 0:
continue
#-------------------------------------------#
# 真实框的坐标进行缩放
#-------------------------------------------#
txywh = this_target[:, 2:6] * imgs[batch_idx].shape[1]
#-------------------------------------------#
# 从中心宽高到左上角右下角
#-------------------------------------------#
txyxy = self.xywh2xyxy(txywh)
pxyxys = []
p_cls = []
p_obj = []
from_which_layer = []
all_b = []
all_a = []
all_gj = []
all_gi = []
all_anch = []
#-------------------------------------------#
# 对三个layer进行循环
#-------------------------------------------#
for i, prediction in enumerate(predictions):
#-------------------------------------------#
# b代表第几张图片 a代表第几个先验框
# gj代表y轴,gi代表x轴
#-------------------------------------------#
b, a, gj, gi = indices[i]
idx = (b == batch_idx)
b, a, gj, gi = b[idx], a[idx], gj[idx], gi[idx]
all_b.append(b)
all_a.append(a)
all_gj.append(gj)
all_gi.append(gi)
all_anch.append(anch[i][idx])
from_which_layer.append(torch.ones(size=(len(b),)) * i)
#-------------------------------------------#
# 取出这个真实框对应的预测结果
#-------------------------------------------#
fg_pred = prediction[b, a, gj, gi]
p_obj.append(fg_pred[:, 4:5])
p_cls.append(fg_pred[:, 5:])
#-------------------------------------------#
# 获得网格后,进行解码
#-------------------------------------------#
grid = torch.stack([gi, gj], dim=1).type_as(fg_pred)
pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i]
pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i]
pxywh = torch.cat([pxy, pwh], dim=-1)
pxyxy = self.xywh2xyxy(pxywh)
pxyxys.append(pxyxy)
#-------------------------------------------#
# 判断是否存在对应的预测框,不存在则跳过
#-------------------------------------------#
pxyxys = torch.cat(pxyxys, dim=0)
if pxyxys.shape[0] == 0:
continue
#-------------------------------------------#
# 进行堆叠
#-------------------------------------------#
p_obj = torch.cat(p_obj, dim=0)
p_cls = torch.cat(p_cls, dim=0)
from_which_layer = torch.cat(from_which_layer, dim=0)
all_b = torch.cat(all_b, dim=0)
all_a = torch.cat(all_a, dim=0)
all_gj = torch.cat(all_gj, dim=0)
all_gi = torch.cat(all_gi, dim=0)
all_anch = torch.cat(all_anch, dim=0)
#-------------------------------------------------------------#
# 计算当前图片中,真实框与预测框的重合程度
# iou的范围为0-1,取-log后为0~inf
# 重合程度越大,取-log后越小
# 因此,真实框与预测框重合度越大,pair_wise_iou_loss越小
#-------------------------------------------------------------#
pair_wise_iou = self.box_iou(txyxy, pxyxys)
pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8)
#-------------------------------------------#
# 最多二十个预测框与真实框的重合程度
# 然后求和,找到每个真实框对应几个预测框
#-------------------------------------------#
top_k, _ = torch.topk(pair_wise_iou, min(20, pair_wise_iou.shape[1]), dim=1)
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
#-------------------------------------------#
# gt_cls_per_image 种类的真实信息
#-------------------------------------------#
gt_cls_per_image = F.one_hot(this_target[:, 1].to(torch.int64), self.num_classes).float().unsqueeze(1).repeat(1, pxyxys.shape[0], 1)
#-------------------------------------------#
# cls_preds_ 种类置信度的预测信息
# cls_preds_越接近于1,y越接近于1
# y / (1 - y)越接近于无穷大
# 也就是种类置信度预测的越准
# pair_wise_cls_loss越小
#-------------------------------------------#
num_gt = this_target.shape[0]
cls_preds_ = p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() * p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
y = cls_preds_.sqrt_()
pair_wise_cls_loss = F.binary_cross_entropy_with_logits(torch.log(y / (1 - y)), gt_cls_per_image, reduction="none").sum(-1)
del cls_preds_
#-------------------------------------------#
# 求cost的总和
#-------------------------------------------#
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_iou_loss
)
#-------------------------------------------#
# 求cost最小的k个预测框
#-------------------------------------------#
matching_matrix = torch.zeros_like(cost)
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False)
matching_matrix[gt_idx][pos_idx] = 1.0
del top_k, dynamic_ks
#-------------------------------------------#
# 如果一个预测框对应多个真实框
# 只使用这个预测框最对应的真实框
#-------------------------------------------#
anchor_matching_gt = matching_matrix.sum(0)
if (anchor_matching_gt > 1).sum() > 0:
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
matching_matrix[:, anchor_matching_gt > 1] *= 0.0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
#-------------------------------------------#
# 取出符合条件的框
#-------------------------------------------#
from_which_layer = from_which_layer[fg_mask_inboxes]
all_b = all_b[fg_mask_inboxes]
all_a = all_a[fg_mask_inboxes]
all_gj = all_gj[fg_mask_inboxes]
all_gi = all_gi[fg_mask_inboxes]
all_anch = all_anch[fg_mask_inboxes]
this_target = this_target[matched_gt_inds]
for i in range(num_layer):
layer_idx = from_which_layer == i
matching_bs[i].append(all_b[layer_idx])
matching_as[i].append(all_a[layer_idx])
matching_gjs[i].append(all_gj[layer_idx])
matching_gis[i].append(all_gi[layer_idx])
matching_targets[i].append(this_target[layer_idx])
matching_anchs[i].append(all_anch[layer_idx])
for i in range(num_layer):
matching_bs[i] = torch.cat(matching_bs[i], dim=0) if len(matching_bs[i]) != 0 else torch.Tensor(matching_bs[i])
matching_as[i] = torch.cat(matching_as[i], dim=0) if len(matching_as[i]) != 0 else torch.Tensor(matching_as[i])
matching_gjs[i] = torch.cat(matching_gjs[i], dim=0) if len(matching_gjs[i]) != 0 else torch.Tensor(matching_gjs[i])
matching_gis[i] = torch.cat(matching_gis[i], dim=0) if len(matching_gis[i]) != 0 else torch.Tensor(matching_gis[i])
matching_targets[i] = torch.cat(matching_targets[i], dim=0) if len(matching_targets[i]) != 0 else torch.Tensor(matching_targets[i])
matching_anchs[i] = torch.cat(matching_anchs[i], dim=0) if len(matching_anchs[i]) != 0 else torch.Tensor(matching_anchs[i])
return matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs
def find_3_positive(self, predictions, targets):
#------------------------------------#
# 获得每个特征层先验框的数量
# 与真实框的数量
#------------------------------------#
num_anchor, num_gt = len(self.anchors_mask[0]), targets.shape[0]
#------------------------------------#
# 创建空列表存放indices和anchors
#------------------------------------#
indices, anchors = [], []
#------------------------------------#
# 创建7个1
# 序号0,1为1
# 序号2:6为特征层的高宽
# 序号6为1
#------------------------------------#
gain = torch.ones(7, device=targets.device)
#------------------------------------#
# ai [num_anchor, num_gt]
# targets [num_gt, 6] => [num_anchor, num_gt, 7]
#------------------------------------#
ai = torch.arange(num_anchor, device=targets.device).float().view(num_anchor, 1).repeat(1, num_gt)
targets = torch.cat((targets.repeat(num_anchor, 1, 1), ai[:, :, None]), 2) # append anchor indices
g = 0.5 # offsets
off = torch.tensor([
[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g
for i in range(len(predictions)):
#----------------------------------------------------#
# 将先验框除以stride,获得相对于特征层的先验框。
# anchors_i [num_anchor, 2]
#----------------------------------------------------#
anchors_i = torch.from_numpy(self.anchors[i] / self.stride[i]).type_as(predictions[i])
#-------------------------------------------#
# 计算获得对应特征层的高宽
#-------------------------------------------#
gain[2:6] = torch.tensor(predictions[i].shape)[[3, 2, 3, 2]]
#-------------------------------------------#
# 将真实框乘上gain,
# 其实就是将真实框映射到特征层上
#-------------------------------------------#
t = targets * gain
if num_gt:
#-------------------------------------------#
# 计算真实框与先验框高宽的比值
# 然后根据比值大小进行判断,
# 判断结果用于取出,获得所有先验框对应的真实框
# r [num_anchor, num_gt, 2]
# t [num_anchor, num_gt, 7] => [num_matched_anchor, 7]
#-------------------------------------------#
r = t[:, :, 4:6] / anchors_i[:, None]
j = torch.max(r, 1. / r).max(2)[0] < self.threshold
t = t[j] # filter
#-------------------------------------------#
# gxy 获得所有先验框对应的真实框的x轴y轴坐标
# gxi 取相对于该特征层的右小角的坐标
#-------------------------------------------#
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
#-------------------------------------------#
# t 重复5次,使用满足条件的j进行框的提取
# j 一共五行,代表当前特征点在五个
# [0, 0], [1, 0], [0, 1], [-1, 0], [0, -1]
# 方向是否存在
#-------------------------------------------#
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
#-------------------------------------------#
# b 代表属于第几个图片
# gxy 代表该真实框所处的x、y中心坐标
# gwh 代表该真实框的wh坐标
# gij 代表真实框所属的特征点坐标
#-------------------------------------------#
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices
#-------------------------------------------#
# gj、gi不能超出特征层范围
# a代表属于该特征点的第几个先验框
#-------------------------------------------#
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
anchors.append(anchors_i[a]) # anchors
return indices, anchors
四、部署
注意: YoloV7模型转onnx,需要onnx的版本为1.8.1
安装onnx:
pip3 install onnx==1.8.1
pt文件转onnx文件:
python3 export.py --weights "/home/myproject/YoloV7_office_main/YoloV7-office-main-knife/finetune_knife_test/runs/train/yolov7/weights/epoch_399.pt" --grid --end2end --simplify --topk-all 100 --iou-thres 0.65 --conf-thres 0.35 --img-size 384 384 --max-wh 384


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









