









文章目录
CenterNet网络框架:
1、CornerNet 和ExtremeNet
CornerNet :预测左上角的点和右下角的点,共2个点;
ExtremeNet:预测最上面的点,最下面的点,最左边的点,最右边的点,中间的点,共5个点;

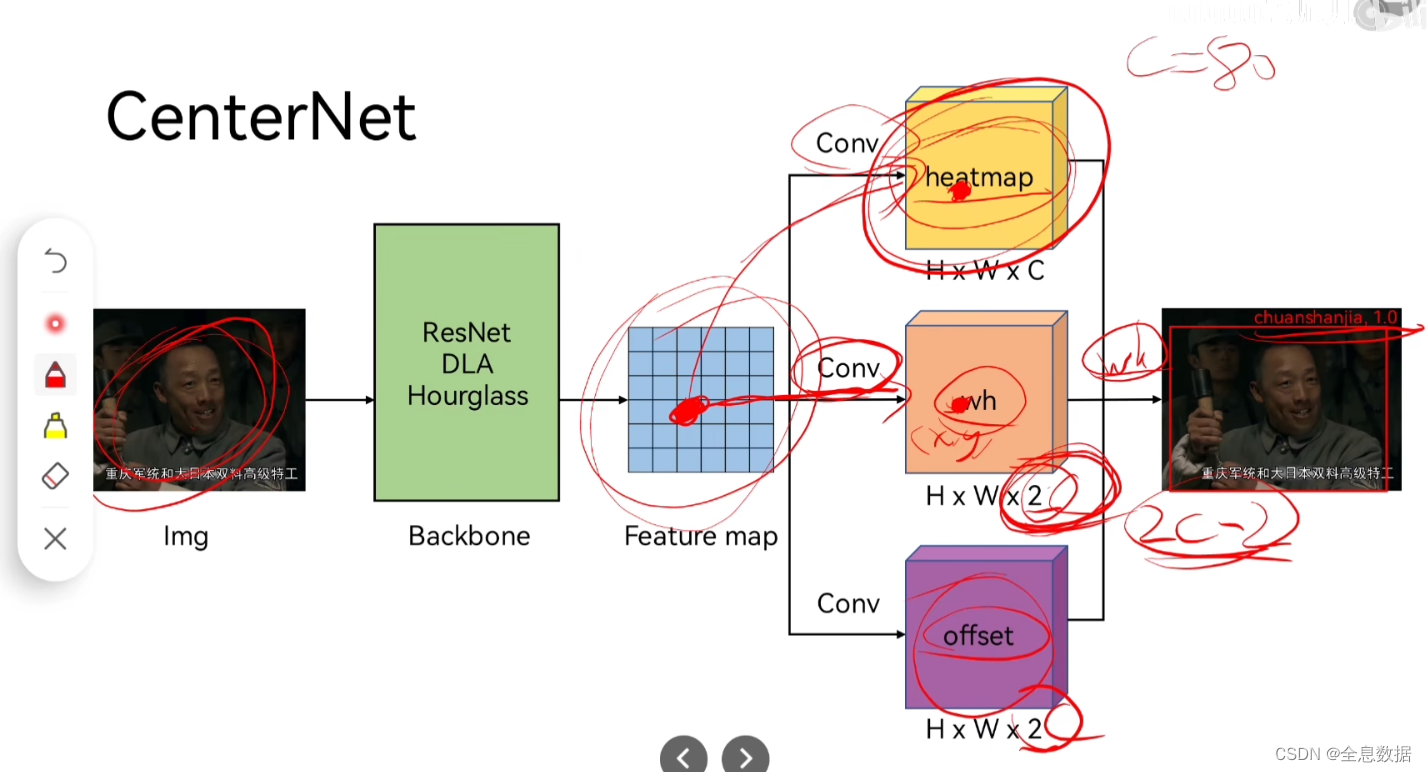
2、CenterNet模型流程
CenterNet预测中心点,中线点的宽高,中心点的残差;如下图,H x W x C中的C是类别数,
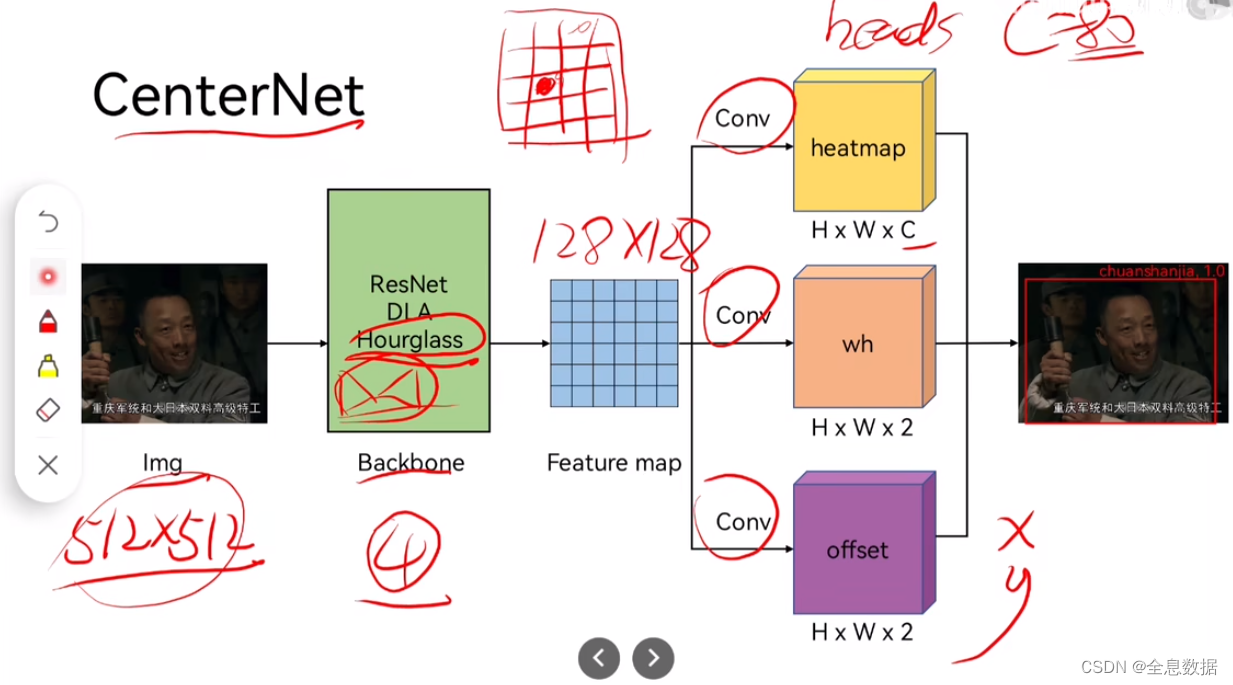
问题:为什么输出heads的wh和offset是2个通道,而不是2
×
\times
×C呢?
答:因为在预测heatmap的时候会进行一些操作后,只取1个点,所以wh和offset只需预测2个通道。
优势:CenterNet会比基于anchor的检测模型减少误检
3、Backbone
Hourglass:主要用于关键点检测,效果好,缺点是权重多
Resnet:速度快,但效果不好
DLA:折中的方案
4、Heatmap与Loss
4.1 如何规定Heatmap GroundTruth
网络在预测heatmap中心点的时候,不是只在一个点为1,其他点为0;而是一个高斯分布,类似于山峰的形状,只要预测的中心点在这个高斯分布区域里面就可以
高斯分布的公式:
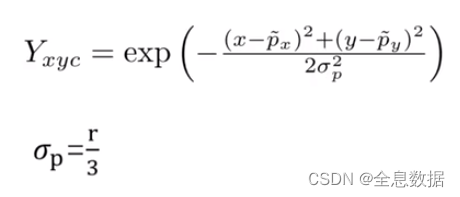
下面求出
r
\ r
r ,分为3种情况,下面依次介绍,
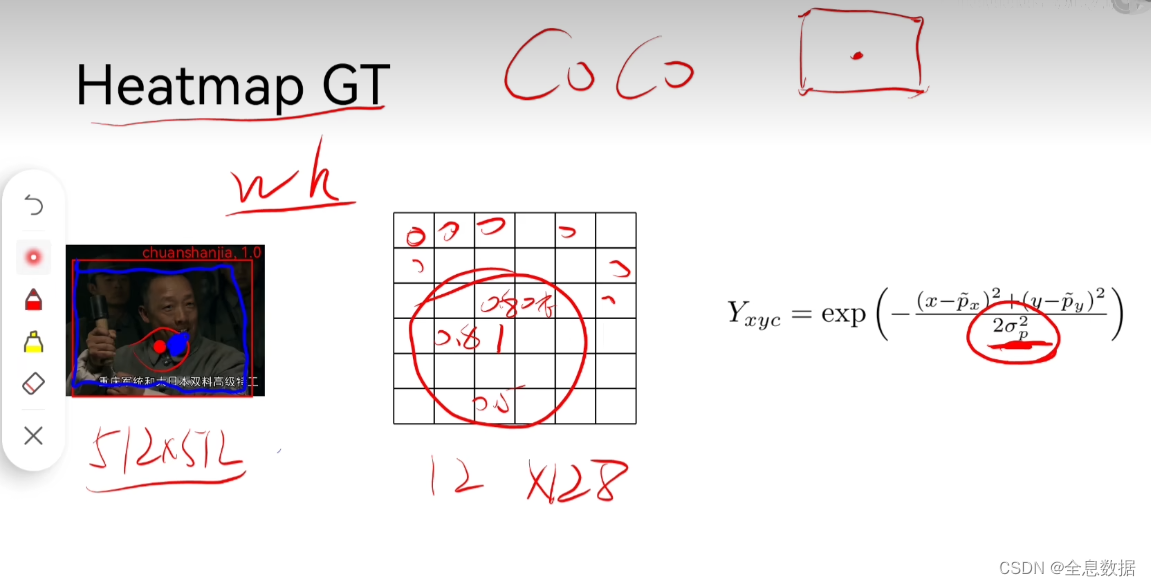
首先介绍一下CornerNet,红框是GroundTruth,绿框是预测的,则预测框和GT有3种情形,分别计算IOU(3种情形的IOU保持一致),这里取IOU为0.7,再求出半径 r ,然后选出3种 r 的 最小值 。

(1)GT在预测框之内
overlap相当于IOU
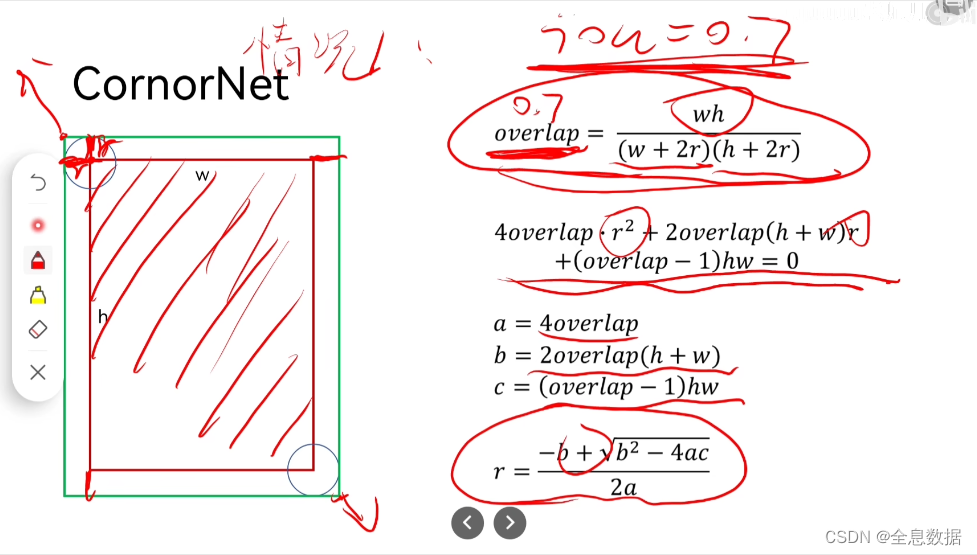
(2) GT在预测框之外
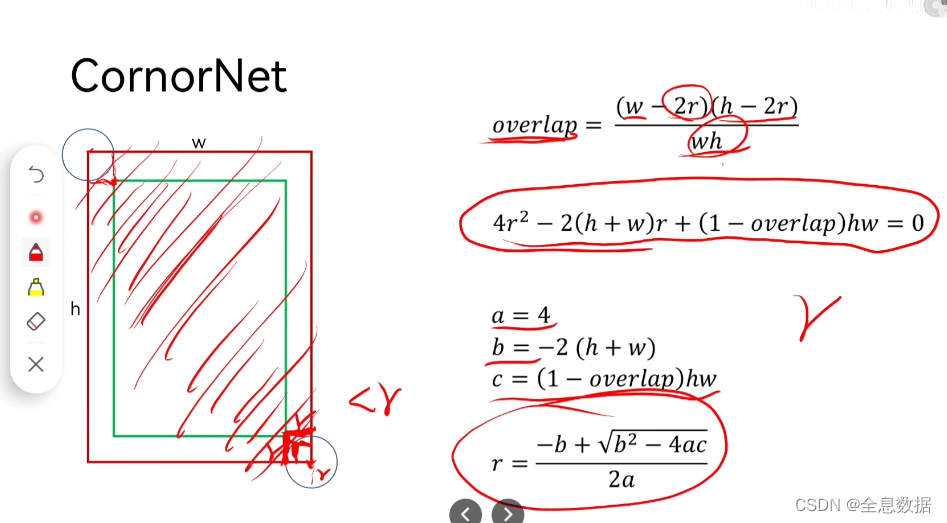 (3)GT和预测框重叠,注意GT与预测框的wh是一样的,
(3)GT和预测框重叠,注意GT与预测框的wh是一样的,

4.2 Heatmap Loss
这是原始的Focal Loss, Y ^ \hat{Y} Y^是predict, Y Y Y是GT,
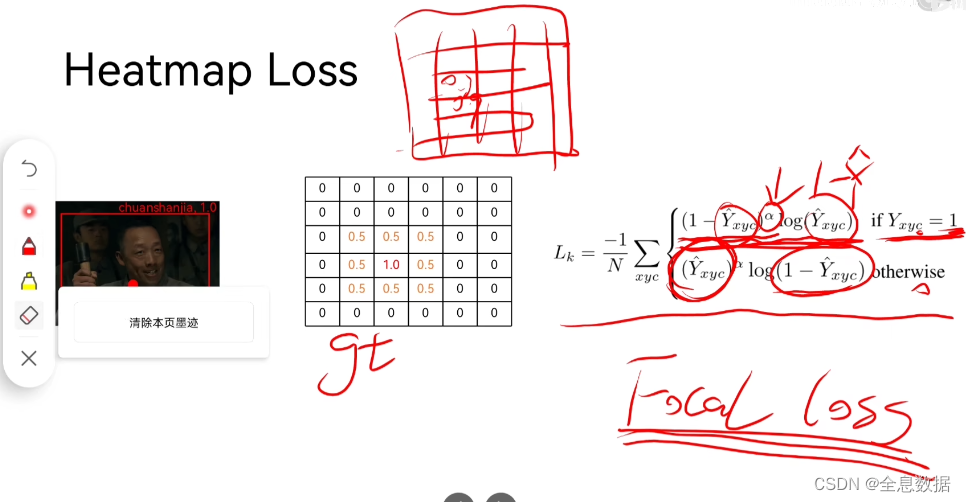
这是改进后的Focal Loss,即GT越接近于1,
(
1
−
Y
x
y
c
)
β
(1-Y_{xyc})^\beta
(1−Yxyc)β越小,相应的非正样本的Loss就越小,
α
\alpha
α和
β
\beta
β是超参数,
为什么要在前面乘以
(
1
−
Y
x
y
c
)
β
(1-Y_{xyc})^\beta
(1−Yxyc)β?我的答案:想让网络较少地学习接近于1的参数,这样网络就会较多地学习
Y
x
y
c
=
1
Y_{xyc}=1
Yxyc=1时的参数。

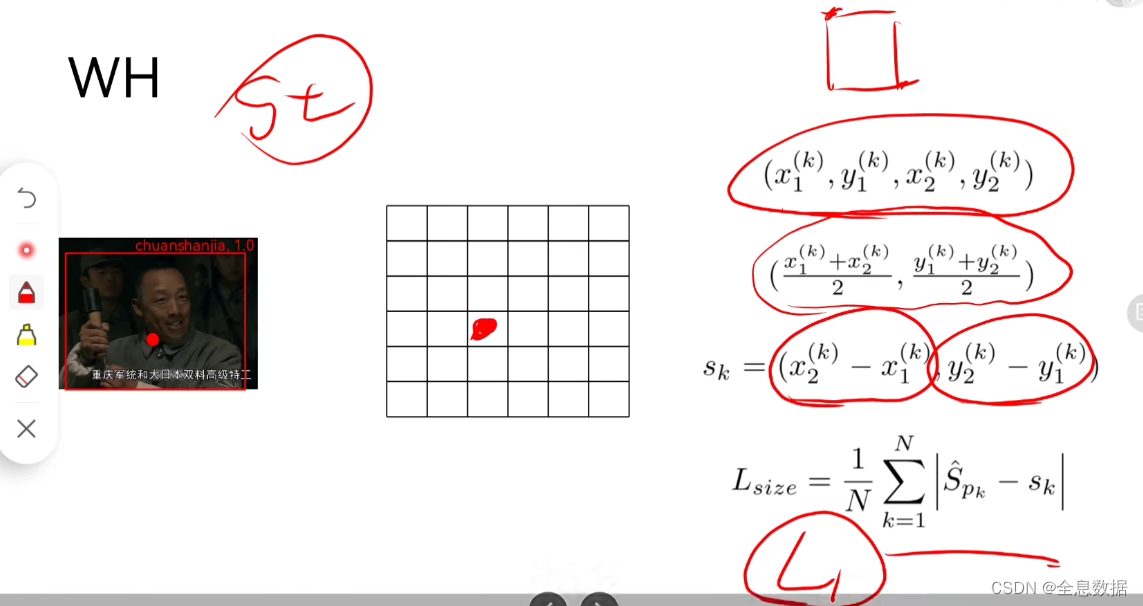
4.3 WH Loss
采用的是L1 Loss,
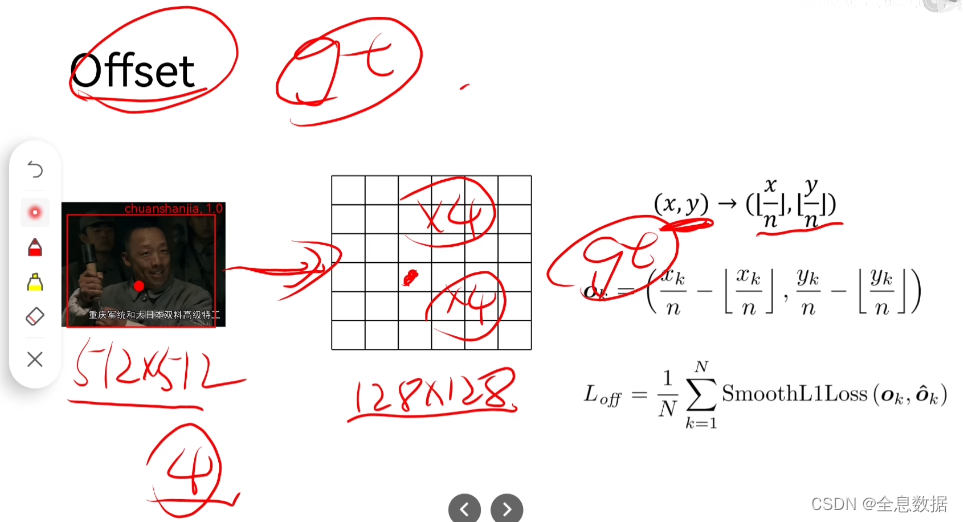
4.4 offse Loss
比如原图是512x512,进行4倍下采样后变成128x128,然后再乘4倍后一定会有精度的损失,所以需要计算offset的回归,
x
k
n
\frac{x_k}{n}
nxk是没有损失精度的float类型,
[
x
k
n
]
[\frac{x_k}{n}]
[nxk]是int类型,是损失精度的,
4.5 Total Loss 和 decode
Loss包括Heatmap Loss,宽高的Loss,为了避免检测大物体的影响,需要在前面乘以 λ s i z e \lambda_{size} λsize, λ s i z e \lambda_{size} λsize设置为0.1,以及offset Loss;
下面2行是解码过程;


















 1551
1551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









