







Scrapy爬百度图片(一)
本人小白一个,最近初学scrapy,所以边学边记录咯!
Scrapy入门
关于这部分我不能提供更多帮助哈哈哈!参考http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/overview.html
获取图片URL
要爬取百度图片当然要知道图片的地址啦!地址怎么来呢?F12总懂了吧哈哈哈!来吧!我们先上图吧!这里已firefox为例,其实chrome也差不多。
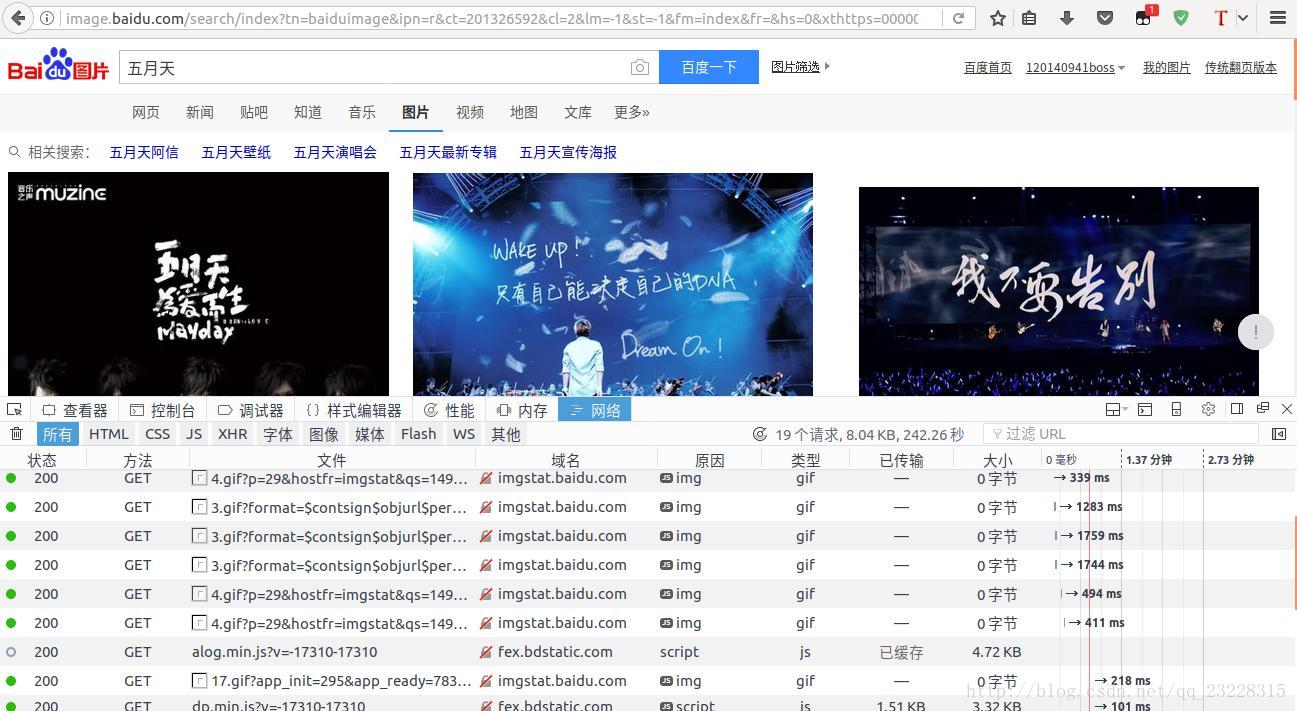
作为一个五月天的死忠,怎么能放弃这个秀偶像的机会呢?这个就是firefox自带的开发者工具了,大家应该都懂的。那图片路径到底在哪呢?根据经验来说,一个Ajax异步加载的网站,图片的路径是保存在json里的。json是什么呢?JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。json在哪里查看呢?
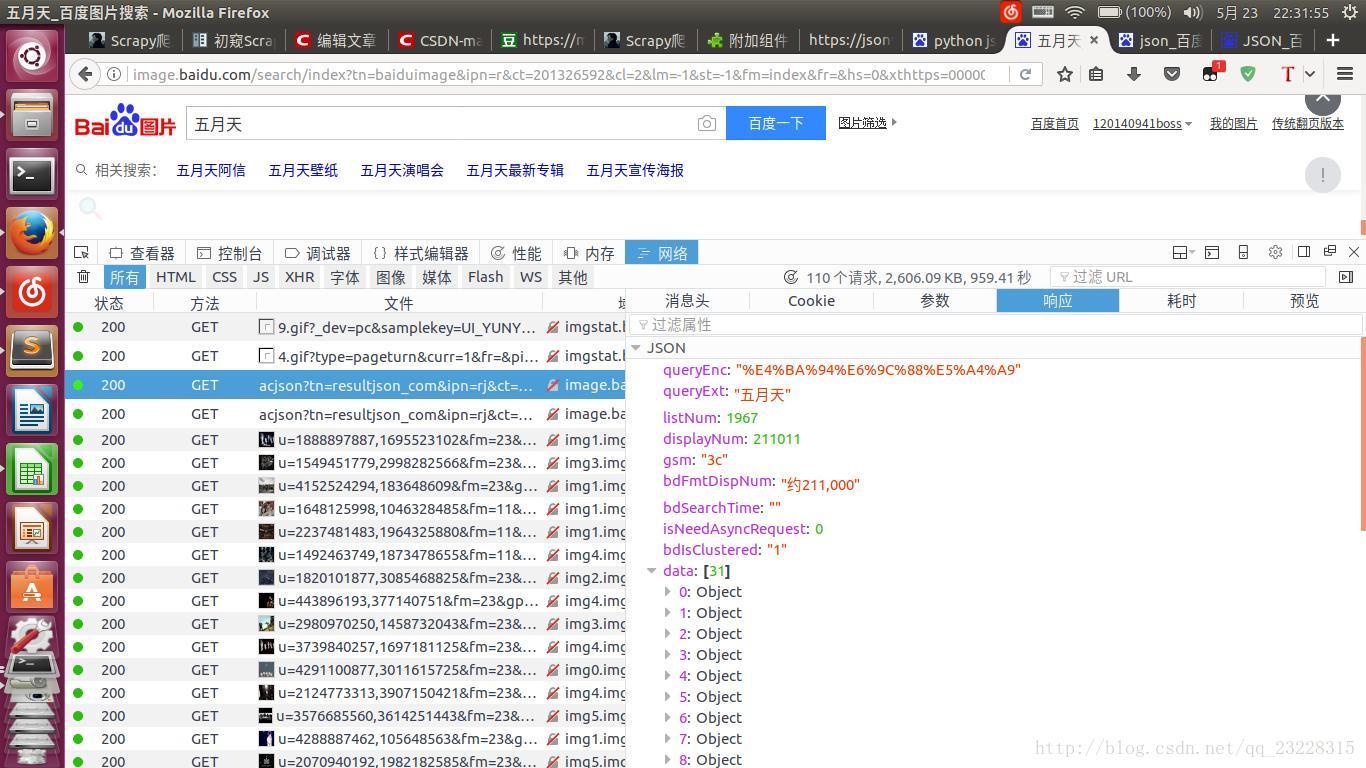
找到没?http状态码200,响应返回的是json文件。让我们来看看它的地址,消息头那里面哦!http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=五月天&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=五月天&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&cg=star&pn=30&rn=30&gsm=1e&1495549541143=
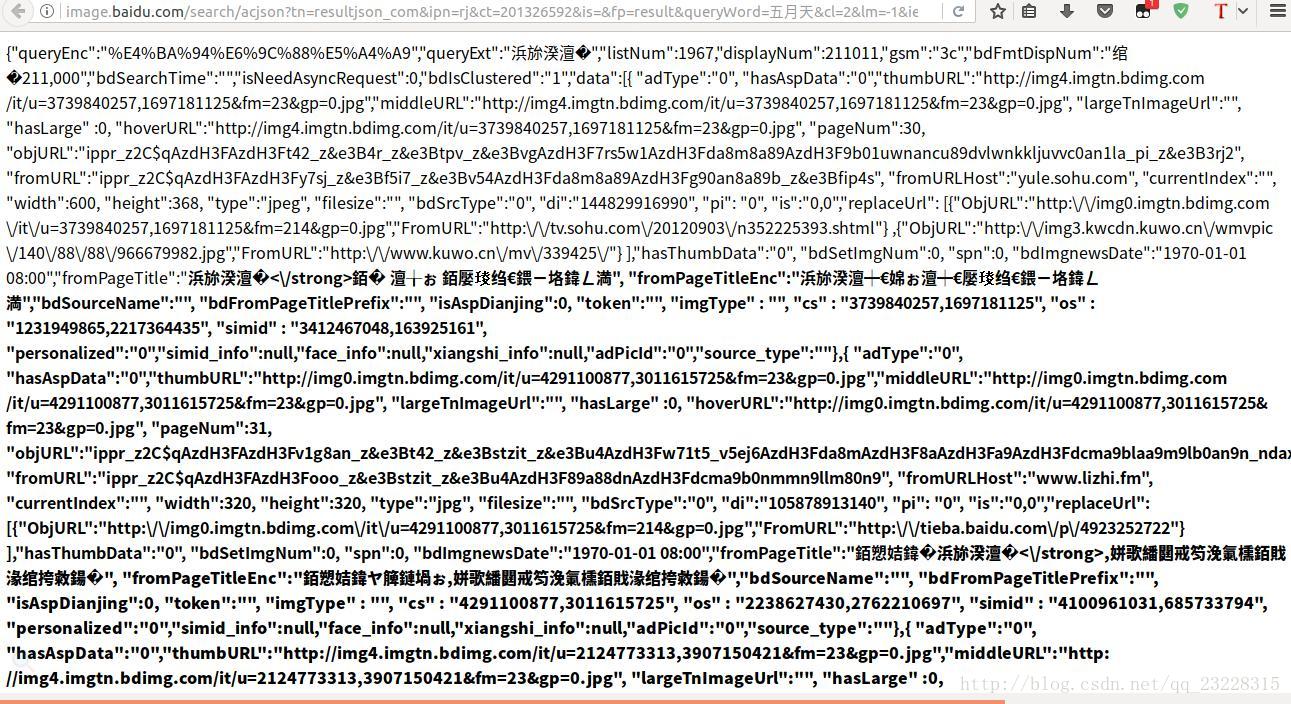
在浏览器里打开这个链接地址,我们可以看到这是一个json文件哟!
那我们要怎么来处理这些json文件呢?我们这里用到的是python的json库。首先,你要在项目的setting.py里把ROBOTSTXT—OBEY设置为False。scrapy在爬取网站时,会遵循robots.txt里的规则,不爬取它禁止的特定内容。当你把它设置为False时,爬虫会不遵循这个准则。那我们来利用spider的调试器来解析一下json。我们在命令行输入”scrapy shell ” 就是刚才那个json地址。下面就是调试结果,高亮部分就是图片地址。
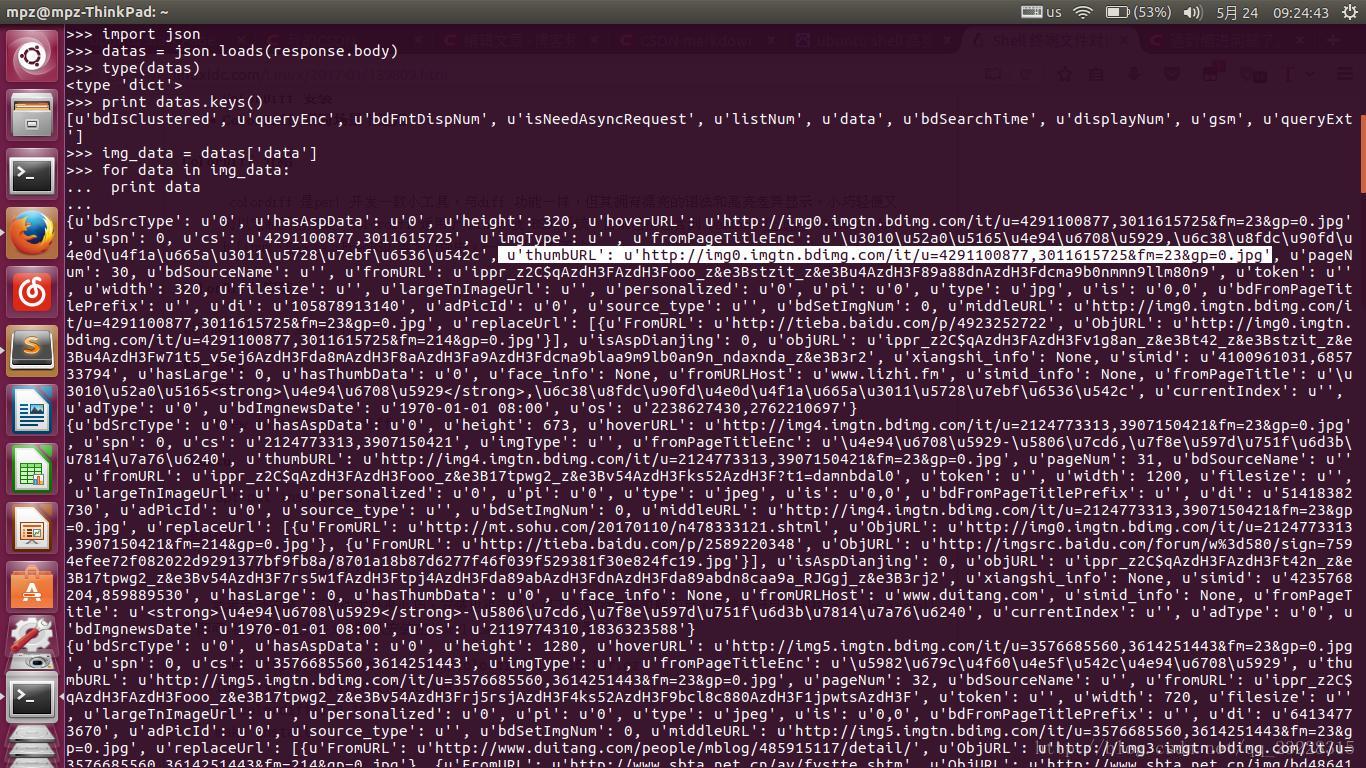
我再提取出key=thumbURL的部分
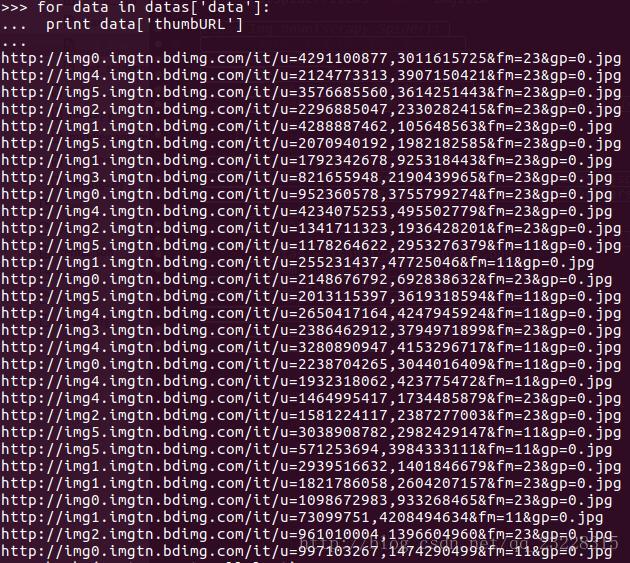
好了,第一部分内容就讲到这了,我们已经可以提取出图片的URL了。请大家敬请期待下一部分哦!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









