







scrapy模块
安装
使用cmd控制台查看scrapy是否安装,没有就安装完再查看。
>conda list
>conda install scrapy
>conda list
创建项目
使用window powershell控制台,先跳转到pycharm项目地址,然后创建项目hello。
创建完成后进入hello目录确定项目主题为dingdian,完成项目创建。
>cd d:
>cd D:\py-workplace
>scrapy startproject hello
>cd hello
>scrapy genspider dingdian wwwwww
打开pycharm,看到项目hello打开。
使用项目
安装
在pycharm的控制台也需要安装scrapy
>pip install scrapy
会有安装提示
Installing collected packages: zope.interface, w3lib, twisted-iocpsupport,
pyasn1, lxml, incremental, hyperlink, hyperframe, hpack, cssselect,
constantly, Automat, Twisted, pyasn1-modules, priority, parsel, jmespath,
itemadapter, h2, service-identity, queuelib, PyDispatcher, protego,
itemloaders, scrapy
原理
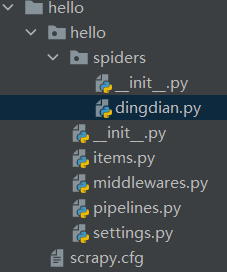
爬虫文件在如图dingdian.py文件书写,items.py用于临时存储,middlewares.py中间件,pipelines.py下载管道,settings.py配置文件。
取自Scrapy工作原理

Scrapy Engine:Scrapy引擎
Scheduler:调度器
Downloader:下载器
Spider:爬虫
Item Pipeline:存储数据临时点+管道
Downloader Middlewares:下载中间件
Spider Middlewares:爬虫中间件
Spider爬虫url -> Scrapy引擎 -> Scheduler安排任务request -> Scrapy引擎 -> Downloader Middlewares增加header的cookie等 -> Downloader下载返回response ->Downloader Middlewares判断数据是否有效 -> Scrapy引擎 -> Spider分析数据 -> Scrapy引擎 -&g
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









