







Map
Map是一种把键对象和值对象进行关联的容器
一个值对象又可以是一个Map,依次类推,这样就可形成一个多级映射。对于键对象来说,像Set一样,一个Map容器中的键对象不允许重复,这是为了保持查找结果的一致性;如果有两个键对象一样,那你想得到那个键对象所对应的值对象时就有问题了,可能你得到的并不是你想的那个值对象,结果会造成混乱,所以键的唯一性很重要,也是符合集合的性质的。当然在使用过程中,某个键所对应的值对象可能会发生变化,这时会按照最后一次修改的值对象与键对应。对于值对象则没有唯一性的要求。你可以将任意多个键都映射到一个值对象上,这不会发生任何问题(不过对你的使用却可能会造成不便,你不知道你得到的到底是那一个键所对应的值对象)。Map有两种比较常用的实现:HashMap和TreeMap。HashMap也用到了哈希码的算法,以便快速查找一个键,TreeMap则是对键按序存放,因此它便有一些扩展的方法,比如firstKey(),lastKey()等,你还可以从TreeMap中指定一个范围以取得其子Map。键和值的关联很简单,用put(Object key,Object value)方法即可将一个键与一个值对象相关联。用get(Object key)可得到与此key对象所对应的值对象。
Map的功能
ArrayList能让你用数字在一个对象序列里面进行选择,所以从某种意义上讲,它是将数字和对象关联起来。但是,如果你想根据其他条件在一个对象序列里面进行选择的话,那又该怎么做呢?栈就是一个例子。它的标准是“选取最后一个被压入栈的对象”。我们常用的术语map,dictionary,或associative array就是一种非常强大的,能在序列里面进行挑选的工具。从概念上讲,它看上去像是一个ArrayList,但它不用数字,而是用另一个对象来查找对象!这是一种至关重要的编程技巧。(就是一个映射,键有点类似于数据库的主键,值有点类似于对应的表)
这一概念在Java中表现为Map。put(Object key, Object value)方法会往Map里面加一个值,并且把这个值同键(你查找时所用的对象)联系起来。给出键之后,get(Object key)就会返回与之相关的值。你也可以用containsKey()和containsValue()测试Map是否包含有某个键或值。
Java标准类库里有好几种Map:HashMap,TreeMap,LinkedHashMap,WeakHashMap,以及IdentityHashMap。它们都实现了Map的基本接口,但是在行为方式方面有着明显的诧异。这些差异体现在,效率,持有和表示对象pair的顺序,持有对象的时间长短,以及如何决定键的相等性。
性能是Map所要面对的一个大问题。如果你知道get()时怎么工作的,你就会发觉(比方说)在ArrayList里面找对象会是相当慢的。而这正是HashMap的强项。它不是慢慢地一个个地找这个键,而是用了一种被称为hash code的特殊值(hashcode具体参见:http://blog.csdn.net/qq_23473123/article/details/51111323)来进行查找的。散列(hash)是一种算法,它会从目标对象当中提取一些信息,然后生成一个表示这个对象的“相对独特”的int。hashCode()是Object根类的方法,因此所有Java对象都能生成hash code。HashMap则利用对象的hashCode()来进行快速的查找。这样性能就有了急剧的提高。
Map(接口):维持键--值的关系(既pairs),这样就能用键来找值了。
HashMap
:HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
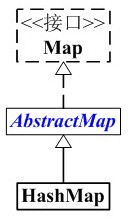
HashMap的继承关系:

HashMap与Map关系如下图:
代码示例:
import java.util.Map;
import java.util.Random;
import java.util.Iterator;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map.Entry;
import java.util.Collection;
public class HashMapTest {
public static void main(String[] args) {
testHashMapAPIs();
}
private static void testHashMapAPIs() {
// 初始化随机种子
Random r = new Random();
// 新建HashMap
HashMap map = new HashMap();
// 添加操作
map.put("one", r.nextInt(10));
map.put("two", r.nextInt(10));
map.put("three", r.nextInt(10));
// 打印出map
System.out.println("map:"+map );
// 通过Iterator遍历key-value
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
System.out.println("next : "+ entry.getKey() +" - "+entry.getValue());
}
// HashMap的键值对个数
System.out.println("size:"+map.size());
// containsKey(Object key) :是否包含键key
System.out.println("contains key two : "+map.containsKey("two"));
System.out.println("contains key five : "+map.containsKey("five"));
// containsValue(Object value) :是否包含值value
System.out.println("contains value 0 : "+map.containsValue(new Integer(0)));
// remove(Object key) : 删除键key对应的键值对
map.remove("three");
System.out.println("map:"+map );
// clear() : 清空HashMap
map.clear();
// isEmpty() : HashMap是否为空
System.out.println((map.isEmpty()?"map is empty":"map is not empty") );
}
}Hashtable
Hashtable 和 HashMap 的主要区别在于 Hashtable 是线程同步的, 除此之外, Hashtable 不允许有 Null 值和 Null 键.
LinkedHashMap
:很像HashMap,但是用Iterator进行遍历的时候,它会按插入顺序或最先使用的顺序(least-recently-used(LRU)order)进行访问。除了用Iterator外,其他情况下,只是比HashMap稍慢一点。
LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
构造方法和方法摘要:
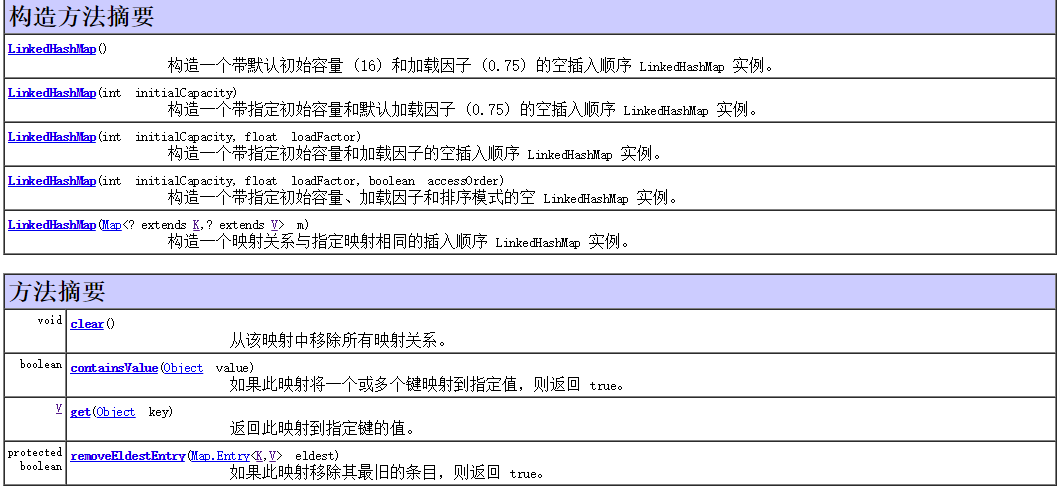
initialCapacity - 初始容量
loadFactor - 加载因子
accessOrder - 排序模式 - 对于访问顺序,为 true;对于插入顺序,则为 false
当accessOrder为false时:
每当访问其中的元素时, 该元素就会从当前的位置移到链表的尾部, 由此我们可以知道, 离链表开头越近的元素使用的最少, 这就是传说中的“最少最近原则”, 这个特性对于实现高速缓存非常有用, 例如, 我们可能希望将最常访问的元素放到缓存中, 而将不长访问的元素放到数据库中.
示例代码:
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ConcurrentLinkedQueue;
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap<Integer, People> map = new LinkedHashMap<Integer, People>(16, (float) 0.75, false);
People p1 = new People("robin", 1, 28);
People p2 = new People("robin", 2, 29);
People p3 = new People("harry", 3, 30);
map.put(new Integer(100), p1);
map.put(new Integer(1), p3);
map.put(new Integer(2), null);
map.put(new Integer(100), p2);
for (People p : map.values()) {
System.out.println("people:" + p);
}
}
}
class People {
String name;
int id;
int age;
public People(String name, int id) {
this(name, id, 0);
}
public People(String name, int id, int age) {
this.name = name;
this.id = id;
this.age = age;
}
public String toString() {
return id + name + age;
}
public boolean equals(Object o) {
if (o == null)
return false;
if (!(o instanceof People))
return false;
People p = (People) o;
boolean res = name.equals(p.name);
if (res)
System.out.println("name " + name + " is double");
else
System.out.println(name + " vS " + p.name);
return res;
}
public int hashCode() {
return name.hashCode();
}
}注意,此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须 保持外部同步。这一般通过对自然封装该映射的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedMap 方法来“包装”该映射。最好在创建时完成这一操作,以防止对映射的意外的非同步访问:
Map m = Collections.synchronizedMap(new LinkedHashMap(...));TreeMap
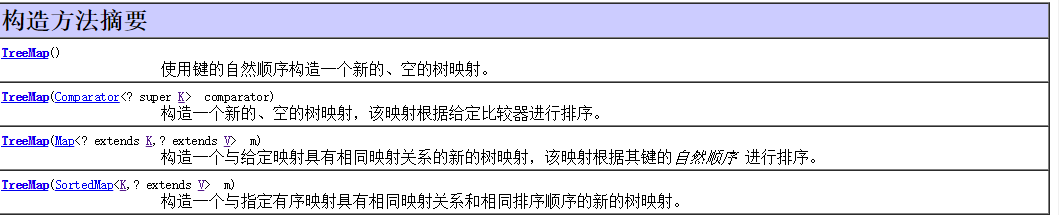
:基于红黑树数据结构的实现。当你查看键或pair时,会发现它们是按顺序(根据Comparable或Comparator)排列的。TreeMap的特点是,你所得到的是一个有序的Map。TreeMap是Map中唯一有subMap()方法的实现。这个方法能让你获取这个树中的一部分。
构造方法:
方法摘要:
Map.Entry<K,V> ceilingEntry(K key)
返回一个键-值映射关系,它与大于等于给定键的最小键关联;如果不存在这样的键,则返回 null。
K ceilingKey(K key)
返回大于等于给定键的最小键;如果不存在这样的键,则返回 null。
void clear()
从此映射中移除所有映射关系。
Object clone()
返回此 TreeMap 实例的浅表副本。
Comparator<? super K> comparator()
返回对此映射中的键进行排序的比较器;如果此映射使用键的自然顺序,则返回 null。
boolean containsKey(Object key)
如果此映射包含指定键的映射关系,则返回 true。
boolean containsValue(Object value)
如果此映射为指定值映射一个或多个键,则返回 true。
NavigableSet<K> descendingKeySet()
返回此映射中所包含键的逆序 NavigableSet 视图。
NavigableMap<K,V> descendingMap()
返回此映射中所包含映射关系的逆序视图。
Set<Map.Entry<K,V>> entrySet()
返回此映射中包含的映射关系的 Set 视图。
Map.Entry<K,V> firstEntry()
返回一个与此映射中的最小键关联的键-值映射关系;如果映射为空,则返回 null。
K firstKey()
返回此映射中当前第一个(最低)键。
Map.Entry<K,V> floorEntry(K key)
返回一个键-值映射关系,它与小于等于给定键的最大键关联;如果不存在这样的键,则返回 null。
K floorKey(K key)
返回小于等于给定键的最大键;如果不存在这样的键,则返回 null。
V get(Object key)
返回指定键所映射的值,如果对于该键而言,此映射不包含任何映射关系,则返回 null。
SortedMap<K,V> headMap(K toKey)
返回此映射的部分视图,其键值严格小于 toKey。
NavigableMap<K,V> headMap(K toKey, boolean inclusive)
返回此映射的部分视图,其键小于(或等于,如果 inclusive 为 true)toKey。
Map.Entry<K,V> higherEntry(K key)
返回一个键-值映射关系,它与严格大于给定键的最小键关联;如果不存在这样的键,则返回 null。
K higherKey(K key)
返回严格大于给定键的最小键;如果不存在这样的键,则返回 null。
Set<K> keySet()
返回此映射包含的键的 Set 视图。
Map.Entry<K,V> lastEntry()
返回与此映射中的最大键关联的键-值映射关系;如果映射为空,则返回 null。
K lastKey()
返回映射中当前最后一个(最高)键。
Map.Entry<K,V> lowerEntry(K key)
返回一个键-值映射关系,它与严格小于给定键的最大键关联;如果不存在这样的键,则返回 null。
K lowerKey(K key)
返回严格小于给定键的最大键;如果不存在这样的键,则返回 null。
NavigableSet<K> navigableKeySet()
返回此映射中所包含键的 NavigableSet 视图。
Map.Entry<K,V> pollFirstEntry()
移除并返回与此映射中的最小键关联的键-值映射关系;如果映射为空,则返回 null。
Map.Entry<K,V> pollLastEntry()
移除并返回与此映射中的最大键关联的键-值映射关系;如果映射为空,则返回 null。
V put(K key, V value)
将指定值与此映射中的指定键进行关联。
void putAll(Map<? extends K,? extends V> map)
将指定映射中的所有映射关系复制到此映射中。
V remove(Object key)
如果此 TreeMap 中存在该键的映射关系,则将其删除。
int size()
返回此映射中的键-值映射关系数。
NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive)
返回此映射的部分视图,其键的范围从 fromKey 到 toKey。
SortedMap<K,V> subMap(K fromKey, K toKey)
返回此映射的部分视图,其键值的范围从 fromKey(包括)到 toKey(不包括)。
SortedMap<K,V> tailMap(K fromKey)
返回此映射的部分视图,其键大于等于 fromKey。
NavigableMap<K,V> tailMap(K fromKey, boolean inclusive)
返回此映射的部分视图,其键大于(或等于,如果 inclusive 为 true)fromKey。
Collection<V> values()
返回此映射包含的值的 Collection 视图。IdentityHashMap
在 HashMap 中, 它用 equals 方法来判断两个键是否相等, 而在 IdentityHashMap 中, 它用 == 来判断两个键是否相等. 除此之外, 它和 HashMap 没有任何区别.
SortedMap
SortedMap(只有TreeMap这一个实现)的键肯定是有序的,因此这个接口里面就有一些附加功能的方法了。
方法表:
















 1585
1585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









