







最近需要做基于卫星和无人机的农业大棚的旋转目标检测,基于YOLO V5 OBB的原因是因为尝试的第一个模型就是YOLO V5,后面会基于其他YOLO系列模型做农业大棚的旋转目标检测,尤其是YOLO V9,YOLO V9目前还不能进行旋转目标的检测,需要修改代码。
PS:欢迎大家分享农业大棚数据集,数据制作太花时间了......下面是我制作的农业大棚图像

我参考的是这位博主:
一、配置环境
(1)
CUDA10.1(cuda_10.1.243_426.00_win10.exe,我使用其他CUDA版本训练的时候报错......)
CUDNN(cudnn-10.1-windows10-x64-v7.6.5.32或者cudnn-10.1-windows10-x64-v8.0.5.39)
conda create -n yolo5 python=3.8
conda activate yolo5pytorch:1.6.1(torch-1.6.0+cu101-cp38-cp38-win_amd64.whl)
torchvision(torchvision-0.7.0+cu101-cp38-cp38-win_amd64.whl)
安装所需要的库:
Cython
coremltools==4.1
matplotlib==3.2.2
numpy==1.18.5
opencv-python==4.1.2.30
onnx==1.8.1
pandas==1.2.3
pillow==8.2.0 # 后面训练的时候因为该库版本过高,需要降级为8.2.0(其他低版本可能也行)
PyYAML==5.3
scipy==1.4.1
tensorboard==2.2
thop==0.0.31-2005241907
tqdm==4.41.0
Shapely==1.7.1
seaborn==0.11.1
sotabencheval==0.0.38
thop
seaborn
protobuf==3.20.3 # 后面训练的时候因为该库版本过高,需要降级为3.20.3(其他低版本可能也行)
# pycocotools===2.0.7(按照博主的方法安装pycocotools没有成功,所以安装的这个版本)在真正训练的时候可能还需要安装别的库(更新或者降级某些库)
(2)
安装pycocotools
进入模型工程文件中的文件夹pycocotools-2.0.2,进入CMD激活环境yolo5,然后运行python setup.py build_ext install(这个我做的时候报错,后面懒得管了)
cd pycocotools-2.0.2
python setup.py build_ext install首先添加E:\Model\YOLOv5_DOTA_OBB2\swigwin-4.0.2到path里面,接着要进行系统环境的刷新,可以选择重启,也可以进入cmd,输入set path=c 进行刷新
然后进入E:\Model\YOLOv5_DOTA_OBB2\utils先后运行
swig -c++ -python polyiou.i
python setup.py build_ext --inplace把C:\ProgramData\anaconda3\envs\yolo5\Lib\site-packages\shapely\DLLs文件夹内所有dll复制到C:\ProgramData\anaconda3\envs\yolo5\Library\bin
二、准备数据集
我使用LabelImg2标注数据(农业大棚),标注图像后会得到xml格式的标注文件 ,这里需要对数据格式进行转换,转成符合yolov5的txt格式。我参考的博主给的工程文件里面并没有roxml_to_data.py这个脚本,所以我使用的是另一个脚本代码转的
原始图像数据放在E:\Model\YOLOv5_DOTA_OBB2\DOTA_devkit_YOLO-master\DOTA_demo\images路径下
前面转成的txt格式文件放在E:\Model\YOLOv5_DOTA_OBB2\DOTA_devkit_YOLO-master\DOTA_demo\labelTxt路径下

文件夹draw_longside_img和yolo_labels暂时是空文件夹,后面会生成文件在里面
进入DOTA_devkit_YOLO-master文件夹,修改DOTA_devkit_YOLO-master\dota_utils.py中的classnames_v1_5,修改为标注数据的种类(我的只有一个种类)

我的类别是dog的原因是因为在使用LabelImg2标注数据的时候采用默认的标签,懒得每次都改.....
然后先后运行PaddingPIC.py(PaddingPIC.py的作用是将图片扩展到高宽相同,便于数据处理,如果你的图像数据已经是640 x 640大小,这一步不用都可以)和YOLO_Transform.py(YOLO_Transform.py的作用是将dota的数据格式转换为yolov5的数据格式,我在转的时候图像需要是png格式的,这个我还没完全搞懂,有空回过头再了解了解)
运行YOLO_Transform.py结束之后转换的txt文件会存放在yolo_labels文件夹中。至此,数据处理完成,只需要将数据放置好
将原始图像(jpg格式)放到E:\Model\YOLOv5_DOTA_OBB2\DOTA_demo_view\images路径下;将txt文件放到E:\Model\YOLOv5_DOTA_OBB2\DOTA_demo_view\labels路径下
三、模型配置
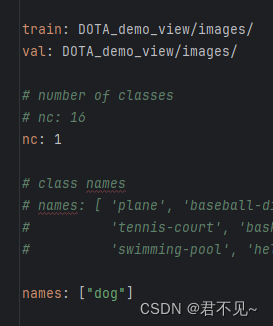
修改data\DOTA_ROTATED.yaml中nc(我的类别只有1)和names
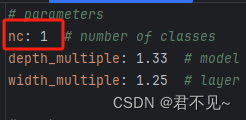
修改models/yolov5x.yaml中的nc(我的类别只有1)
修改data\hyp.scratch.yaml中的学习率的值
下载权重文件,这里要注意,因为这个项目是基于v5-3.1版本的,所以下载的权重文件不能下载最新的pt文件,不然会报错
四、模型训练
在train.py中设置好参数
parser.add_argument('--weights', type=str, default='weights/yolov5x.pt',help='initil weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5x.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/DOTA_ROTATED.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=200)
parser.add_argument('--batch-size', type=int, default=2, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', default=True, help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', default=False, help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--name', default='', help='renames results.txt to results_name.txt if supplied')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', default=True, help='train as single-class dataset')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--logdir', type=str, default='runs/', help='logging directory')
parser.add_argument('--workers', type=int, default=0, help='maximum number of dataloader workers')因为我数据集类别只有一种,所以single-cls参数设置为True
直接运行train.py或者在CMD中训练

五、Detect
在detect.py中设置好参数
parser.add_argument('--weights', nargs='+', type=str, default='runs/exp0/weights/best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='test_images', help='source') # file/folder, 0 for webcam
parser.add_argument('--output', type=str, default='test_images_detection', help='output folder') # output folder
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.1, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.4, help='IOU threshold for NMS')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', default=True, help='display results')
parser.add_argument('--save-txt', action='store_true', default=True, help='save results to *.txt')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', default=False, help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')detesct的结果:

标注的图像仅有132张,并且有些图像数据也不太好,结果就这样了......
下一步便是增加数据集数量和提高数据集质量,使用更好的模型训练
这只是一个篇分享经验的文章,难免有错误或者遗漏的地方,欢迎交流指正















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









