







在用python进行数据处理或者分析结果使,经常需要提取文本中的相关内容,这种情形下利用python的re模块来进行处理是较为高效的一种方法。
下面我将根据几种应用场景来详细讲解如何在python下利用正则来实现各种功能。
场景一:获取文本中所有双引号中的内容
下面这段内容是我lda训练输出的topic-word结果,包含了每个主题对应的词汇和其概率,我需要将所有的词汇提取出来,便于分析主题意义。即”“中的内容。
2018-01-18 07:40:39,950 : INFO : topic #0 (0.014): 0.010*"business" + 0.009*"family" + 0.008*"baby" + 0.007*"wife" + 0.006*"claim" + 0.006*"husband" + 0.006*"model" + 0.006*"woman" + 0.005*"event" + 0.005*"night" + 0.005*"fan" + 0.005*"daughter" + 0.004*"style" + 0.004*"award" + 0.004*"christmas" + 0.004*"sex" + 0.004*"stock" + 0.004*"energy" + 0.004*"mother" + 0.004*"street" + 0.004*"company" + 0.004*"celebrity" + 0.003*"girl" + 0.003*"child" + 0.003*"rock" + 0.003*"sheer" + 0.003*"london" + 0.003*"friend" + 0.003*"face" + 0.003*"coat" : 提取方法:
import re
words = re.findall(r"\"(.+?)\"", line) #findall即提取出所有符合条件的文本并形成列表,\"中\是转义符,(.+?)即为获得双引号内的所有文本。关于正则表达式中的这些符号的含义,可以参考这篇文章:Python正则表达式指南,其中有详细的介绍。
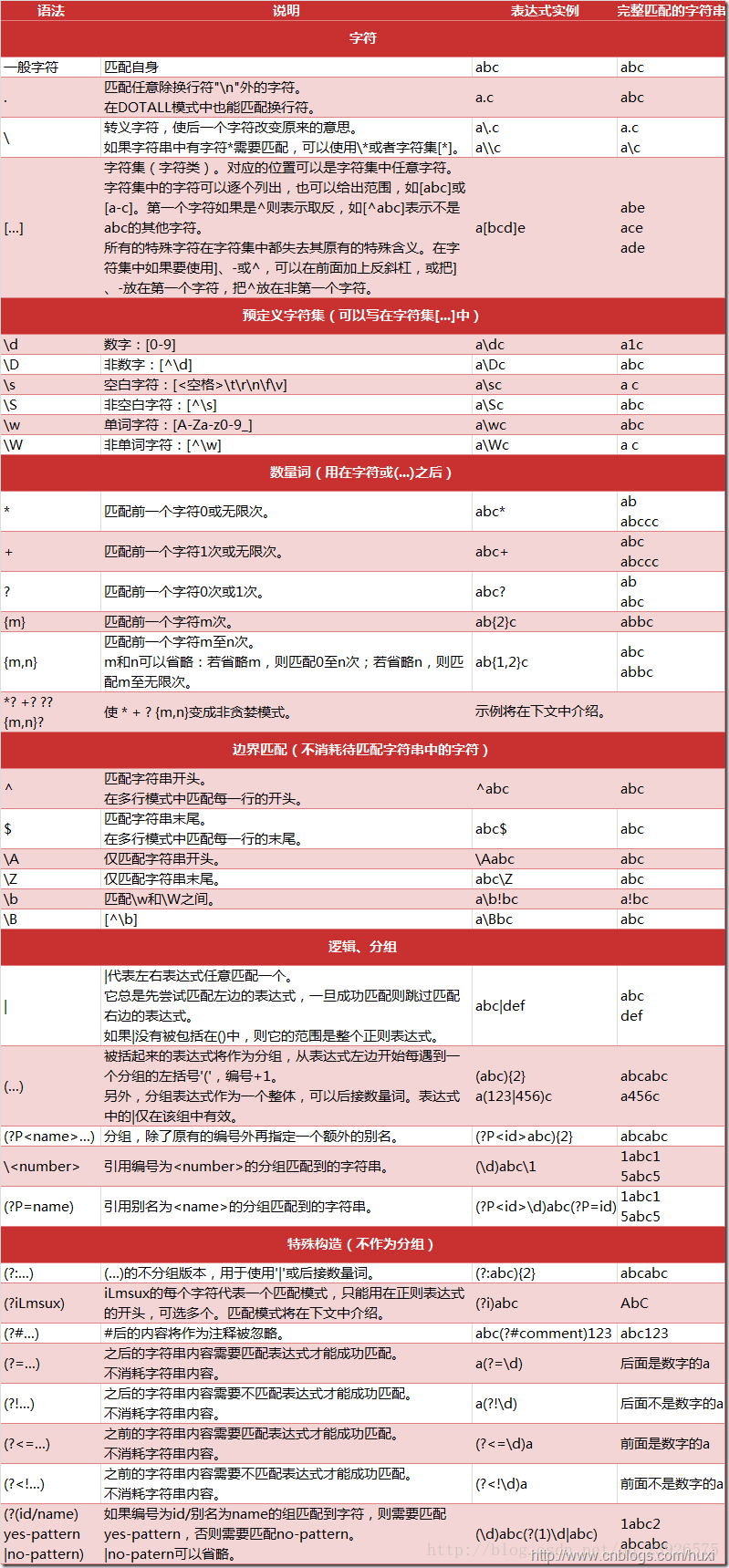
场景二:提取文本中存在的邮箱地址
http://blog.sina.com.cn/s/XXXXXXXXXXXXXXXXXX.html, moon@qq.com, wwww.baidu.com, breeze@163.cn,jiade@qq.123假如我需要提取出上述文本中存在的邮箱地址,则可以根据以下代码实现:
text = "http://blog.csdn.net/qq_23926575, moon@qq.com, wwww.baidu.com, breeze@163.cn,jiade@qq.123"
regex = r"([a-zA-Z0-9_.+-]+@[a-zA-RZ0-9-]+\.[a-zA-Z]+)" #[]中列举了各种符号,[]的作用为能够匹配其中出现的任意字符,其后有个"+"意味着能够匹配多次。a-z即指代abcd…xyz等26个字母。
print re.findall(regex, text)
# 输出结果为:
# ['moon@qq.com', 'breeze@163.cn']
# 最后一个后缀为数字,一般来说不存在这样的邮箱,因此排除。目前只想到这两种常用的功能,re.match和re.search较为鸡肋,不够灵活,不做详细介绍。之后想到其他有用的场景再更。















 3320
3320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









