









kafka

主要参考《深入理解Kafka核心设计与实战原理》、网络课程、kafka源码和本地调试
书中源码地址 https://github.com/hiddenzzh/kafka_book_demo
📚1. 思维导图
📚2. 涉及的名词
- Producer:生产者,负责创建消息
- 三种发送模
- fire-and-forget:发后即忘
- Sync:同步
- Async:异步
- 发送过程经过组件
- 拦截器
- 序列化器
- 分区器
- 三种发送模
- Consumer:消费者,消息接收方,使用pull模式从broker拉取消息,并保存offset,负责业务处理
- Consumer Group:消费者组(逻辑上的概念),每个消费者都有一个对应的消费者组,每个分区只能被一个消费者组中的一个消费者所消费
- Broker:服务代理节点。可以看作是Kafka实例
- Topic:主题 消息以主题为单位进行归类,生产的每条消息都需要指定Topic。逻辑上的概念,一个主题可以跨多个broker
- Partition:分区 一个分区只属于一个主题,物理上可以看作一个可以追加日志(Log)的文件
- offset:消息在追加到分区日志文件时都会分配一个特定的偏移量。是消息在分区中的唯一标识. 不能跨分区,可以保证主题的分区有序
- Replica:副本 同一分区不同副本保存的是相同的消息
- leader:负责处理读写请求,维护所有副本的LEO
- follower:只负责与leader副本同步,与leader处于不同的broker,leader失效时从follower中重新选举leader分区副本。只维护自身的LEO和HW
- Leader Epoch:代表Leader纪元信息,初始值为0,每当Leader更新一次,epoch值加一
- AR(Assigned Replicas):分区中所有的副本 AR = ISR + OSR;leader副本负责维护ISR
- ISR(In Sync Replicas):所有与leader副本保持一定程度同步的副本(包括leader副本)
- OSR(Out Sync Replicas):与leader副本滞后过多的副本
- HW(High Water):高水位,一个特殊的offset,消费者只能读取到这个offset之前的消息
- LEO(Log End Offset):日志文件中下一条待写入消息的offset,ISR副本都会维护LEO,min(offset)为HW
- Log:一个分区对应一个Log(对应一个文件夹)
- LogSegment:为了防止Log过大而引入(对应一个日志文件和两个索引文件,以及可能的事务文件)
- 日志文件:.log后缀
- 偏移量索引文件:.index后缀
- 时间戳索引:.timeindex后缀
- 控制器:集群中会有一个或多个Broker,其中一个Broker会被选举为控制器。负责管理集群中所有分区和副本状态。使用单线程基于队列的模型实现
- 分区Leader选举:按照AR集合顺序查找第一个存活且在ISR集合中的副本
fsync:同步刷盘
- 分区Leader选举:按照AR集合顺序查找第一个存活且在ISR集合中的副本
📚3. 重要知识点
Consumer:
- 消费支持正则表达式
- 位移提交:旧版存储在Zookeeper中,新版存储在内部主题_consumer_offsets
- 再均衡:分区所属权从一个消费者转移到另一个消费者的行为。在此期间消费者无法读到消息
命令:
- 主题管理
- 分区管理
- KafkaAdminClient
日志存储
- 日志删除
- 基于时间
- 基于日志大小
- 基于日志起始偏移量
- 日志压缩
- 磁盘存储
- 采用文件追加的方式写入消息,即顺序写盘操作
- 页缓存:操作系统实现的一种主要的磁盘缓存,以减少对磁盘的I/O操作
- 零拷贝:数据直接从磁盘文件复制到网卡设备中,而不需经过应用程序之手,依赖于 Linux下的mmap(Memory Map),sendfile,Java下是FileChannal.transferTo(), 可以参考多路复用
- DMA(Direct Memory Access):将文件内容复制到内核模式下的Read Buffer
服务端
- 时间轮:时间轮解析
客户端
- 分区分配策略
- RangeAssignor:按照消费者总数和分区总数进行整除获得一个跨度,然后分区按照跨度平均分配,保证每个分区尽可能均匀的分配给所有的消费者
- RoundRobinAssignor:消费组内所有消费者及订阅的所有主题按照字典排序,然后轮询方式一次逐个将分区一次分配给每个消费者
- StickAssignor:
- 分区尽可能分配均匀
- 尽可能与上次分配保持相同
- 当以上两者发生冲突的时候,第一个优先于第二个
- 自定义分配策略:一个分区只能被一个消费者组内的一个消费者消费。这不是绝对的。可以通过自定义分配策略改变。需要集成
AbstractPartitionAssignor
- 消费者协调器和组协调器
- 消费者唯一标识:consumer.id+主机名+时间戳+UUID。consumer.id是旧版消这种配置的,相当于新版中的client_id
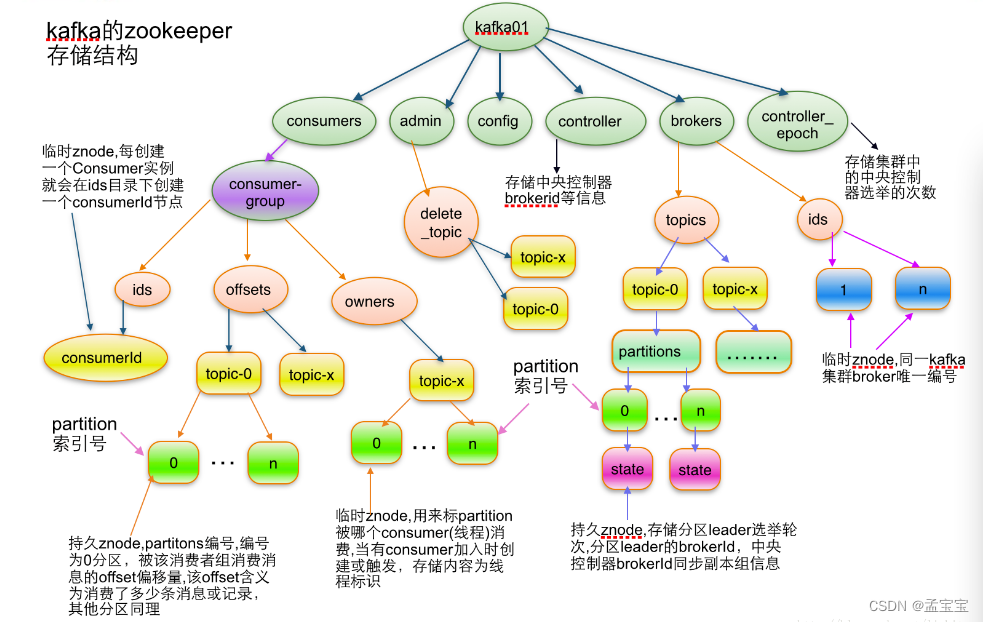
- 消费者唯一标识:consumer.id+主机名+时间戳+UUID。consumer.id是旧版消这种配置的,相当于新版中的client_id
每个消费者对zookeeper的相关路径分别监听,当触发在均衡操作时,一个消费者组下会同时进行在均衡操作,而消费者之间
彼此不知道结果,可能导致Kafka工作在一个不正确状态。依赖zookeeper的做法可能导致
- 1:羊群效应;
- 2:脑裂问题
新版消费者客户端进行了重新设计
将全部消费组分成多个子集,每个消费组的子集再服务端对应一个GroupCoordinator对其进行管理,客户端中有一个ConsumerCoordinator组件负责与GroupCoordinator交互
__consumer_offset:保存了消费位移
- key:version、group、topic、partition
- value:version、offset、metadata、commit_timestamp、expire_timestamp
事务
- 消息传输保障
- at most once
- at least once
- exactly once
对Kafka来说生产者保证 at least once,消费者保证 at most once
0.11.0.0版本引入幂等和事务两个特性,来实现exactly once
可靠性探究
黄金定理: 任何设计阶段考虑到的特殊情况,一点会在系统实际运行中发生,并且在系统实际运行过程中还会遇到很多在设计时未能考虑到的异常故障
Kafka应用
- 消费组管理: kafka-consumer-groups
- 消费位移管理:kafka-consumer-groups
- 手动删除消息:kafka-delete-records
- Kafka connect
- 通用性,规范其他系统需Kafka的集成,简化连接器的开发部署和管理
- 支持独立模式和分布式模式
- Rest接口:支持使用Rest API提交和管理Connector
- 自动位移管理
- 分布式和可扩展
- 流式计算、批处理集成
KafKa监控
- 监控维度
-集群信息- broker信息
- 主题信息
- 消费组信息
- Kafka自身提供JMX监控指标超过500个
- 监控架构分为:1:数据采集;2:数据存储;3:数据展示。3个模块。数据存储可以采用OpenTSDB(基于时间序列的数据库)
高级应用
- 过期时间:消费者拦截器+header添加过期时间
- 延时队列:时间轮解决精度+文件解决内存暴涨
- 死信队列和重试队列:
- 死信队列:消费者不能处理的消息
- 消费端处理消息失败
- 消息路由:headers新增routingKey
- 消息轨迹
- 消息审计:生产者、存储、消费整个过程对消息个数和延迟的审计,一次检测数据是否丢失,重复,延迟
- kafka与Spark,Flink集成
📚4. 关联其他知识点
📚5. 源码阅读
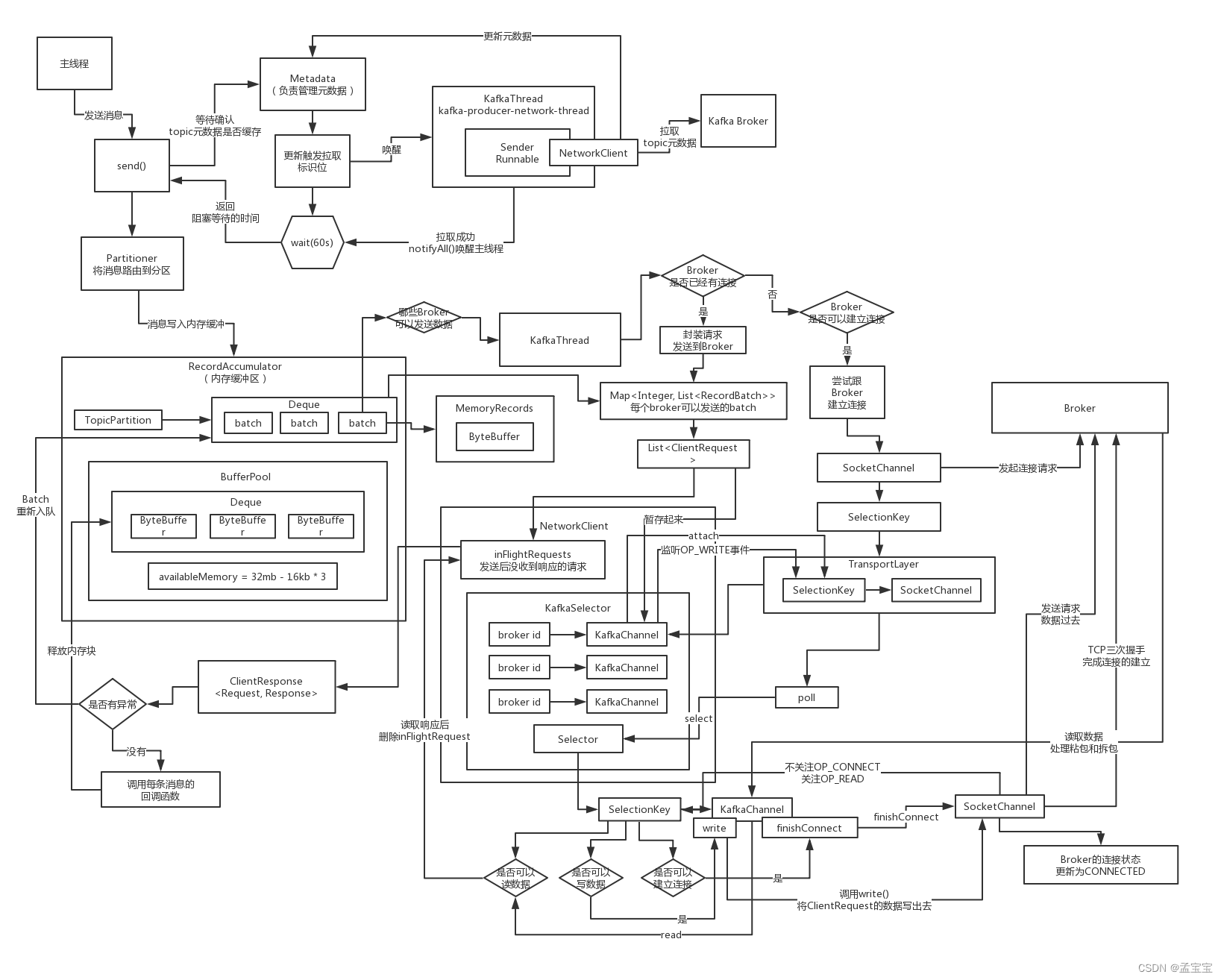
生产者
重点类
RecordAccumulator
















 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











