









如果您在 PDF 图像中找到一些有用的信息并想转换为 Word 格式以供进一步使用,您将需要一个具有OCR 功能的 PDF 图像转 Word 转换器,该转换器旨在识别 PDF 图像中的文本并将其制作出来可编辑。
将 PDF 图像转换为 Word 并不容易,因为我们需要在 Word 输出中保留 PDF 图像的原始格式。因此,我们在这里列出了 6 个顶级的 PDF 图像转Word 转换器,带有 OCR,能够尽可能保持原始质量。
适用于 Windows/Mac 2023 的最佳 PDF 图像到 Word 转换器
奇客PDF是我们挑选的最佳 PDF 图像转 Word 转换器。它既是从 Word、Image 和其他文件创建 PDF 文件的 PDF 创建器,也是将 PDF 导出为 16 种格式的 PDF 转换器。它的 OCR 功能不仅可以将扫描的 PDF 转换,还可以将多种图像格式转换为可搜索的 PDF、可编辑的 Word、Excel、PowerPoint、Text、。更重要的是,它支持批量转换,您可以一次将多个PDF图像转换为Word格式。
如何在电脑上将 PDF 图像转换为 Word?
1.下载并安装 奇客PDF。
奇客PDF编辑奇客PDF编辑-PDF文档内容编辑轻松搞定,像编辑Word一样编辑PDF,一切如此简单。![]() https://www.geekersoft.cn/geekersoft-pdf-editor.html2. 将 PDF 图像拖在程序中打开。
https://www.geekersoft.cn/geekersoft-pdf-editor.html2. 将 PDF 图像拖在程序中打开。
3.上传文件后,选择工具,然后选择文字识别。
4. 单击“转换”按钮开始将 PDF 图像转换为 Word。
如何使用 Google Docs 免费将 PDF 图像转换为 Word
您使用过 Google Docs 在线编辑文档吗?如果没有,您应该尝试将其用作 PDF 图像到 Word 转换器。
Google Docs 可以打开 PDF 图像或扫描的 PDF,然后将它们设为可编辑,您可以直接在 Google Docs 中修改文件,就像您在 Microsoft Office Word 中编辑 Word 文档一样,提供了各种编辑工具。但是使用Google Docs 将PDF 图片转Word 的最大缺点是:格式会丢失,您需要自己重新添加格式。
如何使用 Google Docs 将 PDF 图像转换为 Word?
- 登录您的 Google 帐户并转到 Google 云端硬盘图标。

- 单击新建>文件上传,首先将您的 PDF 图像添加到 Google 云端硬盘。
- 右键单击 PDF 图像并使用 Google 文档打开。
- (可选)编辑文件或添加格式。
- 转到文件>下载为>Microsoft Word Docx。
排名前 2 位的在线免费 PDF 图像到 Word 转换器
无需安装软件或登录 Google 帐户,我们仍然可以免费将 PDF 图像转换为 Word,但我们需要一个在线免费的 PDF 图像到 Word 转换器,为您推荐以下 2 个工具。
#1在线OCR
OnlineOCR 专门设计用于从扫描的 PDF 和图像中提取文本,还将扫描的文件转换为 Word、Excel 和文本格式。它支持识别 46 种语言。您可以预览实时 OCR 结果并检查准确性,然后将结果导出为格式化的 Word 或 Excel 格式。但是,您每次只能转换一个 PDF 图像。
如何免费在线将 PDF 图像转换为 Word?
- 转到 onlineocr.net。
- 单击选择文件以上传您的 PDF 图像。
- 选择文件语言为英语或其他语言。
- 选择输出格式为 Microsoft Word。
- 然后单击“转换”将 PDF 图像转换为 Word 格式。
#2 在线2PDF
Online2PDF 不仅仅是一个 PDF 图像到 Word 转换器,它是一个强大的 PDF 工具,可以编辑、压缩、解锁、保护、合并和转换 PDF。它支持上传扫描的 PDF 和图像进行 OCR,还允许用户将文件导出为各种格式,包括可搜索的 PDF、可编辑的 Word、Excel、PowerPoint、ODT、ODS、ePub、Mobi、AZW3、Text 和 RTF。它可以识别 32 种文件语言。
如何免费在线将 PDF 图像转换为 Word?
- 转到在线 2pdf。
- 单击选择文件并将您的 PDF 图像上传到程序中。
- 选择模式来决定是否要将所有 PDF 图像合并到一个 Word 中。
- 选择输出格式为 Word。
- 启用 OCR 并选择文件语言。
- 单击转换以将 PDF 图像保存为 Word 格式。
如果您已经安装了 Adobe Acrobat
如果您已经安装了 Adobe Acrobat 怎么办?然后你不需要尝试或支付另一个 PDF 图像到 Word 转换器,Adobe 也可以将你的 PDF 图像保存为格式良好的 Word 文档。但由于Adobe无法直接将PDF图片转Word,我们必须先将PDF图片保存为PDF格式,然后上传PDF,Adobe OCR处理。
如何使用 Adobe 将 PDF 图像转换为 Word?
- 启动 Adobe Acrobat。
- 转到工具>创建 PDF,上传您的 PDF 图像,然后单击创建以在 Adobe Acrobat 中打开 PDF 图像。
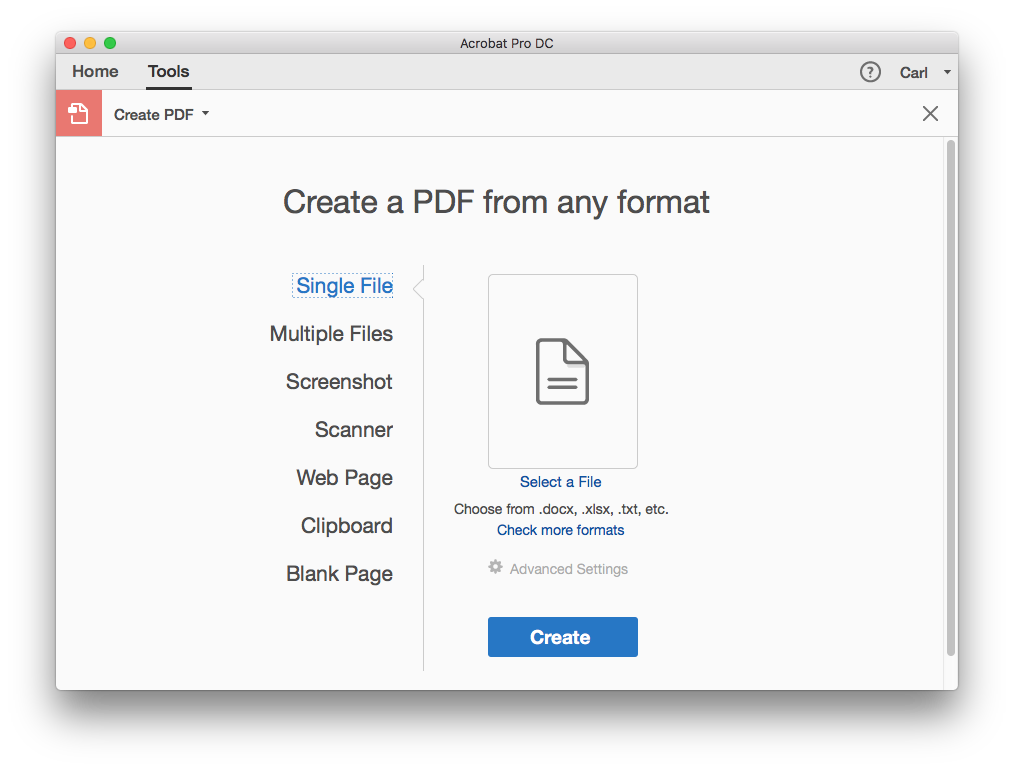
- 再次转到工具,单击增强扫描>识别文本>在此文件中,将使用 OCR 处理 PDF 图像。
- (可选)编辑或修改文件。
- 转到工具>导出 PDF,选择输出为 Microsoft Word。
结论
很容易找到 PDF 图片到 Word 转换器,但并不是所有的转换器都能为您带来准确的转换结果。根据测试结果,独立的 PDF 图像到 Word 转换器在转换时更好更快。















 4279
4279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









