









目录
(3).效率问题,如何快速找到一个没使用的inode/block
1.C语言中的FILE和文件描述符对应的file
这两个是不一样的概念,C语言中的FILE内部有当前文件对应的文件描述符fd,同时还有C语言层面上的缓冲区的内容等信息。
然后操作系统根据FILE里面的fd,在fd作为下标的指针数组里面找到的file对象,里面存放了文件相关的inode元的信息(文件的属性信息),和C语言的FILE是不一样的。
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访问的。
所以C库当中的FILE结构体内部,必定封装了fd。
2.Linux的EXT系列的文件系统
Linux中将磁盘分区管理,每个分区中都会有一个文件系统,将分区中的内容分为多个block group,而每个block group内部使用统一的方式进行管理。
(1).block group中六个部分的内容
- 超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:整个分区的bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。(它每个组都有一个,防止一个被刮花,整个崩掉)
- GDT,Group Descriptor Table:块组描述符,描述块组属性信息,(当前组块里面的block和inode还有多少没用等等)
- 块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用
- inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用。
- i节点表(inode Table):保存了一个个inode信息,一个inode内部存放文件属性,如文件大小,所有者,最近修改时间等
- 数据区:存放文件内容
inode Table里面有一个个inode,用于存放文件属性,data blocks里面有一个个block,用于保存文件的内容(每个inode512B(字节),每个block 4KB)
inode索引结点相关
操作系统要读取一个文件的内容的时候,通过文件描述符找到file结构体,这个结构体内部存放了f_inode指针,指向inode结构体,这个结构体是不是就是文件系统里面的inode
文件系统管理文件,是根据inode编号在inode_table里面找到inode的
Q:这两个inode有什么不同?

inode是VFS使用的一个对象,用于存放内核在操作文件或目录时所需要的全部信息。索引节点有两种,一种是这里所说的VFS索引节点,存在内存中;另一种是具体文件系统的索引节点,存在于磁盘上,使用时将其读入内存填充VFS的索引节点,之后对VFS索引节点的任何修改都将写回磁盘更新磁盘的索引节点。
一个索引节点代表了文件系统的一个文件,在文件创建时创建文件删除时销毁,但是索引节点仅在当文件被访问时,才在内存中创建,且无论有多少个副本访问这个文件,inode只存在一份。
因此,我们没有打开文件时,文件的inode是保存在磁盘中,由文件系统进行管理的。当我们创建文件的时候,inode在磁盘上会被创建,当我们删除时,磁盘上的inode才会被销毁。文件系统创建和删除文件(也就是管理文件)都是通过inode_number在inode_table里面找到inode,从而对文件进行管理的。
当我们打开一个文件以后,在内存中才会有inode结点的信息,这个inode则是通过file里面的f_inode指针找到的,找到inode以后,也就获取到了当前文件的属性和内容,可以对文件进行读写操作。修改了inode的内容后,都会将修改写回磁盘,更新磁盘上的inode
(内存中的inode结构和磁盘中的inode结构是并不是完全一样的,内存中想要读写文件是通过f_op里面的函数做到的,而不是像磁盘里面根据block_id什么的找到文件内容的)
(2).一个文件的inode和对应的block如何关联呢?
Linux系统中,文件名在系统层面是没有用的,文件名是给用户用的,系统中是根据inode编号去找的,一个inode对应一个文件。一个inode对应多个block
每个inode可以看做一个结构体,内部有文件的所有属性,还有一个inode_number编号,还有一个block数组,表示和当前inode对应的Data Blocks中的 block的下标,可以通过这些下标找到inode对应的block。
所以我们操作系统找文件,先根据inode编号找到inode,也就拿到了文件信息,然后再根据inode里面的block数组下标,找到inode对应的block数据块,也就拿到了文件的内容。
(3).效率问题,如何快速找到一个没使用的inode/block
使用位图inode Bitmap,比特位的位置表示inode的编号,比特位01表示当前的inode是否被占用。
如果我要为当前文件创建两个block,那也需要快速找到没被使用的block
使用位图,block Bitmap,比特位的位置表示block的编号,比特位01表示当前block是否被占用
(4).目录是文件,它的属性和内容是什么
目录是文件,所以也是有inode的,里面放目录的属性信息。它也有数据,那数据块里面放什么呢?
文件名:inode编号,文件的数据块里面存放的是这种文件名和inode编号的映射信息
我们创建的所有文件,全部一定在一个特定的目录下!!
(5).touch,echo,cat,rm发生了什么?
1.touch hello.c首先在inode位图里面找没有使用的inode,然后将文件的属性信息填到inode里面。
2.echo重定向写入的时候,通过block位图找到没有被使用的block,然后与inode建立映射关系,最后把内容写到block块里面。
3.我们在对应目录下创建文件的时候,会往目录里面写入inode和文件名的映射关系。然后我们运行cat 文件名,的时候是在当前目录下运行的,操作系统会先查看当前目录->inode->block里面对应文件名的inode,然后根据inode去inode table里面找到inode,然后根据inode里面的映射关系在block table里面找到对应的block块,最后输出文件的内容。
4.删除文件,首先在当前目录->inode->blocks里面找到对应的inode编号和文件名的映射关系,根据当前要删除的文件名找到inode编号,然后在位图中找到对应的inode编号对应的位置,直接将其置0即可。然后根据inode里面的block编号,在block位图里面把对应的数据块置0即可。这也就是为什么我们在删除文件的时候速度很快,同时也是数据可以恢复的原因)
3.软硬链接
软连接就是创建一个链接文件,通过这个链接文件可以访问另一个文件,就像windows系统中的快捷方式,创建方式就是ln -s 文件路径+文件名 链接名。
硬链接的创建方式和软链接很像,就是去掉-s选项即可。创建的硬链接只是一个映射关系,而不是一个文件,我们通过硬链接也可以访问原文件。
比如我们在很深的多级目录里面创建了一个文件,那我下次要访问这个程序的时候,前面要加上一长串路径,非常麻烦。这个时候就可以给这个文件加上一个软连接或者硬链接,我们就可以通过这个链接接访问文件,或者执行程序。
(1).软连接:
语法:ln -s(soft) 对应目录的文件 连接名
unlink 链接名(最好是不要用rm)
软连接特别像windows里面的快捷方式
[zebra@VM-8-12-centos test]$ ll
total 44
-rw-rw-r-- 1 zebra zebra 21 Oct 23 22:19 README.md
drwxrwxr-x 2 zebra zebra 4096 Nov 18 17:10 test10
-rwxrwxrwx 1 zebra zebra 24 Oct 24 10:50 test1.txt
-rw-rw-r-- 1 zebra zebra 224 Oct 26 10:44 test2.cpp
drwxrwxr-x 2 zebra zebra 4096 Oct 31 20:15 test3
drwxrwxr-x 2 zebra zebra 4096 Oct 28 15:02 test4
drwxrwxr-x 2 zebra zebra 4096 Nov 1 15:05 test5
drwxrwxr-x 2 zebra zebra 4096 Nov 11 16:23 test6
drwxrwxr-x 2 zebra zebra 4096 Nov 15 21:02 test7
drwxrwxr-x 2 zebra zebra 4096 Nov 16 00:18 test8_mutex
drwxrwxr-x 2 zebra zebra 4096 Nov 16 21:09 test9_cond
[zebra@VM-8-12-centos test]$ ln -s test10/mytest soft_link
[zebra@VM-8-12-centos test]$ ll
total 44
-rw-rw-r-- 1 zebra zebra 21 Oct 23 22:19 README.md
lrwxrwxrwx 1 zebra zebra 13 Nov 19 11:42 soft_link -> test10/mytest
drwxrwxr-x 2 zebra zebra 4096 Nov 18 17:10 test10
-rwxrwxrwx 1 zebra zebra 24 Oct 24 10:50 test1.txt
-rw-rw-r-- 1 zebra zebra 224 Oct 26 10:44 test2.cpp
drwxrwxr-x 2 zebra zebra 4096 Oct 31 20:15 test3
drwxrwxr-x 2 zebra zebra 4096 Oct 28 15:02 test4
drwxrwxr-x 2 zebra zebra 4096 Nov 1 15:05 test5
drwxrwxr-x 2 zebra zebra 4096 Nov 11 16:23 test6
drwxrwxr-x 2 zebra zebra 4096 Nov 15 21:02 test7
drwxrwxr-x 2 zebra zebra 4096 Nov 16 00:18 test8_mutex
drwxrwxr-x 2 zebra zebra 4096 Nov 16 21:09 test9_cond
[zebra@VM-8-12-centos test]$ 此时我们可以./soft_link来运行mytest程序
[zebra@VM-8-12-centos test]$ ./soft_link
666
i
[zebra@VM-8-12-centos test]$ (2).硬链接:
语法:相比软链接,不要加上-s选项就是创建硬链接
此时我们可以通过./hard_link来运行mytest程序
[zebra@VM-8-12-centos test]$ ./hard_link
666
i
[zebra@VM-8-12-centos test]$ ls -i指令选项
加上 -i 选项以后,可以查看当前文件对应的inode的编号
结论
1.软链接是有自己独立的inode的,所以软链接实际上是一个独立文件,所以软链接有inode,也有blocks,它的数据块里面保存的是指向文件的所在路径和文件名。
如图,软连接的block数据中保存的是原文件名,而硬链接并没有自己的inode和block,只是一个存放在当前目录里面的映射关系。我们删除文件的时候,必须把所有的硬链接全部删除,该inode对应的文件才会被删除。
(这里def是abc的硬链接,可以看到他们前面的inode编号是相同的,def相当于是abc文件内容的另一个文件名,只是一个映射关系,并不是一个文件;abc.s是abc的软连接,其inode编号和abc是不同的,是一个新的文件,文件中的blocks中保存的内容是原文件的文件名“abc”)
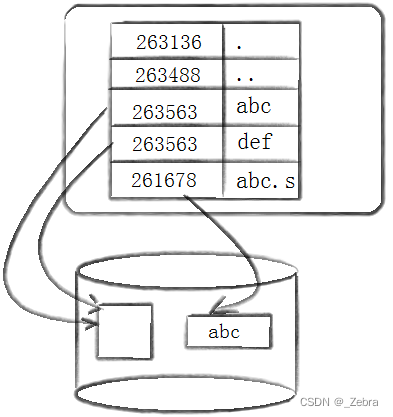
2.硬链接,它的inode编号和原文件是相同的。本质上就不是一个独立的文件,而是一个文件名硬链接本质是根本就不是一个独立的文件,而是一个文件名和inode编号的映射关系,因为自己没有独立的inode
3.创建硬链接,本质是在特定的目录下,填写一对文件名和inode的映射关系!
4.如果创建了一个硬链接以后,把原来的文件删除,相当于对原来的文件进行了重命名。(毕竟如第三点所说,创建了硬链接以后,同一个inode相当于有两个文件名不相同的映射关系,我们删除了原文件只是删除了其中一种映射关系,另一个映射关系还在,这就相当于是重命名了)
5.这个数字表示文件的硬链接数,当这数量变成0的时候,文件才会被彻底删除(也就是要删除所有的硬链接,才能删除文件)
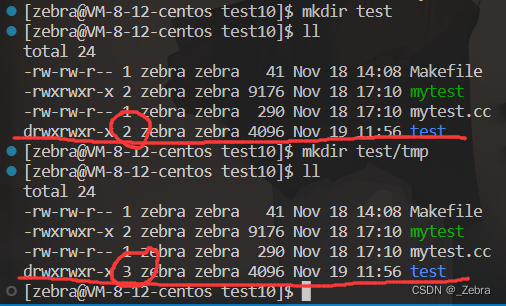
Q:为什么目录的默认硬链接数是2
我们创建一个文件,它默认的硬链接数是1,但是我们创建一个目录,它默认的硬链接数是2,这是为什么呢?我们在当前目录里面再创建一个tmp目录,发现当前目录的硬链接数量变成了3,这又是为什么呢?
A:因为硬链接实际上是一个保存在当前目录里面的映射关系,不像软链接那样是一个文件。这个映射关系是inode和文件名的映射关系,2个硬链接就表示有两个文件名和同一个inode建立了映射关系,保存在目录的block中。除了当前目录名和当前目录inode的映射关系以外,目录里面还有一个.表示当前目录,我们用ls -ali就可以看到.的inode和目录的inode是同一个,所以硬链接数量为2。
再创建一个tmp目录以后,tmp目录里面会有..,对应的inode也是当前目录,所以当前目录的硬链接数量就变成了3。














 1315
1315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









