






Kafka
1.Kafka的基础结构

- Producer:消息生产者,向Kafka中发布消息的角色。
- Consumer:消息消费者,即从Kafka中拉取消息消费的客户端。
- Consumer Group:???
- Broker:一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。
- Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个Topic
- Partition:分区,为了实现扩展性,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)
- Offset:偏移量,分区中的每条消息都有一个唯一的标识,即偏移量。消费者使用偏移量来跟踪已经读取的消息位置。
- Replication:副本, 每个分区的数据可以在多个Broker之间复制,以提高容错性和数据可靠性。一个分区的副本分为Leader和Follower。Leader负责处理读写请求,Follower负责同步数据。
- Leader:分区领导者, 生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
- Follower:分区跟随者, 实时从Leader中同步数据,保持和Leader数据的同步。Leader发生故障时,某个Follower会成为新的Leader。
1.1 Broker
单台Kafka服务器就是一个Broker,Kafka集群由多个Broker组成,每个Broker负责存储和管理部分数据。每个Broker都有一个唯一的ID(Broker ID),用来标识它在集群中的角色和位置。
Broker是Kafka集群的核心组件,负责消息的存储、管理和分发,确保数据的可靠性和高可用性。
1.1.1 Broker工作流程
- Broker启动后, 它将自身信息(Broker ID、监听端口、日志目录等)注册到集群的内置控制器中。
- 如果集群中没有控制器或现有的控制器失效,Broker会发起控制器选举。最终有一个胜出, 并被推选为Controller。
- Controller会定期向集群中的其他Broker发送心跳信号,让它们知道Controller在正常运行。
- 如果Controller宕机,集群中的Broker会开启新一轮的Controller选举。
1.1.2 Controller的作用
- 集群管理: 维护Broker列表,当集群状态发生变化(如Broker加入或离开、分区重新分配等),控制器会更新集群的元数据并将变更通知所有Broker。
- 分区管理: 创建Topic并指定分区数时,Controller会根据集群的当前状态决定将Topic的分区分配到哪些Broker上。控制器使用的分区分配策略可以包括轮询、负载均衡等。
- 副本管理: Partition指定副本时,Controller负责将分区的副本分配到不同的Broker上。这个过程中会挑选出一个Leader(分区领导者)和多个Follower(分区跟随者)
- 领导者选举: Controller负责选举每个分区的领导者(Leader)。领导者负责处理读写请求,并将数据同步到副本。
- 事务管理: Controller负责协调跨分区事务的提交和回滚,确保事务的一致性和原子性。
1.2 Topic
Topic即数据主题,用来分类和存储消息,可以将相同类型的消息分类到同一个topic。生产者将消息发布到topic,消费者从topic中订阅和读取消息。
1.作用:
- 消息分类:生产者将消息发布到指定的Topic中,消费者从Topic中消费消息。通过Topic,可以将不同类型的消息分组,以便于处理和分析。
- 数据持久化:Topic是数据持久化的基本单位,每个Topic的消息会被持久化到磁盘上,保证数据的可靠性。
1.3 Partition
Partition是Topic的物理数据存储单元。每个Topic可以分成一个或多个Partition。Partition是实际存储消息的地方,一个Topic的多个Partition可以分布存储在多个Broker上。
Partition是一个有序的消息队列,按照写入的顺序进行存储和读取。kafka可以保证每个Partition中的消息读写是有序的,但同一个Topic的不同分区之间的消息顺序无法保证。
1.作用:
- 数据存储: Partition存储Topic中的实际消息数据。每个Partition是一个日志文件,消息以追加的方式写入。
- 并行处理: 通过将Topic分成多个Partition,Kafka能够实现数据的并行处理和负载均衡。每个Partition可以被不同的消费者并行读取,从而提高系统的吞吐量和处理能力。
- 数据分布: 分区使得消息可以分布在不同的节点上,从而实现数据的分布式存储。Kafka会根据一定的分区策略(如轮询或基于键的哈希)将消息分配到各个分区中。
- 顺序保证: 在同一个分区内,消息是有序的,即按照写入的顺序进行存储和读取。这对于需要顺序处理的应用场景非常重要。需要注意的是,不同分区之间的消息顺序无法保证。
2.实现
每个Kafka主题在创建时可以指定多个分区,每个分区都有一个唯一的分区编号(从0开始)。生产者在向Kafka发送消息时,可以指定将消息发送到哪个分区,也可以通过分区器(Partitioner)根据消息的键来决定分区。
例如,假设有一个主题test-topic,它有3个分区:
test-topic
|---- Partition 0
|---- Partition 1
|---- Partition 2
1.4 Replication
Replication是将一个分区的消息数据复制到集群中的多个Broker上的过程,复制机制确保即使某个Broker发生故障,数据仍然可以从其他副本中恢复,保证数据的高可用性和容错性。
1.副本因子
分区的副本数量是由副本因子(Replication Factor)决定的。例如,如果副本因子设置为 3,那么每个分区将有 3 个副本,包括一个领导者(Leader)和两个追随者(Follow)。
1.4.1 Leader副本
领导者副本是分区的主要副本,负责处理所有的读写请求。
- 读写操作:生产者将消息写入领导者副本,消费者从领导者副本读取消息。
- 数据同步:领导者副本将数据变更同步到所有的追随者副本。
1.4.2 Follow副本
追随者副本是分区的备份副本,从领导者副本复制数据。
- 数据同步:追随者副本定期从领导者副本获取并应用数据变更,保持与领导者的数据一致性。
- 故障恢复:当领导者副本失效时,追随者副本可以被选举为新的领导者,从而保证数据的高可用性。
1.4.3 ISR
1.4.4 OSR
3.4 offset
消息会按照时间顺序不断被追加到分区的一个结构化commit log中, 这个顺序通过一个称之为offset的id来标识唯一
offset的作用
- 唯一标识: 分区中每条消息的唯一标识, 它是一个从0开始递增的整数, 可以理解为Mysql中的自增主键
- 消费者追踪消息进度: 消费者在消费消息时, 会记录自己消费到哪个offset, 每个消费者在读取消息后都会更新其当前的offset, 并将最新的offset提交给Kafka的特殊主题(默认是
__consumer_offsets), 这样即使消费者重启或者故障恢复后,可以从上次消费的位置继续消费未处理的消息,而不是从头开始。 - 确保消息顺序: 在同一个分区内, 消息按照写入的顺序进行排列, offset也按顺序递增. 通过offset, 消费者可以保证按顺序读取消息
- 重放和恢复: 由于offset是有序且持久化的, 一个消费者可以重置到一个旧的偏移量, 从而重新处理丢失或错误处理的消息;也可以跳过最近的记录,从
现在开始消费。 - 并行处理: 多个消费者可以同时读取不同分区中的消息, 每个消费者只处理其分区中的消息,并记录各自的offset,从而实现高效的并行处理。
offset在实际应用中的例子
假设有一个分区Partition 0,其中包含以下消息:
Offset: 0 1 2 3
Message: "msg1" "msg2" "msg3" "msg4"
- 消费者读取消息
- 消费者开始从offset 0读取消息,依次读取msg1, msg2, msg3
- 消费者会记录自己当前消费到的offset,例如当前消费到了offset 2(即msg3)
- 提交offset
- 消费者会定期将当前消费到的offset提交给Kafka。如果当前消费到的offset是2,那么提交的offset也是2。
- 故障恢复
- 如果消费者在消费msg3后发生故障重启,它可以从上次提交的offset(2)开始继续消费,即从msg4开始。
offset的管理
- 自动提交: kafka消费者可以配置自动提交offset(enable.auto.commit=true), kafka会定期自动提交消费者的当前offset, 这种方式简化了offset管理, 但可能导致在故障情况下重复处理
- 手动提交: 消费者可以手动管理offset,通过显式提交Offset来精确控制消费进度。这样可以在处理完一批消息后确认提交,从而保证在故障情况下不会重复处理已确认的消息。
offset存储
在Kafka 0.9版本之前,消费者的Offset存储在Zookeeper中
从Kafka 0.9版本开始,消费者组的Offset信息存储在一个名为__consumer_offsets的特殊内部Topic中。
- 存储结构:
__consumer_offsetsTopic使用Kafka自身的分区和副本机制来存储Offset。每个Partition对应着一个或多个消费者组的Offset信息。 - 持久性和可靠性:由于Offset存储在Kafka的内部Topic中,Kafka的日志机制保证了Offset信息的持久性和可靠性。
4.Kafka的安装
4.1 安装java
kafka依赖java运行环境, 因此需要先安装java
1.上传并解压安装包
1.将资料中的jdk-8u361-linux-x64.tar.gz上传到/usr/local/java目录下
mkdir /usr/local/java/
tar -zxvf jdk-8u361-linux-x64.tar.gz
2.配置环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_361
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
3.使环境变量生效
source /etc/profile
4.检查java版本
java -version
4.2 安装kafka
1.下载kafka
访问kafka官方下载页面: Kafka Downloads
- 在页面中找到最新的 Kafka 版本,例如 “2.13-3.0.0”
- 右键点击相应的 “Binary downloads” 链接并复制下载链接。
wget https://downloads.apache.org/kafka/3.7.1/kafka_2.13-3.7.1.tgz
2.解压kafka
tar -xzf kafka_2.13-3.7.1.tgz
cd kafka_2.13-3.7.1
3.启动zookeeper
Kafka 依赖于 ZooKeeper,所以首先需要启动 ZooKeeper,然后再启动 Kafka。
bin/zookeeper-server-start.sh config/zookeeper.properties
4.启动kafka
ZooKeeper 启动后,在另一个终端窗口中启动 Kafka:
bin/kafka-server-start.sh config/server.properties
4.3 集群部署
1.编辑 config/kraft/server.properties 文件:
vi config/kraft/server.properties
添加或修改以下内容:
# Broker ID, must be unique for each broker in the cluster
node.id=1
# Cluster ID, must be the same for all brokers in the cluster
# You can generate a new cluster ID using the kafka-storage tool
# and then use it for all brokers
# Example: JQXIisL1TjS-qo-ud6OeYQ
process.roles=broker,controller
controller.quorum.voters=1@broker1:9093,2@broker2:9093,3@broker3:9093
# Kafka listeners
listeners=PLAINTEXT://broker1:9092,CONTROLLER://broker1:9093
inter.broker.listener.name=PLAINTEXT
controller.listener.names=CONTROLLER
# Log directories
log.dirs=/var/lib/kafka/data
# Internal topics (e.g., __consumer_offsets) should have multiple partitions
# and a replication factor greater than 1 in production
num.partitions=1
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2
# Log retention settings
log.retention.hours=168
# Zookeeper settings are no longer needed
5.Kafka命令行操作
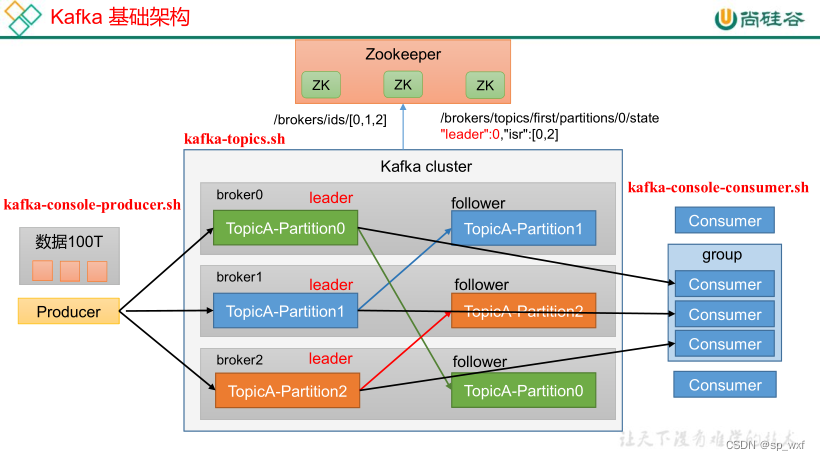
5.1 主题命令行操作
操作主题命令行参数
bin/kafka-topics.sh
| 参数 | 描述 |
|---|---|
| --bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号。 |
| --topic <String: topic> | 操作的 topic 名称。 |
| --create | 创建主题。 |
| --delete | 删除主题。 |
| --alter | 修改主题。 |
| --list | 查看所有主题。 |
| --describe | 查看主题详细描述。 |
| --partitions <Integer: # of partitions> | 设置分区数。 |
| --replication-factor<Integer: replication factor> | 设置分区副本。 |
| --config <String: name=value> | 更新系统默认的配置。 |
一、查看当前服务器中所有topic
# 连接多个节点(集群)
bin/kafka-topics.sh --bootstrap-server 192.168.202.128:9092,192.168.202.130:9092,192.168.202.131:9092 --list
二、创建first topic
bin/kafka-topics.sh --bootstrap-server 192.168.202.128:9092 --create --partitions 1 --replication-factor 3 --topic first
- --topic first:代表创建名称为first的topic
- --partitions 1:代表这个topic只有一个分区
- --replication-factor 3:代表这个topic有三个副本
三、查看first主题的详情
bin/kafka-topics.sh --bootstrap-server 192.168.202.128:9092 --describe --topic first

- Replicas: 2,0,1 代表副本存储在哪些节点中, first这个topic我们设置了3个副本,此处的2,0,1对应的就是这三个副本存储的位置(broker.id)
- Isr: 2,0,1 Isr代表同步副本, 此处2,0,1都属于同步副本(主副本也属于同步副本)
- Leader: 2 代表主副本是borker.id=2的节点
四、修改分区数
注意:分区数只能增加,不能减少
bin/kafka-topics.sh --bootstrap-server 192.168.202.128:9092 --alter --topic first --partitions 3

无法通过命令行的方式修改副本
五、删除topic
bin/kafka-topics.sh --bootstrap-server 192.168.202.128:9092 --delete --topic first
5.2 生产者命令行操作
操作生产者命令参数
bin/kafka-console-producer.sh
| 参数 | 描述 |
|---|---|
| -`-bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号。 |
| --topic <String: topic> | 操作的 topic 名称。 |
一、发送消息
bin/kafka-console-producer.sh --bootstrap-server 192.168.202.128:9092 --topic first
>hello world
>atguigu atguigu
5.3 消费者命令行操作
操作消费者命令参数
bin/kafka-console-consumer.sh
| 参数 | 描述 |
|---|---|
| -`-bootstrap-server <String: server toconnect to> | 连接的 Kafka Broker 主机名称和端口号。 |
| --topic <String: topic> | 操作的 topic 名称。 |
| --from-beginning | 从头开始消费。 |
| --group <String: consumer group id> | 指定消费者组名称。 |
一、消费first主题的数据
bin/kafka-console-consumer.sh --bootstrap-server 192.168.202.128:9092 --topic first
二、把主题中所有的数据都读取出来(包括历史数据)。
bin/kafka-console-consumer.sh --bootstrap-server 192.168.202.128:9092 --from-beginning --topic first
6.Kafka生产者
6.1 消息发送
SpringBoot引入依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
public class CustomProducer {
public static void main(String[] args) {
Properties properties = new Properties();
// 1.连接信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.202.128:9092");
// 2.配置属性
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
// 3.封装消息
ProducerRecord<String, String> record = new ProducerRecord<>("topic-name", "key", "value");
// 4.创建kafka生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
// 5.调用send方法, 发送消息
kafkaProducer.send(record);
// 6.关闭资源
kafkaProducer.close();
}
}
6.1.1 配置类
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.202.128:9092");
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
依赖注入
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
6.1.2 配置文件(.yml)
spring:
kafka:
bootstrap-servers: 192.168.202.128:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
6.2 消息发送原理
- 消息封装: KafkaProducer将消息封装成ProducerRecord
- 消息序列化: 消息发送前,通过拦截链,将消息的键和值进行序列化(Serialization)
- 消息分区: 消息发送时, 分区器会根据策略创建一个TopicPartition对象,它只包含两个字段(topic、partition), 它的作用是确保消息正确路由到指定partition
- 消息缓冲: Producer发送消息的过程并不是立即发送,而是先将消息缓冲到缓冲区(RecordAccumulator),当Deque达到一定阈值后,就会唤醒sender线程将消息发送到kafka集群
分区策略:
- 无键消息: 如果消息没有键(key),则生产者会使用轮询(Round-Robin)算法将消息分配到不同的分区,以达到负载均衡的效果。
- 有键消息: 如果消息有键(key),则生产者会对键进行哈希运算,结果决定消息被发送到哪个分区。这样具有相同键的消息总是被发送到同一个分区。
- 自定义分区器: 生产者也可以实现自定义分区逻辑,通过实现Partitioner接口来自定义分区策略。
缓冲区阈值:
RecordAccumulator中维护了一个ConcurrentMap<TopicPartition, Deque<ProducerBatch>> 类型的集合,其中的Key是TopicPartition,它用来标识目标partition(消息的最终存储位置), Value是Deque<ProducerBatch> 队列,用来缓冲发往目标partition的消息。
- 消息总大小: 当缓冲区中的消息总大小达到预设的字节数时,触发发送操作。这个阈值通常通过配置参数来设置,例如 batch.size
- 消息数量: 当缓冲区中积累了一定数量的消息时,也会触发发送操作。这个阈值也可以通过配置参数来设置,例如 linger.ms 可以间接影响消息数量的积累。
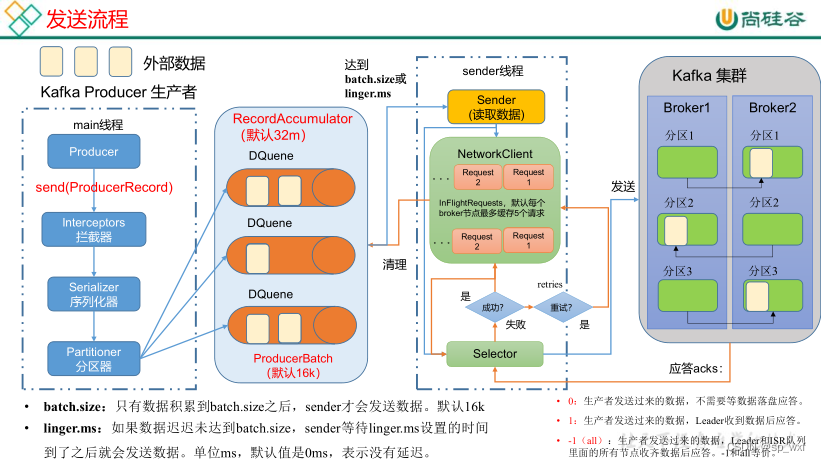
6.3 生产者参数设置
spring:
kafka:
# Kafka 服务器地址列表,用于初始化连接
bootstrap-servers:
- "kafka-broker1:9092"
- "kafka-broker2:9092"
- "kafka-broker3:9092"
producer:
# 指定发送消息的key和value的序列化类型
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 消息的确认模式(默认值是-1)
# 0:生产者不等待任何确认
# 1:生产者在Leader收到消息后会收到确认
# -1/all:Leader和所有的ISR(In-Sync Replicas)都收到消息后才会收到确认
acks: all
# 发送失败时的重试次数, 超出次数后, 可以使用回调函数进行记录日志或者异常处理(默认值是2147483647)
retries: 3
# 在每次重试之间等待的时间(毫秒)
retry-backoff-ms: 100
# RecordAccumulator缓冲区总大小(默认32MB)
# 如果消息大小超过缓冲区大小,生产者会抛出org.apache.kafka.common.errors.ProducerFencedException异常。这种情况下,生产者无法将消息缓冲到内存中,因为超出了可用的缓冲区大小。
buffer-memory: 33554432
# 缓冲队列累积的消息大小达到此值(字节)时发送消息(默认16KB)
batch-size: 16384
# 如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据(默是0ms,表示没有延迟。生产环境建议该值大小为5-100ms)
linger-ms: 5
# 单个请求的最大字节数, 如果生产者尝试发送超过这个大小的消息, Kafka 服务器会拒绝这个请求, 并返回一个相应的错误(默认1MB)
max-request-size: 1048576
# 指定消息压缩的类型, Snappy压缩算法通常被认为是一个良好的平衡
# none:不压缩消息(默认值)
# gzip:使用GZIP压缩算法进行压缩。
# snappy:使用Snappy压缩算法进行压缩。
compression-type: snappy
# 等待服务器响应的最大时间(毫秒)
request-timeout-ms: 30000
# 是否开启幂等性,开启幂等性。确保消息最终仅被添加到目标分区一次,避免消息的重复发送和重复处理。(默认true)
enable-idempotence: true
# 发送到服务器而未收到确认的请求的最大数量。开启幂等性要保证该值是1-5的数字。
max-in-flight-requests-per-connection: 5
# 用来追踪请求的来源
client-id: my-producer-client
# 自定义分区器的类名
partitioner: org.example.MyPartitioner
6.4 监听发送结果
public class CustomProducerListener implements ProducerListener<String, String> {
@Override
public void onSuccess(ProducerRecord<String, String> record, RecordMetadata metadata) {
// 消息发送成功时的处理,可以记录日志等
System.out.println("Message sent successfully: " + record.value());
}
@Override
public void onError(ProducerRecord<String, String> record, Exception exception) {
// 消息发送失败时的处理,可以记录错误日志或者执行其他逻辑
System.err.println("Error sending message: " + record.value());
exception.printStackTrace();
// 这里可以根据实际需求记录日志或者执行其他业务逻辑
}
}
6.5 同步发送
SpringBoot中使用Kafka发送消息默是异步的。这意味着当你调用 KafkaTemplate 的 send 方法发送消息时,发送操作会在后台线程中进行,而不会阻塞当前线程。这种异步发送的方式能够提升生产者发送消息的效率和性能,尤其是在高负载环境下能够更好地利用资源
如果需要同步发送消息,可以通过KafkaTemplate的send方法的返回值Future对象来实现
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, message);
// 使用 get() 方法进行阻塞等待发送结果
SendResult<String, String> result = future.get();
6.6 回调函数
回调函数会在以下情况下触发:
- 消息发送成功:当消息成功发送到 Kafka 服务器并且收到服务器的确认后,成功回调函数会被调用。此时SendResult对象包含了发送消息的元数据信息,如主题、分区、偏移量等
- 消息发送失败:如果在发送消息时发生了异常(如网络问题、Kafka 集群不可用等),失败回调函数会被调用,并且传入一个Throwable对象,表示发送过程中的异常信息。
异步处理:回调函数的执行是异步的,即使设置了回调函数,主线程也不会阻塞等待发送结果。回调函数会在后台线程中处理发送结果,以确保主线程可以继续执行其他操作。
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, msg);
// 添加回调函数
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
RecordMetadata metadata = result.getRecordMetadata();
System.out.println("Topic: " + metadata.topic() + ", Partition: " + metadata.partition()
+ ", Offset: " + metadata.offset());
}
@Override
public void onFailure(Throwable ex) {
System.err.println("Failed to send message: " + ex.getMessage());
ex.printStackTrace();
}
});
更优美的实现
kafkaTemplate.send(topic, msg).addCallback(success -> {
RecordMetadata metadata = success.getRecordMetadata();
System.out.println("Topic: " + metadata.topic() + ", Partition: " + metadata.partition()
+ ", Offset: " + metadata.offset());
}, fail -> {
System.err.println("Failed to send message: " + fail.getMessage());
});
重试过程是在Kafka生产者内部自动处理的,并不会触发回调函数。如果消息在重试次数耗尽后仍然发送失败(即无法通过重试解决的异常)此时会触发回调函数。
6.6.1 回调函数和全局监听的区别
- 实现 ProducerListener 接口:
- 需要定义一个全局的监听器,适合全局统一处理所有消息发送结果的情况。
- 可以处理更多的发送结果信息,如元数据等。
- 使用 addCallback 方法:
- 可以针对每次发送消息单独设置回调函数,更加灵活。
- 需要在每次发送消息时设置回调,比较适合需要个性化处理每条消息发送结果的情况。
6.7 生产者分区
topic被分为多个分区(partition), 每个分区可以独立的存储和管理消息
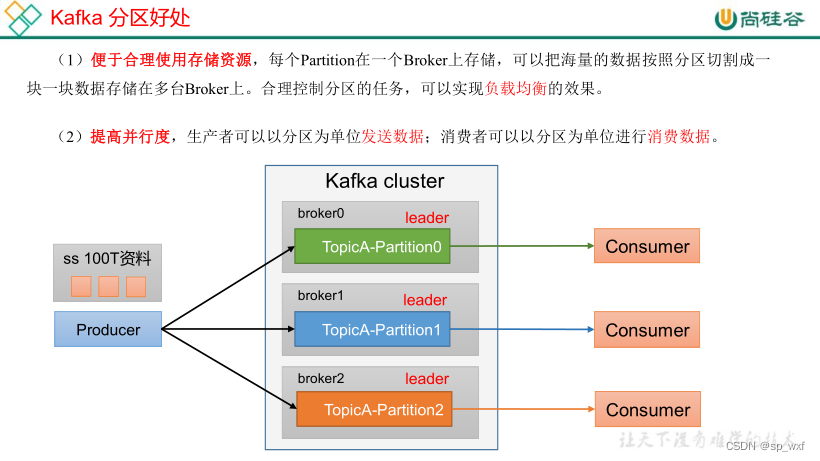
6.7.1 分区策略
将消息发送到指定partition
kafkaTemplate.send(topic, 1, "key", "value");
默认分区器: DefaultPartitioner

6.7.2 自定义分区器
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
public class CustomPartitioner implements Partitioner {
@Override
public void configure(Map<String, ?> configs) {
// 初始化配置
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
int numPartitions = cluster.partitionsForTopic(topic).size();
// 示例:将消息内容中包含特定关键字的消息发送到特定分区
if (value instanceof String) {
String stringValue = (String) value;
if (stringValue.contains("important")) {
return 0; // 发送到分区0
}
}
// 默认分区逻辑:轮询
return Math.abs((key == null ? 0 : key.hashCode()) % numPartitions);
}
@Override
public void close() {
// 清理资源
}
}
# application.yml
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
properties:
partitioner.class: com.example.kafka.CustomPartitioner
7.生产经验
7.1 生产者如何提高吞吐量
Deque达到一定阈值后,就会唤醒sender线程将消息发送到kafka集群, 这个阈值受两个参数影响: batch.size、linger.ms
- batch.size: 批次大小, 默认16K, 当Deque中的积压的消息达到16K后, 就会唤醒sender线程将消息打包发送到同一个分区
- linger.ms: 等待时间,默认为0, 如果消息迟迟没有达到16K, 此时会根据linger.ms设置的时间, 来唤醒sender线程发送消息
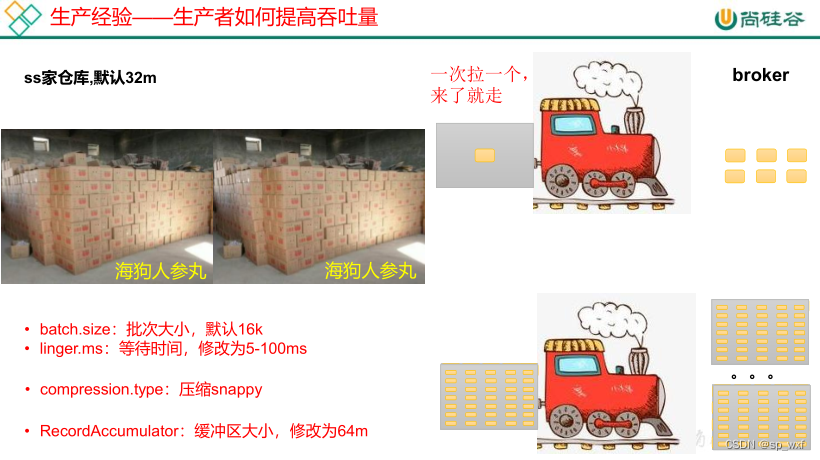
所以在生产环境中, 我们一般会修改linger.ms的值, 改为5~100ms, 而batch.size使用默认值即可
7.2 数据可靠性
7.2.1 ack机制
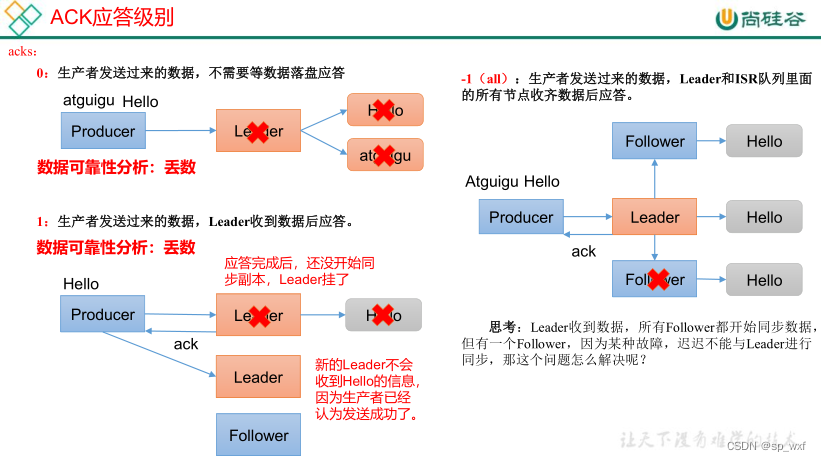
- ack=0: 生产者发送消息后, 不需要等待任何来自服务器的响应
- 优点: 消息只发送一次, 不会被重复消费, 且吞吐量高
- 缺点: 如果当中出现问题,导致服务器没有收到消息, 没有落盘到partition,生产者无从得知,会造成消息丢失
- ack=1: 生产者发送消息后, 等待分区的leader收到数据后应答
- 缺点: 如果leader落盘成功了, 向producer也收到了成功响应, 但是还没来得及将消息同步副本(follower), 此时leader挂了, 此时服务器会从follower中推选新的leader, 新的leader并没有同步消息, 而producer也不会再发了, 此时消息就丢失了
- ack=-1或者all: 生产者发送过来的数据, leader和ISR队列里面的所有节点都落盘成功后, 进行应答
7.2.2 ISR机制
在Kafka中,数据被分成多个主题(Topic),每个主题又被划分为多个分区(Partition)。每个分区可以有多个副本(Replica),这些副本分布在不同的Kafka broker上,以确保数据的高可用性和容错性。
对于每个分区,Kafka选举一个leader副本来处理所有的读写请求。其余的副本称为follower 副本,它们从leader副本复制数据,以保持数据的一致性。
ISR = leader副本 + 所有与leader副本保持同步的follower副本组成的集合
ISR 的特点
- 包括Leader:ISR中的leader是该分区的主要副本,
负责处理所有的写入请求。 - 包含Synchronized Followers:所有在ISR中的follower副本都是已与leader同步的副本。
- 动态变化:如果一个follower副本落后于leader超过一定的阈值,它会被从ISR中移除。当它重新赶上leader后,会重新加入 ISR。
ISR的剔除
- 复制滞后:如果一个 follower 副本落后于 leader 副本的日志位置超过一定阈值(由 replica.lag.time.max.ms 配置项控制),则该 follower 会被从 ISR 中移除。
- 心跳超时:如果一个 follower副本在一定时间内没有向leader发送心跳(由 replica.lag.time.max.ms 控制),它也会被从ISR中移除。
重新加入ISR
重新加入ISR是一个自动化的过程,follower副本重新连接到集群后, follower副本会向leader 副本发送Fetch请求,获取当前leader副本的最新日志位置(即 high watermark), follower副本接收到这些日志条目后,会将它们追加到自己的本地日志文件中。这个过程会不断重复,直到follower副本的日志位置赶上leader副本。在追赶过程中,follower 副本会持续向 leader 副本发送心跳信号,以表明它仍然健康并且正在努力同步数据。
一旦 follower 副本的日志位置赶上 leader 副本,并且它能够持续发送心跳信号,leader 副本会将其重新加入 ISR 集合。
7.2.3 数据完全可靠条件
Broker配置(server.properties)
- 副本因子: 每个分区副本至少为3(保证1个leader副本+2个follow副本), 如果创建topic时, 没有显式指定副本因子, Kafka会使用
default.replication.factor设置的值。 - 最小同步副本数: 确保写入时ISR中的副本数量至少为2个(1个leader副本+1个follow副本), 否则写入请求会被拒绝
- ISR是动态的, 受副本同步状态的影响。即使你设置了
default.replication.factor=3, 实际的ISR可能少于3个, 例如某些副本被剔除了。 - 将min.insync.replicas设置为2,副本因子为3,可以容忍一个副本故障(只要2个副本保持同步即可)
- ISR是动态的, 受副本同步状态的影响。即使你设置了
- 日志保留:配置日志保留时间和大小,以保证数据在一定时间内不被删除。
- 配置副本同步:设置允许副本滞后的最大时间,以确保副本能够及时跟上 leader。
# 设置副本因子
default.replication.factor=3
# 设置最小同步副本数
min.insync.replicas=2
# 设置日志保留时间和大小
log.retention.hours=168 # 保留一周
log.retention.bytes=1073741824 # 1 GB
# 设置允许的副本滞后时间
replica.lag.time.max.ms=10000
生产者配置
- acks:将生产者的 acks 配置设置为 all(也可以用 -1 表示)。这意味着生产者会等待所有 ISR 副本确认消息写入后才会收到确认。
- retries:配置生产者的重试次数,以处理临时的网络或 broker 故障。
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all"); // 确保所有 ISR 副本确认
props.put("retries", 3); // 配置重试次数
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
7.3 生产者重复发送消息
很多情况下会导致生产者重复发送消息
- 网络问题: 在网络不稳定的情况下,生产者发送的消息可能无法及时得到确认。生产者可能会因为超时或网络错误而重新发送消息,导致重复发送.
- 生产者重启: 如果生产者在发送消息后但在收到确认之前重启,生产者可能会再次发送同样的消息。
- 服务器端超时: 如果Kafka broker没有在指定时间内向生产者发送确认,生产者可能会认为消息发送失败并重试。
- 消息确认机制: 如果生产者的acks参数设置为1或0,则在网络或其他异常情况下,可能会导致消息发送确认不一致,从而触发重试。
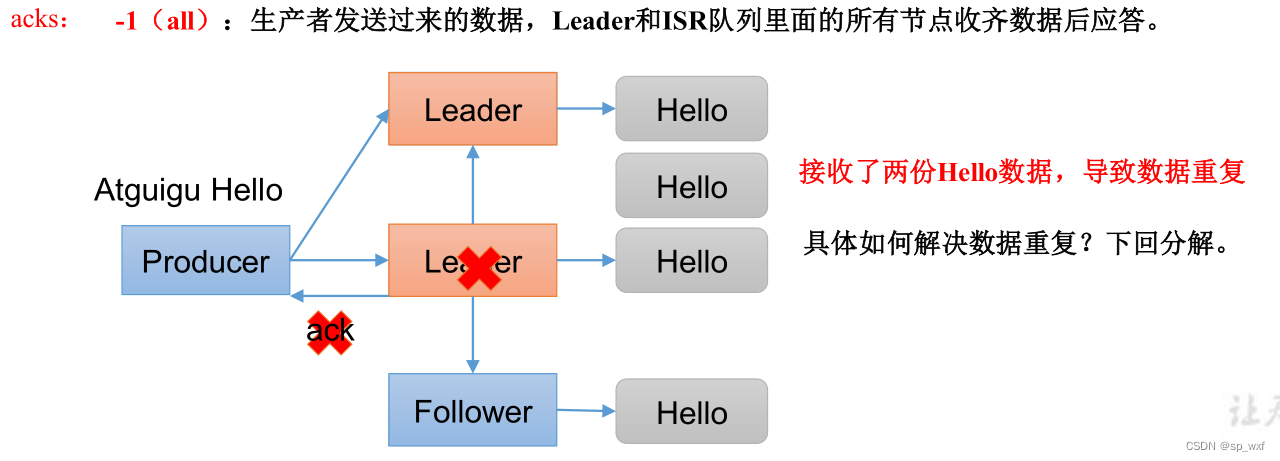
我们可以举一个特殊例子:
ack为-1, leader收到数据后, 将数据落盘, 并将数据同步给所有follower, 在响应ack时leader宕机了, 此时服务器会重新挑选一个follower成为leader, 而这个新的leader其实已经落盘了消息 , 但producer迟迟没收到leader的响应, 会因为超时或网络问题而重试发送消息。
7.4 精确一次
1.至少一次(At Least Once)
生产者会确保每条消息至少发送一次,但在某些情况下,可能会因为重试机制导致消息被发送多次。
它确保消息不丢失,但可能会重复发送,适用于需要高可靠性但可以容忍重复的场景。
实现方案:
# 设置副本因子
default.replication.factor=3
# 设置最小同步副本数
min.insync.replicas=2
spring:
kafka:
producer:
acks: -1
2.最多一次
生产者会确保每条消息只发送一次,不论成功与否
它确保消息不重复发送,但可能会丢失,适用于可以容忍消息丢失但不允许重复的场景。
实现方案:
spring:
kafka:
producer:
retries: 0
acks: 0
3.精确一次(Exactly Once)
通过使用幂等性和事务性机制,确保每条消息被精确传递一次,既不丢失也不重复。
实现方式:
精确一次 = 幂等性 + 事务性 + 至少一次
7.4.1 幂等性
生产者幂等性是Kafka提供的一种机制,用于确保在网络故障或重试情况下,生产者发送的消息不会被重复写入Kafka主题。幂等性机制使得生产者即使多次发送同一条消息,Kafka 也只会将其存储一次,从而避免消息重复。
幂等性机制的工作原理
Kafka 的生产者幂等性依赖于以下几个关键组件:
- Producer ID (PID):生产者ID,每个Kafka生产者实例在启动时会生成一个唯一的生产者 ID。这个ID在整个生命周期内保持不变,用于唯一标识一个生产者实例。
- Sequence Number:每条消息在生产者内都有一个唯一的序列号。序列号是单调递增的。(确保消息在生产者端的顺序性)
生产者重复发送同一条消息, 其Sequence Number是不变的, Kafka服务器通过记录PID + Sequence Number来判断消息是否已经成功写入到分区的日志中。
如果消息的生产者 ID 和序列号与已处理过的消息匹配,Kafka 就会知道这是一条重复发送的消息,并且可以忽略或者返回已确认的状态,而不会再次将该消息追加到分区中。
幂等性生产者的工作流程如下:
- 消息发送:生产者发送消息时, 会将Producer ID以及Sequence Number附加到消息中
- 确认机制: kafka服务器接收到消息后, 会尝试将消息追加到对应的分区日志中, 在这个过程中, 会检测消息的Producer ID以及Sequence Number是否已经追加过(日志中是否已经存在)
- 如果日志中没有这个Producer ID和Sequence Number,表明这是一条新消息,则服务端会将该消息追加到对应分区的日志中,并返回确认响应给生产者。
- 如果服务端在之前已经接收过具有相同Producer ID和Sequence Number的消息,就会直接返回一个已确认的响应,表示消息已经处理过,不需要重复写入。
不论日志中是否已经存在Producer ID和Sequence Number, 最终都会向生产者返回确认响应
如何使用幂等性
spring:
kafka:
producer:
properties:
enable:
idempotence: true
配置enable.idempotence=true后,Kafka生产者会自动升级为幂等性生产者,这会确保生产者在发送消息时按照幂等性的规则进行操作,即通过Producer ID和Sequence Number来确保消息的唯一性和顺序性。
7.4.2 生产者事务
前置条件:
- 设置enable.idempotence=true来启用幂等性,这在启用事务时是必需的。
- 配置transactional.id来为生产者指定一个唯一的事务ID。
yml配置
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
properties:
enable:
idempotence: true
transaction:
transactional-id: my-transactional-id
使用事务
@Transactional
public void sendMessage(String topic, String key, String message) {
kafkaTemplate.executeInTransaction(tpl -> {
tpl.send(topic, key, message);
int i = 1/0;
return true;
});
}
- send:消息被发送到Kafka,这些消息的写入不会立即对消费者可见,因为事务还未提交。
- int i = 1/0: 抛出异常导致事务回滚
- 因事务回滚,Kafka将撤销事务中的所有操作,即使消息已经写入分区日志,这些消息也会被删除或标记为无效。
数据有序
kafka只能保证单分区数据有序, 多分区时, 分区与分区间无序
数据乱序
- kafka在1.x及以后版本保证数据单分区有序,条件如下:
- 未开启幂等性
max.in.flight.requests.per.connection需要设置为1。 - 开启幂等性
max.in.flight.requests.per.connection需要设置小于等于5。
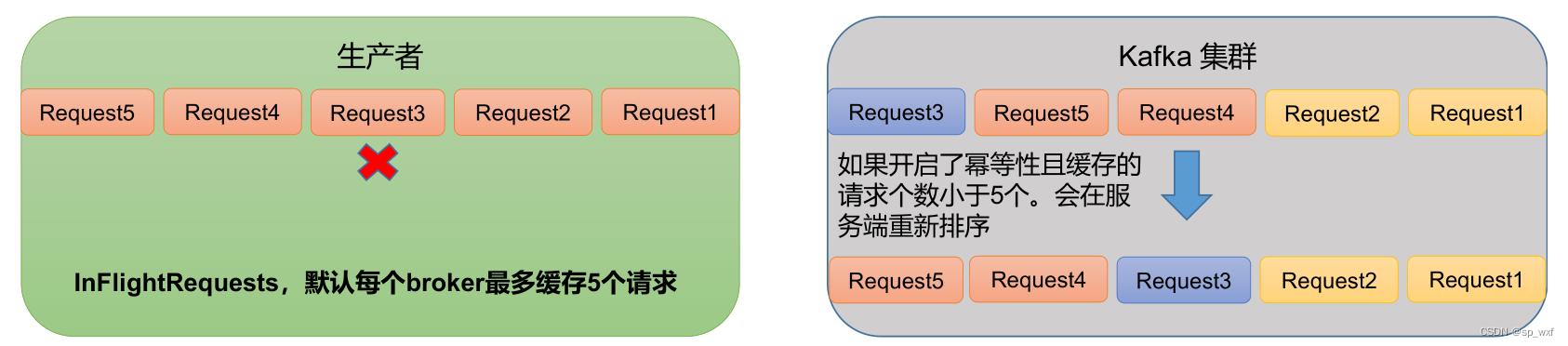
原因说明:因为在kafka1.x以后,启用幂等后,kafka服务端会缓存producer发来的最近5个request的元数据,故无论如何,都可以保证最近5个request的数据都是有序的。(原理是使用了幂等性的Sequence Number, 连续5个消息会自动根据Sequence Number排序)
- 未开启幂等性
4.Kafka Broker
4.1 Kafka Broker工作流程
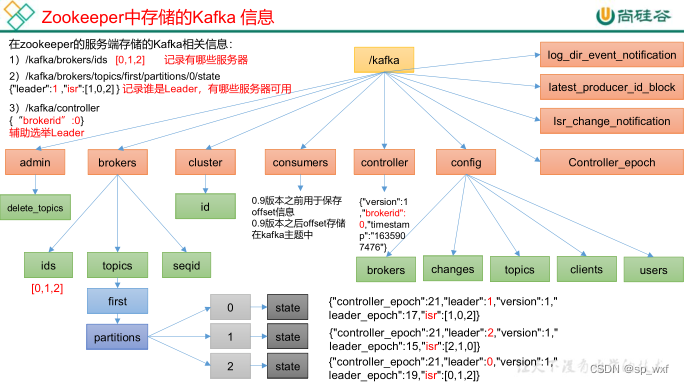
4.1.1 Zookeeper存储的 Kafka 信息
一、启动zookeeper客户端
bin/zkCli.sh
二、通过 ls 命令可以查看 kafka 相关信息。
ls /kafka
4.1.2 Kafka Broker总体工作流程
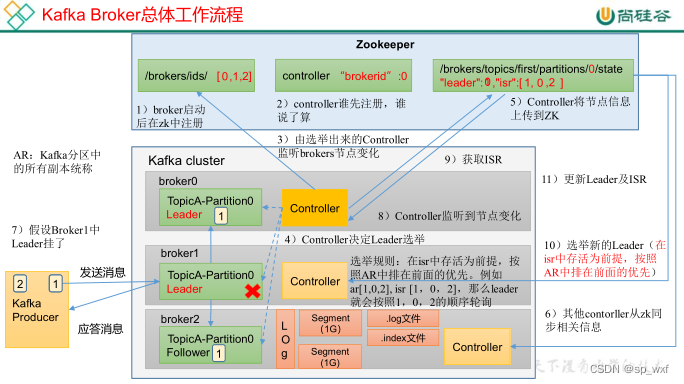
一、controller的概念
在Kafka集群中,某个Broker将被选举出来担任一种特殊的角色,其用于管理和协调Kafka集群,即管理集群中的所有分区的状态并执行相应的管理操作。每个Kafka集群任意时刻都只能有一个Controller。当集群启动时,所有Broker都参与Controller的竞选,最终有一个胜出,一旦Controller在某个时刻崩溃,集群中的其他的Broker会收到通知,然后开启新一轮的Controller选举,新选举出来的Controller将承担起之前Controller的所有工作。
二、controller的作用
- 维护每台Broker上的分区副本信息
- 维护每个分区的Leader副本信息
三、controller为每个分区选举leader
选举规则:在isr中存活为前提, 按照AR中排在前面的优先, 例如AR[1, 0, 2], ISR[1, 2], 那么leader会按照1,2的顺序轮巡
对于topicA的partition0这个分区,它选举出broker1作为leader, 而broker0、broker2作为follower, controller会把这个信息告诉zookeeper(将节点信息上传到zookeeper),这是为了防止controller挂了后, 新的controller不知道主副本信息
4.1.2 Kafka Broker上线与下线
模拟 Kafka 上下线,Zookeeper 中数据变化
一、查看/kafka/brokers/ids 路径上的节点。
[zk: localhost:2181(CONNECTED) 2] ls /kafka/brokers/ids
[0, 1, 2]
二、查看/kafka/controller 路径上的数据。
[zk: localhost:2181(CONNECTED) 15] get /kafka/controller
{"version":1,"brokerid":0,"timestamp":"1637292471777"}
三、查看/kafka/brokers/topics/first/partitions/0/state 路径上的数据。
显示first这个topic中id为0的partitions的情况
[zk:localhost:2181(CONNECTED)16] get/kafka/brokers/topics/first/partitions/0/state
{"controller_epoch":24,"leader":0,"version":1,"leader_epoch":18,"isr":[0,1,2]}
4.1.3 Broker 重要参数
| 参数名称 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR中,如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值,默认30s。 |
| auto.leader.rebalance.enable | 默认是 true。 自动Leader Partition 平衡。 |
| leader.imbalance.per.broker.percentage | 默认是10%。每个broker允许的不平衡的leader的比率。如果每个broker超过了这个值,控制器会触发leader的平衡。 |
| leader.imbalance.check.interval.seconds | 默认值 300 秒。检查 leader 负载是否平衡的间隔时间。 |
| log.segment.bytes | Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分 成块的大小,默认值 1G |
| log.index.interval.bytes | 默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。 |
| log.retention.hours | Kafka 中数据保存的时间,默认 7 天。 |
| log.retention.minutes | Kafka 中数据保存的时间,分钟级别,默认关闭。 |
| log.retention.ms | Kafka 中数据保存的时间,毫秒级别,默认关闭。 |
| log.retention.check.interval.ms | 检查数据是否保存超时的间隔,默认是 5 分钟。 |
| log.retention.bytes | 默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的 segment。 |
| log.cleanup.policy | 默认是 delete,表示所有数据启用删除策略;如果设置值为 compact,表示所有数据启用压缩策略。 |
| num.io.threads | 默认是 8。负责写磁盘的线程数。整个参数值要占总核数的 50%。 |
| num.replica.fetchers | 副本拉取线程数,这个参数占总核数的 50%的 1/3 |
| num.network.threads | 默认是 3。数据传输线程数,这个参数占总核数的50%的 2/3 |
| log.flush.interval.messages | 强制页缓存刷写到磁盘的条数,默认是 long 的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。 |
| log.flush.interval.ms | 每隔多久,刷数据到磁盘,默认是 null。一般不建议修改,交给系统自己管理。 |
4.2 生产经验—节点服役和退役
4.2.1 服役新节点(todo)
4.2.2 退役旧节点(todo)
4.3 Kafka副本
4.3.1 副本基本信息
一、kafka副本的作用
- kafka副本的作用:提高数据的可靠性
- kafka默认副本1个, 生产环境一般配置2个, 保证数据可靠性; 太多副本会增加磁盘存储空间, 增加网络上传数据传输, 降低效率
- kafka中副本分为:Leader和Follower, kafka生产者只会把数据发往Leader, 然后follower自己找leader进行数据同步
- kafka分区中所有的副本统称为AR(Assigned Repllicas), AR = ISR + OSR
- ISR: 表示和 Leader 保持同步的 Follower 集合。
如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。 - OSR: 表示 Follower 与 Leader 副本同步时,延迟过多的副本。
- ISR: 表示和 Leader 保持同步的 Follower 集合。
4.3.2 Leader选举流程
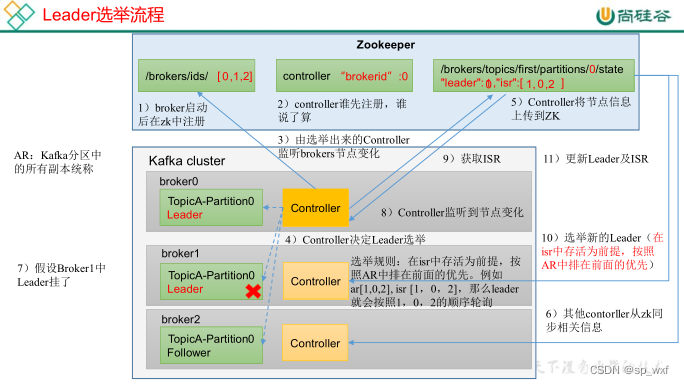
一、Controller Leader
Kafka 集群中有一个broker的Controller会被选举为Controller Leader,负责管理集群broker 的上下线,所有topic的分区副本分配和Leader选举等工作。(Controller的信息同步工作是依赖于Zookeeper的)
1.创建一个新的topic, 设置4个分区, 4个副本
bin/kafka-topics.sh --bootstrap-server 192.168.202.128:9092 --create --topic atguigu1 --partitions 4 --replication-factor 4
Created topic atguigu1.
2.查看这4个分区的leander分布情况
bin/kafka-topics.sh --bootstrap-server 192.168.202.128:9092 --describe --topic atguigu1
Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1Partition: 0 Leader: 3 Replicas: 3,0,2,1 Isr: 3,0,2,1
Topic: atguigu1Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,2,3,0
Topic: atguigu1Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,3,1,2
Topic: atguigu1Partition: 3 Leader: 2 Replicas: 2,1,0,3 Isr: 2,1,0,3
3.停止其中一个kafka的进程, 查看Leader分区的状况
其中我们停到了Broker.id=3的节点, 我们发现分区0的leader原本是节点3. 但是因为节点3挂了, 所以ISR中重新找到节点0作为leader
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,2,1
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,2,0
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1,2
Topic: atguigu1 Partition: 3 Leader: 2 Replicas: 2,1,0,3 Isr: 2,1,0
4.停止Broker.id=2的节点, 并查看 Leader 分区情况
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,1
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,0
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1
Topic: atguigu1 Partition: 3 Leader: 1 Replicas: 2,1,0,3 Isr: 1,0
5.重新启动关停的kafka节点, 查看leader分区的状况
我们发现leader已经选举成功后, 并不会因为节点的重启再去选举一次
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,1,3,2
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,0,3,2
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1,3,2
Topic: atguigu1 Partition: 3 Leader: 1 Replicas: 2,1,0,3 Isr: 1,0,3,2
4.3.3 Leader和Follower故障处理细节(todo)
4.3.4 分区副本分配
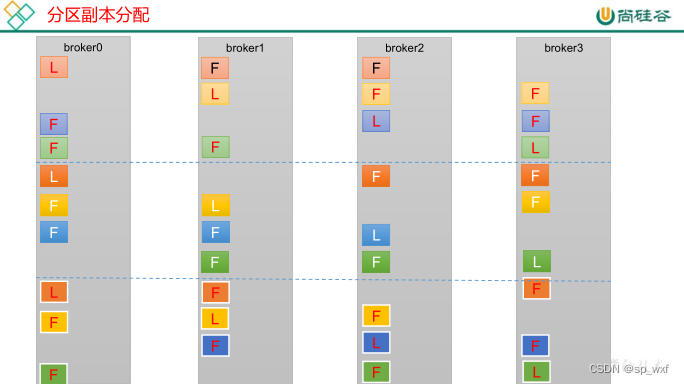
如果kafka服务器只有4个节点, 那么设置kafka的分区数 > 服务器台数, 在kafka底层是如何分配存储副本的呢?
1.创建16个分区, 3个副本
创建一个新的 topic,名称为 second。
bin/kafka-topics.sh --bootstrap-server 192.168.202.128:9092 --create --partitions 16 --replication-factor 3 --topic second
2.查看分区和副本情况
Topic: second4 Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: second4 Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: second4 Partition: 2 Leader: 2 Replicas: 2,3,0 Isr: 2,3,0
Topic: second4 Partition: 3 Leader: 3 Replicas: 3,0,1 Isr: 3,0,1
Topic: second4 Partition: 4 Leader: 0 Replicas: 0,2,3 Isr: 0,2,3
Topic: second4 Partition: 5 Leader: 1 Replicas: 1,3,0 Isr: 1,3,0
Topic: second4 Partition: 6 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: second4 Partition: 7 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: second4 Partition: 8 Leader: 0 Replicas: 0,3,1 Isr: 0,3,1
Topic: second4 Partition: 9 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: second4 Partition: 10 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
Topic: second4 Partition: 11 Leader: 3 Replicas: 3,2,0 Isr: 3,2,0
Topic: second4 Partition: 12 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: second4 Partition: 13 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: second4 Partition: 14 Leader: 2 Replicas: 2,3,0 Isr: 2,3,0
Topic: second4 Partition: 15 Leader: 3 Replicas: 3,0,1 Isr: 3,0,1
4.3.5 手动调整分区副本存储
在生产环境中,每台服务器的配置和性能不一致,但是Kafka只会根据自己的代码规则创建对应的分区副本,就会导致个别服务器存储压力较大。所有需要手动调整分区副本的存储。
需求:创建一个新的topic,4个分区,两个副本,名称为three。将该topic的所有副本都存储到broker0和broker1两台服务器上。

1.创建一个新的 topic,名称为 three。
bin/kafka-topics.sh --bootstrap-server 192.168.202.128:9092 --create --partitions 4 --replication-factor 2 --topic three
2.创建副本存储计划
所有副本都指定存储在 broker0、broker1 中
vim increase-replication-factor.json
输入如下内容:
{
"version":1,
"partitions":[
{"topic":"three","partition":0,"replicas":[0,1]},
{"topic":"three","partition":1,"replicas":[0,1]},
{"topic":"three","partition":2,"replicas":[1,0]},
{"topic":"three","partition":3,"replicas":[1,0]}
]
}
3.执行副本存储计划
bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.202.128:9092 --reassignment-json-file increase-replication-factor.json --execute
4.3.6 生产经验—Leader Partition 负载平衡(todo)
正常情况下,Kafka本身会自动把Leader Partition均匀分散在各个机器上,来保证每台机器的读写吞吐量都是均匀的。但是如果某些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,这会导致少数几台broker的读写请求压力过高,其他宕机的broker重启之后都是follower partition,读写请求很低,造成集群负载不均衡。















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









