







目录
kafka producer 发送消息流程
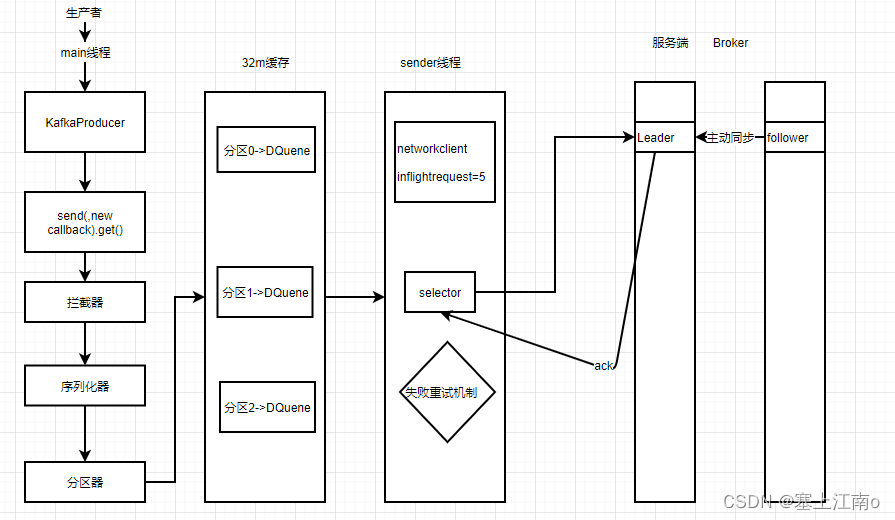
在消息发送的过程中,涉及到了两个线程:main线程和Sender线程。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka Broker
- 主线程:main线程将消息发送给RecordAccumulator
- 封装消息对象ProducerRecord,然后调用send方法将数据发送出去
- 数据依次会进入拦截器、序列化器(将数据对象序列化)、分区器(计算数据应该发送到哪个分区。有几个分区,后续会创建几个队列)
- 随后数据会送往到内存缓存RecordAccumulator中(默认大小32m),然后将不同分区的数据封装到不同的Deque中
- sender线程:Sender线程不断从RecordAccumulator中拉取数据发送到Kafka Broker(发送的条件为batch.size=16k,或者达到linger.ms的阈值)
- Producer客户端会发送Request请求到Kafka Broker,最多发送5个(由参数inflightrequests控制)。原因是,Producer客户端发送Request请求到Kafka Broker,理应上需要得到Kafka Broke中leader的ack应答,表示是否接收数据成功,但是为了考虑效率,Producer客户端可以暂时不必非要等到Kafka Broke中leader的ack,才去发送下一批数据,而是继续保持发送Request请求,发送数据给kafka集群,但是当发送的Request请求达到5个时,则就必须要求kafka集群返回ack应答了,否则将不会发送任何数据
- 请求发送过去以后,就开始传输数据了,数据是通过Selector进行传输的
- 数据到达kafka broker后,follwer就开始主动向leader同步数据,然后leader就会返回ack应答给Selector,告诉客户端这边数据是否同步数据成功。若成功,客户端这边就会删除对应的Request,再删除对应分区的数据;若失败,则客户端进行重试发送(重试次数int最大值)
kafka 异步发送和同步发送
send()方法处,涉及到异步发送和同步发送
- 异步发送
异步发送又分为普通异步发送(默认方式)和带回调函数callback的异步发送
普通异步发送
表现形式:send()
sender线程将数据从Deque中取出发送到kafka集群时,若不管Deque中的数据有没有真正的被送到kafka集群,源头数据依旧还源源不断的写入内存队列Deque中,这种方式被称之为异步发送
带回调函数callback的异步发送
表现形式:send(new callback())
触发时机:producer收到ack时
- 同步发送
表现形式:send().get()
sender线程将数据从Deque中取出发送到kafka集群时,需要等内存队列中的数据被真正的被送到kafka集群后,源头数据才能继续被写入内存队列Deque中,这种方式被称之为同步发送
kafka 分区的好处
(1)方便在集群中扩展
每个Partition可以通过调整大小,以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了
(2)可以提高并发
因为可以,以Partition为单位读写
kafka 分区的策略
kafka的分区器可以指定数据发送到broker的哪个分区,也可以不指定,这些都是由参数进行控制的
(1)参数中指明数据发送到哪个分区
(2)参数中没有指明数据发送到哪个分区,但指明了 key,这种情况下,将 key 的 hash 值与 topic 的 partition 数进行取余,然后决定将数据发送到哪个分区
(3)参数中既没有指明数据发送到哪个分区,又没有指明 key ,这种情况下,它会随机的将数据发送到一个分区,待该分区满后,会在随机选择一个分区
kafka 如何提高吞吐量
调整的是哪个阶段的参数:
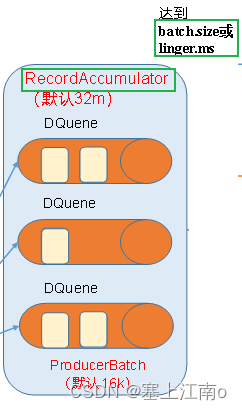
都有哪些参数可调(具体调多少,需要进行测试)
1)32m缓存 =》 64m
2)批次大小默认16k => 32k
3)linger.ms 默认是0ms => 5-100ms
4)采用压缩 snappy zstd
kafka ISR
kafka 数据可靠性保证
数据完全可靠条件 = ACK设置为“-1” + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
解释:
- 分区副本大于等于2—>数据2份以上才叫可靠
- ISR里应答的最小副本数量大于等于2—>意思是ISR中至少有1个leader和1个follower
kafka ACK应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等ISR中的follower全部接收成功,因此Kafka为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置
acks参数配置:
0:producer不等待leader的ack,意思就是producer只管发数据给leader,不管leader是否将数据成功写入磁盘就离开了。如果leader接收到数据后,突然挂了,会导致丢失数据
1:producer等待leader落盘成功后返回ack,可靠性相对较高。如果在follower同步成功之前leader故障,那么将会丢失数据
-1(all):producer等待leader和ISR中所有follower落盘成功后返回ack,可靠性高,性能相对较慢。如果在follower同步完成后,leader发生故障,producer收不到leader的ack,那么随后它会重发数据,故会造成数据重复
如何选择ack级别:
在生产环境中,acks=0不用; acks = 1,一般用于传输普通日志,允许丢个别数据; ack = -1,一般用于传输和钱相关的数据,对可靠性要求比较高的场景
ack = -1
会造成数据的重复,而金融行业恰恰要求数据既不重复又不丢失,那需要怎么办?
那就需要生产者事务和幂等性的配合了,生产者事务和幂等性可以保证数据的精确
kafka 精确一次
Kafka 0.11版本以后,引入了一项重大特性:幂等性和事务。这两项的加持下,可以做到数据既不丢失,又不重复,俗称精确一次
kafka 幂等性
概念:幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证不重复
kafka为了实现幂等性,引入了《pid,分区号,序列号》,当发送数据时,会判读3者是否和上一批数据相同,若相同,则认为是同一批数据,然后过滤掉,否则,落盘数据
幂等性的缺点:
幂等性只能保证单会话内数据不重复。因为其中的PID,会当Kafka重启都会分配一个新的,且Sequence Number是单调自增的
怎么解决幂等性的缺点?
幂等性需要和事务进行配合,才能完全保证数据全局不重复
kafka 事务
内部原理
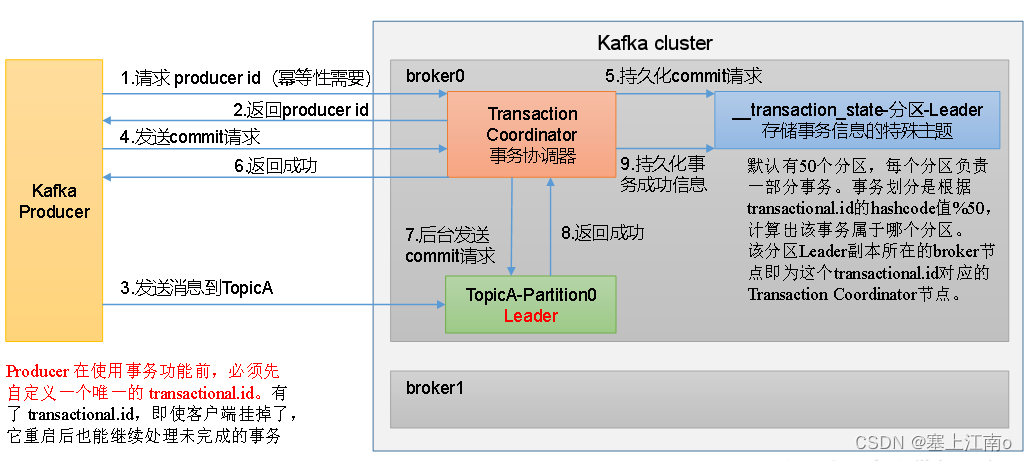
事务主要通过
5个API来实现
// 1初始化事务
void initTransactions();
// 2开启事务
void beginTransaction() throws ProducerFencedException;
// 3在事务内提交已经消费的偏移量(主要用于消费者)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws ProducerFencedException;
// 4提交事务
void commitTransaction() throws ProducerFencedException;
// 5放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;
kafka 至少一次、最多一次、精确一次
| 作用 | 怎么做 |
|---|---|
| 至少一次可以保证数据不丢失,但是不能保证数据不重复 | 至少一次(At Least Once) = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2 |
| 最多一次可以保证数据不重复,但是不能保证数据不丢失 | 最多一次(At Most Once) = ACK级别设置为0 |
| 精确一次可以做到数据既不丢失,又不重复 | 生产者幂等性+事务 |
kafka 如何保证数据有序
指定分区器只将数据送往到一个分区中。若送往到不同分区中,无法保证数据有序。如果就想要保证不同分区数据有序,只有在下游处理数据时,进行全局排序
kafka单分区内数据有一定有序吗?
sender线程那里最多帮我们缓存5个请求,5个请求在依次送往broker时,不一定都能一次性成功,若在发送第二个请求时失败了,重试后,就有可能排在第三个请求后,所以单分区内数据也有可能无序
如何保证kafka单分区内接收到的数据有序
1)设置max.in.flight.requests.per.connection=1,即设置为同步发送
2) 开启幂等性
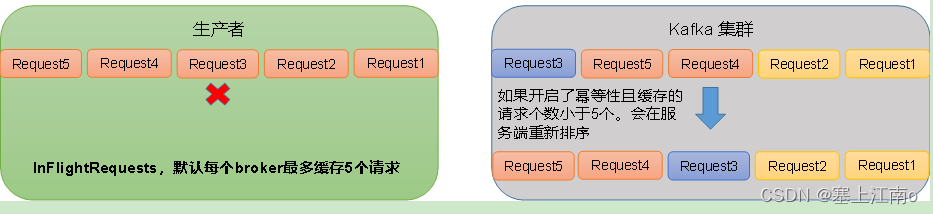
原因说明:启用幂等性后,kafka服务端会在内存缓存producer发来的5个request的元数据信息,假设分别为request1、request2、request3、request4、request5,kafka服务端当接收到request1、request2时,会按照顺序进行落盘(根据幂等性原则),若此时request3没有及时到达kafka服务端,但request4、request5却到达了,那么kafka服务端会先让request4、request5进行等待,直到request3到达以后,才将所有的request按照顺序依次进行落盘
kafka 故障处理细节
(1)follower故障
follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步,等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了
(2)leader故障
leader发生故障之后,会从ISR中选出一个新的 leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复















 30
30











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









