









case具有两种格式。简单case函数和case搜索函数。

这两种方式,可以实现相同的功能。简单情况下函数的写法相对比较简洁,但是和搜索函数相比,功能方面会有些限制,比如写判定式。
还有一个需要注重的问题,情况下函数只返回第一个符合条件的值,剩下的情况下,部分将会被自动忽略。

一,已知数据按照另外一种方式进行分组,分析。(分组函数+case函数)
如有以下数据
| 国家 | 人口 |
|---|---|
| 中国 | 600 |
| 美国 | 100 |
| 加拿大 | 100 |
| 英国 | 200 |
| 法国 | 300 |
| 日本 | 250 |
| 德国 | 200 |
| 墨西哥 | 50 |
| 印度 | 250 |
统计亚洲和北美洲的人口数量,怎么求?
通过案例函数,SQL如下


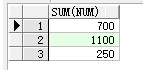
原理:我们要统计每个洲的人数,首先要将国家按洲来分组,中国,日本,印度是亚洲,美国,加拿大,墨西哥是美洲,实现分组后,通过求和聚合函数就能查出每个洲多少人
但是呢!没有洲名明显不能满足我们的要求,那怎么才能加上洲名呢?受分组函数的限制,select后面加列只能是聚合函数和被分组的列,此处被分组的列为country,那我们能直接用country吗?当然不能,因为country这个列的原本的分组逻辑已经改变了,而如果要查询这个列就得用被修改后的分组逻辑来查

| 洲 | 人口 |
|---|---|
| 亚洲 | 1100 |
| 北美洲 | 250 |
| 其他 | 700 |
例2:
| 姓名 | 工资 |
|---|---|
| 小王 | 800 |
| 小张 | 450 |
| 小陈 | 100 |
| 小明 | 250 |
| 小赵 | 300 |
| 小李 | 650 |
| 小沈 | 500 |
| 小孙 | 50 |
| 小唐 | 700 |
其中我们根据工资分为4个等级0~200等级1 200~400等级2 400~600等级3 600~800等级4
select
count(*) as count,
case when salary>=0 and salary<200 then '等级1'
when salary>=200 and salary<400 then '等级2'
when salary>=400 and salary<600 then '等级3'
when salary>=600 and salary<=800 then '等级4'
else null end as Grade
from Payroll group by
case when salary>=0 and salary<200 then '等级1'
when salary>=200 and salary<400 then '等级2'
when salary>=400 and salary<600 then '等级3'
when salary>=600 and salary<=800 then '等级4'
else null end;
| count | grade |
|---|---|
| 2 | 等级1 |
| 2 | 等级2 |
| 2 | 等级3 |
| 3 | 等级4 |
二,用一个sql语句完成不同条件的分组
有如下数据
| 国家(country) | 性别(sex) | 人口(population) |
|---|---|---|
| 中国 | 1 | 340 |
| 中国 | 2 | 260 |
| 美国 | 1 | 45 |
| 美国 | 2 | 55 |
| 加拿大 | 1 | 51 |
| 加拿大 | 2 | 49 |
| 英国 | 1 | 40 |
| 英国 | 2 | 60 |
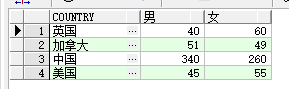
需求:按照国家和性别进行分组:国家–男--女
思路:以country分组,显示的列为country和对应的聚合函数,那聚合函数怎么构造出’男’和’女’列呢?
很简单,对分组后的sex列做判断,如果sex=1,表示为男,此时统计男性总数,sex=2,表示为女,统计女性总数
SELECT country,
-- 原理:分组后,是对组进行操作,第二列的意思就是取此组中,sex=1的记录的population的总和
SUM( CASE WHEN sex = '1' THEN
population ELSE 0 END) as 男,
SUM( CASE WHEN sex = '2' THEN
population ELSE 0 END) as 女
FROM sex_count
GROUP BY country;
三,check中使用case函数
扩展:check约束用于限制列中值的取值范围

需求:插入的女职工记录条中的工资必须大于1000
create table sex_salary(
name varchar(24),
sex number,
salary number,
CONSTRAINT check_salary CHECK
( CASE WHEN sex = 2
THEN CASE WHEN price > 1000 THEN 1 ELSE 0 END
ELSE 1 END = 1 )
)
如果单纯使用check,但是这样的话,女职员的条件可以符合,但男职员就无法输入了
CONSTRAINT check_salary CHECK
( sex = '2' AND salary > 1000 )
四,根据条件有选择的更新。
有以下数据:
| 姓名 | 工资 |
|---|---|
| 小王 | 5000 |
| 小李 | 4600 |
| 小张 | 3000 |
需求:
- 工资5000以上的职员,工资减少10%
- 工资在2000到4600之间的职员,工资增加15%
很容易考虑的是选择执行两次UPDATE语句
但是事情没有想象得那么简单,假设有个人工资5000块。首先,按照条件1,工资减少10%,变成工资4500.接下来运行第二个SQL时候,因为这个人的工资是4500在2000到4600的范围之内,需增加15%,最后这个人的工资结果是5175,不但没有减少,反而增加了。如果要是反过来执行,那么工资4600的人相反会变成减少工资。
- 条件1
UPDATE update_salary
SET salary = salary * 0.9
WHERE salary> = 5000;
- 条件2
UPDATE update_salary
SET salary = salary * 1.15
WHERE 薪金> = 2000 AND 薪金<4600;
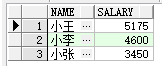
如果想要一个SQL语句实现这个功能的话,我们需要用到案例函数。代码如下:

注意:最后一行的ELSE薪水是必需的,要是没有这行,不符合这两个条件的人的工资将会被写成NULL,那可就大事不妙了在案件函数中否则部分的默认值是NULL,这点是需要注意的地方
这种方法还可以在很多地方使用,比如说变更主键这种累活。
一般情况下,要想把两条数据的主键,一和b交换,需要经过临时存储,拷贝,读回数据的三个过程,要是使用案例函数的话,一切都变得简单多了。
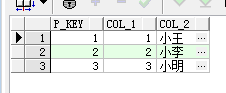

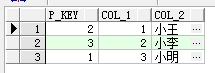
同样的也可以交换两个独特的钥匙。需要注意的是,如果有需要交换主键的情况发生,多半是当初对这个表的设计进行得不够到位,建议检查表的设计是否妥当
五,两个表数据是否一致的检查。
Case函数不同于DECODE函数。在Case函数中,可以使用BETWEEN,LIKE,IS NULL,IN,EXISTS等等。比如说使用IN,EXISTS,可以进行子查询,从而实现更多的功能。
有两个表,tbl_A,tbl_B,两个表中都有keyCol列。现在我们对两个表进行比较,tbl_A中的keyCol列的数据如果在tbl_B的keyCol列的数据中可以找到,返回结果’匹配”,如果没有找到,返回结果 ‘不匹配’。
A 表 B表
B表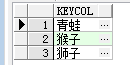
select keycol , case when keycol in (select keycol from tbl_B) then '匹配' else '不匹配' end as IsMathch from tbl_A;
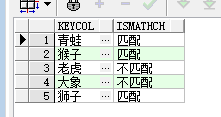
六,在Case函数中使用合计函数
假设有下面一个表

有的学生选择了同时修几门课程(100,200)也有的学生只选择了一门课程(300,400,500)。选修多门课程的学生,要选择一门课程作为主修,主修里面写入Y.只选择一门课程的学生,主修标志为N(实际上要是写入Ý的话,就没有下面的麻烦事了,为了举例子,还请多多包含)。
现在我们要按照下面两个条件对这个表进行查询
- 只选修一门课程的人,返回那门课程的ID
- 选修多门课程的人,返回所选的主课程ID
条件1
select s_id,
case when count(1)=1 then max(c_id) else
max( case when flag = 'Y' then c_id else null end)
end as c_id
from study group by s_id;















 1488
1488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









