




目录
reduceByKey、aggregateByKey、foldByKey、combinByKey对比
spark 介绍
-
hadoop缺点
mapreduce 对于数据的复用就是简单得将中间数据写入到一个稳定的文件系统中(例如HDFS),所以会产生数据的复制备份,磁盘的I/O已经数据的序列化,所以在遇到需要多个计算中间结果的操作时效率会非常低。这类操作有迭代计算、交互式数据挖掘、图计算
-
spark 相较于hadoop的优点
- 减少磁盘I/O
- 增加并行度
- 避免重新计算
- 可选的shuffle和排序
- 完善的生态圈
-
spark 运行模式
- local 本地模式,学习测试使用
- standalone 独立集群模式--学习测试使用 (master/slave 模式)
- standalone-HA 高可用模式--生产环境使用 (基于zk搭建高可用)
- on yarn 集群模式--生产环境使用
- on mesos 集群模式--使用少
- on cloud 集群模式--中小公司会更多的使用云服务
RDD
1) RDD 是什么?
RDD叫做弹性分布式数据集,是spark中最基本的数据抽象。
它代表一个弹性的、不可变、可分区、里面元素可并行计算的集合
弹性
- 存储的弹性:内存与磁盘的自动切换
- 容错的弹性:数据丢失可以自动恢复
- 计算的弹性: 计算出错重试机制
- 分片的弹性: 可根据需求重新分片
分布式:数据存储在大数据集群不同节点上
数据集: RDD封装了计算逻辑,并不保存数据
数据抽象: RDD是一个抽象类,需要子类具体实现
不可变:RDD封装了计算逻辑,是不可变的
可分区、并行计算
2) RDD属性
(1) 一组分片(partition),即数据集的基本组成单位。每个分片都会被一个计算任务处理,用用户可以创建RDD时指定分片个数,如果没有指定,就会采用默认值。默认值就是程序所分配到的cpu core的数目
(2)一个计算每个分区的函数,每个RDD都会实现compute函数达到这个目的,compute函数会对迭代器进行复合,不需要保存每次计算的结果
(3) RDD之间的依赖关系。RDD每次转换都会生成一个新的RDD,形成DAG图,当部分分区数据丢失时,spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对所有分区进行计算
(4)RDD的分片函数(Partitioner),两种分片函数HashPartitioner(哈希)和RangerPartitioner(范围)。只有key-value的RDD,才会有Partitioner,非key-value的RDD的Partitioner的值是None。
Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD shuffle
(5)一个列表,存储存取每个partition的优先位置
RDD 一个分区内执行是有序的,不同分区数据计算是无序的
3)算子
Transformation 转换算子
- map
- mapPartition
以分区为单位进行数据转换,将整个分区的数据加载到内存进行引用,如果处理完的数据不会被释放,存在对象的引用。在内存较小,数据量较大的场合下,容易出现内存溢出
map和mapPartition区别
- 数据处理角度
Map算子是分区内一个数据一个是数据的执行,类似于串行操作。
而mapPartitions算子是以分区为单位进行批处理操作
- 功能的角度
map不会增多或减少数据、输入几条,输出几条。mapPartitions需要传入一个迭代器,返回一个迭代器,可以增加或减少数据
- 性能的角度
map算子类似串行操作,性能低
mapPartitions性能高,但是容易内存溢出,素以内存有限时不推荐用
- mapPartitionsWithIndex
rdd.mapPartitionsWithIndex((index,iter)=>{ if(index==0){ iter }else{ Nil.iterator } }).collect().foreach(println)可根据index区分分区,做操作
- groupBy
根据指定的规则进行分组,分区默认不变,但是数据会被打乱重新组合,会产生shuffle
- filter
val rdd=sc.makeRDD(List(1,2,3,4),2) rdd.filter(num=>num==2).collect().foreach(println)结果:2
问题:当数据进行过滤后,分区不变,但是分区内的数据可能不均衡,产生数据倾斜
- sample
def sample(
withReplacement: Boolean, //是否放回
fraction: Double,// 概率
seed: Long = Utils.random.nextLong // 随机种子): RDD[T] = {
require(fraction >= 0,
s"Fraction must be nonnegative, but got ${fraction}")
withScope {
require(fraction >= 0.0, "Negative fraction value: " + fraction)
if (withReplacement) {
//当为true ,走泊松分布
new PartitionwiseSampledRDD[T, T](this, new PoissonSampler[T](fraction), true, seed)
} else {
//当为false,走伯努利分布
new PartitionwiseSampledRDD[T, T](this, new BernoulliSampler[T](fraction), true, seed)
}
}
}
- distict
//map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
// (1,null),(2,null),(3.null),(4.null),(4,null)
// (1,null),(2,null),(3.null),(4.null)
//(1,null)=>1
// rdd.map(x => (x, null)).reduceByKey((x, _) => x, 2).map(_._1).foreach(println)
-
rdd.coalesce
重分区,默认shuffle为false。 会出现,数据倾斜
def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty) (implicit ord: Ordering[T] = null)
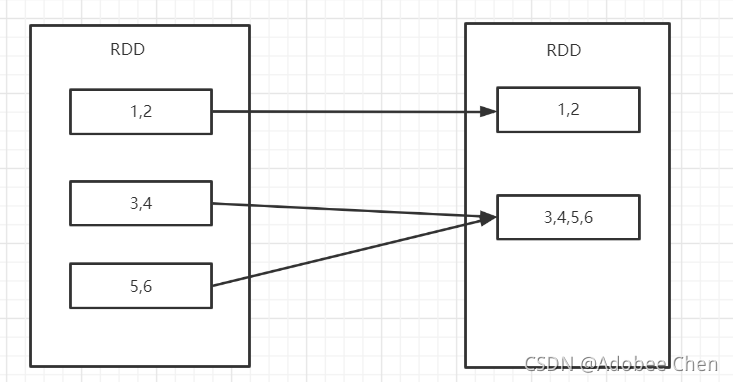
- repartition,底层实际调用了coalesce中shuffle为true方法
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}- sortBy
rdd.sortBy(_._1.toInt,false).foreach(println)def sortBy[K]( f: (T) => K, ascending: Boolean = true, numPartitions: Int = this.partitions.length) (implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]ascending: 升序排序
- 交集 并集 差集 拉链
/** * 交集、并集、差集、拉链 */ 交集、并集、差集:两个rdd之间的数据类型相同 val rdd=sc.makeRDD(List(1,2,3,4),1) val rdd1=sc.makeRDD(List(2,5,3,4),1) //交集 rdd.intersection(rdd1).foreach(println) //并集 rdd.union(rdd1).foreach(println) //差集 rdd.subtract(rdd1).foreach(println) 拉链:分区相同,并分区中个数相同,不要求元素类型相同 // (1,2) (2,5) (3,3) (4,4) rdd.zip(rdd1).foreach(println)
key-value
- groupByKey
分组,没有聚合操作
- reduceByKey
分组、聚合、并有combin
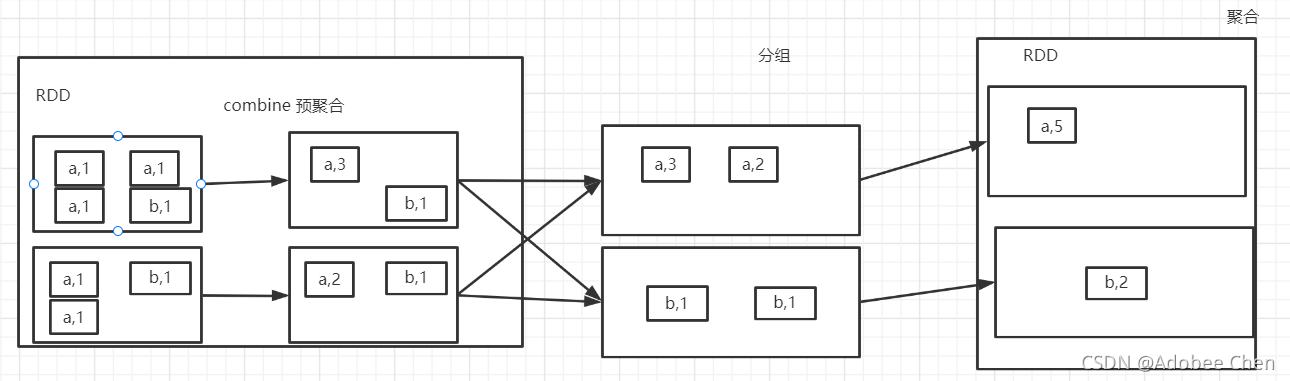
- aggregateByKey
分区内:一个分区内部
分区间:多个分区落盘后进行的操作
/**
第一个参数分区内计算规则
第二个参数分区间计算规则
给一个zeroValue,当第一个值进来时候,与zeroValue进行计算
*/
rdd.aggregateByKey(0)(
(x,y)=>Math.max(x,y),
(x,y)=>x + y
).foreach(println)
- foldByKey
/** 分区内和分区间的计算规则相同 */ rdd.foldByKey(0)(_+_).foreach(println)
-
combineByKey
第一个参数表示: 将相同key的第一个数据进行结构的转换
第二个参数表示: 分区内的计算规则
第三个参数表示: 分区间的计算规则
reduceByKey、aggregateByKey、foldByKey、combinByKey对比
最终都是调用combineByKeyWithClassTag
def combineByKeyWithClassTag[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope { require(mergeCombiners != null, "mergeCombiners must be defined")
-
join(key相同的组合成tuple)
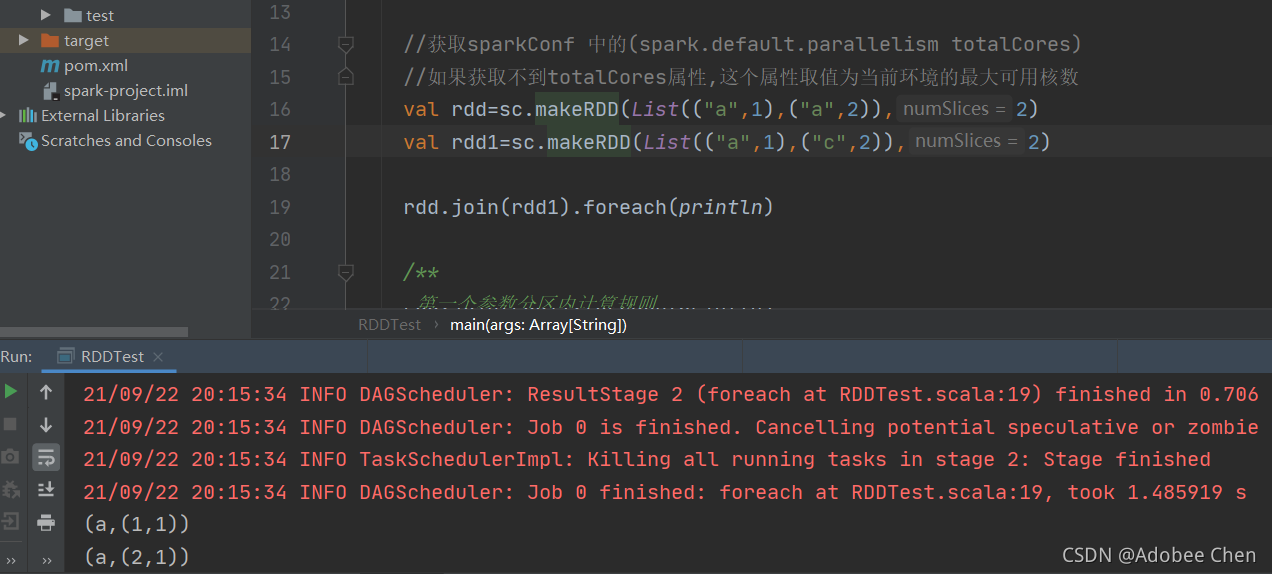
- leftOuterJoin
- rightOuterJoin
- cogroup
cogroup: connect +group
相同的key放在同一组,进行连接
action 算子
- reduce
- collect
以array数组的形式返回数据集的所有元素
方法会将不同分区的数据按照分区顺序采集到Driver端内存中
-
count
-
first 获取数据源中第一个
-
take 取多少个
-
takeOrdered
排过序的取多少个
-
aggregate
val rdd=sc.makeRDD(List(1,2,3,4),2) //每个分区的分区内第一个加上初始值
rdd.aggregate(10)(_+_,_+_)
结果为40
aggregate初始值参与分区内和分区间的计算
10+1 + 2=13
10 +13 +10+3+4=40
aggregate初始值只参与分区内的计算
10+1+2=13 13+10+3+4=30
-
fold
分区内和分区间计算逻辑相同时,可用fold
rdd.fold(10)(_+_)
-
countByKey
相同key出现的次数
-
countByKey 值出现了几次
val rdd=sc.makeRDD(List(1,2,1),2) rdd.countByValue().foreach(println)

-
foreach
-
save
闭包的概念
闭包是函数,它的返回值取决于此函数之外声明一个或多个变量的值。
def f(x:Int) = (i : Int) => (x+i)
即函数值若想被创建必须捕获i的值,这一过程可以被理解为做对函数执行“关闭”操作,所以叫闭包。
在spark中,runJob之前,会进行clean闭包




















 669
669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









