







前言
最近复习Python基础,正好把之前在aistudio做的爬虫demo复习一下
上网全过程:
普通用户:
打开浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 渲染到页面上。
爬虫程序:
模拟浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 提取有用的数据 --> 保存到本地/数据库。
爬虫的过程:
1.发送请求(requests模块)
2.获取响应数据(服务器返回)
3.解析并提取数据(BeautifulSoup查找或者re正则)
4.保存数据
任务描述
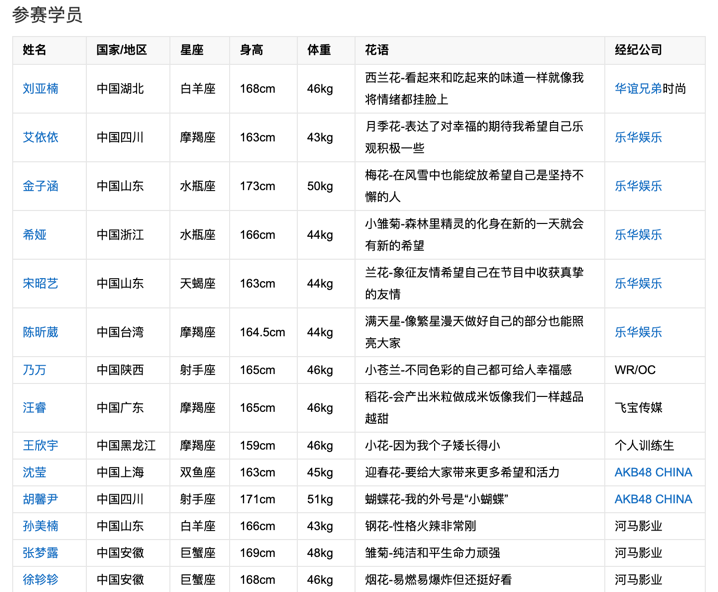
使用Python来爬取百度百科中《青春有你2》所有参赛选手的信息。
数据获取:https://baike.baidu.com/item/青春有你第二季
爬虫模块简介
request
requests是python实现的简单易用的HTTP库,官网地址:http://cn.python-requests.org/zh_CN/latest/
requests.get(url)可以发送一个http get请求,返回服务器响应内容。
BeautifulSoup
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库。网址:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml。
BeautifulSoup(markup, "html.parser")或者BeautifulSoup(markup, "lxml"),推荐使用lxml作为解析器,因为效率更高。
具体流程
一、爬取百度百科中《青春有你2》中所有参赛选手信息,返回页面数据
import json
import re
import requests
import datetime
from bs4 import BeautifulSoup
import os
#获取当天的日期,并进行格式化,用于后面文件命名,格式:20200420
today = datetime.date.today().strftime('%Y%m%d')
def crawl_wiki_data():
"""
爬取百度百科中《青春有你2》中参赛选手信息,返回html
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
url='https://baike.baidu.com/item/青春有你第二季'
try:
response = requests.get(url,headers=headers)
print('code = {}'.format(response.status_code))
# print('response.text:\n{}'.format(response.text))
#将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象, 可以传入一段字符串
soup = BeautifulSoup(response.text,'lxml')
#返回的是class为table-view log-set-param的<table>所有标签
tables = soup.find_all('table',{
'class':'table-view log-set-param'})
crawl_table_title = "参赛学员"
# 因为有多个相同样式的表格,所以找相关的参考,例如前面元素的“参赛学员”
for table in tables:
#对当前节点前面的标签和字符串进行查找
table_titles = table.find_previous('div').find_all( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6279
6279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









