






4、网络
技术栈:
1、计算机网络体系结构
OSI分层 (7层):物理层、数据链路层(网桥,交换机)、网络层(IP,ICMP,ARP)、传输层(TCP,UDP)、会话层、表示层、应用层。
TCP/IP分层(4层):网络接口层、 网际层、运输层、 应用层。
五层协议 (5层):物理层、数据链路层、网络层、运输层、 应用层。
2、ARP是地址解析协议,简单语言解释一下工作原理
ARP 实现由 IP 地址得到 MAC 地址
主机A广播发送ARP请求分组(源主机IP地址,源主机MAC地址,目的主机的IP地址)
主机B向A发送ARP响应分组(源主机IP地址,源主机MAC地址)
1:首先,每个主机都会在自己的ARP缓冲区中建立一个ARP列表,以表示IP地址和MAC地址之间的对应关系。
2:src发送:
当源主机要发送数据时,首先检查ARP列表中是否有对应IP地址的目的主机的MAC地址
如果有,则直接发送数据;
如果没有,就向本网段的所有主机发送ARP数据包,该数据包包括的内容有:源主机IP地址,源主机MAC地址,目的主机的IP地址。
3:dst接受:
当本网络的所有主机收到该ARP数据包时:
首先检查数据包中的IP地址是否是自己的IP地址,如果不是,则忽略该数据包;
如果是,则首先从数据包中取出源主机的IP和MAC地址写入到ARP列表中,如果已经存在,则覆盖,然后将自己的MAC地址写入ARP响应包中,告诉源主机自己是它想要找的MAC地址。
4:dst发送:
源主机收到ARP响应包后。将目的主机的IP和MAC地址写入ARP列表,并利用此信息发送数据。
如果源主机一直没有收到ARP响应数据包,表示ARP查询失败。
3、TCP
是一种面向连接的、可靠的、基于字节流的传输层通信协议
(1)可靠性保证:
-
数据包校验:目的是检测数据在传输过程中的任何变化,若校验出包有错,则丢弃报文段并且不给出响应,这时TCP发送数据端超时后会重发数据;
-
对失序数据包重排序:既然TCP报文段作为IP数据报来传输,而IP数据报的到达可能会失序,因此TCP报文段的到达也可能会失序。TCP将对失序数据进行重新排序,然后才交给应用层;
-
丢弃重复数据:对于重复数据,能够丢弃重复数据;
-
应答机制:当TCP收到发自TCP连接另一端的数据,它将发送一个确认。这个确认不是立即发送,通常将推迟几分之一秒;
-
超时重发:当TCP发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段;
-
流量控制:TCP连接的每一方都有固定大小的缓冲空间。TCP的接收端只允许另一端发送接收端缓冲区所能接纳的数据,这可以防止较快主机致使较慢主机的缓冲区溢出,这就是流量控制。TCP使用的流量控制协议是可变大小的滑动窗口协议。
(2)滑动窗口
TCP由于存在确认应答机制,在一方发出一条消息以后,另一方要发送ACK表明自己收到消息。
如果按照下面这种形式,每次收到ACK才发出下一条消息,这种一发一收的效率太低。但是如果客户端不急着接收ACK,可以利用等待ACK的空挡直接发送下一批数据,这样就可以做到短时间内发送多批数据。这就是滑动窗口的基本思想。
滑动窗口可能出现的状况:
(1)中间报文丢了
假设客户端依次发送1001-2000,2001-3000,3001-4000
客户端如果连续多次(一般是连续三次)收到了2001的确认应答,说明序号为2001之后的报文丢了,此时就会重传2001~3000的报文;服务端收到2001~3000的报文以后,由于之前已经收到了3001~4000 的报文(暂时存放在接收缓冲区),那么服务端相当于已经收到了全部的报文,此时服务端发送的确认序号是 4001,表明4001之前的报文已经全部收到(4001+ACK)
(2)后发送的报文先收到了ACK
原因:要么丢了 要么网络延时到达
如果开了sack选项(net.ipv4.tcp_sack),表示会选择性地重传未回ACK的报文;否则,会重传开始丢失的报文段之后的所有报文
(3)滑动窗口大小为0时,何时才能继续发送数据?
原因:对方上层的处理速度较慢,导致对方接收缓冲区里的数据没有被取走
解决方法:
a、发送方定期发送不携带数据的报文
发送方定期可以发送一个不携带数据的报文,报文不携带数据,也就不会占用服务端的缓冲区,接收方返回的ACK中会携带窗口大小,以此来判断是否可以继续发送数据。
b、接收方缓冲区一旦更新立马通知发送方
接收方的上层把数据取走的时候,服务端主动发送一个窗口更新的通知报文,该报文不携带任何数据,只是在报文首部设置了16位窗口大小
(3)拥塞控制:
1、慢启动
由小到大逐渐增加拥塞窗口的大小
2、拥塞避免
让拥塞窗口缓慢增长,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1,而不是加倍,这样拥塞窗口按线性规律缓慢增长
设置一个慢开始门限 ssthresh,当 cwnd >= ssthresh 时,进入拥塞避免,每个轮次只将 cwnd 加 1
如果出现了超时,则令 ssthresh = cwnd / 2,然后重新执行慢开始
3、快重传
在接收方,要求每次接收到报文段都应该对最后一个已收到的有序报文段进行确认。如果收到三个重复确认,那么可以知道下一个报文段丢失,此时执行快重传,立即重传下一个报文段。
例如已经接收到 M1 和 M2,此时收到 M4,应当发送对 M2 的确认;收到三个 M2,则 M3 丢失,立即重传 M3
4、快恢复
当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把ssthresh门限减半,但是接下去并不执行慢开始算法
4、TCP 三次握手
客户端A 服务端B

(1)A向B发送请求报文,SYN=1,ACK=0,选择一个初始序号seq=x。
(2)B 收到连接请求报文,如果同意建立连接,则向 A 发送连接确认报文,SYN=1,ACK=1,确认号为ack= x+1,同时也选择一个初始的序号 seq=y。
(3)A 收到 B 的连接确认报文后,还要向 B 发出确认,确认号为ack= y+1,序号为 seq=x+1。
B 收到 A 的确认后,连接建立。
5、TCP四次挥手
客户端A 服务端B
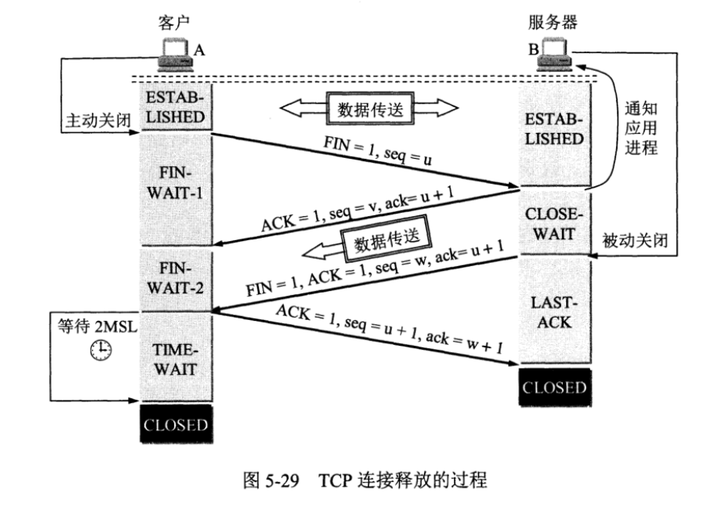
(1)A 发送连接释放报文,FIN=1(表明此报文段的发送方的数据已发送完毕,并要求释放运输连接)。
(2)B 收到之后发出确认,此时 TCP 属于CLOSE-WAIT状态,让服务器端发送还未传送完毕的数据,即B 能向 A 发送数据但是 A 不能向 B 发送数据。
(3)当 B 不再需要连接时,发送连接释放报文,FIN=1。
(4)A 收到后发出确认,进入 TIME-WAIT 状态,等待 2 MSL(最大报文存活时间)后释放连接。
cat /proc/sys/net/ipv4/tcp_fin_timeout -> 60s
-
B 收到 A 的确认后释放连接。
为什么A在TIME-WAIT状态必须等待2MSL的时间呢?
为了保证A发送的最后一个ACK报文段能够到达B;
防止“已经失效的连接请求报文段”出现在本链接中。
为什么建立连接协议是三次握手,而关闭连接却是四次握手呢?
当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了,所以你可能未必马上会关闭SOCKET,也即你可能还需要发送一些数据给对方之后,再发送FIN报文给对方来表示你同意现在可以关闭连接了
问题定位思路:
案例分析:
1、农行客户反馈异常堆栈信息
背景:
客户在业务高峰时间段,部分请求失败,进程fullgc增多,整体loadaverage较高,机器性能差,有许多sync_sent状态的tcp连接。整体物理机为132U,故障点cpu和内存占用率都不高,软中断较多。客户分析内核日志,发现部分时间点有一些堆栈信息,怀疑是因为异常而打印。同时客户他结合bug链接,打印比较相似,怀疑可能因为触发内核bug导致的网络异常。
分析过程:
messages打印
Call Trace: <IRQ> nf_nat_ipv4_out+0x87/0xa0 [nf_nat_ipv4] nf_hook_slow+0x43/0xc0 ip_output+0xd2/0xe0 ? ip_fragment+0x70/0x70 ip_forward+0x36b/0x460 ? ip4_key_hashfn+0xb0/0xb0 ip_rcv+0x28c/0x350 ? inet_del_offload+0x40/0x40 __netif_receive_skb_core+0xac6/0xbc0 ? update_dl_rq_load_avg+0x10f/0x210 ? process_backlog+0x9f/0x150 process_backlog+0x9f/0x150 net_rx_action+0x156/0x3f0 ? sched_clock+0x5/0x10
疑似补丁
netfilter: nat: can't use dst_hold on noref dst · torvalds/linux@542fbda · GitHub
A.触发场景:
1、dst代码属于路由缓存相关,dst_entry结构体表示ip数据包的路由,其中的__refcnt是路由的引用计数,路由创建成功后即设为1,删除即为0;
2、dst指针(属于dst_entry结构体)的引用计数被清零,但是由于等待rcu列表延时释放,下次调用的时候就会触发零引用计数问题
B.原理:
rcu存在延时释放的机制,在读取过程中,另外一个线程删除了一个节点。删除线程可以把这个节点从链表中移除,但它不能直接销毁这个节点,必须等到所有的读取线程读取完成以后,才进行销毁操作
C.代码逻辑:
1、在dst_release中会调用call_rcu,call_rcu会注册回调函数dst_destroy_rcu,在所有读取线程reader完成后才会调用dst_destroy_rcu销毁rcu并释放dst
2、newrefcnt从1减到0后由于延时释放无法立即释放dst,故导致存在零引用计数
D.影响:
1、当查不到路由cache 后(下一跳地址的cache),会通过 dst_alloc() 创建一个 dst_entry 结构,即创建一条路由缓存;泄漏一个dst_entry是192B,都不到1KB
2、系统上ipv4路由缓存相关参数默认配置为-1,表示路由缓存数目不限制,大概率不会泄露很多内存,但还是建议合入补丁;
warning打印
WARNING: CPU: 31 PID: 1130809 at ./include/net/dst.h:252 nf_xfrm_me_harder+0x13b/0x150 [nf_nat]
对应代码
static inline void dst_hold(struct dst_entry *dst)
{
/*
* If your kernel compilation stops here, please check
* the placement of __refcnt in struct dst_entry
*/
BUILD_BUG_ON(offsetof(struct dst_entry, __refcnt) & 63);
WARN_ON(atomic_inc_not_zero(&dst->__refcnt) == 0); //当refcnt为0时触发,表明这里的引用计数异常
}
调用关系
nf_xfrm_me_harder
dst_hold
WARN_ON(atomic_inc_not_zero(&dst->__refcnt) == 0);
skb_dst_drop(skb);
refdst_drop(skb->_skb_refdst);
dst_release((struct dst_entry *)(refdst & SKB_DST_PTRMASK));
newrefcnt = atomic_dec_return(&dst->__refcnt); //refcnt减一赋值给newrefcnt
//newrefcnt<0 打印refcnt不做任何处理
//否则会去释放dst
//udp到ip层
ip_send_skb //将skb交给ip协议层
ip_local_out
dst_output
skb_dst(skb)->output(net, sk, skb); //rt->dst.output = ip_output; rt_dst_alloc里面定义
ip_output
//tcp到ip层
ip_queue_xmit
ip_local_out
ip_output
nf_hook_slow
NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING, net, sk, skb, NULL, dev, ip_finish_output, !(IPCB(skb)->flags & IPSKB_REROUTED));
nf_hook(pf, hook, net, sk, skb, in, out, okfn); //ip_finish_output对应于okfn
nf_hook_state_init(&state, hook, pf, indev, outdev, sk, net, okfn); //state->okfn被赋值为ip_finish_output
ret = nf_hook_slow(skb, &state, hook_head, 0);
----verdict = nf_hook_entry_hookfn(&e->hooks[s], skb, state);
entry->hook(entry->priv, skb, state);
nf_nat_ipv4_out //.hook = nf_nat_ipv4_out, 在nf_nat_ipv4_ops里面
err = nf_xfrm_me_harder(state-net, skb, AF_INET);
dst_hold
WARN_ON(atomic_inc_not_zero(&dst->__refcnt) == 0);
skb_dst_drop(skb);
refdst_drop(skb->_skb_refdst);
dst_release((struct dst_entry *)(refdst & SKB_DST_PTRMASK));
newrefcnt = atomic_dec_return(&dst->__refcnt); //refcnt减一赋值给newrefcnt
//如果newrefcnt<0,打印refcnt
//否则释放dst
----如果返回值verdict为NF_DROP
kfree_skb(skb);
合入补丁前
int nf_xfrm_me_harder(struct net *net, struct sk_buff *skb, unsigned int family)
{
struct flowi fl;
unsigned int hh_len;
struct dst_entry *dst;
int err;
err = xfrm_decode_session(skb, &fl, family);
if (err < 0)
return err;
dst = skb_dst(skb);//旧dst
if (dst->xfrm)
dst = ((struct xfrm_dst *)dst)->route;
dst_hold(dst);
dst = xfrm_lookup(net, dst, &fl, skb->sk, 0);
if (IS_ERR(dst))
return PTR_ERR(dst);
skb_dst_drop(skb); //打印refcnt: -1 不会走到dst_destroy_rcu去释放dst导致泄漏
skb_dst_set(skb, dst);
/* Change in oif may mean change in hh_len. */
hh_len = skb_dst(skb)->dev->hard_header_len;
if (skb_headroom(skb) < hh_len &&
pskb_expand_head(skb, hh_len - skb_headroom(skb), 0, GFP_ATOMIC))
return -ENOMEM;
return 0;
}
合入补丁后
1、遇到引用计数为0直接退出,return EHOSTUNREACH的错误码,并且在上层调用nf_hook_slow函数调用中有释放skb的操作 2、错误码解释:no route to host,没有到达主机的路由,即路由表里面没有到达目标主机的表项,也没有默认网关项。
int nf_xfrm_me_harder(struct net *net, struct sk_buff *skb, unsigned int family)
{
struct flowi fl;
unsigned int hh_len;
struct dst_entry *dst;
int err;
err = xfrm_decode_session(skb, &fl, family);
if (err < 0)
return err;
dst = skb_dst(skb);
if (dst->xfrm)
dst = ((struct xfrm_dst *)dst)->route;
if (!dst_hold_safe(dst))
return -EHOSTUNREACH; //异常退出
dst = xfrm_lookup(net, dst, &fl, skb->sk, 0);
if (IS_ERR(dst))
return PTR_ERR(dst);
skb_dst_drop(skb);
skb_dst_set(skb, dst);
/* Change in oif may mean change in hh_len. */
hh_len = skb_dst(skb)->dev->hard_header_len;
if (skb_headroom(skb) < hh_len &&
pskb_expand_head(skb, hh_len - skb_headroom(skb), 0, GFP_ATOMIC))
return -ENOMEM;
return 0;
}
软中断解释
打印warning日志的ksoftirqd/110进程对应核的软中断并不高,只有1%,说明软中断较高和打印日志无关,应该是其他原因导致
结论:
1、call trace打印日志是因为引用计数为0没有流程处理导致,会存在dst内存泄漏影响,建议修复;
2、软中断高的问题建议可以通过perf去抓取热点分析
参考链接:
1、udp->ip & tcp->ip
https://www.cnblogs.com/honpey/p/9066603.html
2、LINUX内核网络数据包发送(三)——IP协议层分析
3、rcu机制与使用
https://www.cnblogs.com/schips/p/linux_cru.html
4、Linux中的RCU机制[一] - 原理与使用方法
Linux中的RCU机制[一] - 原理与使用方法 - 知乎
5、Linux 路由缓存的前世今生
Linux 路由缓存的前世今生_maimang09的博客-CSDN博客
6、目的入口(dst_entry)的结构详解
2、网卡bond0丢包
背景
1、该业务集群共有50台物理机节点,有46个节点存在bond0丢包问题,物理接口ens1f0np0和ens2f0np0不丢包
2、所有节点的丢包模式类似,具体为每30s丢18-20个包
配置排查
1、/proc/net/dev下的bond0和2个备
2、类似ethtool –S bond0查看rx_missed_errors和rx_dropped
cat /sys/device/virtual/net/xxx/statistics
发现只有bond0的rx_dropped在上涨;两个物理网卡的drop值不变
3、网卡类型为bnxt_en网卡
代码排查
1、查看bond代码(bond_get_stats)发现收包的drop统计信息只是从各个slave接口收集上来的
2、代码逻辑
dev_seq_printf_stats(seq, dev)
dev_get_stats(dev, (struct rtnl_link_stats64)&temp)
//根据不同netdev来调用不同的函数
ndo_get_stats64 or ndo_get_stats or dev->stats
temp -> rx_dropped += dev->rx_dropped
打印统计数据 stats->xxx
bond_get_stats(bond_dev,stats) //ndo_get_stats64
bond_for_each_slave_rcu
dev_get_stats(slave->dev, &temp) -> bnxt_get_stats64
bnxt_en网卡:
bnxt_get_stats64(dev, stats) //ndo_get_stats64
无rx_dropped
ftrace抓取信息
echo 'p:dev_get_stats dev_get_stats name=+0(%di):string rx_drop=+456(%di):x64'>>/sys/kernel/debug/tracing/kprobe_events echo 1 > /sys/kernel/debug/tracing/kprobe_events/dev_get_stats/enabled echo 1 > /sys/kernel/debug/tracing/tracing_on #观察cat /proc/net/dev中bond0的drop值,发现升高后执行以下命令 cat trace > trace.txt echo 0 > /sys/kernel/debug/tracing/tracing_on
发现slave都为0x0,bond0丢包一直上涨,根据代码分析怀疑是由于报文协议类型不支持丢弃,导致rx_dropped增加
3、分析rx_dropped增加的函数并tcpdump抓包查看报文协议类型
skb_pfmemalloc_protocol函数会去筛选报文类型,只有这5个协议类型支持,其他类型会直接丢弃,rx_dropped计数会增加
#define ETH_P_ARP 0x0806 /* Address Resolution packet */ #define ETH_P_IP 0x0800 /* Internet Protocol packet */ #define ETH_P_IPV6 0x86DD /* IPv6 over bluebook */ #define ETH_P_8021Q 0x8100 /* 802.1Q VLAN Extended Header */ #define ETH_P_8021AD 0x88A8 /* 802.1ad Service VLAN */
抓包发现是LLDP和STP报文,这2种协议由于不属于以上5种类型,导致丢包















 3961
3961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









