






2、存储
技术栈:block scsi
(1)bufferio和directio
read SYSCALL_DEFINE3(read,xxx) ksys_read vfs_read __vfs_read //一般设备文件会注册此接口 file->f_op->read //普通文件注册此类方法 new_sync_read ext4_file_read_iter //ext4的ext4_file_operations
对于 ext4 文件系统,最后调用的是 ext4_file_write_iter
ext4_file_write_iter
generic_file_write_iter
将 I/O 的调用分成两种情况:
第一是直接 I/O 最终调用的是 generic_file_direct_write,这里调用的是 mapping->a_ops->direct_IO,实际调用的是 ext4_direct_IO,往设备层写入数据。
使用这种IO,只要在打开文件时,增加一个O_DIRECT标记,不会和内存打交道,而是直接写入到 or 读取存储设备中
优点:读IO时减少一次从内核缓冲区到用户程序缓存的数据拷贝
缺点:访问的数据不在用户程序缓存中,每次数据都会直接从磁盘加载,耗时导致性能问题
第二种是缓存 I/O 最终会将数据从应用拷贝到内存缓存中,但是这个时候,并不执行真正的 I/O 操作。 只将整个页或其中部分标记为脏。写操作由一个 timer 触发,那个时候,才调用 wb_workfn 往硬盘写入页面。
(1)写IO:write back (默认)和 write through
•write back先写入到缓存,一段时间后由内核线程写入到磁盘或者显式调用sync刷盘;
•write through在写入缓存同时也写入磁盘中
(2)读IO:查找file对应的pagecache,如果不存在,则从磁盘读入,再写入pagecache

generic_file_write_iter
__generic_file_write_iter
//iocb->ki_flags & IOCB_DIRECT,即directio
generic_file_direct_write
ext4_direct_IO
//bufferio
generic_perform_write
(2)block层
1、io大致流程
单队列:
//下io
submit_bio
generic_make_request
blk_queue_bio
scsi_request_fn
scsi_dispatch_cmd
queuecommand //接口由LLD驱动注册
LLD驱动 —> 盘
盘 -> LLD驱动
//从底层返回
scsi_done
blk_complete_request
__blk_complete_request
scsi_softirq_done
scsi_finish_request
scsi_io_completion
多队列:
//下io
submit_bio
generic_make_request
blk_mq_make_request
scsi_queue_rq
scsi_dispatch_cmd
queuecommand //接口由LLD驱动注册
LLD驱动 —> 盘
盘 -> LLD驱动
//从底层返回
scsi_mq_done
blk_mq_complete_request
__blk_mq_complete_request
scsi_softirq_done
scsi_finish_request
scsi_io_completion
2、io请求 request -> bio
generic_make_request :
1、获取一个请求队列 request_queue [如何向块设备层提交请求? -> submit_bio]
2、调用这个队列的 make_request_fn 函数。[请求提交与调度]
request_queue请求队列里存放请求request请求
struct request_queue {
/*
* Together with queue_head for cacheline sharing
*/
struct list_head queue_head;
struct request *last_merge;
struct elevator_queue *elevator;
...
}
每个 request 包括一个链表的 struct bio,有指针指向一头一尾
struct request {
struct request_queue *q;
struct blk_mq_ctx *mq_ctx;
...
struct bio *bio;
struct bio *biotail;
}
3、io调度
struct elevator_type elevator_noop
Noop 调度算法是最简单的 IO 调度算法,它将 IO 请求放入到一个 FIFO 队列中,然后逐个执行这些 IO 请求。
struct elevator_type iosched_deadline
Deadline 算法要保证每个 IO 请求在一定的时间内一定要被服务到,以此来避免某个请求饥饿。
struct elevator_type iosched_cfq
CFQ 完全公平调度算法。所有的请求会在多个队列中排序。同一个进程的请求,总是在同一队列中处理。时间片会分配到每个队列,通过轮询算法,保证了 I/O 带宽,以公平的方式,在不同队列之间进行共享。
调用 elv_merge 来判断,当前这个 bio 请求是否能够和目前已有的 request 合并起来,成为同一批 I/O 操作,从而提高读取和写入的性能
4、一些参数及性能优化
对单个IO的大小限制是由芯片以及驱动能力决定的
max_hw_sectors_kb: maximum size of a single I/O the hardware can accept (硬件单次可可以接受的最大IO长度) max_sectors_kb: the maximum size the block layer will send (block 单次发送IO最大的长度) max_segments: max_segments the DMA engine limitations for scatter gather (SG) I/O (DMA 引擎限制(SG) I/O 段的个数) max_segment_size: maximum size of each segment and the maximum number of segments for a single I/O (单(SG) I/O 段的最大的长度)
问题定位思路(block层):
(2)scsi层
1、host target channel id lun关系
#host控制器 [root@localhost tracing]# ll /sys/class/scsi_host/host* lrwxrwxrwx. 1 root root 0 Jul 6 05:58 /sys/class/scsi_host/host0 -> ../../devices/pci0000:00/0000:00:01.1/ata1/host0/scsi_host/host0 lrwxrwxrwx. 1 root root 0 Jul 6 05:58 /sys/class/scsi_host/host1 -> ../../devices/pci0000:00/0000:00:01.1/ata2/host1/scsi_host/host1 lrwxrwxrwx. 1 root root 0 Jul 6 05:58 /sys/class/scsi_host/host2 -> ../../devices/pci0000:00/0000:00:04.0/virtio1/host2/scsi_host/host2
#sda和sdb对应virtio1 [root@localhost tracing]# ll /sys/block/ total 0 lrwxrwxrwx. 1 root root 0 Jul 6 05:58 dm-0 -> ../devices/virtual/block/dm-0 lrwxrwxrwx. 1 root root 0 Jul 6 05:58 dm-1 -> ../devices/virtual/block/dm-1 lrwxrwxrwx. 1 root root 0 Jul 6 05:58 dm-2 -> ../devices/virtual/block/dm-2 lrwxrwxrwx. 1 root root 0 Jul 6 05:58 sda -> ../devices/pci0000:00/0000:00:04.0/virtio1/host2/target2:0:0/2:0:0:0/block/sda lrwxrwxrwx. 1 root root 0 Jul 6 05:58 sdb -> ../devices/pci0000:00/0000:00:04.0/virtio1/host2/target2:0:0/2:0:0:1/block/sdb [root@localhost tracing]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 140G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 139G 0 part ├─x-root 253:0 0 50G 0 lvm / ├─x-swap 253:1 0 4G 0 lvm [SWAP] └─x-home 253:2 0 85G 0 lvm /home sdb 8:16 0 1G 0 disk
在scsi内部针对每个target创建了一个名字为
targetk:m:n
的device结构体,其中k是host编号,m是channel编号,n是id编号
Scsi子系统针对每个lun创建了两个device对象,分别是sdev_gendev和sdev_dev
它们的名字都是
k:n:lun:N
,其中k是host编号,m是channel编号,n是id编号,lunN是lun编号
[root@localhost 2:0:0:0]# ll /dev/sd* brw-rw----. 1 root disk 8, 0 Jul 6 05:58 /dev/sda brw-rw----. 1 root disk 8, 1 Jul 6 05:58 /dev/sda1 brw-rw----. 1 root disk 8, 2 Jul 6 05:58 /dev/sda2 brw-rw----. 1 root disk 8, 16 Jul 6 05:58 /dev/sdb
2、扫盘
3、超时机制
在IO下发过程中,IO可能因为软件或硬件问题导致IO无法返回,这时如果没有超时机制,IO会一直阻塞。实际上存在超时机制,在达到一定时间IO仍未返回,会触发超时处理。
(1)定时器设置 & 超时函数
从block层进入scsi的时候,在分配request-queue时,会给每个请求队列分配一个定时器q->timeout,用于检测IO超时,默认30秒;
当IO在指定时间没有返回时,会调用超时定时器的回调blk_rq_timed_out_timer(),它调用q->timeout_work,即blk_mq_timed_out
//超时函数初始化
INIT_WORK(&q->timeout_work, blk_mq_timeout_work);
//request_queue->rq_timeout = 30
blk_queue_rq_timeout(q, set->timeout ? set->timeout : 30 * HZ);
blk_mq_timeout_work
//对每个未完成的io做检查
blk_mq_queue_tag_busy_iter(q, blk_mq_check_expired, &next);
blk_mq_check_expired
...
//指定时间没有返回
if (blk_mq_req_expired(rq, next))
blk_mq_rq_timed_out(rq, reserved);
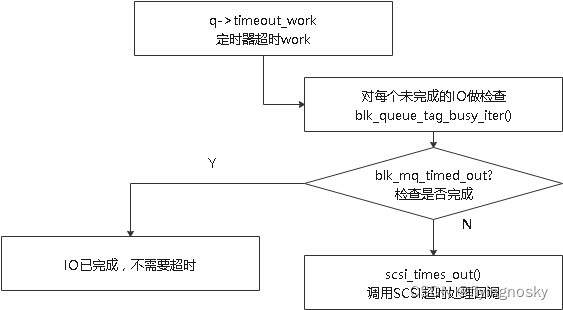
blk_mq_timed_out会对未完成的IO做检查,如果该IO已经完成,就不需要进行超时处理;
否则调用req->q->mq_ops->timeout()进行超时处理,对于SCSI层,对应处理函数为scsi_times_out()。
static void blk_mq_rq_timed_out(struct request *req, bool reserved)
{
req->rq_flags |= RQF_TIMED_OUT;
if (req->q->mq_ops->timeout) {
enum blk_eh_timer_return ret;
ret = req->q->mq_ops->timeout(req, reserved);
if (ret == BLK_EH_DONE) //表示io已完成不需要设置超时
return;
WARN_ON_ONCE(ret != BLK_EH_RESET_TIMER);
}
blk_add_timer(req); //设置定时器
}
(2)scsi超时处理 --- scsi_times_out
SCSI层超时处理首先会调用底层驱动的超时处理接口host->hostt->eh_timed_out()处理,若处理完!BLK_EH_DONE,直接返回;
否则调用scsi_abort_command()尝试去abort掉该命令,若成功abort,直接返回,否则进入错误处理进行恢复。
enum blk_eh_timer_return scsi_times_out(struct request *req)
{
struct scsi_cmnd *scmd = blk_mq_rq_to_pdu(req);
enum blk_eh_timer_return rtn = BLK_EH_DONE;
struct Scsi_Host *host = scmd->device->host;
trace_scsi_dispatch_cmd_timeout(scmd);
scsi_log_completion(scmd, TIMEOUT_ERROR);
if (host->eh_deadline != -1 && !host->last_reset)
host->last_reset = jiffies;
if (host->hostt->eh_timed_out) //底层驱动超时接口
rtn = host->hostt->eh_timed_out(scmd);
if (rtn == BLK_EH_DONE) { //
/*
* For blk-mq, we must set the request state to complete now
* before sending the request to the scsi error handler. This
* will prevent a use-after-free in the event the LLD manages
* to complete the request before the error handler finishes
* processing this timed out request.
*
* If the request was already completed, then the LLD beat the
* time out handler from transferring the request to the scsi
* error handler. In that case we can return immediately as no
* further action is required.
*/
if (req->q->mq_ops && !blk_mq_mark_complete(req))
return rtn;
if (scsi_abort_command(scmd) != SUCCESS) {
set_host_byte(scmd, DID_TIME_OUT);
scsi_eh_scmd_add(scmd);
}
}
return rtn;
}
(3)scsi_abort_command
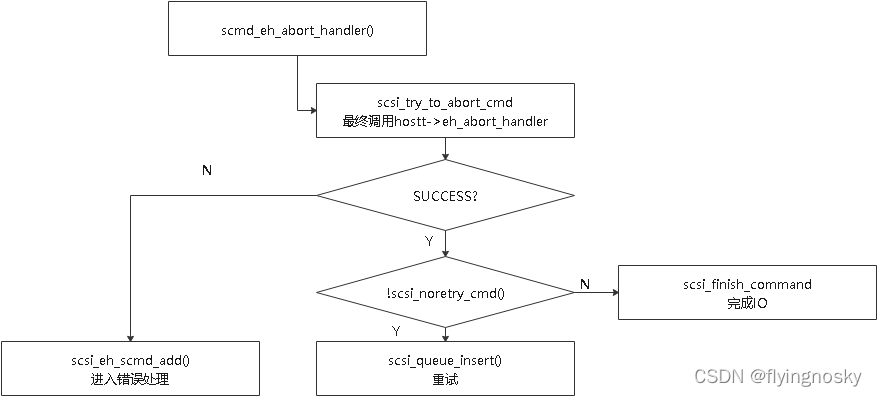
scsi_abort_command()会在shost->tmf_work_q工作队列上执行abort_work,对应的回调函数scmd_eh_abort_handler()执行流程如下:
scsi_init_command
//注册abort_work
INIT_DELAYED_WORK(&cmd->abort_work, scmd_eh_abort_handler);
scsi_abort_command
//在shost->tmf_work_q工作队列上执行abort_work
queue_delayed_work(shost->tmf_work_q, &scmd->abort_work, HZ / 100);
scmd_eh_abort_handler逻辑:
1、如果abort成功, 驱动告知scsi中层重试,并且重试次数未用完,则进行重试
scsi_queue_insert(scmd, SCSI_MLQUEUE_EH_RETRY);
2、如果abort成功, 驱动告知scsi中层重试或者重试次数用完,则返回 set_host_byte(scmd, DID_TIME_OUT)并且scsi_finish_command完成io;
3、如果abort失败, 则添加到scsi错误处理线程处理, 并唤醒错误处理线程:
scsi_eh_scmd_add(scmd); 这是host为SHOST_RECOVERY, 新的IO暂时无法下发
scsi_eh_scmd_add(scmd);
scsi_host_set_state(shost, SHOST_CANCEL_RECOVERY);
后续会在错误处理后更新host状态为SHOST_RUNNING
scsi_error_handler
...
eh_strategy_handler
scsi_restart_operations(shost);
scsi_host_set_state(shost, SHOST_RUNNING)
4、错误处理
1、 只有超时的IO和出错IO才有可能走到scsi_error_handler
2、若驱动有注册strategy接口,表示驱动接管了IO的错误处理,使用驱动的错误处理(scsi_unjam_host);如果驱动没有注册,则走scsi_unjam_host,这个函数是scsi中层默认的错误处理主逻辑。
3、scsi中层的踢盘流程:
scsi_error_handler
scsi_unjam_host
//下发scsi命令获取盘片状态,获取失败对链路做reset
if(!scsi_eh_get_sense)
scsi_eh_ready_devs
scsi_host_template结构体中定义了错误处理相关函数指针:
(1)eh_device_reset_handler使SCSI设备复位;
(2)eh_target_reset_handler使目标节点复位;
(3)eh_bus_reset_handler使SCSI总线复位;
(4)eh_host_reset_handler使主机适配器复位
scsi_eh_ready_devs:
if (!scsi_eh_stu(shost, work_q, done_q))
//单盘rset 1.调驱动接口去reset硬盘 2.下发tur指令探测硬盘是否在位 这两个只要有一个超时就会进行target reset
if (!scsi_eh_bus_device_reset(shost, work_q, done_q))
//Target reset 1.调驱动接口去reset target 2.下发tur指令探测target是否在位 两个有一个超时就进入host reset
if (!scsi_eh_target_reset(shost, work_q, done_q))
if (!scsi_eh_bus_reset(shost, work_q, done_q))
//1.调驱动接口去reset盘 2.下发tur指令探测盘是否在位 两个有一个超时就会进行踢盘
if (!scsi_eh_host_reset(shost, work_q, done_q))
//reset失败,将盘设置为offline
scsi_eh_offline_sdevs
问题定位思路(scsi层):
1、io超时
上层下发的IO请求,从block层进入scsi的时候会启动一个定时器,默认超时时间是30s,如果30s 内该IO没有返回,就会进入超时处理流程。IO返回后,定时器被清除。
/sys/block/sda/device/timeout
//定时器初始化 --- block层初始化IO时初始化定时器
blk_mq_init_allocated_queue(q)
INIT_WORK(&q->timeout_work, blk_mq_timeout_work);
blk_queue_rq_timeout(q, set->timeout ? set->timeout : 30 * HZ); //set->timeout未设置,默认为30s
//何时启动定时器 --- scsi层的scsi_request_fn函数中会循环从request_queue取request并启动定时器
scsi_request_fn(struct request_queue *q)
blk_peek_request(struct request_queue *q)
blk_start_request(struct request_queue *q)
blk_add_timer(struct request *req)
超时处理函数
enum blk_eh_timer_return scsi_times_out(struct request *req)
{
struct scsi_cmnd *scmd = blk_mq_rq_to_pdu(req);
enum blk_eh_timer_return rtn = BLK_EH_DONE;
struct Scsi_Host *host = scmd->device->host;
trace_scsi_dispatch_cmd_timeout(scmd);
scsi_log_completion(scmd, TIMEOUT_ERROR);
if (host->eh_deadline != -1 && !host->last_reset)
host->last_reset = jiffies;
//若驱动有注册超时处理函数,则调用驱动的超时处理函数
if (host->hostt->eh_timed_out)
rtn = host->hostt->eh_timed_out(scmd);
//1.如果返回值为 BLK_EH_RESET_TIMER
//说明需要继续等待该 request,此时会重新调用 blk_add_timer() 再次发起一轮等待
//2.如果返回值为 BLK_EH_DONE
//说明 blkdev driver 已经完成该 request 的 completion 处理,此时只是将该 request 从 request queue 的 timeout_list 链表中移除
if (rtn == BLK_EH_DONE) {
/*
* For blk-mq, we must set the request state to complete now
* before sending the request to the scsi error handler. This
* will prevent a use-after-free in the event the LLD manages
* to complete the request before the error handler finishes
* processing this timed out request.
*
* If the request was already completed, then the LLD beat the
* time out handler from transferring the request to the scsi
* error handler. In that case we can return immediately as no
* further action is required.
*/
if (req->q->mq_ops && !blk_mq_mark_complete(req))
return rtn;
if (scsi_abort_command(scmd) != SUCCESS) {
set_host_byte(scmd, DID_TIME_OUT);
//设置host为SHOST_RECOVERY状态,会导致这个host下的所有磁盘都无法再下io
scsi_eh_scmd_add(scmd);
}
}
return rtn;
}
io超时 -> abort
1、abort成功的scmd,如果没有超时重试次数(默认6次),则调用scsi_queue_insert将scmd重新插入到request_queue里重新走IO处理流程;超过重试次数走错误处理流程
2、abort失败的scmd,则将这个scmd添加到错误处理链表,走错误处理流程
2、io错误
IO有另外2条返回路径,一条是通过queuecommand直接返回,另外一条是通过scsi_done返回。
IO错误会从这2条路径中的任意一条返回。
3、scsi sense key错误处理
scsi层会根据驱动侧返回的sense key进行处理:部分sense key错误指示可以重试;部分sense key直接以失败io结束
ASC(ADDITIONAL SENSE CODE):附加检测码,用来描述 sense key报告的错误或者异常情况的更多信息,如果设备没有错误或者异常情况,则附加检测码应该设置为零。
ASCQ(ADDITIONAL SENSE CODE QUALIFIER):附加检测码的限定符,用来描述与附加检测码相关的详细信息,如果设备没有错误或者异常情况,则附加检测码的限定符应该设置为零。
【参考链接:https://en.wikipedia.org/wiki/Key_Code_Qualifier】
(3)常用工具
iotop
iotop:是一款开源、免费的用来监控磁盘I/O使用状况的类似top命令的工具,iotop可以监控进程的I/O信息
快捷键:
1、左右箭头:改变排序方式,默认是按IO排序(光标所在);
2、r:改变排序顺序(">"表示降序,"<"表示升序);
3、o:只显示有IO输出的进程;
4、p:PID/TID的显示方式的切换;
5、a:显示累积IO使用量;
常用方法:
1、显示指定PID
b是非交互式,-n 2指监控2次,-d 5 表示5秒刷新一次,-p是只显示进程
iotop -b -n 2 -d 5 -p 1
2、显示指定用户
b是非交互式,-n 2指监控2次,-d 5 表示5秒刷新一次,-u是指定用户
iotop -b -n 2 -d 5 -u root
3、-t表示打印时间戳
4、-k表示单位设置为KB
iostat
iostat是一款Linux下的io性能监控软件,用于统计CPU使用情况和块设备I/O情况
安装:
yum install sysstat
参数说明:
1、-c:仅显示CPU统计信息,与-d选项互斥;
2、-d:仅显示磁盘统计信息,与-c选项互斥;
3、-k:以K为单位显示每秒的磁盘请求数,默认单位块;
4、-p:device | ALL
显示块设备及系统分区的统计信息,与-x选项互斥;
5、-t : 在输出数据时,打印搜集数据的时间;
6、-x: 输出扩展信息
7、参数后加2个数字,分别表示间隔秒数和显示次数
输出行解释:
avg-cpu段:
%user:在用户态使用的CPU的百分比;
%nice:nice操作所使用的CPU的百分比;
%system:在内核态运行所使用CPU的百分比;
%iowait:表示CPU等待的时间占用整个cpu周期的百分比(cpu idle time)/(all cpu time);
%steal:丢失时间占用cpu;
%idle:CPU处于空闲状态的时间
%iowait并不能说明磁盘瓶颈;
如果存在很高的read/write时间,考虑是否是磁盘读写次数过多,导致磁盘性能降低
Device段:
rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s
wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
r/s: 每秒完成的读 I/O 设备次数。即 rio/s
w/s: 每秒完成的写 I/O 设备次数。即 wio/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。wkB/s: 每秒写K字节数。是 wsect/s 的一半。
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)
avgqu-sz平均请求队列长度
await:平均每次设备I/O操作的等待时间(ms)=> IO 平均处理时间 + IO在队列的平均等待时间
r_await:每个读操作平均所需的时间;不仅包括硬盘设备读操作的时间,还包括了在kernel队列中等待的时间。
w_await:每个写操作平均所需的时间
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
%util: 一秒中有百分之多少的时间用于I/O操作,即被io消耗的cpu百分比
await高并不能说明磁盘性能差!
考虑两种IO的模型:
250个IO请求同时进入等待队列; 250个IO请求依次发起,待上一个IO完成后,发起下一个IO 第一种情况await高达500ms,第二个情况await只有4ms,但是都是同一块盘
%util:
当10个I/O请求依次顺序提交的时候,需要1秒才能全部完成,在1秒的采样周期里%util达到100%;
而如果10个I/O请求一次性提交的话,0.1秒就全部完成,在1秒的采样周期里%util只有10%。 可见,即使%util高达100%,硬盘也仍然有可能还有余力处理更多的I/O请求,即没有达到饱和状态
blktrace
blktrace 结合btt可以统计一个IO是在调度队列停留的时间长,还是在硬件上消耗的时间长,利用这个工具可以协助分析和优化问题。
操作步骤:
1、收集设备/dev/sdb上的io情况60秒,将结果保存到sdb-trace文件中 blktrace -d /dev/sdb -o sdb-trace -w 60
2、将sdb-trace开头的所有文件合并为一个sdb-trace.bin,这个过程中的输出放在sdb-trace.txt中 blkparse -i sdb-trace -d sdb-trace.bin -o sdb-trace.txt
3、通过btt工具知道磁盘I/O在每一个阶段耗时分布 btt -i sdb-trace.bin -o btt.txt 其中btt.txt.avg是请求信息分布情况
每一个字母都代表了IO请求所经历的某个阶段。
Q – 即将生成IO请求
G – IO请求生成
I – IO请求进入IO Scheduler队列
D – IO请求进入driver
C – IO请求执行完毕
I/O请求在每个阶段所消耗的时间:
Q2G – 生成IO请求所消耗的时间,包括remap和split的时间;
G2I – IO请求进入IO Scheduler所消耗的时间,包括merge的时间;
I2D – IO请求在IO Scheduler中等待的时间;
D2C – IO请求在driver和硬件上所消耗的时间;
Q2C – 整个IO请求所消耗的时间(Q2I + I2D + D2C = Q2C),相当于iostat的await。
D2C可以作为硬件性能的指标;
I2D可以作为IO Scheduler性能的指标。
ftrace
打开block层的trace
echo > trace
echo 1 > /sys/kernel/debug/tracing/tracing_on
echo 1>/sys/kernel/debug/tracing/events/block/enable
// 即将生成同步(S)写(W)请求,起始扇区为:0, 长度为8个扇区(4K)
block_bio_queue
// 生成IO 请求
block_getrq
//添加到IO plug链表
block_plug
// IO 插入到请求队列
block_rq_insert
// IO 下发到驱动
block_rq_issue
// IO 完成
block_rq_complete
案例分析:
1、iostat相关
(1)系统盘存在长时间util打满的情况
blktrace看下哪个地方耗时
(2)系统盘没有io读写,为什么iostat查看util是100%
cat /sys/block/sda/inflight发现第一列一直有一个1,就是有一个读io一直在重试,util是表示盘的繁忙程度,所以一直是100%
#查看sda对应的控制器 cat /sys/class/scsi_host/host0/state -> recovery
说明IO一直卡在错误恢复处理,调用驱动的错误处理没有返回
2、nfsv3 d状态
看栈卡在rpc_wait_bit_killable,建议nfs服务端先排查下
3、top卡住
ps看到有很多d状态进程,进程都是会对sdn盘进行操作,iostat看到util很高,盘
4、在内核中通过哪个数据结构能拿到块设备的槽位号?
gendisk结构体里面的major和first_minor字段
5、LVM不可用的大小
有个LVM的问题需要请教一下,lvm的PV,总是有4MiB是不可用的,想问下不可用部分的大小取决于哪些因素?我了解到的信息说默认PE的大小是4MiB,每个PV会有1MB的metadata,第一个PE是在metadata后面的,那为啥不可用空间是4MiB,不是1MiB的metadata?
//lvm2源码 pvdisplay_full函数:
pv->size 291502080*512 = 149,249,064,960 bytes
Total PE pv->pe_count 35583
PE Size pv->pe_size 4194304 bytes
data_size = (uint64_t) pv->pe_count * pv->pe_size; //149,245,919,232 bytes
pv->pe_start 1MB*1024*1024 = 1,048,576 bytes
if (pv->size > data_size + pv->pe_start) { //符合
pvsize = pv->size;
unusable = pvsize - data_size; //3,145,728 bytes = 3MB
} else {
pvsize = data_size + pv->pe_start;
unusable = pvsize - pv->size;
}
实际不可用的3MB在最后面,还有最前面的1MB是不可用的
6、在内核里是否有机制会对硬盘下发FLUSH CACHE的命令?比如pflush流程
(1)除非是pass-thought命令下的 内核下发的是0x35
(2)下io都会走的阿
queuecommand接口会根据驱动注册的走到ata_scsi_queuecmd->__ata_scsi_queuecmd->ata_get_xlat_func->ata_scsi_flush_xlat->转换0x35命令
7、arm服务器故障率相比于x86偏高协助定位
(1)背景: 2022年华为云多次发生EVS存储池降级问题,落地海思补丁等优化措施后,故障率有降低但仍旧比x86偏高,需要定位根因
(2)三种告警ID典型场景,找到故障根因和解决方案: 1、51004 慢盘告警,此类就是检测到了单纯的慢盘,基本未进入IO错误恢复处理,要分析慢盘原因。 2、51455 有driver timeout打印,分析盘侧timeout原因 3、51635 单个IO超时超时30s,此类问题基本都是因为IO错误恢复处理时间较长,时间长是因为host和盘交互,盘侧响应慢。 ---上述3类告警,根因都是盘侧响应慢。
解决方案分4个维度: 1、硬盘(慢盘引入源优化),理论猜想,EVS写忽高忽低影响硬盘可靠性,影响盘响应IO时间。 2、驱动(IO下发优化),合入早期/本期攻关全部补丁,ARM/X86差异根因,IO下发频率最关键。 3、EVS业务(业务优化),加大超时时间?慢盘告警(无超时/ERROR记录)只做提示,降低故障级别,无需更换盘。 4、主动管理,统计盘故障前 iostat参数,比如rwait,svctm,确认一个临界值,提前更换盘。
技术根因: taishan机型sas驱动器下发io频率快,SATA HDD亚健康状态下盘内io队列高,导致出现DMA setup帧响应慢,业务侧出现慢盘故障; x86为AHCI SATA控制器,SATA盘单盘单队列,相比而言io下发频率正常
(3)对于os的诉求: 背景:对于性能差的sas盘,需要上层(block, SCSI或libsas)提供类似流控能力,降低对性能差的磁盘下IO的频率
问题描述:对于性能差的sas盘,如果通过sas控制器高速下IO,会导致SAS盘响应更慢。因此需要上层提供类似流控能力,降低对性能差的磁盘下IO的频率
有2个方案:
1、完全在内核态实现检测慢盘逻辑并在检测到慢盘之后降低对该盘的IO速度 实现思路:监控该盘的IO从下发到完成时间,采样判断是否属于慢盘(具体判断方法待实测),检测到属于慢盘后在libsas层的queuecommand加延时从而降低对性能差的磁盘下IO的频率 优点:用户态不需要感知 缺点:判断是否属于慢盘可能会误判,内核态实现复杂度较高;修改不灵活
2、在内核态提供对指定盘降低速率的能力,用户态可配置,由用户态决定是否对该盘做限速 实现思路:对每个盘注册sysfs接口供用户态配置 优点:实现灵活,内核不与具体策略耦合 缺点:用户态需要配合修改
os做的一些事:
1、driver_timeout -> 错误处理 -> 踢盘逻辑 获取sense 信息,出现了2次Sense Key : Medium Error [current], 这里会进入sd_eh_action逻辑。
libsas错误处理:
sas_scsi_recover_host
scsi_eh_ready_devs
scsi_eh_stu
scsi_eh_action
Medium access timeout failure. Offlining disk //如果出现连续出现两次错误,则置位offline SDEV_OFFLINE
等IO错误处理结束后,清除SHOST_RECOVERY标记,新IO可以下发下来,新IO会检测磁盘状态,如果磁盘SDEV_OFFLINE/ SDEV_TRANSPORT_OFFLINE /SDEV_DEL状态,则会打印 “rejecting I/O to offline device”
3、驱动侧分析寄存器证明io已发送 但是还是有打印driver_timeout,解释原因
增加热补丁在把io插入到done的链表的函数判断中
sas_eh_handle_sas_errors
if (!task)
list_move_tail(&cmd->eh_entry, &done); 确认进入错误处理时,io正好返回,因已进入错误处理,最后打印driver_timeout
(4)最终解决方案: taishan和x86差异确定为可以通过调节NCQ并发io间隔解决,使用usleep_range函数设置了间隔














 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









