







本次只记录最近对于窗口的新认知
关于窗口的详细知识可以参考如下链接:
https://blog.csdn.net/mynameisgt/article/details/124223193
窗口的作用是为了在无限流上进行统计计算,数据到来时,则为此条数据开辟窗口。当 Flink 的时间大于等于窗口的结束时间时,触发这个窗口的计算,计算完毕之后,销毁此窗口。
在一个流上开窗口之前,可以做 keyBy ,也可以不做 keyBy。
两者的区别是,如果一个数据流先 keyBy 再做窗口计算,这样的窗口叫做 Keyed Windows。相同 key 的数据一定会被分到一个窗口中,换句话说,相同的 key 的数据,一定不会存在于两个窗口中。
这样做的意义是,每个窗口只分担整个数据流的一部分计算。
而如果窗口计算之前没有 keyBy,这样的窗口叫做 Non-Keyed Windows。整个数据流的数据都将会被一个窗口计算,如果数据量很大,必然承受不住。
除非非要把所有数据拉到一起计算,否则这样的使用场景很少。
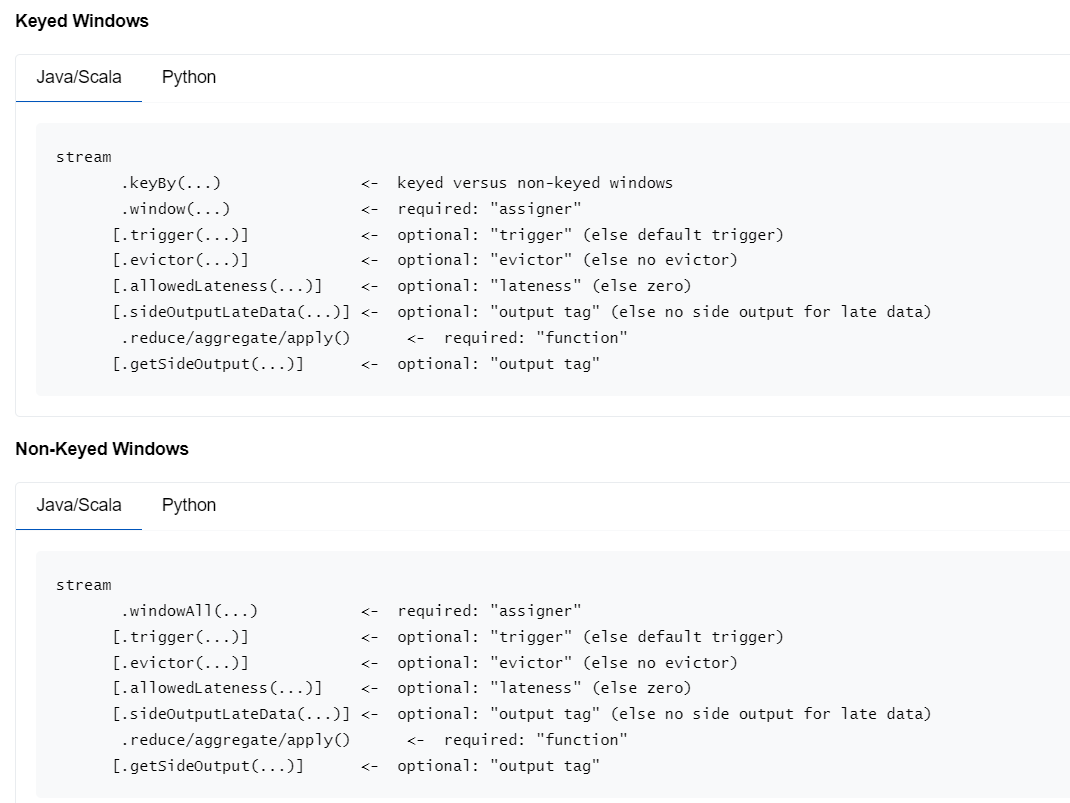
上面这张图来自 Flink 官网,展示了窗口计算的所有 Api。
其中 trigger 是触发器,可以自定义窗口的触发规则,大部分情况下不需要定义,默认是随着数据的推动,水位线上升到了窗口的结束时间,则触发这个窗口的计算。
evictor 是剔除器,剔除器默认的实现是,在计算完一个窗口后,把这个窗口的前一个窗口的数据给剔除掉。如果有特殊的需求,比如本窗口的xxx特性的数据不想参与计算,则可以重写此剔除器。
allowedLateness 也是个比较难理解的东西。
按以往的认知,为了处理数据的小范围延迟,可以在发射 watermark 的时候,使 watermark 的时间晚于事件时间多少 s 来实现,那么这里又设置了这个 api 的意思是?
如果在窗口后面用此方法设置了
.allowedLateness(Time.seconds(5))
那么,水位线推进到窗口结束时间又加了 5s 的时候,才触发窗口计算。不然当这条延迟非常大的数据来的时候,窗口已经销毁了,无法参与计算了。
如果设置了 getSideOutput ,则仍然可以捕获这些因为严重延迟而未被计算的数据。拿到之后,可以做额外的处理,比如可以累加到 sink 输出的外部存储结果中。
最后是窗口的增量计算和全量计算
reduce 与 aggregate 是增量计算,每来一条数据,就往一个中间值上做聚合(比如累加),当最后一条数据到来时,数据也就算好了。
那么同样是增量计算,他们有何区别? reduce 计算中,中间临时结果与最终结果是同一种数据类型,如果做累加可以使用 reduce。
而 aggregate ,则适当灵活一点,中间临时结果,可以是任意类型,那么就可以定义一个元祖,来存储多条数据。
比如求平均值,就需要总和和个数才能得到,中间临时结果就可以定义成元组类型。
如果说计算逻辑仍然过于复杂,那就需要使用 apply 了,这个方法可以通过一个迭代器,拿到窗口的所有数据,可以自定义任何逻辑计算,想怎么算就怎么算。
apply 还可以获得到窗口的元数据,比如窗口的开始时间和结束时间,比如当前的水位,都可以拿到。
另外如果仍然定义了其他复杂逻辑,还需要使用状态,那么就可以用 processFunction,这里可以获得到 context,便可以定义状态做更加复杂的计算。















 867
867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









