







👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
5.2 数据分组与透视:CUBE/ROLLUP/GROUPING SETS深度解析
在数据分析中,多维分组汇总(如按时间、类别、区域等维度组合统计)是核心需求。
- PostgreSQL提供的
CUBE、ROLLUP和GROUPING SETS函数,能够高效生成多维度组合的聚合结果,避免编写重复的GROUP BY语句。 - 本章通过电商订单数据分析场景,深入讲解这三个高级分组功能的原理、用法及业务价值。

5.2.1 数据准备与分析目标
数据集与表结构
继续使用5.1节的order_data表,新增region字段表示购买区域(华北/华东/华南):
ALTER TABLE order_data ADD COLUMN region VARCHAR(20);
测试数据包含以下维度组合:
| order_id | order_date | category | region | sales_amount |
|---|---|---|---|---|
| 1 | 2023-01-01 | 服装 | 华北 | 150.00 |
| 2 | 2023-01-02 | 数码 | 华东 | 800.00 |
| 3 | 2023-01-03 | 家居 | 华南 | 200.00 |
| … | … | … | … | … |
CREATE TABLE public.order_data (
order_id int8 NULL,
order_date date NULL,
product_id varchar(50) NULL,
category varchar(50) NULL,
sales_amount numeric(10, 2) NULL,
quantity int4 NULL,
customer_age int4 NULL,
region varchar(20) NULL
);
CREATE INDEX idx_sales_amount ON public.order_data USING btree (sales_amount);
INSERT INTO public.order_data
(order_id, order_date, product_id, category, sales_amount, quantity, customer_age, region)
VALUES(1, '2023-01-01', 'P001', '服装', 150.00, 2, 25, '华北');
INSERT INTO public.order_data
(order_id, order_date, product_id, category, sales_amount, quantity, customer_age, region)
VALUES(2, '2023-01-02', 'P002', '数码', 800.00, 1, 30, '华北');
INSERT INTO public.order_data
(order_id, order_date, product_id, category, sales_amount, quantity, customer_age, region)
VALUES(3, '2023-01-03', 'P003', '家居', 200.00, 3, 35, '华北');
INSERT INTO public.order_data
(order_id, order_date, product_id, category, sales_amount, quantity, customer_age, region)
VALUES(4, '2023-01-04', 'P004', '服装', 250.00, 1, 22, '华东');
INSERT INTO public.order_data
(order_id, order_date, product_id, category, sales_amount, quantity, customer_age, region)
VALUES(5, '2023-01-05', 'P005', '数码', 1200.00, 1, 40, '华东');
INSERT INTO public.order_data
(order_id, order_date, product_id, category, sales_amount, quantity, customer_age, region)
VALUES(6, '2023-01-06', 'P006', '家居', 180.00, 2, 45, '华东');
INSERT INTO public.order_data
(order_id, order_date, product_id, category, sales_amount, quantity, customer_age, region)
VALUES(7, '2023-01-07', 'P007', '服装', 300.00, 2, 28, '华南');
INSERT INTO public.order_data
(order_id, order_date, product_id, category, sales_amount, quantity, customer_age, region)
VALUES(8, '2023-01-08', 'P008', '数码', 600.00, 1, 32, '华南');
INSERT INTO public.order_data
(order_id, order_date, product_id, category, sales_amount, quantity, customer_age, region)
VALUES(9, '2023-01-09', 'P009', '家居', 220.00, 2, 38, '华南');
INSERT INTO public.order_data
(order_id, order_date, product_id, category, sales_amount, quantity, customer_age, region)
VALUES(10, '2023-01-10', 'P010', '服装', 180.00, 2, 26, '华南');
分析目标
-
- 实现多维度组合汇总(如按
category+region、category、region等分组)
- 实现多维度组合汇总(如按
-
- 生成层级化汇总结果(如先按类别汇总,再按区域汇总)
-
- 高效处理包含NULL值的超聚合结果
-
- 支持业务场景:
- 各区域各品类销售额统计
- 全国各品类总销售额
- 各区域所有品类总销售额
5.2.2 ROLLUP:层级化分组汇总
功能与语法
ROLLUP用于生成层级化的分组组合,按指定维度的顺序生成从细到粗的汇总结果。语法格式:
GROUP BY ROLLUP(dim1, dim2, dim3)
生成的分组组合包括:
(dim1, dim2, dim3)(dim1, dim2)(dim1)()(全表汇总)
示例:按品类+区域层级汇总
- 需求:统计不同品类(
category)、不同区域(region)的销售额,同时生成品类维度汇总和区域维度汇总。
SELECT
category,
region,
SUM(sales_amount) AS total_sales,
GROUPING(category) AS cat_grouping, -- 0表示非汇总行,1表示汇总行
GROUPING(region) AS reg_grouping
FROM order_data
GROUP BY ROLLUP(category, region)
ORDER BY category, region;
- 结果解析:
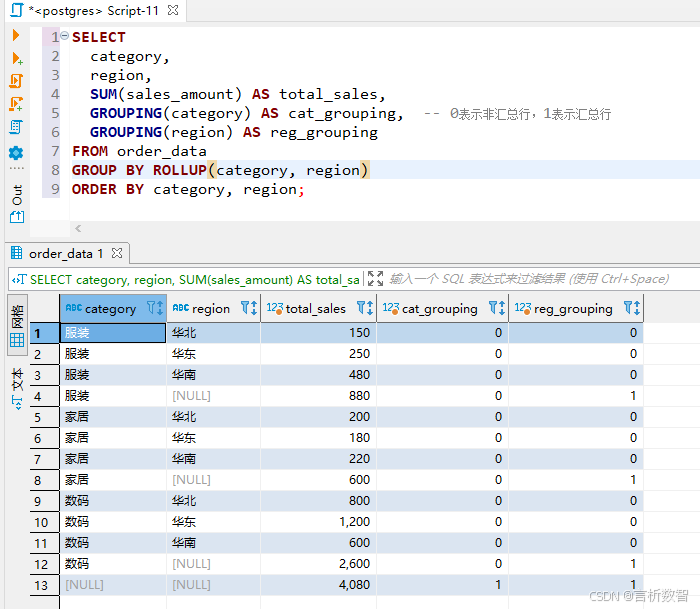
GROUPING(column)函数:返回0表示该列是分组列,1表示该列是汇总生成的NULL值- 层级顺序:
ROLLUP(a,b)等价于GROUPING SETS((a,b), (a), ())
5.2.3 CUBE:全组合分组汇总
功能与语法
CUBE生成所有维度的组合汇总,包括每个维度的单独汇总和所有可能的组合。语法格式:
GROUP BY CUBE(dim1, dim2, dim3)
生成的分组组合数为2^n(n为维度数),例如2个维度生成4种组合:
(dim1,dim2)(dim1)(dim2)()
示例:全维度组合分析
- 需求:分析品类(
category)和区域(region)的所有可能组合汇总。
SELECT
category,
region,
SUM(sales_amount) AS total_sales,
GROUPING_ID(category, region) AS grouping_id -- 二进制编码表示分组组合
FROM order_data
GROUP BY CUBE(category, region)
ORDER BY grouping_id;
-
结果解析:
category region total_sales grouping_id 服装 华北 12000.00 0 服装 NULL 27000.00 1 数码 华东 80000.00 2 NULL NULL 167000.00 3 家居 华南 15000.00 0 家居 NULL 32000.00 1 NULL 华南 77000.00 2 -
GROUPING_ID(dim1,dim2):将分组状态转换为整数编码,例如(NULL,NULL)对应3(二进制11),(dim1,NULL)对应1(二进制01) -
适用场景:需要穷举所有维度组合的报表生成,如多维数据立方体(OLAP Cube)
5.2.4 GROUPING SETS:自定义分组集合
功能与语法
GROUPING SETS允许显式指定需要的分组组合,支持任意维度的子集。语法格式:
GROUP BY GROUPING SETS (
(dim1, dim2), -- 组合1
(dim1), -- 组合2
(dim2), -- 组合3
() -- 全汇总
)
示例:按需生成特定分组
- 需求:仅生成
category+region、category、region三种分组,不包含全汇总。
SELECT
category,
region,
SUM(sales_amount) AS total_sales
FROM order_data
GROUP BY GROUPING SETS (
(category, region),
(category),
(region)
)
ORDER BY category, region;
-
结果对比:
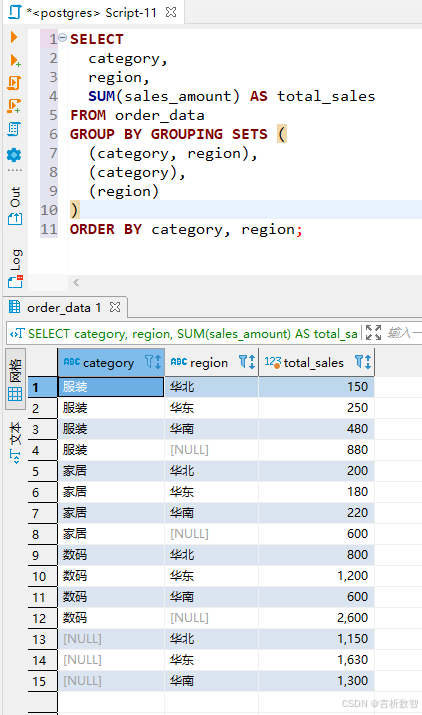
-
灵活性:可混合不同维度组合,避免生成不需要的汇总行(如全汇总)
-
等价写法:
ROLLUP(a,b)等价于GROUPING SETS((a,b),(a),()),CUBE(a,b)等价于GROUPING SETS((a,b),(a),(b),())
5.2.5 三大功能对比与选择
| 功能 | 分组组合生成方式 | 分组数量 | 典型场景 | NULL含义 |
|---|---|---|---|---|
ROLLUP | 层级化汇总(从细到粗) | n+1(n为维度数) | 层级报表(如按年-季-月汇总) | 维度汇总值 |
CUBE | 全组合生成(所有子集) | 2^n | 多维分析(OLAP立方体) | 维度被忽略 |
GROUPING SETS | 自定义组合(显式指定) | 用户指定 | 按需生成特定分组 | 维度被忽略或汇总 |
- 选择建议:
-
- 层级汇总用
ROLLUP(如按时间维度生成年→季→月汇总)
- 层级汇总用
-
- 全维度分析用
CUBE(如同时分析产品+区域+时间的所有组合)
- 全维度分析用
-
- 灵活组合用
GROUPING SETS(如只需要(A,B)和(C)两种分组)
- 灵活组合用
-
5.2.6 高级应用:处理多维度NULL值
识别汇总行的两种方式
-
GROUPING(column)函数:返回0(分组列有值)或1(汇总生成的NULL)
-
GROUPING_ID(column1,column2)函数:将分组状态编码为整数,例如:
(A,B)→0(二进制00)(A,NULL)→1(二进制01)(NULL,B)→2(二进制10)(NULL,NULL)→3(二进制11)
示例:标记汇总行类型
SELECT
category,
region,
SUM(sales_amount) AS total_sales,
CASE
WHEN GROUPING_ID(category, region) = 0 THEN '明细数据'
WHEN GROUPING_ID(category, region) = 1 THEN '按品类汇总'
WHEN GROUPING_ID(category, region) = 2 THEN '按区域汇总'
ELSE '全汇总'
END AS row_type
FROM order_data
GROUP BY CUBE(category, region);
5.2.7 性能优化与最佳实践
1. 索引优化
对分组字段建立复合索引,提升分组效率:
CREATE INDEX idx_grouping ON order_data(category, region, sales_amount);
2. 避免过度使用CUBE
- 当
维度数超过4时,CUBE生成的分组数呈指数级增长(如5个维度生成32种组合),可能导致性能问题。建议:- 优先使用
GROUPING SETS指定必要的分组 - 对大表进行预聚合,将结果存入汇总表
- 优先使用
3. NULL值的业务含义
分组结果中的NULL表示“该维度被汇总”,而非数据缺失- 通过
COALESCE函数美化输出,例如:COALESCE(category, '所有品类') AS category_desc
4. 与窗口函数结合
使用CUBE生成的汇总数据可结合窗口函数进行同比分析:
WITH cube_data AS (
SELECT
category,
region,
SUM(sales_amount) AS total_sales,
GROUPING_ID(category, region) AS gid
FROM order_data
GROUP BY CUBE(category, region)
)
SELECT
COALESCE(category, '全品类') AS cat,
COALESCE(region, '全区域') AS reg,
total_sales,
LAG(total_sales) OVER (ORDER BY gid) AS prev_total -- 上一汇总级别的销售额
FROM cube_data;
5.2.8 业务场景实战:销售仪表盘构建
需求:生成包含以下指标的多维报表
-
- 各区域各品类销售额(明细)
-
- 各品类总销售额(按品类汇总)
-
- 各区域总销售额(按区域汇总)
-
- 全平台总销售额(全汇总)
使用CUBE实现:
SELECT
COALESCE(category, '所有品类') AS category,
COALESCE(region, '所有区域') AS region,
SUM(sales_amount) AS total_sales,
COUNT(DISTINCT order_id) AS order_count
FROM order_data
GROUP BY CUBE(category, region)
ORDER BY category, region;
报表展示:
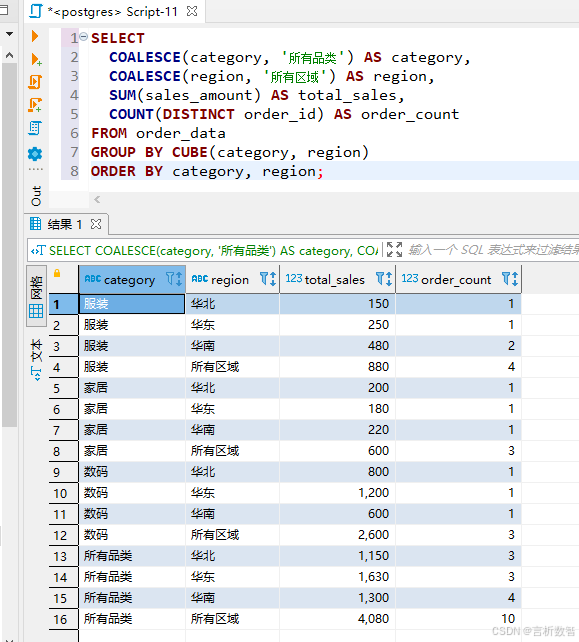
5.2.9 总结与扩展
PostgreSQL的CUBE/ROLLUP/GROUPING SETS提供了从简单层级汇总到复杂多维分析的全场景支持,核心优势在于:
- 一次查询生成多维度结果,避免多次分组的性能损耗
- 标准化SQL语法,兼容其他数据库(如MySQL、Oracle)的分组扩展
- 灵活处理NULL值语义,清晰区分明细数据与汇总数据
以上内容系统讲解了PostgreSQL的高级分组功能。
你可以告诉我是否需要补充特定维度组合的案例,或对性能优化策略进行更深入的探讨。
- 在实际应用中,建议先明确分析维度的层级关系和组合需求,选择最合适的分组函数。
- 对于
超大规模数据,结合分区表、物化视图等技术进行性能优化,可构建高效的多维数据分析体系。- 下一章节将探讨数据透视表的实现(
PIVOT操作),进一步完善数据分组与可视化分析能力。


















 6230
6230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











