







1.目标定位
我们希望在图中识别不同类别的目标,通过一系列卷积操作,得到输出
Y = [p_c(是否有目标0/1),
bx,by(目标中间相对于图片的位置坐标),
bh,bw(边界框的尺寸),
c1,c2,c3.....cn(根据类别多少的one-hot)]
.

2.特征点检测
如人脸68个特征点,人体骨骼特征点等

3.卷积的滑动窗口检测
使用5X5,1X1卷积来实现全连接层
通过卷积的方式实现窗口滑动的效果,如下我们用14x14的窗口的到一个输出,对于更大的图片,通过设置步长,完成卷积,结果相当于不同窗口区域得到的结果

4.Bounding Box Regression(边框回归)
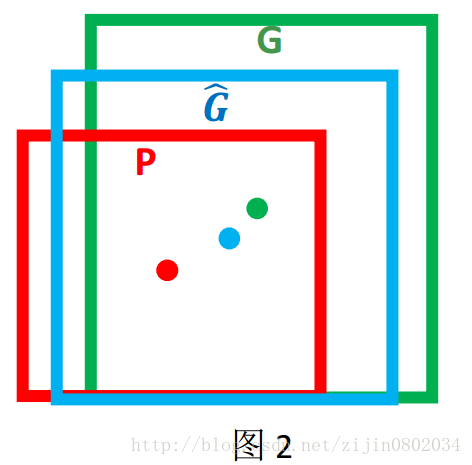
红色的框 P 代表原始的Proposal, 绿色的框 G 代表目标的 Ground Truth, 我们的目标是寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口G^。
给定(Px,Py,Pw,Ph)寻找一种映射f, 使得f(Px,Py,Pw,Ph)=(Gx^,Gy^,Gw^,Gh^) 并且(Gx^,Gy^,Gw^,Gh^)≈(Gx,Gy,Gw,Gh)
5.交并比IoU
交并比IoU用来衡量两个边界框的重叠程度
IoU=A∩B / A∪B

6.NMS非极大值抑制
对于同类目标的边界框,
1,首先筛选掉概率低于既定值的边界框
2,选取概率最大的边界框
3,筛选掉那些与之IuO>0.5(自定)的边界框
然后重复2,3
当有多类目标时,我们对每一类单独进行非最大值抑制

7.Anchor Boxes
对于多个物体中心重叠在一个格子的情况,如下图,每种目标的形状会有区别,高瘦的人,扁宽的车。
通过这两个Anchor Box来界定是哪个目标,因此这个格子的输出也就变成了16个参数

8.YOLO算法
YOLO有S*S的格子,每个格子包含B个边界框,格子对应的预测总的类别数为C种类别。

YOLO的处理流程:
1)将图片尺寸放缩到448*448大小;
2)将图片塞给CNN网络,进行处理;
3)进行NMS(非极大值抑制)进行bbox的冗余裁剪,处理掉大批的冗余,得到最后的预测结果。
9.RPN(区域候选网络)
R-CNN
1. 在图像中确定约1000-2000个候选框 (使用选择性搜索)
2. 每个候选框内图像块缩放至相同大小,并输入到CNN内进行特征提取
3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4. 对于属于某一特征的候选框,用回归器进一步调整其位置
Fast R-CNN
1. 在图像中确定约1000-2000个候选框 (使用选择性搜索)
2. 对整张图片输进CNN,得到feature map
3. 找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
4. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
5. 对于属于某一特征的候选框,用回归器进一步调整其位置
Faster R-CNN
1. 对整张图片输进CNN,得到feature map
2. 卷积特征输入到RPN,得到候选框的特征信息
3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4. 对于属于某一特征的候选框,用回归器进一步调整其位置















 6773
6773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









