






 本文探讨深度学习中卷积、池化和激励函数的顺序,重点分析池化为何要在激励函数之前。以relu激励函数为例,对比avg_pooling和MAX_pooling先激励后池化与先池化后激励的结果,指出avg_pooling先激励会丢失信息,而MAX_pooling两种顺序结果相同。
本文探讨深度学习中卷积、池化和激励函数的顺序,重点分析池化为何要在激励函数之前。以relu激励函数为例,对比avg_pooling和MAX_pooling先激励后池化与先池化后激励的结果,指出avg_pooling先激励会丢失信息,而MAX_pooling两种顺序结果相同。
以下内容为个人的看法:
顺序:卷积---池化---激励函数
我们知道卷积肯定是在第一层,毕竟 σ(wx+b),wx+b 就是卷积操作,那为什么池化要在激励函数之前呢?
原因解析:假设激励函数是 relu 激励函数:
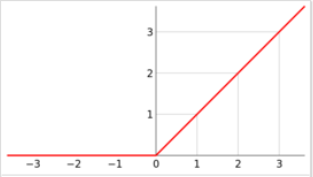
并假设我们卷积后的值为:3,-2,1,2 ;
对于 avg_poolling :
先 relu 再池化:当经过 relu 函数之后,得到的值为:relu(3) = 3,relu(-2) = 0,relu(1) = 1,relu(2) = 2,
则接下来经过 avg_pooling 结果为 ( 3+0+1+2 ) / 4 = 7/4
先池化在 relu: 经过 avg_pooling 结果为 (3-2+1+2)/4 = 4/4 = 1, 再经过 relu 函数,最终结果为 relu (1) = 1
我们看到,其实这两种操作后,得到的结果是不一样的。但是如果我们先 relu 再池化,会将卷积后的第二个值 -2 给过滤掉,当我们紧接着做 avg_pooling 时,可以认为丢失了一些信息。所以我们选择先池化再接激励函数。
对于 MAX_pooling,其实先池化再接激励函数,或者先激励函数再接池化是一样的。两个操作是可以交换的。
先 relu 再池化:当经过 relu 函数之后,得到的值为:3,0,1,2,再经过 MAX_poolling 结果为 MAX(3,0,1,2) = 3
先池化在 relu: 经过 MAX_pooling 结果为MAX (3,-2,1,2) = 3, 再经过 relu 函数,最终结果为 relu (3) = 3
完!

















 2031
2031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









