







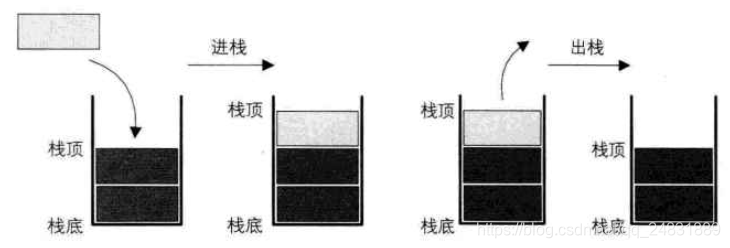
栈(stack)的定义
- 例子
- 弹夹式手枪压入子弹
- 浏览器前进后退键
- 文档图像软件中的撤销操作
- 定义
- 定义:栈(stack)是限定只在表尾进行插入和删除操作的线性表
- 允许插入和删除的一端称为栈顶(top),另一端称为栈底(bottom),不含任何数据元素的栈称为空栈.
- 栈又称为后进先出(Last In First Out)的线性表,简称LIFO结构.
- 注意点
- 栈首先是一个线性表,栈中的元素具有线性关系,即前驱后继关系.
- 栈是一种特殊的线性表,只在线性表的表尾进行插入和删除操作,这里的表尾指的是栈顶,不是栈底.
- 栈限制了线性表的插入和删除位置,只在栈顶进行插入删除操作。则:栈底是固定的,最先进栈的元素存在栈底.
- 栈的插入操作,叫做进栈push,也叫压栈,入栈;
- 栈的删除操作,叫做出栈pop,也叫弹栈.
- 进出栈顺序:有3个整型数字元素1,2,3依次进栈,求可能的出栈顺序
| 进出栈操作 | 出栈顺序 |
|---|---|
| 1,2,3进,3,2,1出 | 321 |
| 1,2进,2,1出,3进3出 | 213 |
| 1,2进,2出,3进,31出 | 231 |
| 1进,1出,23进,32出 | 132 |
| 1进,1出,2进,2出,3进,3出 | 123 |
3个元素存在5种可能的出栈顺序,除了312不可能外,其余顺序都有可能.
栈的抽象数据类型
ADT stack
stack(self) # 创建一个新的空栈
is_empty(self) # 判断栈是否为空
destroy_stack(self) # 若栈存在,则销毁它
clear_stack(self) # 若栈存在,清空栈中元素
get_top(self) # 若栈存在且非空,获取栈顶元素
push(self, elem) # 若栈存在且非满,新元素入栈
pop(self) # 若栈存在且非空,栈顶元素出栈
len(self) # 若栈存在,返回元素个数
栈的顺序存储
-
栈的顺序存储结构
- 线性表使用一维数组实现顺序存储,我们将数组下标为0的一端作为栈底,定义一个
top变量来标记栈顶元素在数组中的位置, - 假设存储栈的长度为
stacksize,则top的取值范围为[-1,stacksize).top = -1表示栈为空,top = 0说明栈只存在一个元素,top = stacksize-1说明栈满.对于stacksize=5的栈的存储情况如下所示:
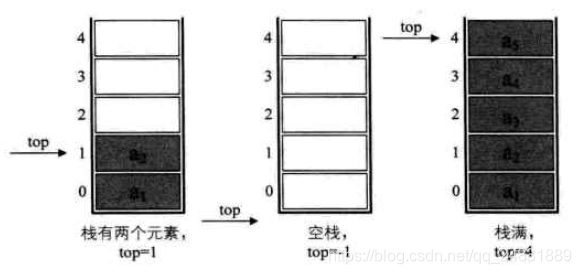
- 线性表使用一维数组实现顺序存储,我们将数组下标为0的一端作为栈底,定义一个
-
进栈
- 若栈存在且未满,栈顶指针加1,将新元素赋值给栈顶空间.
- S -> top ++, S -> data[S -> top] = elem.
def push(stack, elem): if not stack: print('there is no existing Stack named stack') return Error if stack.top == len(stack) - 1: print('the stack is full') return Error stack.top += 1 stack.data[stack.top] = elem return OK -
出栈
- 若栈存在且不为空,返回要删除的栈顶元素,栈顶指针减1
- e = S -> data[S -> top], S -> top --.
def pop(stack): if not stack: print('there is no existing Stack named stack') return Error if stack.top == -1: print('the stack is null') return Error elem = stack.data[stack.top] stack.top -= 1 return elem -
两栈共享空间
- 动机:对于栈的顺序存储结构来说,其数组存储空间大小难以确定,对于两个相同类型的栈,我们可以使用一个共享数组存储了两个栈.
- 做法:将数组的两端分别作为两个栈的栈底,两个栈如果增加元素,就从两端向中间延伸.
- 假设数组长度为n,top1和top2分别为两个栈的栈顶指针.当
top1=-1时栈1为空,当top2=n时栈2为空,当top1 + 1 == top2时,栈满. - 两栈共享空间类
class SqDoubleStack: def__init__(self, maxsize): self.data = [] self.top1 = -1 self.top2 = maxsize self.maxsize = maxsize def push(self, elem, stack_num): if self.top1 + 1 == self.top2: raise ValueError if stack_num == 1: self.top1 += 1 self.data[self.top1] = elem elif stack_num == 2: self.top2 -= 1 self.data[self.top2] = elem def pop(self, stack_num): if stack_num == 1: if self.top1 == -1: raise ValueError elem = self.data[self.top1] self.top -= 1 elif stack_num == 2: if self.top2 == self.maxsize: raise ValueError elem = self.data[self.top2] self.top2 += 1- 总结:当两个栈的数据类型相同,且空间需求有相反作用时,通常使用两栈共享的空间存储方法才有比较大的意义.
栈的链式存储
-
栈的链式存储结构
- 栈的链式存储结构,简称为链栈Linked Stack
- 将单链表的头指针和栈的栈顶指针合二为一,去掉单链表中常用的头结点,形成了下图的结构:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c9ZSkjvr-1570845319667)(images/4-3.png)]](https://img-blog.csdnimg.cn/20191012101701825.png)
- 链栈类实现
# 单链表结点类 class Node: def __init__(self, value, next = None): self.val = value self.next = next class LinkedStack: def __init__(self): self.top = None self.num = 0 def is_empty(self): return self.top is not None def push(self, elem): s = Node(elem) if self.top == None: self.top = s else: s.next = self.top self.top = s self.num += 1 def pop(self): if self.num == 0: raise ValueError elem = self.top.val self.top = self.top.next self.num -= 1 return elem- 顺序栈和链栈的比较
- 时间复杂度都为O(1)
- 空间性能
- 顺序栈需要事先确定一个固定长度,可能存在内存浪费,优势是存取时定位很方便
- 链栈的每个元素都有指针域,增加了内存开销,但对于栈的长度无限制
- 结论:如果栈的使用过程中元素变化不可预料,使用链栈,反之使用顺序栈.
栈的应用
- 函数调用
- 表达式求值
- 括号匹配
- 实现浏览器的前进后退功能














 6208
6208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









