






执行引擎
执行引擎的目标是自动化的平衡资源控制与执行效率。
连接模式
连接模式(Connection Mode)的概念,将其划分为内存限制模式(MEMORY_STRICTLY)和连接限制模式(CONNECTION_STRICTLY)这两种类型。
内存限制模式
使用此模式的前提是,ShardingSphere对一次操作所耗费的数据库连接数量不做限制。 如果实际执行的SQL需要对某数据库实例中的200张表做操作,则对每张表创建一个新的数据库连接,并通过多线程的方式并发处理,以达成执行效率最大化。 并且在SQL满足条件情况下,优先选择流式归并,以防止出现内存溢出或避免频繁垃圾回收情况。
连接限制模式
使用此模式的前提是,ShardingSphere严格控制对一次操作所耗费的数据库连接数量。 如果实际执行的SQL需要对某数据库实例中的200张表做操作,那么只会创建唯一的数据库连接,并对其200张表串行处理。 如果一次操作中的分片散落在不同的数据库,仍然采用多线程处理对不同库的操作,但每个库的每次操作仍然只创建一个唯一的数据库连接。 这样即可以防止对一次请求对数据库连接占用过多所带来的问题。该模式始终选择内存归并。
内存限制模式适用于OLAP操作,可以通过放宽对数据库连接的限制提升系统吞吐量; 连接限制模式适用于OLTP操作,OLTP通常带有分片键,会路由到单一的分片,因此严格控制数据库连接,以保证在线系统数据库资源能够被更多的应用所使用,是明智的选择。
自动化执行引擎
自动化执行引擎将连接模式的选择粒度细化至每一次SQL的操作。 针对每次SQL请求,自动化执行引擎都将根据其路由结果,进行实时的演算和权衡,并自主地采用恰当的连接模式执行,以达到资源控制和效率的最优平衡。 针对自动化的执行引擎,用户只需配置maxConnectionSizePerQuery即可,该参数表示一次查询时每个数据库所允许使用的最大连接数。
执行引擎分为准备和执行两个阶段:
准备阶段
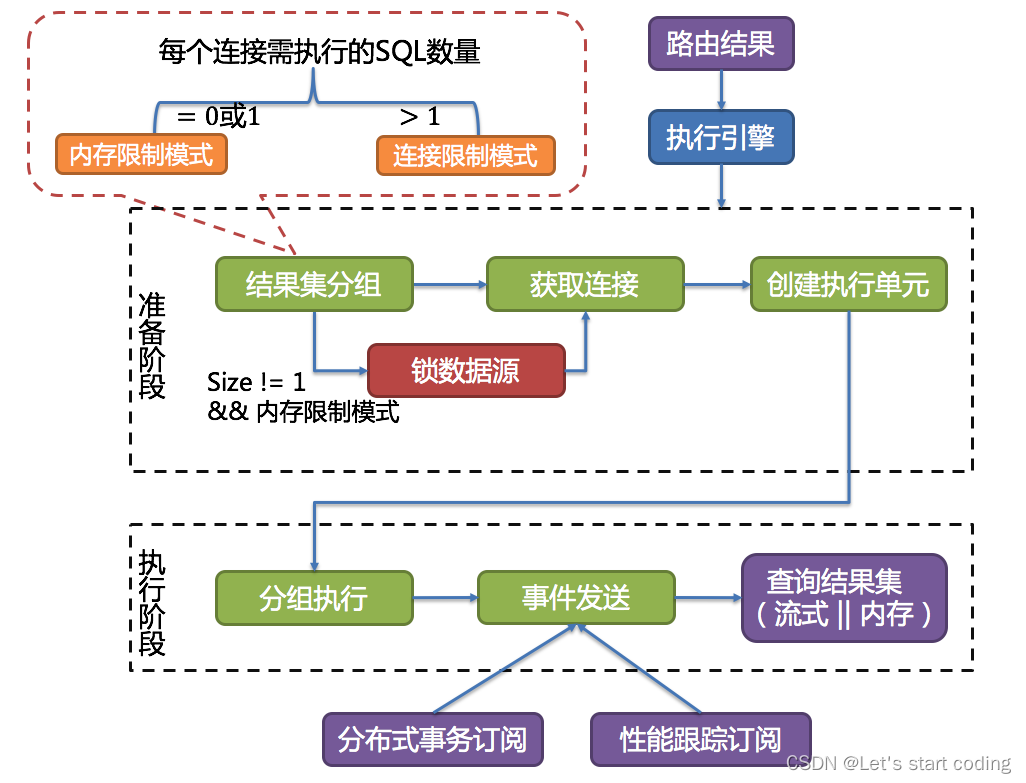
结果集分组是实现内化连接模式概念的关键。执行引擎根据maxConnectionSizePerQuery配置项,结合当前路由结果,选择恰当的连接模式。 具体步骤如下:
- 将SQL的路由结果按照数据源的名称进行分组。
- 通过下图的公式,可以获得每个数据库实例在maxConnectionSizePerQuery的允许范围内,每个连接需要执行的SQL路由结果组,并计算出本次请求的最优连接模式
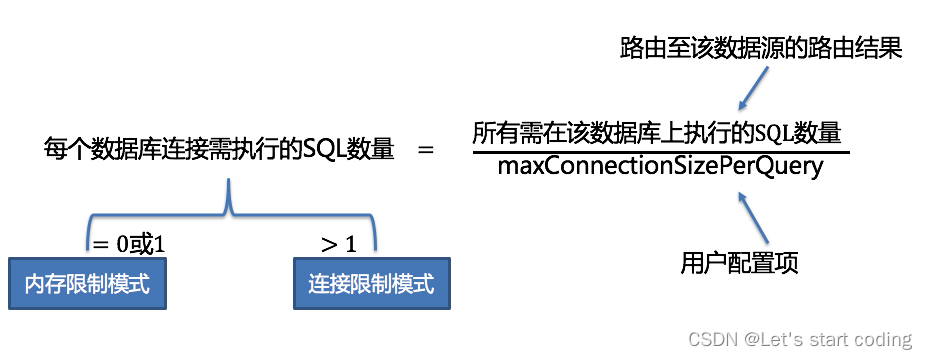
在maxConnectionSizePerQuery允许的范围内,当一个连接需要执行的请求数量大于1时,意味着当前的数据库连接无法持有相应的数据结果集,则必须采用内存归并; 反之,当一个连接需要执行的请求数量等于1时,意味着当前的数据库连接可以持有相应的数据结果集,则可以采用流式归并。
每一次的连接模式的选择,是针对每一个物理数据库的。也就是说,在同一次查询中,如果路由至一个以上的数据库,每个数据库的连接模式不一定一样,它们可能是混合存在的形态。
通过上一步骤获得的路由分组结果创建执行的单元。 当数据源使用数据库连接池等控制数据库连接数量的技术时,在获取数据库连接时,如果不妥善处理并发,则有一定几率发生死锁。 在多个请求相互等待对方释放数据库连接资源时,将会产生饥饿等待,造成交叉的死锁问题。
通过上一步骤获得的路由分组结果创建执行的单元。 当数据源使用数据库连接池等控制数据库连接数量的技术时,在获取数据库连接时,如果不妥善处理并发,则有一定几率发生死锁。 在多个请求相互等待对方释放数据库连接资源时,将会产生饥饿等待,造成交叉的死锁问题。
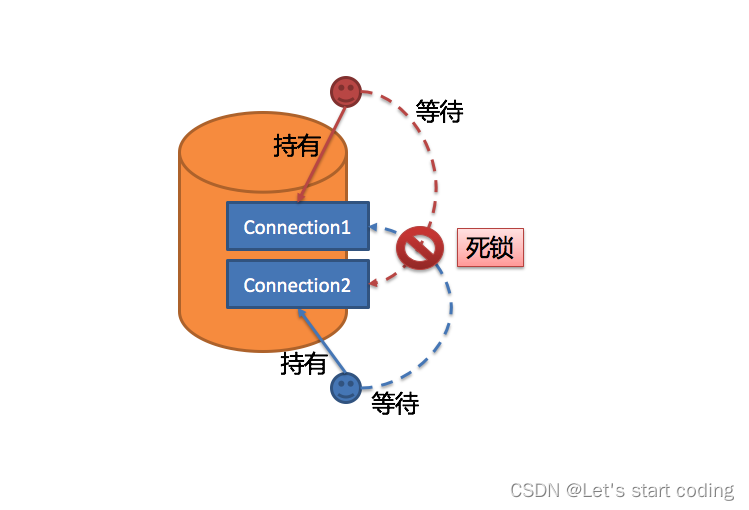
ShardingSphere为了避免死锁的出现,在获取数据库连接时进行了同步处理。 它在创建执行单元时,以原子性的方式一次性获取本次SQL请求所需的全部数据库连接,杜绝了每次查询请求获取到部分资源的可能。 由于对数据库的操作非常频繁,每次获取数据库连接时时都进行锁定,会降低ShardingSphere的并发。因此,ShardingSphere在这里进行了2点优化:
避免锁定一次性只需要获取1个数据库连接的操作。因为每次仅需要获取1个连接,则不会发生两个请求相互等待的场景,无需锁定。 对于大部分OLTP的操作,都是使用分片键路由至唯一的数据节点,这会使得系统变为完全无锁的状态,进一步提升了并发效率。 除了路由至单分片的情况,读写分离也在此范畴之内。
仅针对内存限制模式时才进行资源锁定。在使用连接限制模式时,所有的查询结果集将在装载至内存之后释放掉数据库连接资源,因此不会产生死锁等待的问题。
执行阶段
该阶段用于真正的执行SQL,它分为分组执行和归并结果集生成两个步骤。
分组执行将准备执行阶段生成的执行单元分组下发至底层并发执行引擎,并针对执行过程中的每个关键步骤发送事件。 如:执行开始事件、执行成功事件以及执行失败事件。执行引擎仅关注事件的发送,它并不关心事件的订阅者。 ShardingSphere的其他模块,如:分布式事务、调用链路追踪等,会订阅感兴趣的事件,并进行相应的处理。
ShardingSphere通过在执行准备阶段的获取的连接模式,生成内存归并结果集或流式归并结果集,并将其传递至结果归并引擎,以进行下一步的工作。
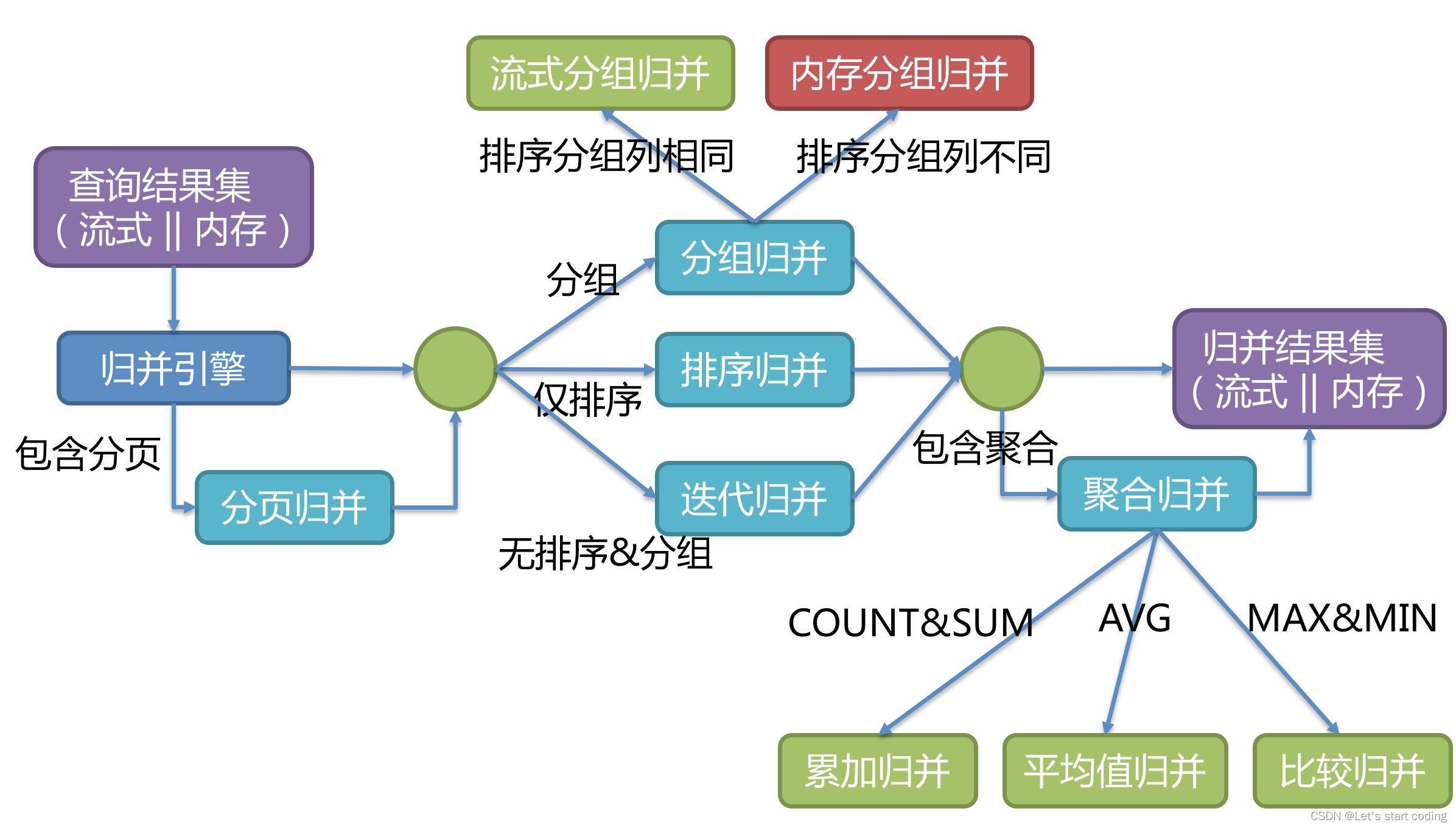
归并引擎
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。
ShardingSphere支持的结果归并从功能上分为遍历、排序、分组、分页和聚合5种类型,它们是组合而非互斥的关系。 从结构划分,可分为流式归并、内存归并和装饰者归并。流式归并和内存归并是互斥的,装饰者归并可以在流式归并和内存归并之上做进一步的处理。
流式归并是指每一次从结果集中获取到的数据,都能够通过逐条获取的方式返回正确的单条数据,它与数据库原生的返回结果集的方式最为契合。遍历、排序以及流式分组都属于流式归并的一种。
内存归并则是需要将结果集的所有数据都遍历并存储在内存中,再通过统一的分组、排序以及聚合等计算之后,再将其封装成为逐条访问的数据结果集返回。
装饰者归并是对所有的结果集归并进行统一的功能增强,目前装饰者归并有分页归并和聚合归并这2种类型。
遍历归并
它是最为简单的归并方式。 只需将多个数据结果集合并为一个单向链表即可。在遍历完成链表中当前数据结果集之后,将链表元素后移一位,继续遍历下一个数据结果集即可。
排序归并
由于在SQL中存在ORDER BY语句,因此每个数据结果集自身是有序的,因此只需要将数据结果集当前游标指向的数据值进行排序即可。 这相当于对多个有序的数组进行排序,归并排序是最适合此场景的排序算法。
ShardingSphere在对排序的查询进行归并时,将每个结果集的当前数据值进行比较(通过实现Java的Comparable接口完成),并将其放入优先级队列。 每次获取下一条数据时,只需将队列顶端结果集的游标下移,并根据新游标重新进入优先级排序队列找到自己的位置即可。
通过一个例子来说明ShardingSphere的排序归并,下图是一个通过分数进行排序的示例图。 图中展示了3张表返回的数据结果集,每个数据结果集已经根据分数排序完毕,但是3个数据结果集之间是无序的。 将3个数据结果集的当前游标指向的数据值进行排序,并放入优先级队列,t_score_0的第一个数据值最大,t_score_2的第一个数据值次之,t_score_1的第一个数据值最小,因此优先级队列根据t_score_0,t_score_2和t_score_1的方式排序队列。
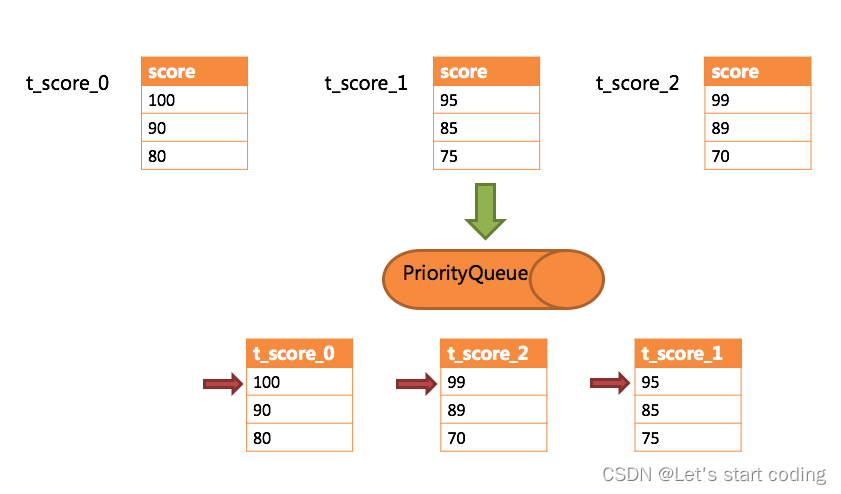
下图则展现了进行next调用的时候,排序归并是如何进行的。 通过图中我们可以看到,当进行第一次next调用时,排在队列首位的t_score_0将会被弹出队列,并且将当前游标指向的数据值(也就是100)返回至查询客户端,并且将游标下移一位之后,重新放入优先级队列。 而优先级队列也会根据t_score_0的当前数据结果集指向游标的数据值(这里是90)进行排序,根据当前数值,t_score_0排列在队列的最后一位。 之前队列中排名第二的t_score_2的数据结果集则自动排在了队列首位。
在进行第二次next时,只需要将目前排列在队列首位的t_score_2弹出队列,并且将其数据结果集游标指向的值返回至客户端,并下移游标,继续加入队列排队,以此类推。 当一个结果集中已经没有数据了,则无需再次加入队列。














 1001
1001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









