




 这篇博客解析了ViG(Vision GNN)论文,介绍了一种通过将图像划分为16x16像素节点构建图的创新方法,用于跨模态图匹配任务。论文展示了如何用GNN处理视觉数据,涉及的开源实现来自华为、中科院和北京大学。
这篇博客解析了ViG(Vision GNN)论文,介绍了一种通过将图像划分为16x16像素节点构建图的创新方法,用于跨模态图匹配任务。论文展示了如何用GNN处理视觉数据,涉及的开源实现来自华为、中科院和北京大学。

论文:http://arxiv.org/abs/2206.00272
开源地址(即将开源):
https://github.com/huawei-noah/CV-Backbones
https://gitee.com/mindspore/models
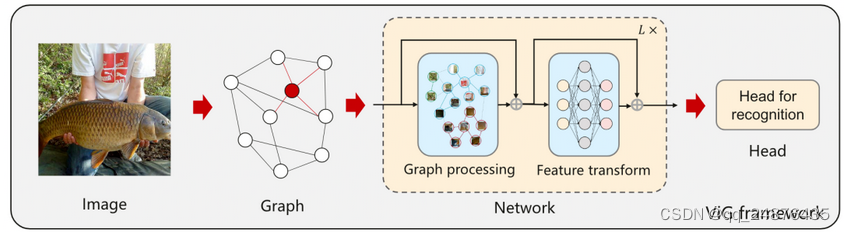
最近在看一些跨模态图匹配的工作,想找一些图构建的方法,今天恰好看到这篇ViG的工作,类似ViT 工作一样,可以将图像划分为patch,每16x16像素为一个Patch,也就是图数据中的一个节点,总共有196个节点,直接处理图像数据,很受吸引,这里分享了一个知乎的解读,便于自己理解。论文笔记(十六)Vision GNN: An Image is Worth Graph of Nodes 只使用GNN进行视觉任务 中科院华为北大22年6月论文 - 知乎


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









