







基于有效特征提取和交互学习的跨模态图像文本检索
2022年 Scientific Programming
摘要:针对多模态环境的复杂性和现有浅层网络结构无法实现高精度的图文检索,提出一种结合高效特征提取和交互式学习卷积自动编码器CAE的跨模态图像和文本检索方法。首先,改进残差网络卷积核,引入二维主成分分析提取图像特征,通过长短时记忆网络LSTM和词向量提取文本特征,高效提取图特征。基于交互式学习CAE,实现了图像和文本的跨模态检索。其中,图像和文本特征分别输入双模式CAE的两个输入端,通过中间层的交互学习得到图文关系模型,实现图文检索。最后,基于Flickr30K、MSCOCO和Pascal VOC 2007数据集,对提出的方法进行了实验验证。实验结果表明,该方法能够完成准确的图像检索和文本检索。此外,平均查准率(MAP)达到0.3以上,查准率和查全率(PR)曲线的面积优于其他比较方法,具有一定的适用性。
1. Introduction
随着数字化的推进,越来越多的人使用互联网来获取他们需要的信息。如何让用户准确、快速地搜索到自己需要的信息已经成为一个热点问题。在移动互联网时代,我们每个人都在接收来自互联网的海量信息,同时产生海量的多媒体信息,即多模态数据。原始形式的跨模态检索类似于单模态检索。随着多模态数据的增长,用户更加难以高效、准确地检索到自己感兴趣的信息。迄今为止,检索方法很多,其中大部分都是基于单一的模态,如按文本搜索文章,按图片搜索图片,或表面上的多模态搜索。其实就是以搜索关键词的形式,在互联网众多资源中查询和请求最匹配的内容。
为了满足人们的实际需求,提供更好的检索服务,学者们致力于跨模态检索领域相关方法和实践的研究。提出的跨模态检索方法具有广泛的应用场景和研究意义。如何挖掘这些多模态数据中的有效信息是跨模态检索研究领域的一个重要问题。
研究人员发现数据的低层特征和高层语义之间存在语义鸿沟,不同模态的数据是异构的[4,5]。可见,跨模态检索研究的核心是挖掘不同模态数据之间的关联信息。如何挖掘这些关联信息成为跨模态检索技术研究的关键。
近年来,随着深度学习技术的快速发展,人们已经越来越有能力解决更复杂的机器学习问题,并在分析和处理多模态数据方面取得了很大进展[6]。多模态内容分析在智慧城市、智慧家庭、智慧交通等多个领域具有广泛的应用前景。基于深度学习在单模态领域应用研究的突破性进展,将其应用于跨模态检索任务的理论研究,同时提供技术实践[7]。
目前的跨模态检索系统建模主要解决两个问题:一是如何完成不同模态信息特征的统一映射,二是如何在保证检索率的基础上提高模型的检索率。这两个问题是相互依存的。由于不同模态信息的多样性和异构性,各模态的特征提取方法和统一表示形式成为解决问题的关键。此外,三种及以上模态的语料库研究比较少,两种模态的语料库比较常见。特别是带有图像和文本的模态对齐的语料库更为常见。
2. Related Research
由于不同模态数据之间存在巨大的异构鸿沟,如何有效地度量不同模态数据的内容相似性成为一大挑战[11]。如今,已经提出了许多跨模态检索方法[12]。
2.1.实值跨模态检索方法 Real-Valued Cross-Modal Retrieval Method.
基于实值表示的跨模态检索方法一般可以分为两类:典型相关分析(CCA)和深度学习[13]。CCA使用不同的模态数据形成样本对,学习一个投影矩阵,将不同的模态数据投影到一个共同的潜在子空间,然后在子空间中,度量模态数据之间的相似性[14]。参考文献[15]提出了一种新的用于跨模态检索的多标记核典型相关分析(ml-KCCA)方法,该方法使用多标记注释中反映的高级语义信息来增强核典型相关分析。参考文献[16]提出了具有深度典型相关分析的跨媒体相关学习(CMC-DCCA)。能够更好地挖掘跨媒体数据之间的复杂关联,实现更好的跨媒体检索性能。然而,其特征提取算法的性能高度依赖于样本集的大小,并且在实际情况下很难获得非合作目标的训练样本。如何高效地设置参数范围,还需要进一步探索。
基于深度学习的跨模态检索方法充分利用深度学习模型强大的特征提取能力,学习不同模态数据的特征表示,进而在高层建立模态之间的语义关联[17]。参考文献[18]提出了一种监督跨模态检索的两阶段深度学习方法,将传统的范数相关分析从2视图扩展到3视图,分两个阶段进行监督学习。评估在两个公开数据集上的实验结果表明,该方法具有更好的性能。但是,对于复杂检索环境的检测精度,仍有优化的空间。目前,表征学习模型在自动提取特征时获得的维数相对较高。尤其是基于深度学习的跨模态检索模型,在表示阶段得到的样本特征维数通常不小于4096,最终的特征维数仍然过高[19]。参考文献[20]提出了一种结合深度玻尔兹曼机(DBM)和CNN提取图像高阶语义特征的图像检索方法。
2.2. Cross-Modal Retrieval Method Based on Hash Transformation.基于哈希变换的跨模态检索
基于实值表示的跨模态检索方法在面对大规模数据时存在计算耗时和需求空间大的问题。提出了一种基于哈希变换的信息检索方法。该方法是基于不同模态数据的成对样本对,学习相应的哈希变换,将相应的模态数据特征映射到汉明二进制空间,然后在这个空间实现更快的跨模态检索[21]。哈希变换的前提是相似样本的哈希码也是相似的。参考文献[22]提出了一种称为DNDCMH的方法。算法使用指定特定面部属性的存在的二进制向量作为输入查询,以从数据库中检索相关的面部图像。其次,主成分分析(PCA)等降维方法可以在一定程度上降低特征维数,但在保持必要的检索精度的前提下,可降维的维数相当有限,缺乏能够适应大规模图像集的高效合理的检索机制[23]。参考文献[24]提出了一种新的自监督深度多模态哈希(SSDMH)方法。然而,跨模态检索仍然只实现了图像内容和主题词的匹配,忽略了大量基于内容的、细微的、重要的图像信息[25]。参考文献[26]提出了一种深度哈希方法,可以将堆叠卷积自动编码器与哈希学习相结合,并将输入图像分层映射到低维空间。一些额外的松弛约束被添加到目标函数以优化hash算法。在超高维图像数据集上的实验结果表明,该方法在跨模态检索中具有良好的稳定性,但检测时效性有待优化。然而,各种模型都有其特定的适应目标、优势和局限性。如何在实际应用中结合模型和各种算法的优势,构建一个通用的跨模态检索模型是当前跨模态检索研究中亟待解决的问题之一。
2.3. Other Cross-Modal Retrieval Methods.其他跨模态检索方法
除了以上经典方法,还有一些其他方法。例如,冯等人[27]提出了一种自动编码器(Corr-AE)模型,其特征在于使用两个自动编码器网络将图像向量和文本向量彼此编码,以获得用于模型训练的两个相关损失项。参考文献[28]提出了一种基于多模态语义自动编码器的检索方法。方法使用编码器解码器来学习映射,并在确保嵌入的同时保留特征和语义信息。在[29]中提出的双向网络模型也应用了自动编码器的思想,其比Corr-AE更详细地被优化。参考文献[30]提出了一种基于语义概念和顺序(SCO)的图形匹配方法,其特点是在检索图像时引入了多标签分类机制。具体来说,SCO对目标检测网络提取的每个候选图像执行多标签分类操作,使得每个候选图像不仅可以携带实体类别信息,还可以添加一些属性标签。
根据以上分析,(1)在CCA方法中,先提取不同数据的单模态特征表示,然后进行关联学习。两阶段法不能保证提取的单模态特征是关联学习所需的有效表示。(2)深度学习方法中,大部分网络使用浅层网络对关联学习部分进行建模,忽略了模式间的高层语义关联。(3)在深度哈希方法中,当它将模态表示转换为哈希编码时,会丢失一些信息。
有效的特征提取和特征关联学习是提高跨模态检索准确率的关键。为了更好地进行不同模态数据之间的关联学习,提出了一种结合高效特征提取和交互式学习卷积自动编码器(CAE)的跨模态图文检索方法。提出的方法的创新之处如下:
图像特征提取:将2DPCA构造的新卷积核集成到基于残差网络的图像特征提取中,避免了传统PCA的复杂运算,降低了图像空间特征的维数。
跨模态CAE架构:在传统多模态CAE架构的基础上,集成了一个特征关联模块(即联合公共表示),将各个模态的表示关联起来,实现交互学习,使学习到的各个模态的中间表示包含模态之间的关联关系,提高跨模态检索的准确率。
3. Method Framework
3.1. Overall Framework.为了充分利用多模态数据信息互补的优势,在训练阶段,该方法同时将图像数据和文本数据作为网络的输入,通过多模态CAE模型进行图像和文本特征的交互学习,生成检索系统的分类模型。在测试阶段,将图像或文本特征输入分类模型进行判别,得到检索结果。总体结构如图所示
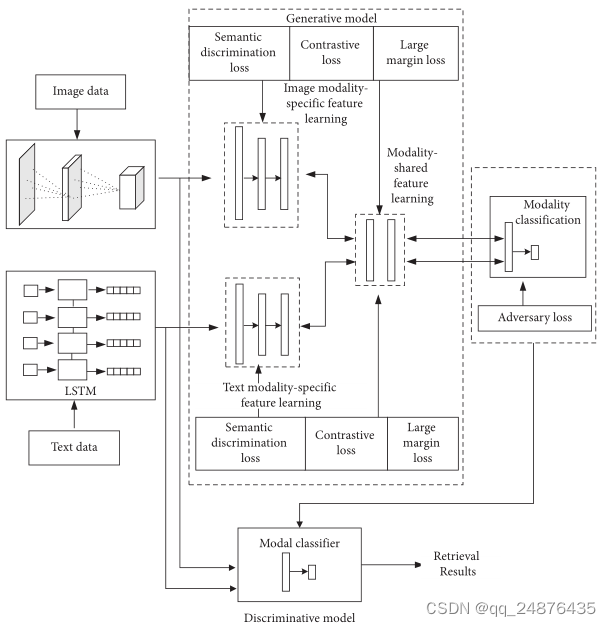
其中,图像数据使用残差网络作为图像特征提取器,并引入二维主成分分析(2DPCA)构造新的卷积核。文本数据使用word2vec和长短期记忆(LSTM)网络作为文本特征提取器。采用基于交互学习的跨模态卷积CAE设计网络融合层,将两种模态数据特征融合并发送到下一个全连接层。为了学习从图文数据特征空间到语义标签空间的非线性映射,防止过拟合,在全连通层中增加了归一化层和ReLU层。最终全连接层的输出维度与真实标签的数据维度一致。提出的方法充分利用了多模态数据图像数据和文本数据不同模态数据的互补信息。
3.2.改进的卷积核图像特征提取
3.2.1.卷积神经网络用于提取图像特征。对于图像特征的提取,选择了非常主流的残差网络,更适合图像特征。网络有五个卷积级,每个卷积级都有相应的池化操作。输入一幅图像数据后,经过层层卷积处理,输出的图像特征图大小为7 × 7 × 2048,可以根据后续机器学习任务的需要进行处理。图像模态数据维数高,内容信息丰富。深度卷积神经网络的选择将提取有效的视觉单模态表示特征。利用Wx简化整个嵌入式子网的模型参数,图像模态数据经过这个网络后的特征输出hx为
![]()
其中X是输入图像模态数据。
3.2.2.引入2DPCA构造新的卷积核。PCA是一种提取高维空间数据的主要特征,并将其转换到低维向量空间的线性分析方法。2DPCA直接利用图像的二维信息,在保留图像空间特征的同时,避免了PCA的行列向量转换带来的复杂计算。假设有M个图像I={I1,I2,…,IM}尺寸为w×h×c,样本的平均图像可表示为

每个样本和平均图像之间的差图像是
![]()
要求的协方差矩阵是
![]()
最优投影子空间U={η1,η2,…,ηd}可以使用对应于协方差矩阵的前d个特征值的正交特征向量来构建。将原始图像映射到投影空间,可以得到降维后的特征图像Ti=ZiU。2DPCA算法的流程如图2所示。
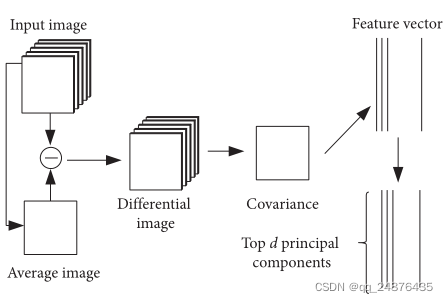
图2DPCA算法的流。
4. Cross-Modal Convolutional Autoencoder 交叉模式卷积自动编码器
4.1.经典卷积自动编码器(CAE)。自动编码器(AE)是一种无监督学习算法,通过学习数据表示使输出接近输入。AE通过编码器提取数据特征,然后通过解码器对获得的特征进行解码,实现输入数据的重构。CAE是基于无监督的AE,结合CNN的卷积和池化操作来卷积编码器和解码器,以实现更好的特征提取[31]。单层CAE网络模型如图3所示。编码部分由卷积层和最大池化层组成。
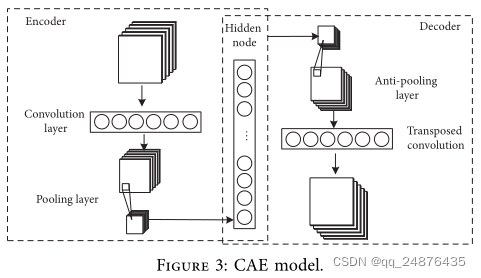
给定MC1特征图I={I1,I2,…,IC1}卷积运算后,得到一组FC2特征图
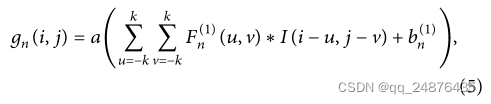
其中gn(I,j)是第n个通道的激活图中像素(i,j)处的激活值,a()是非线性激活函数。滤波器的大小是fc2=2k+1。F(1)n是编码过程中卷积滤波器的权重,每个滤波器的通道数与输入样本的通道数相同。b(1)n是编码器卷积层到第n个信道的激活图的偏移。
卷积编码部分的卷积层输出特征图的大小是
![]()
最大池化操作后,得到编码部分的最终输出。其中,
![]()
是卷积模块C1的输出特征映射尺寸。
解码过程是从特征激活图重建原始图像的过程。CAE是全卷积网络,所以解码过程主要通过反卷积运算来实现。考虑到编码后得到的特征激活图的大小小于原始图像,仅通过解码过程的转置卷积无法重构原始图像的大小信息。因此,需要对输入的特征图进行补零操作以便以后解码;可以重建与原始图像大小相同的重建图像。编码部分的卷积输出被用作解码器的输入,然后与卷积滤波器F(2)进行卷积,以获得重建图像:
![]()
其中G是通过编码获得的特征映射的集合,b(2)n是对应于解码器去卷积层的第n个通道的激活映射的偏移。
4.2.基于交互学习的跨模态CAE。
与现有的多模态CAE模型[32,33]不同,该方法在分别学习不同模式的表示的同时,通过隐层后的一个特征关联模块(即联合公共表示)在每个模式的表示之间产生某种关联,实现交互学习。因此,每个模态的中间表示包含了模态之间的相关性,有助于提高跨模态检索的准确性。提出的双模态互动学习CAE架构如图4所示。
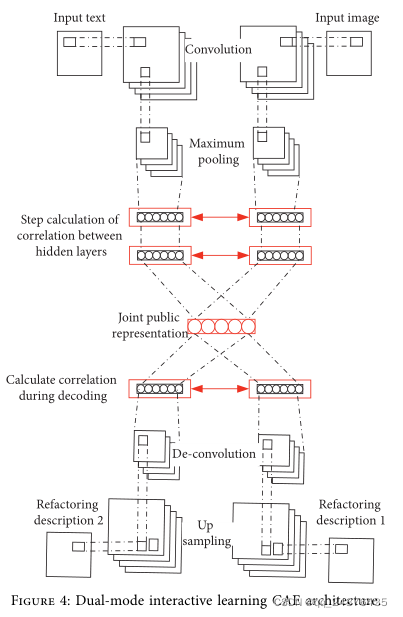
输入文本和图像数据分别通过卷积层和池层获得数据表示。通过中间交互层,对文本和图像数据的特征表示进行交互学习,获得新的公共表示特征数据。原始输入可通过特征数据的反卷积获得[34–36]。
为了训练双模式交互学习CAE,需要在训练阶段构造目标函数。在经典的CAE训练中,目标函数通常是最小化重建误差。但是,在双模式交互学习CAE模型中,集成了多模态特征之间的交互学习,以提高模型检索的准确性。所以,目标函数需要包括最大化隐藏层中两个模态特征之间的相关性的目标。
给定的输入是zi={xi;yi},其中zi是输入视图xi和yi的关联表示。自重构损失和交叉重构损失定义为
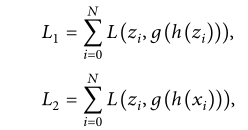
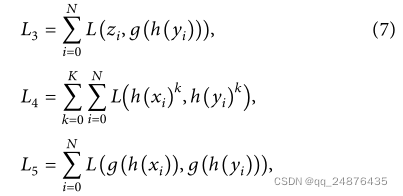
其中g、h是通常被认为是ReLU的非线性度,
![]()
是第K个中间隐藏层(K=2)的表示,L是误差函数。在损失L2和L3(用于交叉重建)中,使用0向量而不是另一个视图来计算xi和yi。
最后,为了增强两个模态特征之间的相互作用,相关损失的目标函数表示如下:
![]()
![]()
其中h(X)和h(Y)是组合模型的投影(图4中联合公共表示的投影)。x和Y是两个模态特征的表示。λk是用于每个第k个中间编码步骤的相对正则化超参数(类似地,在解码阶段使用λ)。在编码过程中,使用了一个卷积层和两个中间层(K=2)。对于解码,去卷积层和中间层(K=1)用于重建。λ影响模型训练的复杂度。过小时,模型容易过拟合。当值较大时,容易造成欠拟合。考虑到每个网站上的搜索结果这里统一设置数据集,L7项中λ1=0.004,λ2=0.05,L6项中λ=0.02。
两个视图h(X)和h(Y)之间的相关性为
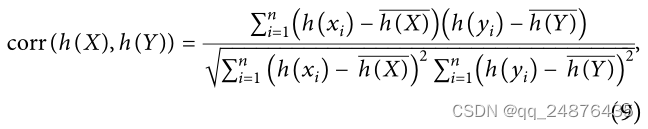
其中-h(X)和-h(Y)是两个视图的隐藏表示的平均向量。h(xi)和h(yi)是单模态视图的隐藏层表示。
整合所有目标函数以构建总目标函数,其表达如下:
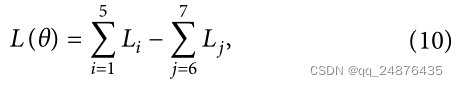
其中,θ是模型参数。上面的公式最小化了自重建和交叉重建,并且最大化了视图之间的关联。
5. Experiment and Analysis
5.1. Experimental Dataset.为了验证该方法的性能,在三个常用的真实跨模态图形检索数据集上验证了该方法的有效性:Flickr30K数据集、MSCOCO数据集和Pascal VOC 2007数据集。
Flickr30K: Flickr30K数据集包含31783张图片,图片的英文描述为158915句。每个图像对应5句不同的描述句。这些图像的㼿e语句描述是通过人工注释获得的。㼿e Flickr30K数据集分为三部分:1000张图片和相应描述作为验证数据集,1000张图片和相应描述作为测试数据集,剩余部分作为训练数据集。
MSCOCO: MSCOCO数据集包含123287幅图像,每幅图像还对应5个不同的描述语句。数据集分为四部分,其中82783幅图像作为训练数据集,5000幅图像作为验证数据集,5000幅图像作为测试数据集,30504幅图像作为保留数据集。
Pascal VOC 2007: Pascal VOC 2007数据集包含5011个用于训练的图像注释对和4952个用于测试的图像注释对,这些数据都来自Flickr网站。每个样本对被标记为20个语义类别中的一个。㼿is数据集被随机分为三个子集:训练集、测试集和验证集,分别包含800、100和100个样本。
实验运行环境是一台配置英特尔酷睿i7-7700 CPU和Nvidia GTX1070Ti 8G显存GPU的PC。深度学习使用的框架是PyTorch,开发语言是Python。
5.2.性能指数和比较法。选取了跨模态检索领域常用的评价指标对所提出的方法进行比较和分析:平均精度(MAP)和精度-召回率(PR)曲线。其中,MAP可以通过正样本和负样本在搜索结果中的位置,对实验结果进行有效评估。AP表示每个特定搜索的平均准确度,计算如下:
![]()
其中N表示属于与查询相同的语义类别的搜索结果的总数。n是搜索返回的所有结果的数量。k是搜索结果序列中的位置索引。P(k)是第一个k搜索的精度。φ(k)表示第k个搜索结果和查询是否具有相同的语义类别(相同为1,不同为0)。
MAP的值是对应于多个搜索的AP值的平均值:
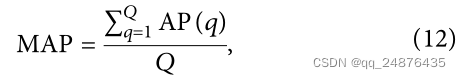
其中Q表示搜索的总数。
使用MAP@R表示给定一个查询,根据相似性对相似性最高的前R个结果进行排序。对这些r结果的准确度进行平均:
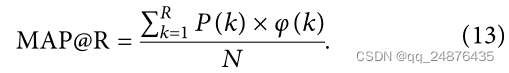
PR曲线是准确率随召回率变化的曲线,作为跨模态检索的性能评价指标。
在实验中,选取的三个数据集有两种模式:图像和文本。在两个检索任务上比较了模型和参考模型,即用图像检索文本和用文本检索图像。例如,当基于文本检索图像时,所提出的方法选择测试集中的每个文本来检索测试集中的所有图像,并最终获得检索结果。
为了验证该方法的有效性,与CCA和深度哈希方法进行了比较。对应的研究是[15]提出的多标记核典型相关分析(ml-KCCA)方法和[22]提出的跨模态哈希检索方法(DNDCMH)。此外,为了突出本文提出的交互式学习CAE模型的有效性,与基于CAE模型的其他方法进行了比较,如[28]提出的基于多模态语义自动编码器(SCAE)的文本检索方法。
5.3.跨模态检索示例
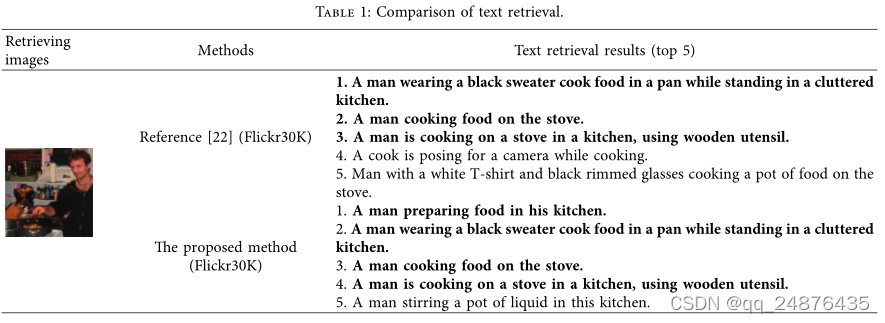
5.3.1.图文检索分析。通过所提出的方法和[22]检索方法获得的图文检索结果如表1所示。它是文本检索Flickr30K测试集上的图像结果。粗体的文本是正确的召回文本,没有粗体的文本是错误的召回文本。
从表1可以看出,所提出的方法在召回指数方面具有更好的检索结果。具体来说,在文本检索任务中,所提出的方法使用图像搜索来寻找更高级的正确文本排序。直观地呈现了现象,更加直观地说明了所提方法的有效性。在[22]中,DNDCMH用于实现文本检索。由于缺乏图像特征提取效果,正确文本较少。
5.3.2.文本图像检索分析。为了比较所提出的方法和比较方法[15,22,28]的性能,在文本-图像检索中,使用“汽车”作为查询文本来检索Pascal VOC 2007数据集上的图像。通过各种方法检索的前5幅图像如图5所示。
从图5可以看出,与其他比较方法相比,该方法的文本检索结果更加合理。由于该方法使用word2vec和LSTM网络进行文本特征提取,提取效果更好。通过交互学习的CAE网络获得的检索图像更加准确。

图5:使用文本“汽车”进行图像检索的例子
5.4.性能对比。为了证明所提出的方法在三个数据集上的检索性能,将其与[15,28]和[22]中的方法进行了比较。四种方法的前50个结果的图值如表2所示。
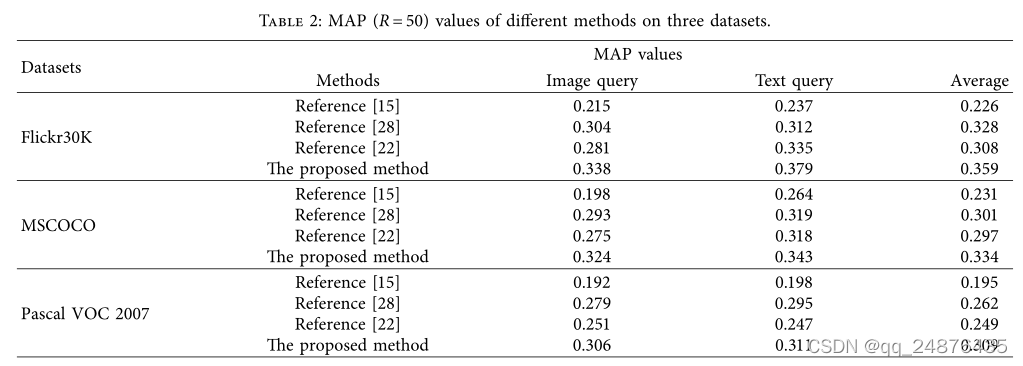
从表2中可以看出,在通过文本检索图像和通过图像检索文本这两个检索任务中,与其他比较方法相比,所提出的方法在这三个数据集上的MAP有了显著的提高。由于Pascal VOC 2007数据集具有最大的量级,因此所提出的方法在Pascal VOC 2007上具有最显著的改进。在Flickr30K MSCOCO和Pascal VOC 2007三个跨模态图形检索领域数据集上,该方法在两个检索任务上的平均MAP分别为0.359、0.334和0.309。与[15]相比,分别提高了58.85%、44.59%、58.46%;与[28]相比,分别下降了14.14%、9.57%和10.69%;与[22]相比,分别下降了16.56%、12.46%和24.10%。
此外,在Flickr30K数据集上使用不同的方法,图像检索和文本检索两种不同检索任务的PR曲线如图6所示。纵坐标代表精度,横坐标代表召回率。类似地,在MSCOCO和Pascal VOC 2007数据集上使用不同方法的两个不同检索任务的PR曲线分别显示在图7和图8中。
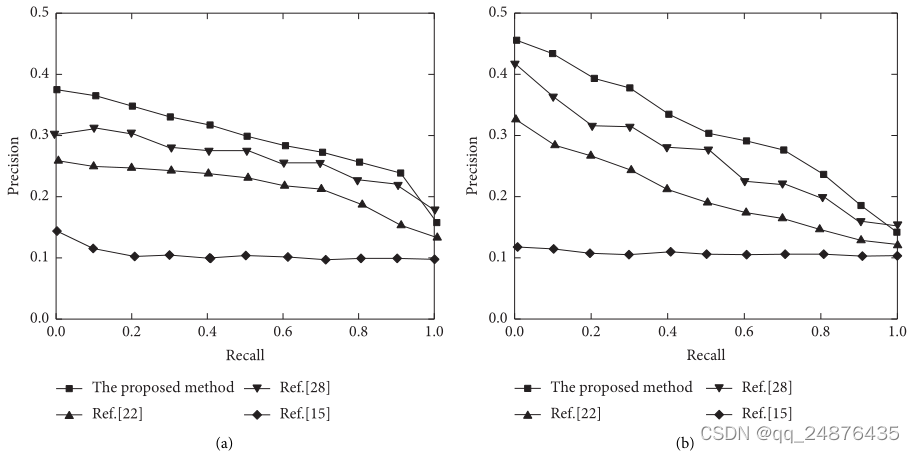
图6 Flickr30K数据集上的PR曲线。(a)用图像检索文本。(b)用文本检索图像。
从图6可以看出,无论是图像检索文本还是文本检索图像,提出的方法的PR曲线面积都比其他比较方法大。由于采用了图文交互CAE的跨模态检索方法,并将2DCPA融入到特征提取中,提高了检索的准确率。参考文献[15]提出了一种ml-KCCA方法来实现跨模式检索,但由于特征提取较差,检索性能较低。参考文献[28]结合低层特征和高层语义信息学习特征表示。虽然解决了特征表示的问题,但由于缺乏特征交互,对于复杂环境的检索精度仍有待提高。参考文献[22]使用DNDCMH方法完成跨模态检索。但是,这种方法通用性差,检索性能不如提出的方法。
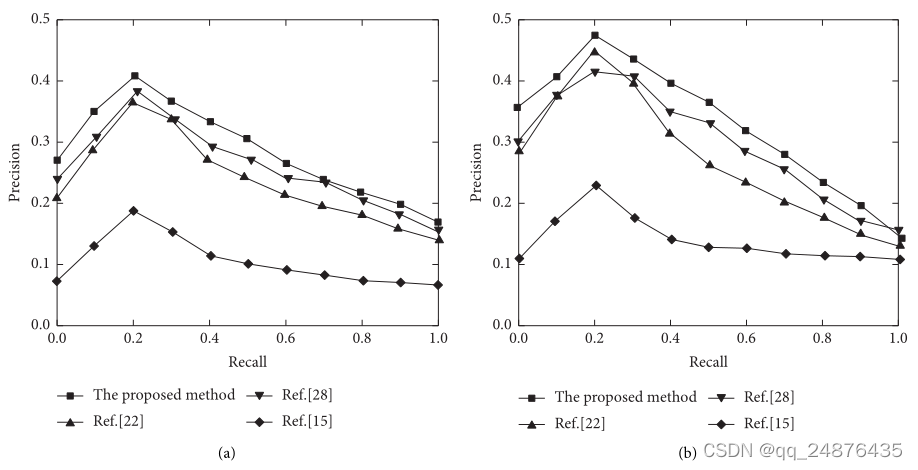
图7:MSC oco数据集上的PR曲线。(a)用图像检索文本。(b)用文本检索图像。
从图7可以看出,在图像检索文本和文本检索图像两个检索任务中,所提出的方法的检索性能都优于其他比较方法。当召回率为0.2时,每种方法的准确率达到最大,召回率不断增加和减少。由于MSCOCO数据集的样本相对较少,因此与Flickr30K数据集相比,由不同方法的PR曲线组成的区域有所增加。
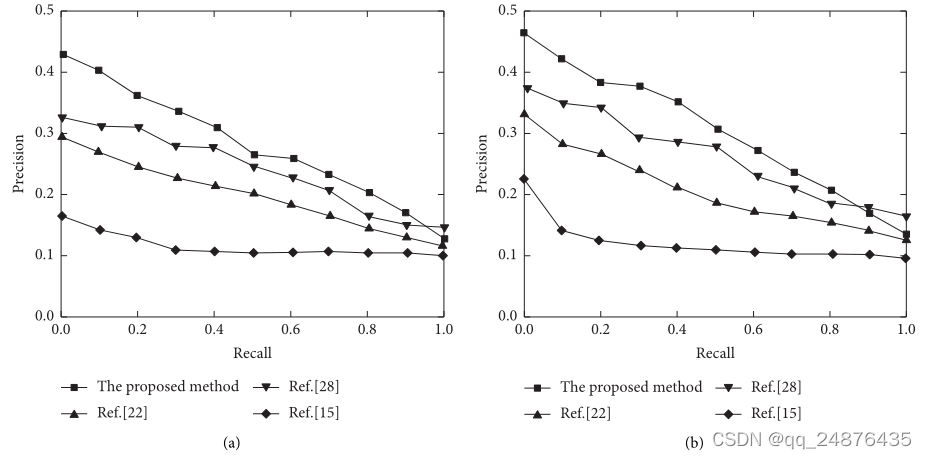
图Pascal VOC 2007数据集上的PR曲线。(a)用图像检索文本。(b)用文本检索图像。
从图8可以看出,与前两个数据集一样,所提出的方法在Pascal VOC 2007数据集上的检索性能优于其他比较方法。提出的方法利用残差网络提取图像特征,并引入2DPCA构造新的卷积核。同时,使用word2vec和LSTM网络用于文本特征提取,特征提取效率更高。它比[15]使用现有的标签信息和[22]使用特定的图像要好。此外,[28]使用语义CAE方法来学习多模态映射,并将多模态数据投影到低维空间中,以保留特征和语义信息,并提高检索准确性。但提出的方法使用了具有交互学习的CAE模型,图像和文本特征学习的融合效果更好,因此检索性能更理想。
总之,从不同数据集上的PR曲线可以看出,所提出的方法在不同的召回率下表现出最好的结果。证明了它所构建的深度互动学习方法是有效的。
6. Conclusion
跨模态检索技术满足了人们更加多样化的检索需求,解决了不同模态数据之间的异构鸿沟和语义鸿沟问题。但是,检索精度仍有待提高。为此,提出了一种结合高效特征提取和交互式学习CAE的跨模态图像检索方法。㼿e残差网络卷积通过引入2DPCA改进核函数提取图像特征,通过LSTM和词向量提取文本特征,得到图像和文本特征。之后将这两个特征输入到交互学习的跨模态CAE中,通过中间层的交互学习,实现图文检索。此外,基于Flickr30K、MSCOCO和Pascal VOC 2007数据集对提出的方法进行了实验验证。㼿e实验结果表明,该方法能够完成准确的图像检索和文本检索。而且在两个检索任务上的平均MAP分别为0.359、0.334、0.309,高于其他比较方法。㼿e对于由PR曲线形成的区域也是如此。
目前,本文提出的方法仅适用于文本和图像之间的跨模态检索,但网络上存在多种类型的多模态数据。接下来,还将扩充更多音频、视频等不同媒体类型的数据,满足人们更广泛的检索需求。

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









