









前言
大家好,我是林哥!
在上一篇,HDFS 底层交换原理,看这篇就够了!文章中,已经聊了 HDFS 高可用架构、HDFS 源码级读写流程及可用性问题。今天接着上篇,继续跟大家聊聊 HDFS 读写失败场景下的容错机制和 HDFS 调优的一些技巧,希望给大家带来一点点启发!本篇文章概览如下:

1.HDFS 读写异常的容错机制
Hadoop 的设计理念就是部署在廉价的机器上,因此在容错方面做了周全的考虑,主要故障包括 DataNode 宕机,网络故障和数据损坏。本文介绍的容错机制只考虑 HDFS 读写异常场景。
1.1 读数据异常场景处理
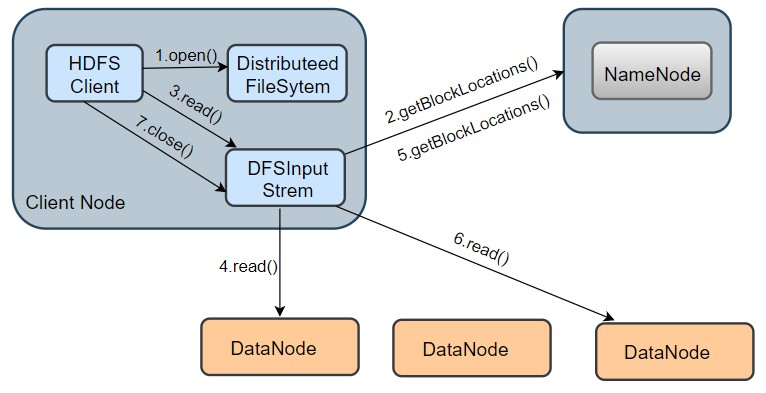
我们通过上图,简单回顾下 HDFS 的读数据流程,先打开文件,再调用read()方法读取数据。
在read()方法中,会调readWithStrategy()方法读取DataNode存储的数据。
-
readWithStrategy( )方法

readWithStrategy()方法中使用 pos 控制数据的读取位置。
-
首先,调用 blockSeekTo()方法获取一个保存了目标数据块的DataNode -
其次,再调用 readBuffer()方法从获取到的DataNode中读取数据
从 readWithStrategy()方法实现可知,读失败场景比较简单。从上述代码 48 - 59 行可知,如果发生异常:
-
先把当前的异常节点放入 HashMap中,然后DFSIputStream会尝试重新去连接列表里的下一个DataNode,默认重试 2 次。 -
同时, DFSInputStream还会对获取到的数据进行checkSums核查,如果与存储在NameNode的校验和不一致,说明数据块损坏,DFSInputStream就会试图从另一个拥有备份的DataNode中去读取数据。 -
最后, NameNode会去同步异常数据块。
1.2 写数据异常场景处理
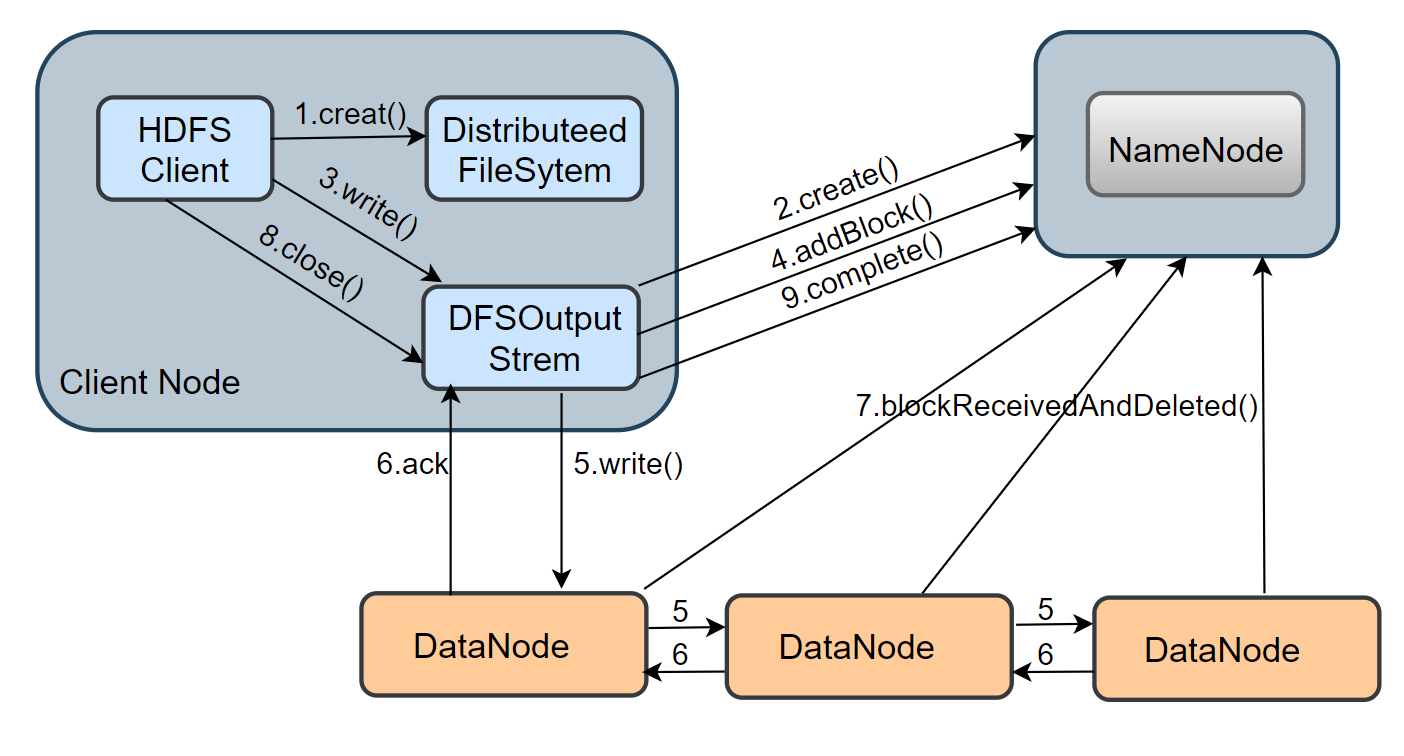
通过上图,简单回顾下写数据流程,客户端调用creat()方法,通过 RPC 与 NameNode 通信,请求创建一个文件,之后调用write,向数据流管道(Pipeline)写入数据。
写数据过程中以数据包(Packet)为单位,进行一个一个传输,数据包发送流程如下图:
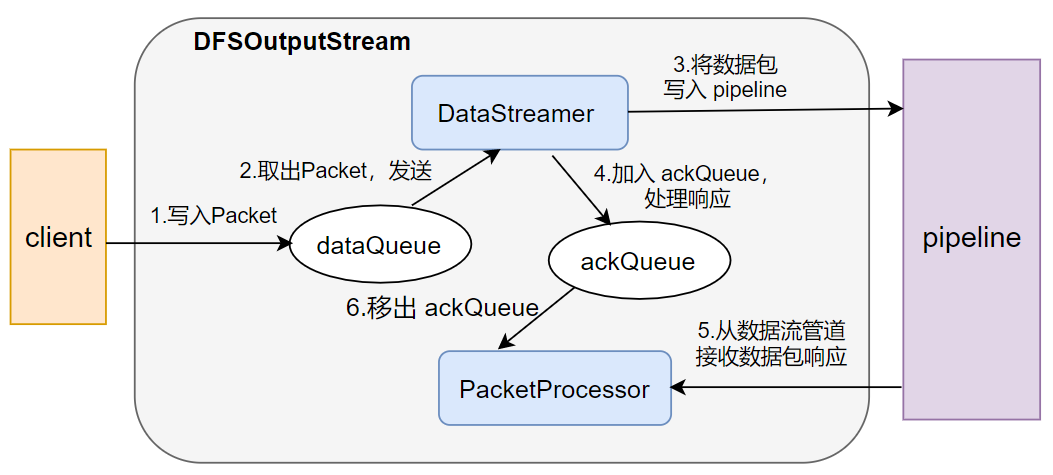
当构建完 DFSOutputStream 输出流时,客户端调用write()方法把数据包写入 dataQueue 队列,在将数据包发送到 DataNode 之前,DataStreamer会向 NameNode 申请分配一个新的数据块
然后,建立写这个数据块的数据流管道(pipeline),之后DataStreamer 会从 dataQueue 队列取出数据包,通过 pipeline 依次发送给各个 DataNode。
每个数据包(packet)都有对应的序列号,当一个数据块中所有的数据包都发送完毕,并且都得到了 ack 消息确认后,PacketProcessor 会将该数据包移出 ackQueue,之后,Datastreamer会将当前数据块的 pipeline 关闭。
通过不断循环上述过程,直到该文件(一个文件会被切分为多个Block)的所有数据块都写完成。 在数据块发送过程中,如果某台DataNode宕机,HDFS主要会做一下容错:
-
首先 pipiline被关闭,ackQueue队列中等待确认的packet会被放入数据队列的起始位置不再发送,以防止在宕机的节点的下游节点再丢失数据。 -
然后,存储在正常的 DataNode上的 Block 块会被指定一个新的标识,并将该标识传递给NameNode,以便故障DataNode在恢复后,就可以删除自己存储的那部分已经失效的数据块。 -
宕机节点会从数据流管道移除,剩下的 2 个好的 DataNode会组成一个新的Pipeline,剩下的Block的数据包会继续写入新的pipeline中。 -
最后,在写流程结束后, NameNode发现节点宕机,导致部分Block块的备份数小于规定的备份数,此时NameNode会安排节点的备份数满足dfs.replication的配置要求。
以上过程,针对客户端是透明的。
2. HDFS 调优技巧
2.1 HDFS 小文件优化方法
HDFS 集群中 NameNode 负责存储数据块的元数据,其中包括文件名、副本数、文件的BlockId、以及Block 所在的服务器等信息,这个元数据的大小大约为 150 byte。
对于元数据来说,不管实际文件是大还是小,其大小始终在 150 byte 左右。如果 HDFS 存储了大量的小文件,会产生很多的元数据文件,这样便会导致NameNode内存消耗过大;此外,元数据文件过多,使得寻址时间大于数据读写时间,这样显得很低效。
-
数据源头解决:依赖于 HDFS存储的数据写入前,通过 SequenceFile 将小文件或小批数据合成大文件再上传到HDFS上。 -
事后解决:使用 Hadoop Archive归档命令,将已经存储在HDFS上的多个小文件打包成一个 HAR 文件,即将小文件合并成大文件。
2.2 存储优化
纠删码存储
Hadoop 3.X 之前,数据默认以 3 副本机制存储,这样虽然提高了数据的可靠性,但所带来的是 200% 的存储开销。对于 I/O 频率较低的冷热数据集,在正常操作期间很少访问额外的块副本,但仍然消耗与第一个副本相同的资源量。
因此,一个自然的改进就是使用纠删码代替复制,它保证了相同级别的数据可靠性,存储空间却更少。它是将一个文件拆分成一些数据单元和一些校验单元。具体数据单元与校验单元的配比是根据纠删码策略确定的。
-
RS-3-2-1024K : 使用 RS 编码,每 3 个数据单元,生成 2 个校验单元,共 5 个单元,也就是说,这 5 个单元中,只要有任意的 3 个单元存在(无论是数据单元还是校验单元),就可以通过计算得到原始数据。每个单元的大小是 1024k。
此外,还有RS-10-4-1024k、RS-6-3-1024k、RS-LEGACY-6-3-1024k、XOR-2-1-1024k 这四种策略。所有的纠删码策略,只能在目录上设置。
默认情况下,所有内建的 EC 策略是不可用的,可以以下通过两种方式开启对纠删码策略的支持除:
-
通过以下配置项,指定想要使用的 EC 策略。

-
开发人员还可以基于集群规模和期望的容错性,使用命令行的方式:
hdfs ec -enablePolicy -policy [policyName],在集群上开启对某种纠删码策略的支持,policyName为纠删码策略名。之后,开发人员便可以通过
hdfs ec -setPolicy -path [directoryName] -policy [policyName]命令,实现对某个文件目录指定使用上述开启的 EC 策略了。如果缺少[policyName]这个参数,集群会使用系统的默认值:RS-6-3-1024k。
异构存储
异构存储是另外一种存储优化,主要解决不同的数据,存储在不同类型的硬盘中,以获取最佳性能。
-
存储类型:
RAM_DISK:存储在内存镜像文件系统;
SSD:SSD 固态硬盘
DISK:普通磁盘存储,在
HDFS中,如果没有主动声明数据目录存储类型,默认都是 DISKARCHIVE: 这个没有特指哪种存储介质,主要指的是计算能力比较弱而存储密度比较高的存储介质,用来解决数据量的容量扩增的问题,一般用于归档
-
存储策略:
Lazy_Persist:策略 ID 为15,它只有一个副本保存在内存中,其余副本都保存在磁盘中。
ALL_SSD:策略 ID 为12,其所有副本数都存在固态硬盘中。
One_SSD:策略 ID 为10,它有一个副本保存在固态,其余副本都保存在磁盘中
HOT(default):策略 ID 为7,所有副本都保存在磁盘中,这是默认的存储策略。
Warm:策略 ID 为5,一个副本在磁盘,其余副本都保存在归档存储上。
Cold:策略 ID 为2,所有副本都保存在归档存储上。
2.3 HDFS 调优参数
-
NameNode内存生产配置HADOOP_NAMENODE_OPTS=-Xmx102400m,Hadoop 3.x 中,其内存是动态分配的。cloudera 给出的经验值:
NameNode最小值 1G,每增加 100 万个block增加 1G 值;DataNode最小值 4G,一个DataNode上的副本总数低于 400 万,调为 4G,超 400 万,每增加 100 万,增加 1G。 -
NameNode同时与DataNode通信的线程数,即心跳并发配置(hdfs-site.xml)
企业经验:
dfs.namenode.handler.count=20 ×𝑙𝑜𝑔 𝑒^𝐶𝑙𝑢𝑠𝑡𝑒𝑟 𝑆𝑖𝑧𝑒,比如集群规模(DataNode 台 数)为 3 台时,此参数设置为 21 -
DataNode进行文件传输时最大线程数(hdfs-site.xml)
-
DataNode的最大连接数
对于 DataNode 来说,如同 Linux 上的文件句柄的限制,当 DataNode上面的连接数超过配置中的设置时, DataNode就会拒绝连接,可以将其修改设置为65536。
-
Hadoop 的缓冲区大小(core-site.xml)

-
开启回收站工作机制(core-sit.xml)
开启回收站功能,可以将删除的文件在不超时的情况下恢复,起到防止误操作。

注意:
-
如果是在网页删除的文件,不会进入回收站 -
要求: fs.trash.checkpoint.interval<=fs.trash.interval
-
3. 高频面试题
-
客户端在写 DataNode的过程中,DataNode宕机是否对写有影响? -
是否要完成所有目标 DataNode节点的写入,才算一次写成功操作? -
读的过程如何保证数据没有被损坏,如果损坏如何处理? -
交互过程数据校验的基本单位是什么? -
数据写入各个 DataNode时如何保证数据一致性? -
短路读机制 -
短路读机制是如何保证文件的安全性的?
参考资料
[1]https://hadoop.apache.org/docs/r3.1.1/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html
















 2317
2317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









