









前言
想要搞明白Java对象内存申请过程的原因,是因为第一次接触线上GC日志的时候,发现了一些很奇怪的现象,就是young gc触发了full gc。为了搞清楚这个现象,得先要来个测试去复现。
复现现象
我所使用的实验代码和配置原本是用来测试空间担保机制的,不过我们重点不是这个机制而是fullgc的问题:
-Xmx20m
-Xms20m
-Xmn10m
-XX:+PrintGCTimeStamps
-Xloggc:D:/gc.log
-XX:+PrintGCDetails
-XX:SurvivorRatio=8public static void main(String[] args) throws Exception{
Thread.sleep(15000);
byte[] a1,a2,a3,a4;
a1 = new byte[2*1024*1024];
a2 = new byte[2*1024*1024];
a3 = new byte[2*1024*1024];
a4 = new byte[3*1024*1024];
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}注意了,观察gc的命令在jdk1.7的时候一定要带上-gccause参数,才能更加清晰,采集的时间间隔要尽可能的短,我这里用的是5ms。我之前在做实验的时候因为不知道这两个技巧,搞了很久。
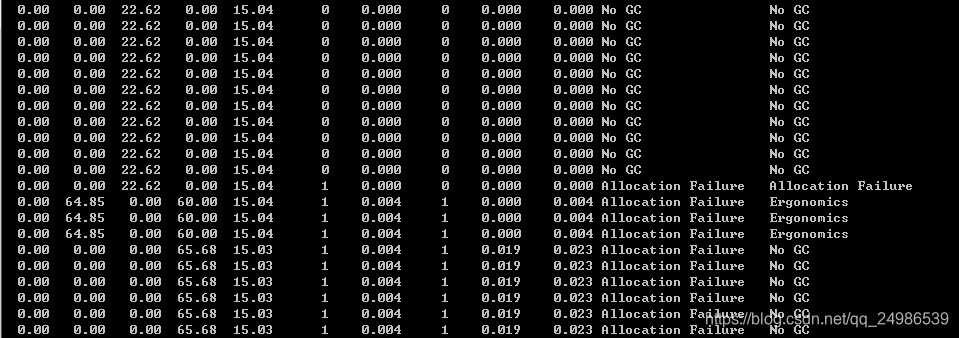
观察这个图片,看到第一次触发young gc是因为eden无法分配导致的,原因旁边写的很明白了。第二次fullgc的原因也有写,但是我当时并不知道,我当时用的只是-gcutil而已。到这里如果迫不及待想知道为什么,可以直接去看:读懂一行Full GC日志(回复JVM内存分配担保机制一文中 Mr/Mrs Xxx 在留言区提出的问题)。
Java HotSpot(TM) 64-Bit Server VM (24.79-b02) for windows-amd64 JRE (1.7.0_79-b15), built on Apr 10 2015 12:36:16 by "java_re" with unknown MS VC++:1600
Memory: 4k page, physical 8309608k(1597972k free), swap 27075900k(16055712k free)
CommandLine flags: -XX:InitialHeapSize=20971520 -XX:MaxHeapSize=20971520 -XX:MaxNewSize=10485760 -XX:NewSize=10485760 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:SurvivorRatio=8 -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
15.115: [GC [PSYoungGen: 7996K->664K(9216K)] 7996K->6808K(19456K), 0.0044966 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
15.120: [Full GC [PSYoungGen: 664K->0K(9216K)] [ParOldGen: 6144K->6725K(10240K)] 6808K->6725K(19456K) [PSPermGen: 3233K->3232K(21504K)], 0.0189363 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
Heap
PSYoungGen total 9216K, used 3237K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
eden space 8192K, 39% used [0x00000000ff600000,0x00000000ff9296e8,0x00000000ffe00000)
from space 1024K, 0% used [0x00000000ffe00000,0x00000000ffe00000,0x00000000fff00000)
to space 1024K, 0% used [0x00000000fff00000,0x00000000fff00000,0x0000000100000000)
ParOldGen total 10240K, used 6725K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
object space 10240K, 65% used [0x00000000fec00000,0x00000000ff291790,0x00000000ff600000)
PSPermGen total 21504K, used 3239K [0x00000000f9a00000, 0x00000000faf00000, 0x00000000fec00000)
object space 21504K, 15% used [0x00000000f9a00000,0x00000000f9d29f18,0x00000000faf00000)
从gc日志的时间就可以看到是直接触发的FGC。而且我们也发现了这个原因很重要,没有这个原因就没办法针对的去查询资料,所以如果gc日志里面可以打印出来这个原因的话,排查就很方便了。现在现象也说了,资料地址也给了,剩下的就是只是动手看一遍源码,按照自己的方式整理一遍。
ParallelScavenge回收器中GC任务的前后两个Check
我用的是openjdk7,电脑上面调试用的是openjdk10。
首先来看第一次check:
//hotspot\src\share\vm\gc_implementation\parallelScavenge\psScavenge.cpp
void PSScavenge::invoke() {
ParallelScavengeHeap* heap = (ParallelScavengeHeap*)Universe::heap();
PSAdaptiveSizePolicy* policy = heap->size_policy();
IsGCActiveMark mark;
bool scavenge_was_done = PSScavenge::invoke_no_policy();
//...
}
bool PSScavenge::invoke_no_policy() {
//...
scavenge_entry.update();
if (GC_locker::check_active_before_gc()) {
return false;
}
//获取堆
ParallelScavengeHeap* heap = (ParallelScavengeHeap*)Universe::heap();
//从堆中获取gc的原因
GCCause::Cause gc_cause = heap->gc_cause();
assert(heap->kind() == CollectedHeap::ParallelScavengeHeap, "Sanity");
// Check for potential problems.
//在youngc之前进行检查,看看是否要直接触发fullgc
if (!should_attempt_scavenge()) {
return false;
}
//...
}上面只是说明了should_attempt_scavenge这个在前面判断的,还未到正题:
//hotspot\src\share\vm\gc_implementation\parallelScavenge\psScavenge.cpp
//是否要尝试回收,当返回false-触发fullgc
bool PSScavenge::should_attempt_scavenge() {
ParallelScavengeHeap* heap = (ParallelScavengeHeap*)Universe::heap();
PSGCAdaptivePolicyCounters* counters = heap->gc_policy_counters();
PSYoungGen* young_gen = heap->young_gen();
PSOldGen* old_gen = heap->old_gen();
if (!ScavengeWithObjectsInToSpace) {
// Do not attempt to promote unless to_space is empty
//若toSpace不为空则直接返回false,触发fullgc
if (!young_gen->to_space()->is_empty()) {
//...
return false;
}
}
// Test to see if the scavenge will likely fail.
PSAdaptiveSizePolicy* policy = heap->size_policy();
// A similar test is done in the policy's should_full_GC(). If this is
// changed, decide if that test should also be changed.
size_t avg_promoted = (size_t) policy->padded_average_promoted_in_bytes();
//取最小值(之前YGC晋升到old的平均大小,新生代已使用大小)
size_t promotion_estimate = MIN2(avg_promoted, young_gen->used_in_bytes());
//若小于old的空闲空间,则表示无需fullgc
bool result = promotion_estimate < old_gen->free_in_bytes();
if (PrintGCDetails && Verbose) {
//...
}
//...
return result;
}注释写的很清楚了,就是一个预测判断操作,第二个check是在gc任务的最后面:
//看注释,好像是说,所有堆的回收策略都在这里。然后重点说了invoke_no_policy
//方法:它只会做一件事,就是尝试回收
void PSScavenge::invoke() {
ParallelScavengeHeap* heap = (ParallelScavengeHeap*)Universe::heap();
PSAdaptiveSizePolicy* policy = heap->size_policy();
IsGCActiveMark mark;
bool scavenge_was_done = PSScavenge::invoke_no_policy();
PSGCAdaptivePolicyCounters* counters = heap->gc_policy_counters();
//...
if (!scavenge_was_done ||
//是否要fullgc
policy->should_full_GC(heap->old_gen()->free_in_bytes())) {
//gc的原因是_adaptive_size_policy,也就是说是jvm自动判断引起的fullgc
GCCauseSetter gccs(heap, GCCause::_adaptive_size_policy);
CollectorPolicy* cp = heap->collector_policy();
//清理软引用,默认情况是不清理
const bool clear_all_softrefs = cp->should_clear_all_soft_refs();
//开始fullgc,默认是标记压缩算法
if (UseParallelOldGC) {
PSParallelCompact::invoke_no_policy(clear_all_softrefs);
} else {
PSMarkSweep::invoke_no_policy(clear_all_softrefs);
}
}
}实现的方式和第一次check有点类似:
//hotspot\src\share\vm\gc_implementation\parallelScavenge\psAdaptiveSizePolicy.cpp
// If the remaining free space in the old generation is less that
// that expected to be needed by the next collection, do a full
// collection now.
//如果old的闲置空间小于下次预期晋升的空间,就要做一次fullgc
bool PSAdaptiveSizePolicy::should_full_GC(size_t old_free_in_bytes) {
// A similar test is done in the scavenge's should_attempt_scavenge(). If
// this is changed, decide if that test should also be changed.
//和should_attempt_scavenge()类似,都是计算一个历代平均值是否大于当前old的free空间
bool result = padded_average_promoted_in_bytes() > (float) old_free_in_bytes;
//...
return result;
}看完这个就基本上明白了,为什么会出现连续gc,一次YGC,一次FGC的情况,为了证明这个现象,当然也有对应的测试代码,不过这个代码不是我想出来的,具体地址给忘了,具体配置和代码如下:
-Xmx30m
-Xms30m
-Xmn10m
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-Xloggc:D:/gc.log
-XX:SurvivorRatio=8import java.util.ArrayList;
import java.util.List;
public class YGCBeforeOrAfterCheckToFullGC {
public static void main(String[] args) throws Exception{
Thread.sleep(15000);
List<byte[]> list = new ArrayList<>();
for(int i=0; i<7; i++){
//每次分配3MB,是的eden在第三次的时候触发ygc
//这个时候会将eden数据全部放到老年代中,晋升6MB
//到第5,7次的时候,分别再次触发ygc,一共晋升到old18MB,平均每次6MB
list.add(new byte[3*1024*1024]);
Thread.sleep(500);
}
Thread.sleep(1000);
//注意第7次ygc,可以看到old已经到了18MB,所以触发fullgc势在必行
//但是本次清理,并没有清理掉任何东西
list.clear();
//这个时候eden里面还有3MB,我们再来分配两次3MB,让其准备触发YGC
for(int i=0; i<2; i++){
list.add(new byte[3*1024*1024]);
}
//但是在YGC之前,先对比是否要直接fullgc,min(6MB,6MB)>old的2MB
//所以触发了一次fullgc,这次fullgc将old清空,然后将eden中的3MB移动到old中
}
}代码上面有注释,这个我是根据之前代码分析得来的。我们来看看具体的现象:
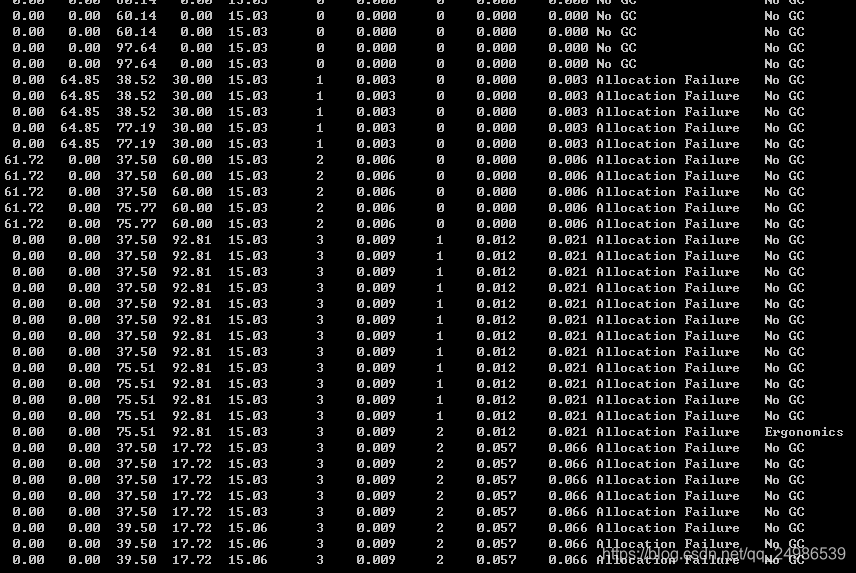
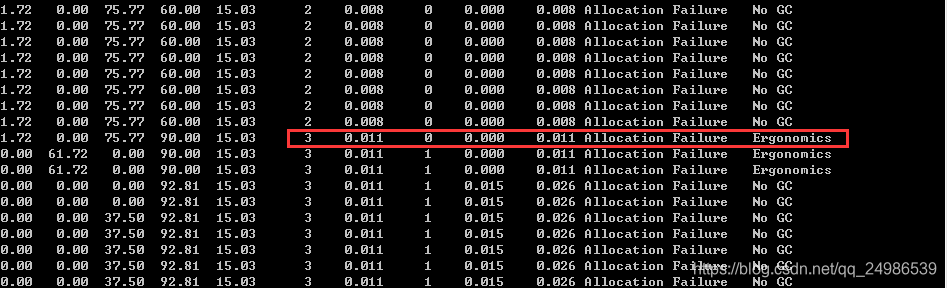
根据之前的理论分析,一共2次fullgc,3次ygc,完全吻合。为了更为细致的观察:
gc日志:
6.135: [GC [PSYoungGen: 7998K->664K(9216K)] 7998K->6808K(29696K), 0.0034513 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
17.139: [GC [PSYoungGen: 6987K->616K(9216K)] 13131K->12904K(29696K), 0.0022924 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
18.141: [GC [PSYoungGen: 6822K->632K(9216K)] 19110K->19064K(29696K), 0.0031362 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
18.144: [Full GC [PSYoungGen: 632K->0K(9216K)] [ParOldGen: 18432K->19006K(20480K)] 19064K->19006K(29696K) [PSPermGen: 3232K->3231K(21504K)], 0.0169288 secs] [Times: user=0.01 sys=0.00, real=0.02 secs]
20.663: [Full GC [PSYoungGen: 6185K->0K(9216K)] [ParOldGen: 19006K->3628K(20480K)] 25191K->3628K(29696K) [PSPermGen: 3231K->3231K(21504K)], 0.0431159 secs] [Times: user=0.03 sys=0.00, real=0.04 secs]
Heap
PSYoungGen total 9216K, used 3235K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
eden space 8192K, 39% used [0x00000000ff600000,0x00000000ff928fd0,0x00000000ffe00000)
from space 1024K, 0% used [0x00000000ffe00000,0x00000000ffe00000,0x00000000fff00000)
to space 1024K, 0% used [0x00000000fff00000,0x00000000fff00000,0x0000000100000000)
ParOldGen total 20480K, used 3628K [0x00000000fe200000, 0x00000000ff600000, 0x00000000ff600000)
object space 20480K, 17% used [0x00000000fe200000,0x00000000fe58b390,0x00000000ff600000)
PSPermGen total 21504K, used 3238K [0x00000000f9000000, 0x00000000fa500000, 0x00000000fe200000)
object space 21504K, 15% used [0x00000000f9000000,0x00000000f9329888,0x00000000fa500000)
Java对象的内存申请流程
到这里是不是开始对gc以及内存分配开始产生兴趣了?赶紧去下载一个源码一起看。别看这个标题好像很厉害,其实前人都已经研究过了,这里先贴地址,我看的几篇都是占小狼博客,这里面我感觉讲的很详细了:
这里不涉及gc的细节,只是大致说一下分配过程,最好可以自己看代码过一遍,看别人写远不如自己也看一遍来的印象深刻,即便是跟着别人的博客看。
现在我们以new指令为例,这个反编译class文件就可以看到。
第一步,解析new指令。解释器解析到new指令的时候,会去调用:
//hotspot\src\share\vm\interpreter\interpreterRuntime.cpp
IRT_ENTRY(void, InterpreterRuntime::_new(JavaThread* thread, constantPoolOopDesc* pool, int index))
klassOop k_oop = pool->klass_at(index, CHECK);
instanceKlassHandle klass (THREAD, k_oop);
// Make sure we are not instantiating an abstract klass
//不能是抽象类
klass->check_valid_for_instantiation(true, CHECK);
// Make sure klass is initialized
//class必须是已经初始化的
klass->initialize(CHECK);
//内存分配开始
oop obj = klass->allocate_instance(CHECK);
thread->set_vm_result(obj);
IRT_END看到上面的那个pool,那是一个常量池,根据代码推测可以知道这是去池子里面去拿class对象去了。这个时候就可以去查阅一下深入JVM那本书了,简单理解就是,每个class都有一个类常量池,一开始这个池子里面只是一个符号而已,也就是符号引用,我们要将其解析为直接引用,这样第二次获取就不用解析了。当JVM发现这只是个符号,就把这个全限定名丢给当前类的加载器去加载,然后返回直接引用。再就是看看是不是抽象类,有没有初始化好?这些准备工作做好后,然后就是申请空间,初始化对象。
第二步,调用class对象的内存分配方法进行内存分配和初始化,这里暂时不理解InstanceKlass和其他一些类的关系,暂时这么说。
//hotspot\src\share\vm\oops\instanceKlass.cpp
instanceOop InstanceKlass::allocate_instance(TRAPS) {
//是否自定义了finalize
bool has_finalizer_flag = has_finalizer(); // Query before possible GC
//计算要分配的空间
int size = size_helper(); // Query before forming handle.
instanceOop i;
//从堆中申请内存空间,并创建对象
i = (instanceOop)CollectedHeap::obj_allocate(this, size, CHECK_NULL);
//和自定义finalize相关的操作
if (has_finalizer_flag && !RegisterFinalizersAtInit) {
i = register_finalizer(i, CHECK_NULL);
}
return i;
}跟着跑去堆里面调用分配对象方法,到这里为止其实都没有什么看头:
//hotspot\src\share\vm\gc_interface\collectedHeap.inline.hpp
oop CollectedHeap::obj_allocate(KlassHandle klass, int size, TRAPS) {
debug_only(check_for_valid_allocation_state());
assert(!Universe::heap()->is_gc_active(), "Allocation during gc not allowed");
assert(size >= 0, "int won't convert to size_t");
//分配
HeapWord* obj = common_mem_allocate_init(size, false, CHECK_NULL);
//初始化
post_allocation_setup_obj(klass, obj, size);
NOT_PRODUCT(Universe::heap()->check_for_bad_heap_word_value(obj, size));
return (oop)obj;
}继续跟进,看到下面有个填0处理,根据网上博客来看,是说用于初始化实例数据的,这样代码里面就不用特别赋值了,直接就是0:
//hotspot\src\share\vm\gc_interface\collectedHeap.inline.hpp
HeapWord* CollectedHeap::common_mem_allocate_init(size_t size, bool is_noref, TRAPS) {
//分配
HeapWord* obj = common_mem_allocate_noinit(size, is_noref, CHECK_NULL);
//Copy::fill_to_aligned_words(obj + hs, size - hs);
//对非对象头的部分做填0处理
init_obj(obj, size);
return obj;
}第三步,尝试在TLAB上分配,TLAB也是从堆上申请的空间,只不过分配权只属于申请TLAB的线程:
//hotspot\src\share\vm\gc_interface\collectedHeap.inline.hpp
if (UseTLAB) {
result = allocate_from_tlab(klass, THREAD, size);
if (result != NULL) {
assert(!HAS_PENDING_EXCEPTION,
"Unexpected exception, will result in uninitialized storage");
return result;
}
}在TLAB上分配有两个路径,第一种是快速分配,因为TLAB的空间有三个指针组成,start,top,end。start和end标识TLAB范围,top表示可分配的起始位置,所以直接对指针进行计算就行了,也就是前面博客里面说的指针碰撞,对于无空间碎片(规整)的分配形式,可以用指针碰撞来形容;而不规则有空间碎片的,可以用内存列表来形容分配方式。
HeapWord* CollectedHeap::allocate_from_tlab(Thread* thread, size_t size) {
assert(UseTLAB, "should use UseTLAB");
HeapWord* obj = thread->tlab().allocate(size);
if (obj != NULL) {
return obj;
}
// Otherwise...
return allocate_from_tlab_slow(thread, size);
}HeapWord* obj = top();
if (pointer_delta(end(), obj) >= size) {
//填充数据,让堆误以为是连续的
size_t hdr_size = oopDesc::header_size();
Copy::fill_to_words(obj + hdr_size, size - hdr_size, badHeapWordVal);
set_top(obj + size);
//...
return obj;
}
return NULL;快速分配不行,那就只能慢速分配了:
1. 是否超过TLAB本身允许的浪费阈值?超过就会直接返回进行下一步,返回之前会对这个阈值进行增大。
// Retain tlab and allocate object in shared space if
// the amount free in the tlab is too large to discard.
// tlab的剩余空间是否超过了最大浪费的阈值,就直接返回,不再tlab中分配,直接到eden中分配
// 并且记录下,慢分配到大小
if (thread->tlab().free() > thread->tlab().refill_waste_limit()) {
//这里set_refill_waste_limit(refill_waste_limit() + refill_waste_limit_increment());
//这里阈值时可以增长的,每次都会自增TLABWasteIncrement大小,看debug,应该是默认时4
thread->tlab().record_slow_allocation(size);
return NULL;
}2. 若在允许的范围之内,那么就会去申请一块新的TLAB进行存放
//计算所需空间
size_t new_tlab_size = thread->tlab().compute_size(size);
if (new_tlab_size == 0) {
return NULL;
}
// 从堆中分配新的TLAB
HeapWord* obj = Universe::heap()->allocate_new_tlab(new_tlab_size);
if (obj == NULL) {
return NULL;
}
//统计refill的次数;初始化重新申请到的内存块;旧的TLAB末尾浪费的部分填充数据
//让堆误以为是连续的
thread->tlab().fill(obj, obj + size, new_tlab_size);年轻代的申请方式用的是cas,指针碰撞申请空间。
第四步,TLAB不行那就只能去堆上分配。这里有两种分配策略,基础和失败时的分配策略。基础策略就是cas分配方式,失败分配就是要去触发GC,这个时候申请内存的线程是被阻塞的,等待VM线程的GC操作完成。当然在触发GC之前还有一下判断是否要直接放入old中如果本来放不下,而且又大于eden的一半,那就直接进入old里面:
//先尝试分配
HeapWord* result = young_gen()->allocate(size, is_tlab);
while (result == NULL) {
result = young_gen()->allocate(size, is_tlab);
if (result != NULL) {
return result;
}
//看这个是size>=eden/2直接进入old
if (!is_tlab &&
size >= (young_gen()->eden_space()->capacity_in_words(Thread::current()) / 2)) {
//直接在old上分配
result = old_gen()->allocate(size, is_tlab);
if (result != NULL) {
return result;
}
}
//...
//准备YGC
if (result == NULL) {
// Generate a VM operation
VM_ParallelGCFailedAllocation op(size, is_tlab, gc_count);
VMThread::execute(&op); //阻塞等待
// GC操作是否执行成功,因为可能会有多个线程一起执行,导致可能没法拿到锁
if (op.prologue_succeeded()) {
// If GC was locked out during VM operation then retry allocation
// and/or stall as necessary.
// 如果gc在vm操作的时候被锁住,那么会循环重试,因为可能被其他线程触发了
if (op.gc_locked()) {
assert(op.result() == NULL, "must be NULL if gc_locked() is true");
continue; // retry and/or stall as necessary
}
//...
}
}
//...
}第四步,触发Allocation Failed(VM_GenCollectForAllocation)的GC,这个交给VM线程去处理,当前线程就会阻塞等待。后面的就是先check是否要fullgc,如果不需要就触发YGC回收,YGC之后又会有一次判断,是否要进行fullgc。然后循环又重头开始,cas分配,以此类推。至于如何退出循环的,可能是堆溢出异常?或者是超过了分配次数,这块不是很清楚,先不理会。
最后如果还是未能分配成功,那就是返回NULL,结果就是抛出堆溢出的异常。
//无法分配内存
//是否开启-XX:+UseGCOverheadLimit,开启就说明,若回收耗费98%,但是回收内存不到2%则
//自动认为OOM
if (!gc_overhead_limit_was_exceeded) {
//内存溢出,看看是否要dump堆文件
// -XX:+HeapDumpOnOutOfMemoryError and -XX:OnOutOfMemoryError support
report_java_out_of_memory("Java heap space");
if (JvmtiExport::should_post_resource_exhausted()) {
JvmtiExport::post_resource_exhausted(
JVMTI_RESOURCE_EXHAUSTED_OOM_ERROR | JVMTI_RESOURCE_EXHAUSTED_JAVA_HEAP,
"Java heap space");
}
//抛出堆溢出异常
THROW_OOP_0(Universe::out_of_memory_error_java_heap());
} else {
//java.lang.OutOfMemoryError: GC overhead limit exceeded
// -XX:+HeapDumpOnOutOfMemoryError and -XX:OnOutOfMemoryError support
report_java_out_of_memory("GC overhead limit exceeded");
if (JvmtiExport::should_post_resource_exhausted()) {
JvmtiExport::post_resource_exhausted(
JVMTI_RESOURCE_EXHAUSTED_OOM_ERROR | JVMTI_RESOURCE_EXHAUSTED_JAVA_HEAP,
"GC overhead limit exceeded");
}
THROW_OOP_0(Universe::out_of_memory_error_gc_overhead_limit());
}gc任务投递给工作池执行,看到任务名称带有root,应该是根节点搜索吧:
// We'll use the promotion manager again later.
PSPromotionManager* promotion_manager = PSPromotionManager::vm_thread_promotion_manager();
{
// TraceTime("Roots");
ParallelScavengeHeap::ParStrongRootsScope psrs;
GCTaskQueue* q = GCTaskQueue::create();
for(uint i=0; i<ParallelGCThreads; i++) {
q->enqueue(new OldToYoungRootsTask(old_gen, old_top, i));
}
q->enqueue(new SerialOldToYoungRootsTask(perm_gen, perm_top));
q->enqueue(new ScavengeRootsTask(ScavengeRootsTask::universe));
q->enqueue(new ScavengeRootsTask(ScavengeRootsTask::jni_handles));
// We scan the thread roots in parallel
Threads::create_thread_roots_tasks(q);
q->enqueue(new ScavengeRootsTask(ScavengeRootsTask::object_synchronizer));
q->enqueue(new ScavengeRootsTask(ScavengeRootsTask::flat_profiler));
q->enqueue(new ScavengeRootsTask(ScavengeRootsTask::management));
q->enqueue(new ScavengeRootsTask(ScavengeRootsTask::system_dictionary));
q->enqueue(new ScavengeRootsTask(ScavengeRootsTask::jvmti));
q->enqueue(new ScavengeRootsTask(ScavengeRootsTask::code_cache));
ParallelTaskTerminator terminator(
gc_task_manager()->workers(),
(TaskQueueSetSuper*) promotion_manager->stack_array_depth());
if (ParallelGCThreads>1) {
for (uint j=0; j<ParallelGCThreads; j++) {
q->enqueue(new StealTask(&terminator));
}
}
gc_task_manager()->execute_and_wait(q);
}第五步,如果申请成功,那就是初始化对象。。。
小结
总结一下流程:
1. 解析new命令
2. 从类常量池中定位class对象,如果是第一次使用就解析符号引用为直接引用,然后初始化类
3. 进行内存分配,先在TLAB上分配,不行就在堆上分配
4. 先尝试用cas在eden上分配,不行就看看有没有超过eden的一般,有就是在old上分配,这块如果分配不成功也不会有fullgc
5. 都不行,那就触发GC任务,和具体算法有关系。
以默认的ParallelScavenge为例,先check是否要fullgc,min(历代晋升old均值,年轻代总大小)如果大于old剩余空间就触发;
如果不触发那就进行YGC。
(1) YGC会把eden和from中存活对象放到to里面,如果年龄到了(动态年龄计算)就放到old里面,但是如果survivor放不下,那就只能将不能放的部分放到到old里面,如果old也放不下,那就只能fullgc,还是不行就溢出;
(2) 如果YGC可以,那就while循环,如果发现eden还是分配不了,那就再次GC,直到抛出退出循环抛出异常为止。
里面还有空间担保机制等等,具体实现我也没看,只是看到深入JVM里面有说到这个,自个做了实验。
如果有人看到这里,可以发现,上面也有很多模棱两可的表达或者根本没说,这些地方我并没有搞懂:比如说并发触发GC的情况;比如说什么时候退出循环,什么时候被判定为溢出;还有TLAB分配的最大值,如何计算TLAB分配空间;对象如何初始化,对象的布局是什么,通过什么方式访问对象的实例数据等。其实了解这些并不是没有好处,对于底层的理解越深,越可以掌控全局。
所以这篇文章还有另外一个目的,就是一个引子。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









