






@[TOC]kafka使用教程
1 kafka基本概念
1.1什么是kafka
Kafka是一个分布式消息中间件,支持分区的、多副本的、多订阅者的、基于zookeeper(注:kafka3.0版本起不再依赖zookeeper)协调的分布式消息系统。
1.1.1消息队列介绍
消息队列常用于两个系统之间的数据传递;分布式消息传递基于可靠的消息队列,在客户端应用和消息系统之间异步传递消息。有两种主要的消息传递模式:点对点传递模式、发布-订阅模式。
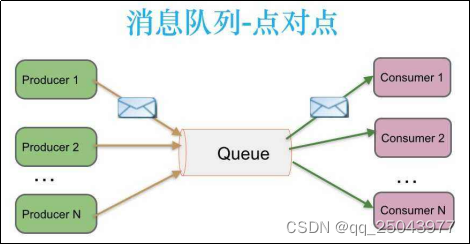
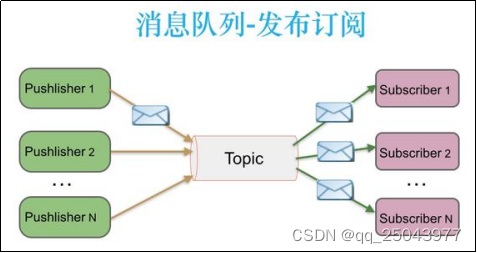
1.1.2为什么使用消息队列
(1)利用消息队列对原系统进行解耦(解耦数据的处理过程);
①提高扩展性:因为消息队列解耦了处理过程,有新增需求时只要另外增加处理过程即可。不需要改变原系统代码;
②提高峰值处理能力:在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见,如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷请求而完全崩溃;
③提高系统的可恢复性:系统的一部分组件时效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统回复后被处理
(2)异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想从队列中放多少消息就放多少,然后在需要的时候再去处理它们。
(3)增加数据冗余和安全性:有些情况下,处理数据的过程会失败,消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。
(4)顺序保证:在大多使用场景下,数据的处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。kafka只能保证一个partition内的消息有序性
(5)缓冲:在任何中重要的系统中,都会有需要不同的处理时间的元素,例如,加载一张图片比应用过滤器花费更少时间。消息队列通过一个缓冲层来帮助任务最高效率的执行-写入队列的处理会尽可能的快速。该缓冲有助于控制和优化数据流经过系统的速度。
(6)用于数据流:在一个分布式系统里,要得到一个关于用户操作会用多长时间及其原因的总体印象,是个巨大的挑战。消息系列通过消息处理的频繁,来方便的辅助确定那些表现不佳的处理过程或领域,这些地方的数据流不够优化。
1.2 kafka的特点
1.高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, 由多个consumer group 对partition进行consume操作。
2.可扩展性:kafka集群支持热扩展
3.持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
4.容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
5.高并发:支持数千个客户端同时读写
1.3 kafka的使用场景
1.日志收集:一个公司可以用kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、HBase、Solr等。
2.消息系统:解耦和生产者和消费者、缓存消息等。
3.用户活动跟踪:kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
4.运营指标:kafka也经常用来记录运维监控数据。包括收集各种分布式应用的数据,各种操作的集中反馈,比如报警和报告。
5.流式数据处理:比如spark streaming和 Flink
2 kafka的系统架构
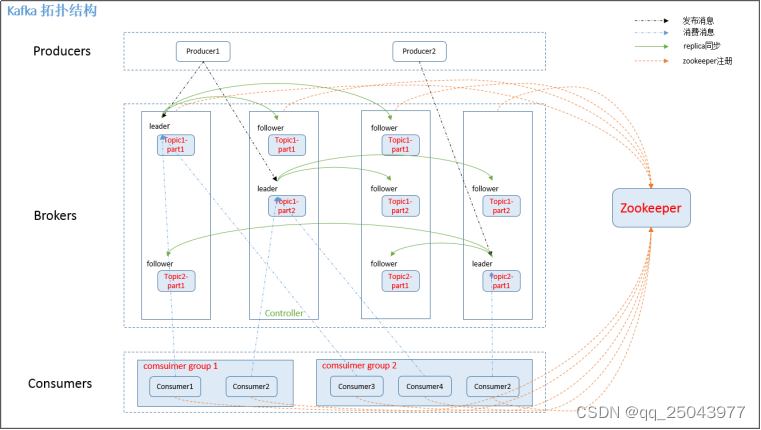
2.1 producer
消息生产者,就是向kafka broker 发消息的客户端。
2.2 consumer
consumer :消息消费者,从kafka broker 取消息的客户端。
consumer group:单个或多个consumer可以组成一个consumer group;这是 kafka 用来实现消息的广播(发给所有的 consumer)和单播(发给任意一个 consumer)的手段。一个 topic 可以有多个Consumer Group。
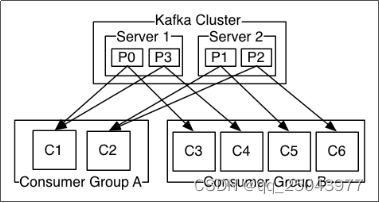
2.3 topic
数据的逻辑分类;
你可以理解为数据库中“表”的概念;
(1)partition
topic中数据的具体管理单元;(可以理解为hbase中表的“region”概念)一个topic 可以划分为多个partition,分布到多个 broker上管理;每个partition由一个kafka broker服务器管理;partition 中的每条消息都会被分配一个递增的id(offset);每个 partition 是一个有序的队列,kafka 只保证按一个partition 中的消息的顺序,不保证一个 topic 的整体(多个 partition 间)的顺序。每个partition都可以有多个副本;
(2)broker
一台 kafka 服务器就是一个 broker。
一个kafka集群由多个 broker 组成。
一个 broker 可以容纳多个 topic的多个partition。
分区对于 kafka 集群的好处是:实现topic数据的负载均衡。分区对于消费者来说,可以提高并发度,提高效率。
(3)offset
消息在底层存储中的索引位置,kafka底层的存储文件就是以文件中第一条消息的offset来命名的,通过offset可以快速定位到消息的具体存储位置;
2.4 Leader
partition replica中的一个角色,producer和consumer只跟leader交互(负责读写)。
2.5 副本Replica
partition的副本,保障partition的高可用(replica副本数目不能大于kafka broker节点的数目,否则报错。每个partition的所有副本中,必包括一个leader副本,其他的就是follower副本
2.6 Follower
partition replica中的一个角色,从leader中拉取复制数据(只负责备份)。
如果leader所在节点宕机,follower中会选举出新的leader;
2.7偏移量Offset
每一条数据都有一个offset,是数据在该partition中的唯一标识(其实就是消息的索引号)。各个consumer会保存其消费到的offset位置,这样下次可以从该offset位置开始继续消费;consumer的消费offset保存在一个专门的topic(__consumer_offsets)中;(0.10.x版本以前是保存在zk中)
2.8 消息Message
在客户端编程代码中,消息的类叫做 ProducerRecord; ConsumerRecord;
简单来说,kafka中的每个massage由一对key-value构成
3kafka的数据存储结构
由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。每个segment对应两个文件:“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称-分区序号。
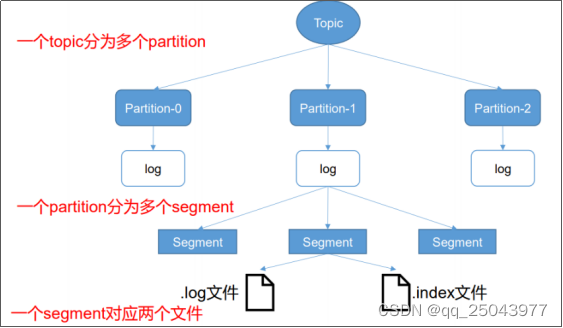
例如,test这个topic有三个分区,则其对应的文件夹为test-0,test-1,test-2。
index和log文件以当前segment的第一条消息的offset命名。

“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中message的物理偏移地址。














 19万+
19万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









