







首先我们要注意的是虚拟空间分为内核空间和用户空间。
IA32下内核空间的地址转换:
1. 从逻辑地址到线性地址的转换
对于Linux来说,基本不使用分段的机制,或者说,Linux中的分段机制只是为了兼容IA32的硬件而设计的。
Linux内核的设计并没有全部采用Intel所提供的段方案,仅仅有限度地使用了一下分段机制。这不仅简化了Linux内核的设计,而且为把Linux移植到其他平台创造了条件。
在 IA32 上任意给出的地址都是一个虚拟地址,即任意一个地址都是通过“选择符:偏移量”的方式给出的,这是段机制存访问模式的基本特点。所以在IA32上设计操作系统时无法回避使用段机制。一个虚拟地址最终会通过“段基地址+偏移量”的方式转化为一个线性地址。 但是,由于绝大多数硬件平台都不支持段机制,只支持分页机制,所以为了让 Linux 具有更好的可移植性,我们需要去掉段机制而只使用分页机制。但不幸的是,IA32规定段机制是不可禁止的,因此不可能绕过它直接给出线性地址空间的地址。万般无奈之下,Linux的设计人员干脆让段的基地址为0,而段的界限为4GB,这时任意给出一个偏移量,则等式为“0+偏移量=线性地址”,也就是说“偏移量==线性地址”。即 逻辑地址==线性地址。
段机制把逻辑地址转换为线性地址,分页机制进一步把该线性地址再转换为物理地址。
2. 从线性地址到物理地址的转换
内核空间下在从线性地址到物理地址的转换过程中是:线性地址 – offset (0x1000)=物理地址
IA32下用户空间的地址转换:
先来普及一些基础知识:
虚拟地址空间是根据CPU的位数而定,当CPU的位数为32位,虚拟地址空间总共是2^32次方,即4G大小。
CPU的位数越大,CPU处理数字的运算能力就越强,位数指的是数据总线的条数,数据总线与地址总线相同是比较好的一种情况
CPU的指令集(mov lea add call )可以使CPU明白自己需要完成的是什么事
在8086处理器诞生之前,内存寻址方式就是直接访问物理地址。8086处理器为了寻址1M的内存空间,把地址总线扩展到了20位。但是,一个尴尬的问题出现了,ALU的宽度只有16位,也就是说,ALU不能计算20位的地址。为了解决这个问题,分段机制被引入。
X86体系:
1. 未保护模式下(8086处理器为代表):
16位的寄存器(存放的是基地址):
CS:代码寄存器 DS:数据段寄存器 SS:堆栈段寄存器
ES:附加段寄存器
在 8086 的实模式(未保护模式)下,把某一段寄存器左移4位,然后与地址ADDR相加后被直接送到内存总线上,这个相加后的地址就是内存单元的物理地址。
未保护模式下,内存地址的分段映射:
DS<<4 + IP(偏移量) = 物理地址(不安全,DS可能被修改)
保护模式的出现:
80386处理器是一个32位处理器,ALU和地址总线都是32位的,寻址空间达 4G。也就是说它可以不通过分段机制,直接访问4G的内存空间。然而由于兼容之前的处理器。因此必须支持实模式和保护模式。所以80386要在段寄存器的基础上构筑保护模式,并且保留16位的段寄存器。
从80386之后的处理器,架构基本相似,统称为IA32(32 Bit Intel Architecture)。
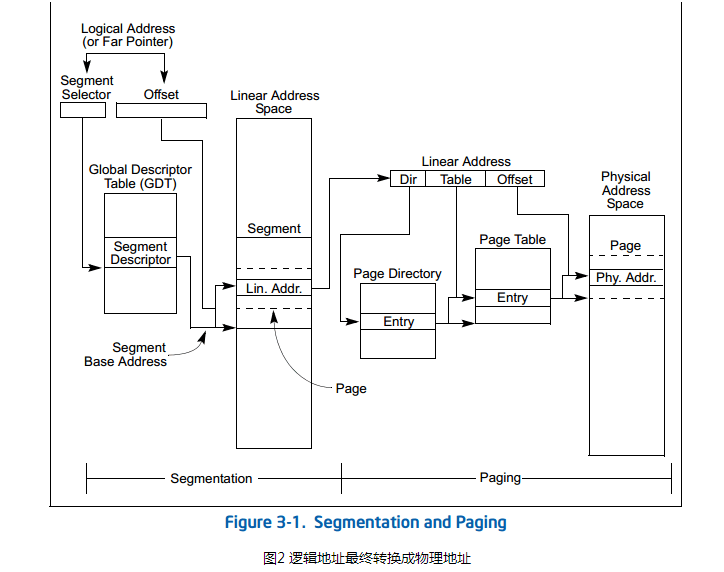
2.保护模式下
在IA32的保护模式下,逻辑地址不是被直接送到内存总线而是被送到内存管理单元(MMU)。MMU由一个或一组芯片组成,其功能是把逻辑地址映射为物理地址,即进行地址转换。
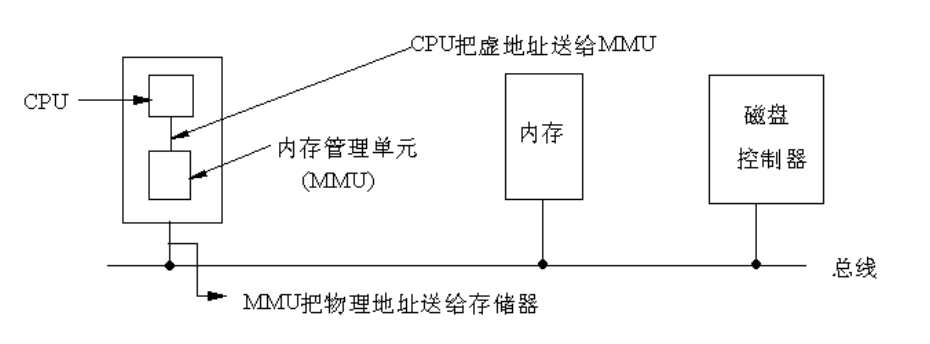
保护模式下三个地址的关系:
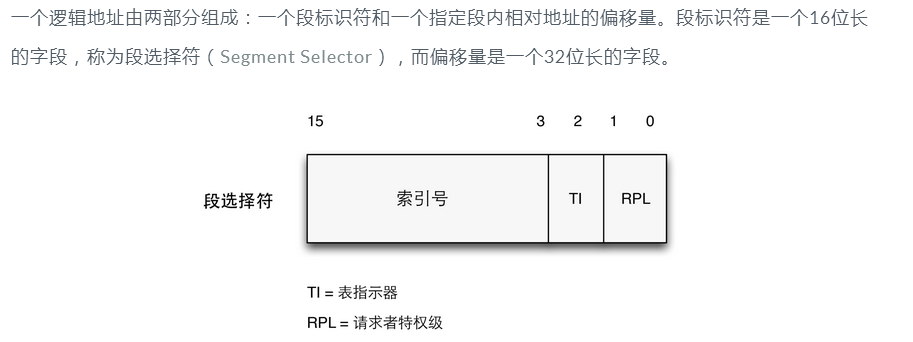
IA32下设置了6个段寄存器,段寄存器中存储的是段选择符:

* 段选择符:*

GDT和LDT
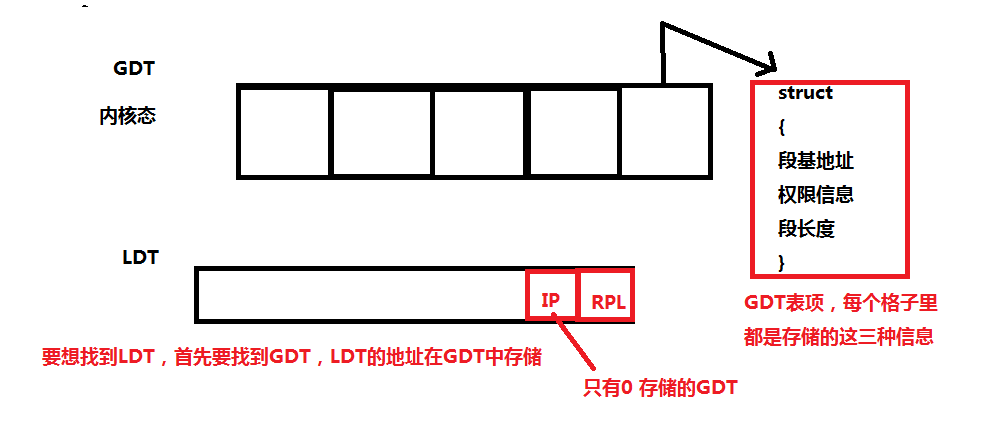
从逻辑地址到线性地址的映射过程:
1)根据指令的性质判断它是在哪个段寄存器中
2)检查段寄存器的TI字段,看其属于LDT还是GDT
3)根据段寄存器的index,将段寄存器中的地址右移3位,计算段描述符的地址
4)在内存管理寄存器LDTR和GDTR中分别找LDT和GDT的地址,每个地址对应一个段寄存器和一个内存管理寄存器
5)将指令发出的地址作为位移,与段描述符表项进行对比,查看是否越界
6)根据指令的性质和段描述符中的权限,查看是否越权
7)将IP偏移量(逻辑地址)与GDT[DS >> 3] 相加可得到线性地址
{ 段描述表项:L 长度 D 基地址 G 内存段单位(0代表字节(1M字节内存),1代表一个页面4k(4K*1M=4G))}
保护模式下内存地址的分段映射:
GDT[DS >> 3].baseAddr + 逻辑地址 = 线性地址
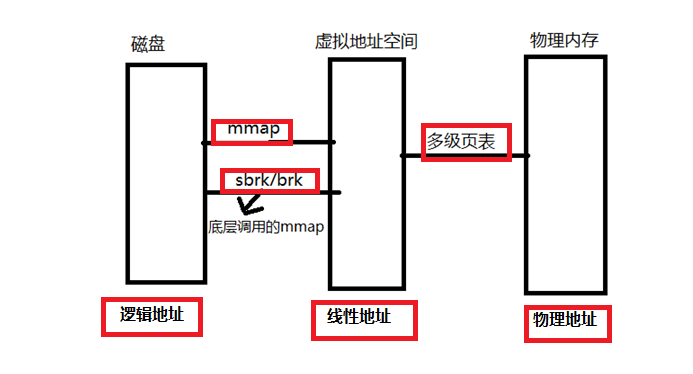
如果操作系统只开启内存分段: 线性地址== 物理地址
如果操作系统开启了内存分页: 线性地址(多级页表映射)—>物理地址
推荐书籍:《程序员的自我修养》第1章 内存分段,分页
从线性地址到物理地址的映射过程:
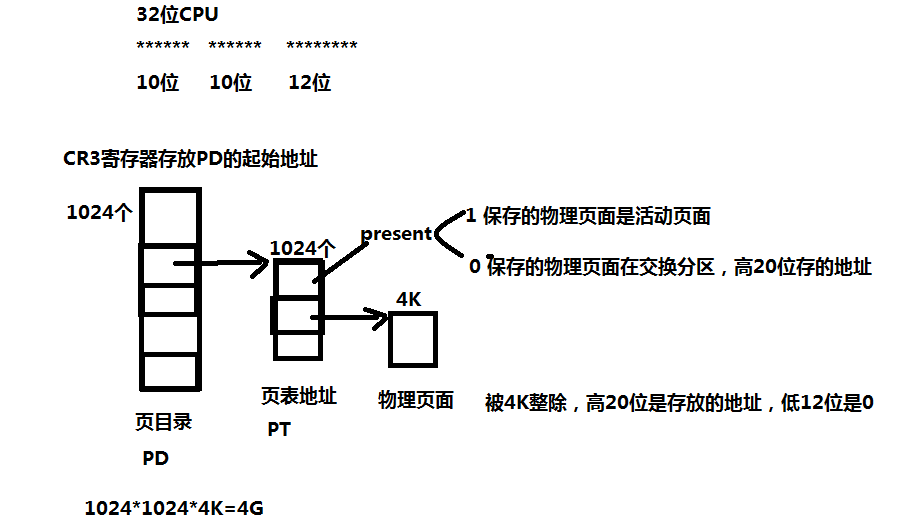
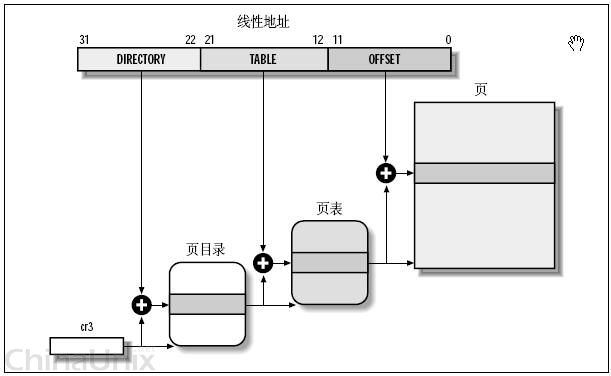
便于读者更清晰地理解,特在网上找了一个图供读者来看
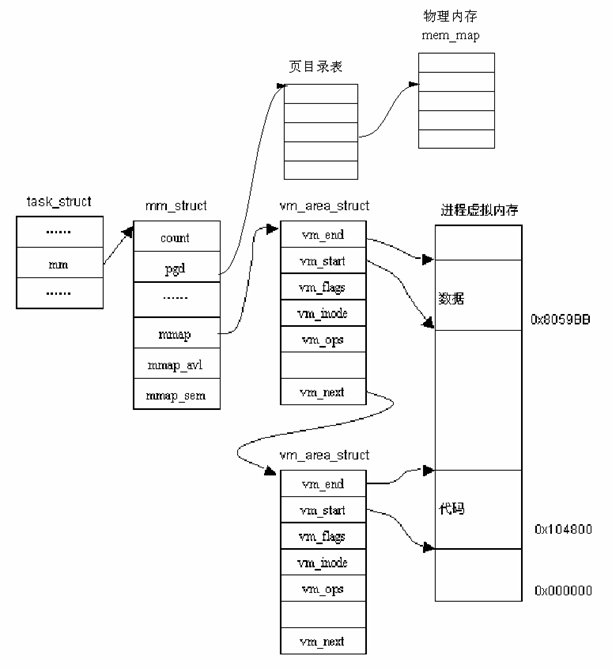
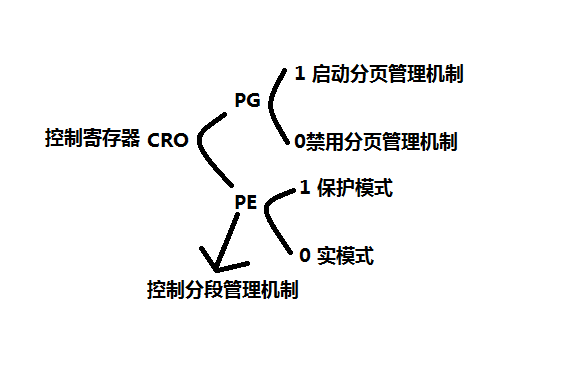
分页机制由CR0中的PG位启用。
如PG=1,启用分页机制,把线性地址转换为物理地址。
如PG=0,禁用分页机制,直接把段机制产生的线性地址当作物理地址使用。
分页机制管理的对象是页。分页机制把整个线性地址空间及整个物理地址空间都看成由页组成,在线性地址空间中的任何一页,可以映射为物理地址空间中的任何一页。
线性地址中的相邻地址在映射到物理地址上时,不一定是相邻的,因为有可能不在同一个页面。反之亦然。
分页机制通过把线性地址空间中的页,重新定位到物理地址空间来进行管理,因为每个页面的整个4K字节作为一个单位进行映射,并且每个页面都对齐4K字节的边界,因此,线性地址的低12位经过分页机制直接地作为物理地址的低12位使用。
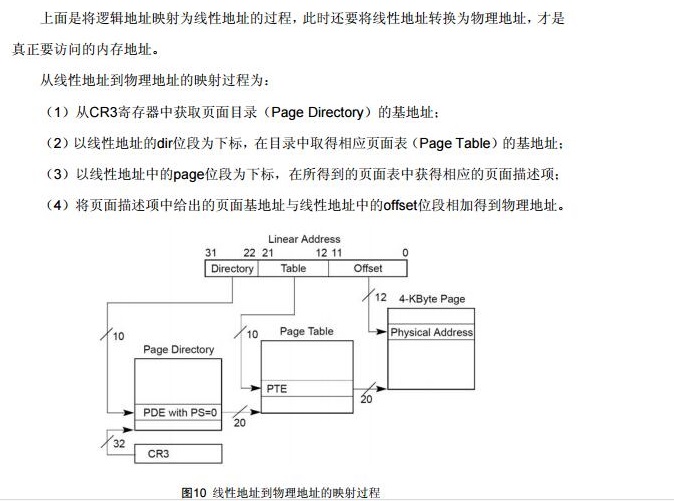
映射过程:
1)从CR3中获取得页目录的基地址
2)以线性地址的DIR位段为下标,在目录表中取得相应页面表的基地址
3)以线性地址中的page位段为下标,在得到的页面表中获得相应页面描述符
4)将页面描述符项中给出的页面基地址,与线性地址中的offset段相加得到物理地址
总结:
地址的转换过程是通过软件的完美配合来实现的。一个是操作系统内核,一个是cpu中的MMU(也可以在MMU中设置TLB,加快地址翻译速度)。内核主要提供寄存器,页目录,页表等,MMU主要负责计算过程。
要注意的是,分段机制是IA32提供的寻址方式,这是硬件层面的。无论windows还是linux,只要使用IA32的CPU访问内存,都需经过MMU的转换流程才能得到物理地址,也就是说必须经过逻辑地址–线性地址–物理地址的转换。
就IA32架构的CPU来说,就有多种分页实现,常规分页机制,PAE机制等。Linux的分页机制是建立在硬件基础之上的,不同的平台需要有不同的实现。Linux在软件层面构造的虚拟地址,最终还是要通过MMU转换为物理地址,不管Linux的分页机制是怎样实现,CPU只按照它的分页实现来解读线性地址,所以Linux传给CPU的线性地址必然是满足硬件实现的。比如说:Linux在32位CPU上,它的四级页表结构就会兼容到硬件的两级页表结构。可见,Linux在软件层面上做了一层抽象,用四级页表的方式兼容32位和64位CPU内存寻址的不同硬件实现。
读者也可通过工具bochs 2.6.8来计算从逻辑地址到物理地址的转换过程。
使用bochs计算地址映射过程的推荐链接:
http://blog.csdn.net/zouliping123/article/details/8275381















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









