






一、引言
在《并发编程的艺术》一书中对ScheduledThreadPoolExecutor的介绍还是基于jdk1.6版本,而在jdk1.7之后ScheduledThreadPoolExecutor发生了较大的变化,其使用的阻塞队列由之前的DelayQueue变成了DelayedWorkQueue。DelayedWorkQueue是DelayQueue(take进行delay判断)和PriorityQueue(堆结构)的结合。
ScheduledThreadPoolExecutor的功能与Timer类似,但ScheduledThreadPoolExecutor功能更强大、更灵活。Timer对应的是单个后台线程,而ScheduledThreadPoolExecutor可以在构造函数中指定多个对应的后台线程数。
ScheduledThreadPoolExecutor是一个用于执行定时任务或延时任务的线程池,提交到该线程池中的任务会等到执行时间到了才会被执行。与前面所讲的ThreadPoolExecutor不同,提交到ThreadPoolExecutor中的任务,只要ThreadPoolExecutor中有空闲线程任务会被从任务队列马上取出(或者未达到核心线程数),就会被马上执行,如果ThreadPoolExecutor中没有空闲线程,则任务会被暂存在任务队列。而提交到ScheduledThreadPoolExecutor中的任务,不管此时ScheduledThreadPoolExecutor有没有空闲线程,任务都会被放入到队列里去,等待任务执行时间到期时被线程从队列中取出并执行。
假如在看ScheduleThreadPoolExecutor的源码之前,我们凭自己思路设计一个定时任务线程池,需要怎么设计呢?
普通线程池的运行机制是从任务队列队首位置取出任务后,需要立马执行,但是定时任务线程池不一样,每个任务都有自己的定时执行时间,或者延时运行时间,任务队列,队首的任务也不是要立马执行。
因为需要定期执行,每个定时任务其实是重复执行,所以可以看做定时任务线程池一旦初始化建立,并启动后,队列里面的任务是固定的。每个任务都安排一个线程沉睡到指定执行的时间点,然后唤醒该线程并执行,貌似是可以的,但是假如这些任务的执行时间是没有重合,前后的时间间隔也比较大,明明一个线程就可以搞定,却新建了很多线程,占用内存,浪费资源,此时,阻塞任务队列也成为摆设,毫无意义。所以这种思路不可取。
既然每个任务都有一个线程蹲守watch方案不可取,那就只蹲守watch一个任务,那蹲守哪个任务呢?肯定是延时执行时间最临近当前时间的任务了,怎么知道哪个任务的延时执行时间是最临近的呢,必须有线程在添加新任务时候,给阻塞任务队列里面的任务,按照延时时间排排序,这就是涉及到适合延时任务队列的最优的排序的算法了。肯定还需要一个哨兵线程来蹲守即将到期的任务。
如果线程池里面的任务执行时间有重合,任务过期,线程数不够,发生拥挤又怎么办呢?该怎么优化?
JAVA的源码又是怎么做的呢?带着这些问题,去源码中寻找答案。
二、源码解析(JDK1.8)
2.1、构造方法
虽然ScheduledThreadPoolExecutor源码将构造方法放到后面展开,将它的专属任务类放到最前面,但是既然引言对其与父类ThreadPoolExcutor做了对比,这里还是先讲一下它设定的几个构造方法:
/**
* 默认线程工厂、拒绝策略
*/
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
/**
* 带线程工厂,可以给线程自定义名字
*/
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}
/**
* 自定义一个拒绝策略,如果线程池被shutDown后会用得着
*/
public ScheduledThreadPoolExecutor(int corePoolSize,
RejectedExecutionHandler handler) {
// 因为是无界队列,所以最大线程数是没有用的,如果核心线程数为0,那么就会只有一个工作线程
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), handler);
}
/**
* 几个构造方法生成的线程池都是最大线程数和无界队列,如果有程序一直往线程池提交延时任务,也会造成OOM的风险
* 所以使用该线程池一定有把握,延时任务不会瞬时超大批量的添加,当然实际使用中,该场景也比较少。
* 实在无法避免此风险,就自己另外定义一个子类,做扩展,并将队列和最大线程数设置成有界
* 并自定义合适拒绝策略
*/
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}ThreadPoolExcutor的父类AbstractExecutorService,里面的submit()方法:
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}2.1.1、可接受的任务task:FutureTask
虽然提交的都是Runnable或者Callable实现类,但其实都被包装成FutureTask,也就是RunnableFuture的实现类。FutureTask可以看做是Callable的包装类,内部有Callable 和保存其结果的 outcome ,同时它实现RunnableFuture也就是同时实现了 Runnable 和 Future ,有run() 和 get() 方法,run()调用的Callable的call(),将结果存在outcome,它构造方法可以接受Callable类型的参数,也可以接受Runnable类型的参数,但如果是Runnble,可不是直接用来实现Runnable接口用的,而是将Runnbale适配成Callable(Callable调用的是Runnbale的run(),FutureTask的run() 又是再调用call() 饶了一圈)。不管怎么样,它既然实现Runnable,也就是可以被装配到线程里异步运行。由此可见,它设计的思路,主要是融合Callable 和 Future,同时为了可以被提交到线程池,装配给线程执行,而实现Runable。说白了,它是整合了 Callable、Future、Runnable的产物。
它存在的意义还是实现可提交到线程异步执行,并能返回结果的任务类型(当然,如果调用get()获取返回结果,就是同步获取结果了),需要的话,可以读一下FutureTask的源码。既然ThreadPoolExcutor可接受的任务的定义这么重要,那么ScheduledThreadPoolExecutor可接受的延时任务,当然也重要,所以在ScheduledThreadPoolExecutor源码中,ScheduledFutureTask比较靠前。
2.2、ScheduledFutureTask
2.2.1、ScheduledFutureTask的UML图

2.2.2、ScheduledFutureTask源码
private class ScheduledFutureTask<V>
extends FutureTask<V> implements RunnableScheduledFuture<V> {
/** 每个延时任务都有一个次序号,防止在在延时队列中排序的时候,
* 两个任务的延时时间一样,出现排序冲突,则通过次序号来决定
* 虽然任务是周期执行的,但是一旦任务被提交,次序号就定了,重复放入队列,并不会改变次序号
*/
private final long sequenceNumber;
/** 任务执行的时刻,在执行完后重复放入队列的时候,会被更新 */
private long time;
/**
* 循环执行的间隔时间
*/
private final long period;
/** The actual task to be re-enqueued by reExecutePeriodic */
RunnableScheduledFuture<V> outerTask = this;
/**
* 延时队列小顶堆中的下标
*/
int heapIndex;
/**
* 周期为0,非周期性任务,将runnable装配成callable再
*/
ScheduledFutureTask(Runnable r, V result, long ns) {
super(r, result);
this.time = ns;
this.period = 0;
this.sequenceNumber = sequencer.getAndIncrement();
}
/**
* Creates a periodic action with given nano time and period.
*/
ScheduledFutureTask(Runnable r, V result, long ns, long period) {
super(r, result);
this.time = ns;
this.period = period;
this.sequenceNumber = sequencer.getAndIncrement();
}
/**
* 非周期性任务callable
*/
ScheduledFutureTask(Callable<V> callable, long ns) {
super(callable);
this.time = ns;
this.period = 0;
this.sequenceNumber = sequencer.getAndIncrement();
}
/**
* 延时时间:RunnableScheduledFuture接口继承RunnableFuture、 ScheduleFuture, ScheduleFuture继承Delayed, Future
* Delaye(extends Comparable)接口有getDelay,延时队列的take() poll(long timeout, TimeUnit unit) 会用到
*/
public long getDelay(TimeUnit unit) {
return unit.convert(time - now(), NANOSECONDS);
}
public int compareTo(Delayed other) {
if (other == this) // compare zero if same object
return 0;
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;
long diff = time - x.time;
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
// 或许延时时间有相等的,但序号是不可能相等的
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);
return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;
}
/**
* 源自RunnableScheduledFuture,是否周期性执行
*/
public boolean isPeriodic() {
return period != 0;
}
/**
* 下次执行时间
*/
private void setNextRunTime() {
long p = period;
if (p > 0)
time += p;
else
// 后面解析触发器
time = triggerTime(-p);
}
public boolean cancel(boolean mayInterruptIfRunning) {
boolean cancelled = super.cancel(mayInterruptIfRunning);
if (cancelled && removeOnCancel && heapIndex >= 0)
remove(this);
return cancelled;
}
/**
* 该任务task的run方法: 线程池 Worker中的线程start()执行,Worker -> worker.run() -> runWork()执行
* while (task != null || (task = getTask()) != null) {task.run}
*/
public void run() {
boolean periodic = isPeriodic();
// 是否还能运行,这个方法很重要,紧接着ScheduledThreadPoolExecutor内部源码解析会做详细解析
if (!canRunInCurrentRunState(periodic))
cancel(false);
else if (!periodic)
ScheduledFutureTask.super.run();
// cancle的任务就算被放进队列,这一步是不会执行的
else if (ScheduledFutureTask.super.runAndReset()) {
// 重新放入队列的时候,设置下次的执行的时间,time 在getDelay会用到,delay在
// 延时队列的take -> available.awaitNanos(delay);
setNextRunTime();
// 本次执行完,重新放入队列:可以理解为周期性反复执行
reExecutePeriodic(outerTask);
}
}
}2.3、ScheduledThreadPoolExecutor的源码解析
// 在shutDown后,是否还能继续保留周期性执行的任务,如果想要在shutDown后,取消周期性任务,那就设置为false
// 本身就是默认值false, 而它的set方法也没有其他地方调用,说明一直保持默认的false, 但是set方法是public,
// 可以设置为true,只不过这样比较危险,因为一旦设置为true,就算shutDown线程池,
// 周期性任务可能会一直周期性反复执行,即使再设为false,也可能会继续执行1次,从而失控
private volatile boolean continueExistingPeriodicTasksAfterShutdown;
/**
* 初始值为true,说明非周期性任务,比如普通的延时任务,在已经放入队列前提下,再shutDown线程池后,是仍然可以执行
* 当然如果想要shutDown后取消延时任务,那就设置为false
*/
private volatile boolean executeExistingDelayedTasksAfterShutdown = true;
/**
* 这里初始值为false, 因为后面不需要在cancel后再remove,因为cancel里面有for循环,
* 可能还在执行cancel的时候已经有线程取到task开始执行了,这与设计目的不符,那么一般在判断条件里isShutdown() &&
* !canRunInCurrentRunState(task.isPeriodic()) &&
* remove(task)直接remove掉,&& 的逻辑前面的条件为false后,后面的remove就不会执行了
* 当然想要设置为true也没关系,只不过会显得多此一举,程序执行没有必要的逻辑
*/
private volatile boolean removeOnCancel = false;
/**
* 计数器,每放入一个任务,次序号自增,且该任务的次序号固定不可变,与之前的源码相呼应
*/
private static final AtomicLong sequencer = new AtomicLong();
/**
* Returns current nanosecond time.
*/
final long now() {
return System.nanoTime();
}
/**
* 在此状态,是否还能运行: periodic 只有在schedule()方法的时候,才为 false <— period == 0
* 那么也只有延时任务此方法才会返回true
*/
boolean canRunInCurrentRunState(boolean periodic) {
return isRunningOrShutdown(periodic ?
continueExistingPeriodicTasksAfterShutdown : // false
executeExistingDelayedTasksAfterShutdown); // true
}
/**
* @param 延时执行,当执行schedule、scheduleAtFixedRate、scheduleWithFixedDelay等方法的时候会执行此方法
*/
private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
// shutDown 就拒绝任务
reject(task);
else {
// 线程池的的队列添加任务:和线程池的execute(r) 方法不同,线程池的execute首先是判断线程数
// 不够核心线程数就添加工作线程,而这里是直接先丢到任务队列,然后再确保有工作线程:假如核心线程数
// 为0,因为无界队列的关系,所以最大线程数设定无用,不会添加工作线程,只会无尽的往队列里丢任务,
// 没有线程执行任务,所以要确保至少有一个线程执行任务
super.getQueue().add(task);
if (isShutdown() &&
// 如果已经添加到任务队列,才shutDown, 那么在判断在shutDown后,任务是否可以继续运行
// 比如设置continueExistingPeriodicTasksAfterShutdown为true, 任务周期时间为1ns,
// 提交任务和获取任务的线程,线程切换
// 或者固定频率周期任务超时(执行时间过期),所以,任务一放进队列立马执行
// 再设为false,可能还没有执行到remove这里,该任务已经取出在执行(remove返回false
// ,此处if条件返回false), 但是再放入队列的时候(下面那个方法)
// 会失败,所以可以执行一次,如果不设为FALSE,会一直执行,哪怕线程池shutDown,这导致失控
!canRunInCurrentRunState(task.isPeriodic()) &&
remove(task))
task.cancel(false);
else
// 确保有线程可以执行任务,这个方法在ThreadPoolExecutor里,但就是为了定时任务线程池量身定制的
ensurePrestart();
}
}
/**
* 周期性反复执行:其实主要作用是将任务重新放回延时队列,后面的ensurePrestart
* 只是确保有线程可以执行本次任务
* @param task the task
*/
void reExecutePeriodic(RunnableScheduledFuture<?> task) {
if (canRunInCurrentRunState(true)) {
super.getQueue().add(task);
// 比如设置continueExistingPeriodicTasksAfterShutdown为true, 任务周期时间为1ns,
// 提交任务和获取任务的线程,线程切换
// 或者固定频率周期任务超时(执行时间过期),所以,任务一放进队列立马执行(运行到此方法的这个位置),
// 进入if这里,才设为false(不可控的那么及时,即使设为false,下句代码立马再cancel),
// 可能还没有执行到remove这里,该任务已经取出在执行,remove时候任务早已不在队列,remove失败
// 那么就会再执行一次,但是多出的这一次可能就影响了业务逻辑
if (!canRunInCurrentRunState(true) && remove(task))
task.cancel(false);
else
ensurePrestart();
}
}
<------------------------------------------------------------------>
// ensurePrestart确保Worker数量
// corePoolSize=0 如果核心线程数为0,那么就会只有一个工作线程
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
if (wc < corePoolSize)
addWorker(null, true);
else if (wc == 0)
addWorker(null, false);
}
<------------------------------------------------------------------>
/**
* 根据shutDown的机制,取消任务并从队列中移除任务,
*
*/
@Override void onShutdown() {
BlockingQueue<Runnable> q = super.getQueue();
boolean keepDelayed =
getExecuteExistingDelayedTasksAfterShutdownPolicy();
boolean keepPeriodic =
getContinueExistingPeriodicTasksAfterShutdownPolicy();
if (!keepDelayed && !keepPeriodic) {
for (Object e : q.toArray())
if (e instanceof RunnableScheduledFuture<?>)
((RunnableScheduledFuture<?>) e).cancel(false);
q.clear();
}
else {
// Traverse snapshot to avoid iterator exceptions
for (Object e : q.toArray()) {
if (e instanceof RunnableScheduledFuture) {
RunnableScheduledFuture<?> t =
(RunnableScheduledFuture<?>)e;
if ((t.isPeriodic() ? !keepPeriodic : !keepDelayed) ||
t.isCancelled()) { // also remove if already cancelled
if (q.remove(t))
t.cancel(false);
}
}
}
}
// 死循环,尝试彻底终结线程池,前提是线程池的状态还没有到TERMINATED,
tryTerminate();
}
/**
* 看起来没有什么作用,直接将参数返回,用于子类实现
* @since 1.6
*/
protected <V> RunnableScheduledFuture<V> decorateTask(
Runnable runnable, RunnableScheduledFuture<V> task) {
return task;
}
/**
* @since 1.6
*/
protected <V> RunnableScheduledFuture<V> decorateTask(
Callable<V> callable, RunnableScheduledFuture<V> task) {
return task;
}
/**
* 触发器设置触发时间
*/
private long triggerTime(long delay, TimeUnit unit) {
return triggerTime(unit.toNanos((delay < 0) ? 0 : delay));
}
/**
* 触发器设置触发时间,逻辑就是当前时刻加上延时时间
*/
long triggerTime(long delay) {
return now() +
((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay));
}
/**
* 将队列中所有延迟的值限制在Long.MAX_VALUE,以避免溢出。
* 比如可能发生:如果任务正在退出队列,但有尚未完成,而添加了其他任务,延迟为长的最大值。
* 这时候就可能会溢出
*/
private long overflowFree(long delay) {
Delayed head = (Delayed) super.getQueue().peek();
if (head != null) {
long headDelay = head.getDelay(NANOSECONDS);
/**
* 能走进本方法中,就说明delay是一个接近long最大值的数。此时判断如果headDelay小于0
* 就说明延迟时间已经到了或过期了但是还没有执行,并且delay和headDelay的差值小于0,
* 说明headDelay和delay的差值已经超过了long的范围
*/
if (headDelay < 0 && (delay - headDelay < 0))
delay = Long.MAX_VALUE + headDelay;
}
return delay;
}
/**
* 延时执行任务,与周期性任务区别在于周期时间为0 一次性任务,接收runnable
*/
public ScheduledFuture<?> schedule(Runnable command,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<?> t = decorateTask(command,
new ScheduledFutureTask<Void>(command, null,
triggerTime(delay, unit)));
delayedExecute(t);
return t;
}
/**
* 接收callable 延时任务
*/
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay,
TimeUnit unit) {
if (callable == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<V> t = decorateTask(callable,
new ScheduledFutureTask<V>(callable,
triggerTime(delay, unit)));
delayedExecute(t);
return t;
}
/**
* 固定频率周期性执行任务,任务下一次执行的时刻是固定的,当该任务的下一次执行时刻已经错过了(当前时刻已经晚于next执行时刻,即超时),
* 那么该任务本次执行完毕后,立马重复执行(其实延时任务也是这样,当触发时间已经错过(当前时间晚于触发时间,已过期),延时任务一放入队列,立马执行),
* 也有不能立马执行的:可能因为线程池线程数不够,比如线程池中没有核心线程,而唯一的工作线程可能还在执行其他任务,或者核心线程数不够,
* 小于总任务数,所有的工作线程在执行其他任务 ,想反如果系统资源空缺出来,那么任务执行时间变短,该任务执行时刻可能被修正到期望(设定)时刻,
* 不再错过任务执行时刻,即不再超时,如果预估的周期时间本来比资源全空闲情况执行时间还要短,那么任务执行时刻无法修正,一直是无时间间隔的执行)
*/
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
unit.toNanos(period));
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}
/**
* 固定延时时长的周期性任务,不管任务执行时间如何变化(任务执行时间除了本身的时间复杂度,还与系统资源相关,
* 可能资源突然空闲出来,任务执行时间变短,相反会变长)任务的执行的前后间隔时间固定,与前面的方法区别在于重新放入队列的时候,
* 下一次触发时间是该任务本次执行的时刻直接加上周期时间,还是当前系统时间加上周期时间。固定延时执行就是后者
*
*/
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (delay <= 0)
throw new IllegalArgumentException();
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),
unit.toNanos(-delay));
RunnableScheduledFuture<Void> t = decorateTask(command, sft);
sft.outerTask = t;
delayedExecute(t);
return t;
}
/**
* 此方法是任务立马执行,延时时间为0
*/
public void execute(Runnable command) {
schedule(command, 0, NANOSECONDS);
}
/**
* 重写方法
*/
public Future<?> submit(Runnable task) {
return schedule(task, 0, NANOSECONDS);
}
public <T> Future<T> submit(Runnable task, T result) {
return schedule(Executors.callable(task, result), 0, NANOSECONDS);
}
public <T> Future<T> submit(Callable<T> task) {
return schedule(task, 0, NANOSECONDS);
}
/**
* 前面已经讲过,该方法要慎用(设为true,后面再设为false可能还是无法控制不再执行任务,
* 可能还是会再执行一次),甚至最好不用,非要用并设为true的话,该任务必须后续做cancel逻辑
*/
public void setContinueExistingPeriodicTasksAfterShutdownPolicy(boolean value) {
continueExistingPeriodicTasksAfterShutdown = value;
if (!value && isShutdown())
onShutdown();
}
public boolean getContinueExistingPeriodicTasksAfterShutdownPolicy() {
return continueExistingPeriodicTasksAfterShutdown;
}
/**
* 可以设置为false,这样延时任务在shutDown后,也不可执行
*/
public void setExecuteExistingDelayedTasksAfterShutdownPolicy(boolean value) {
executeExistingDelayedTasksAfterShutdown = value;
if (!value && isShutdown())
onShutdown();
}
public boolean getExecuteExistingDelayedTasksAfterShutdownPolicy() {
return executeExistingDelayedTasksAfterShutdown;
}
/**
* 最好不用,设为true也是不必要的冗余逻辑
*/
public void setRemoveOnCancelPolicy(boolean value) {
removeOnCancel = value;
}
public boolean getRemoveOnCancelPolicy() {
return removeOnCancel;
}
/**
* 线程池的shutDown用来控制
* @throws SecurityException {@inheritDoc}
*/
public void shutdown() {
super.shutdown();
}
/**
* 不光此时阻塞的线程被打断,runnable,但是仍然在获取任务的线程,一旦进入take方法的await阻塞,立马抛出异常,运行结束,被中断
*/
public List<Runnable> shutdownNow() {
return super.shutdownNow();
}
scheduleAtFixedRate和scheduleWithFixedDelay提交的任务流程是一样的,唯一区别就是setNextRunTime这个方法,前者是本次执行时刻+周期时间,后者是当前系统时间+延时时间。
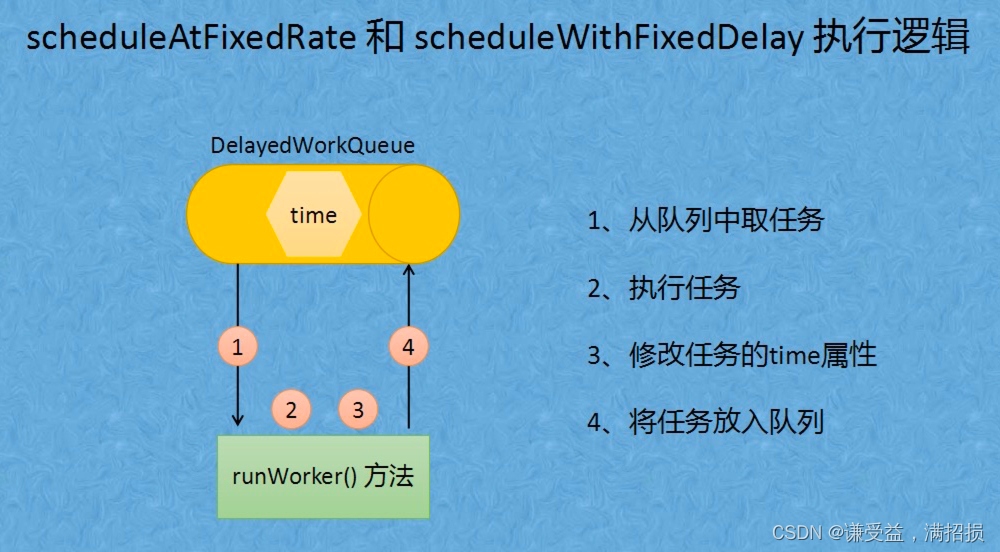
scheduleAtFixedRate

scheduleWithFixedDelay

2.4、DelayedWorkQueue源码解析
最后来解析定时任务线程池的自实现延时队列:
 JDK1.7之前,延时队列直接用的DelayQueue,只能存放实现了Delayed接口的对象,故要自定义一个实现Callable或实现Runnable的类,这样便能往队列中存入对象了。有了任务对象还要定义指定线程什么时候运行的属性,因为Delayed接口中只给定了一个获取剩余延迟时间的接口方法:login getDelay(TimeUnit unit)。所以要同时实现Delayed接口,而当前JDK版本,自己实现了一ScheduledFutureTask,整合了Runable,Callable,Future,Delayed,上面也具体讲述了。
JDK1.7之前,延时队列直接用的DelayQueue,只能存放实现了Delayed接口的对象,故要自定义一个实现Callable或实现Runnable的类,这样便能往队列中存入对象了。有了任务对象还要定义指定线程什么时候运行的属性,因为Delayed接口中只给定了一个获取剩余延迟时间的接口方法:login getDelay(TimeUnit unit)。所以要同时实现Delayed接口,而当前JDK版本,自己实现了一ScheduledFutureTask,整合了Runable,Callable,Future,Delayed,上面也具体讲述了。
解读线程池的时候,一般会去了解优先级队列PriorityBlockingQueue,这里顺带也说了一下PriorityQueue,两者的实现方式是一模一样的,都是采用基于数组的平衡二叉堆实现,不论入队的顺序怎么样,take、poll出队的节点都是按优先级排序的。但是PriorityBlockingQueue/PriorityQueue队列中的所有元素并不是在入队之后就已经全部按优先级排好序了,而是只保证head节点即队列的首个元素是当前最小或者说最高优先级的,其它节点的顺序并不保证是按优先级排序的,PriorityBlockingQueue/PriorityQueue队列只会在通过take、poll取走head之后才会再次决出新的最小或者说最高优先级的节点作为新的head,其它节点的顺序依然不保证。所以通过peek拿到的head节点就是当前队列中最高优先级的节点。
明白了优先级队列的原理要理解DelayQueue就非常简单,因为DelayQueue就是基于PriorityQueue实现的,DelayQueue队列实际上就是将队列元素保存到内部的一个PriorityQueue实例中的(所以也不支持插入null值),DelayQueue只专注于实现队列元素的延时出队。
延迟队列DelayQueue是一个无界阻塞队列,它的队列元素只能在该元素的延迟已经结束或者说过期才能被出队。它怎么判断一个元素的延迟是否结束呢,原来DelayQueue队列元素必须是实现了Delayed接口的实例,该接口有一个getDelay方法需要实现,延迟队列就是通过实时的调用元素的该方法来判断当前元素是否延迟已经结束。
既然DelayQueue是基于优先级队列来实现的,那肯定元素也要实现Comparable接口,没错因为Delayed接口继承了Comparable接口,所以实现Delayed的队列元素也必须要实现Comparable的compareTo方法。延迟队列就是以时间作为比较基准的优先级队列,这个时间即延迟时间,这个时间大都在构造元素的时候就已经设置好,随着程序的运行时间的推移,队列元素的延迟时间逐步到期,DelayQueue就能够基于延迟时间运用优先级队列并配合getDelay方法达到延迟队列中的元素在延迟结束时精准出队。
DelayedWorkQueue就是DelayQueue的扩展,有必要的话,读一下DelayQueue的源码,至于为什么需要自己扩展出一个内部类来实现,下面的源码解析会解释。
DelayedWorkQueue采用小顶堆堆数据结构来存储元素,小顶堆(队列)中的元素是ScheduledFutureTask。每一个ScheduledFutureTask自身存储了自身在堆中的位置索引,这使得在队列中删除元素的时间复杂度从o(n)(因为删除之后还要进行堆的排序),调整降到了o(logn)
static class DelayedWorkQueue extends AbstractQueue<Runnable>
implements BlockingQueue<Runnable> {
/*
* 用小顶堆算法,上筛和下筛必须要读取效率高,所以用数组实现;
* 不过ThreadPoolExecutor的阻塞队列一般用LinkededBlockingQueue,这里为什么用数组呢?
* 首先线程池中经常有取消cancel和remove,所以用Linked这种比较适合,但是它只适合只有添加顺序,
* 没有compareTo的顺序,否则就算用linked,删除后,照样还要排序移动元素,
* 排序交换(读取)的效率比数组肯定低
*/
private static final int INITIAL_CAPACITY = 16;
private RunnableScheduledFuture<?>[] queue =
new RunnableScheduledFuture<?>[INITIAL_CAPACITY];
private final ReentrantLock lock = new ReentrantLock();
private int size = 0;
/**
* leader线程,是等待延时队列中首个任务延时时间到了就立马唤醒,取出任务,执行任务,
* 作用类似占位亚元,leader都休眠了等任务执行时间到期,其他的就更要等了,
* 也正是因为最先请求任务的线程wait休眠,所以他会释放锁,为了避免其他线程都来争抢获取到队首
* 任务,那么就必要需要一个占位leader角色,虽然有独占锁互斥,不用担心线程不安全,但是无效的
* 争抢,比如同时在waitSet等够时间后,同时CAS争抢入CLH队列,这还不算,频繁在CLH队列和waitSet队列之中切换,
* 无用的损耗系统资源
*/
private Thread leader = null;
/**
* 等待条件作为参考对象,对应的有等待队列
*/
private final Condition available = lock.newCondition();
/**
* 设置下标,这也是ScheduleThreadPoolExecutor自实现延时队列的原因之一
* 方便根据下标快速cancel 和remove,还有indexOf方法,目的是不用遍历对比,
* 从而避免影响延时队列的方法执行时间,变得不准时
*/
private void setIndex(RunnableScheduledFuture<?> f, int idx) {
if (f instanceof ScheduledFutureTask)
((ScheduledFutureTask)f).heapIndex = idx;
}
/**
* 上筛:从目标下标位置开始,一直与父节点对比,小于父节点就一直交换位置,直到比父节点大,上筛结束
* offer,添加元素(从队尾开始上筛),删除元素都会用到上筛
* 具体过程讲解会有图解
*/
private void siftUp(int k, RunnableScheduledFuture<?> key) {
while (k > 0) {
//上筛没有下筛麻烦,只要不是根节点就行,且父节点只有一个
int parent = (k - 1) >>> 1;
RunnableScheduledFuture<?> e = queue[parent];
// 这里任务都是ScheduleFutureTask, compareTo方法是不可能有相等的情况
if (key.compareTo(e) >= 0)
break;
queue[k] = e;
setIndex(e, k);
k = parent;
}
queue[k] = key;
setIndex(key, k);
}
/**
* 下筛,在take() poll() remove方法里有用到,只不过是通过finishPoll方法,将队尾的元素从队首进行一次下筛操作,
* 基本就是原来小顶堆的根节点的子节点上位根节点(即队首),而队尾节点往上上一层;之所以让队尾的元素来进行下筛,是因为这样做
* 比起从中间某个位置拿一个元素去顶替根节点,不用后面所有的元素都需要移动一遍
*/
private void siftDown(int k, RunnableScheduledFuture<?> key) {
int half = size >>> 1;
// 首先得有子节点
while (k < half) {
// 默认取的左孩子节点作为被交换位置的孩子节点
int child = (k << 1) + 1;
RunnableScheduledFuture<?> c = queue[child];
int right = child + 1;
// 当有右子节点,且右子节点小于左子节点时候,右子节点成为待交换位置的子节点
if (right < size && c.compareTo(queue[right]) > 0)
c = queue[child = right];
if (key.compareTo(c) <= 0)
break;
queue[k] = c;
setIndex(c, k);
k = child;
}
queue[k] = key;
setIndex(key, k);
}
/**
* 扩容:增长50%
*/
private void grow() {
int oldCapacity = queue.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // grow 50%
if (newCapacity < 0) // overflow
newCapacity = Integer.MAX_VALUE;
queue = Arrays.copyOf(queue, newCapacity);
}
/**
* indexOf的作用:contains remove 不用遍历
*/
private int indexOf(Object x) {
if (x != null) {
if (x instanceof ScheduledFutureTask) {
int i = ((ScheduledFutureTask) x).heapIndex;
// Sanity check; x could conceivably be a
// ScheduledFutureTask from some other pool.
if (i >= 0 && i < size && queue[i] == x)
return i;
} else {
for (int i = 0; i < size; i++)
if (x.equals(queue[i]))
return i;
}
}
return -1;
}
public boolean contains(Object x) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return indexOf(x) != -1;
} finally {
lock.unlock();
}
}
/**
* remove上筛和下筛都用到了,后面会详细图解
*/
public boolean remove(Object x) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 之所以用下标取该位置元素,而不是直接用x,就是防止,程序进入这里,x已经被其他线程删除,取走(队首删除),
int i = indexOf(x);
if (i < 0)
return false;
setIndex(queue[i], -1);
int s = --size;
RunnableScheduledFuture<?> replacement = queue[s];
queue[s] = null;
if (s != i) {
// 顶替x位置,help GC x
//先下筛,无子节点,或者无需下筛,那么就可能需要上筛
siftDown(i, replacement);
// 经过下筛,是必然相等的
if (queue[i] == replacement)
// 如果下筛成功,则不需要上筛,上筛直接返回,最极端的情况,是既不需要上筛也不需要下筛
siftUp(i, replacement);
}
return true;
} finally {
lock.unlock();
}
}
public int size() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return size;
} finally {
lock.unlock();
}
}
public boolean isEmpty() {
return size() == 0;
}
public int remainingCapacity() {
return Integer.MAX_VALUE;
}
public RunnableScheduledFuture<?> peek() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return queue[0];
} finally {
lock.unlock();
}
}
public boolean offer(Runnable x) {
if (x == null)
throw new NullPointerException();
RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>)x;
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = size;
if (i >= queue.length)
// 扩容
grow();
size = i + 1;
if (i == 0) {
// 初始状态,直接放到队首
queue[0] = e;
setIndex(e, 0);
} else {
// 否则从队尾上筛
siftUp(i, e);
}
if (queue[0] == e) {
// 如果是在队首了,唤醒等待任务的线程,并将leader置空,免得take那里阻塞
// take或poll(delay)里面的逻辑try{}finally那里不是必然会释放leader = null吗?为什么这里还要释放leader?
// 比如,(1)有其他线程A,刚执行完上一波任务,就去获取下一波任务来执行,执行take方法
// 没有获取到锁从而阻塞,而不是wait阻塞。(有线程B获取到锁,正在尝试获取任务,只不过leader被占用,
// 它也是获取不到,进入waitSet),C线程往队列添加任务,也被阻塞, 正好队首的任务的执行时刻到期,
// leader线程从waitSet移到CLH队列,但在CLH争用队列里,A线程排在leader之前,同样C线程也在leader之前
// 那么这个A线程会截胡leader线程获取到<队首任务>释放锁,此时队列为空,C线程被A唤醒(unpark,非signal唤醒)
// 获取锁往队列添加任务,C线程程序会走到这里,同时leader线程不能被唤醒,leader角色不能被释放,
// leader就需要C线程在此释放(2)没有其他线程在CLH队列里排在leader前面,leader线程成功被唤醒,但是在争用锁的时候,
// 有其他线程CAS争抢锁成功,leader失败,同样会让leader线程再次阻塞,leader角色不能被释放
// 还有比较极端情况,(3)防止take方法里,刚赋值leader,还没有进入try,就发生其他异常,
// 这里leader亚元角色就会一直被占据,得不到释放,
leader = null;
available.signal();
}
} finally {
lock.unlock();
}
return true;
}
public void put(Runnable e) {
offer(e);
}
public boolean add(Runnable e) {
return offer(e);
}
public boolean offer(Runnable e, long timeout, TimeUnit unit) {
return offer(e);
}
/**
* 完成任务的获取,要设置下标为-1, 表示已经删除,并且将队尾元素放到队首(小顶堆根节点)做下筛
*/
private RunnableScheduledFuture<?> finishPoll(RunnableScheduledFuture<?> f) {
int s = --size;
RunnableScheduledFuture<?> x = queue[s];
// 队尾位置释放
queue[s] = null;
if (s != 0)
// 取走任务,移动元素,顶替队首(下筛替换),help GC 队首任务对象
siftDown(0, x);
// 设置已经删除标志
setIndex(f, -1);
return f;
}
/**
* 这个方法这里线程池内部的环境是不会用到的,只是简单实现父类和接口
*/
public RunnableScheduledFuture<?> poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
RunnableScheduledFuture<?> first = queue[0];
if (first == null || first.getDelay(NANOSECONDS) > 0)
return null;
else
return finishPoll(first);
} finally {
lock.unlock();
}
}
// take方法是阻塞队列的重点方法,核心线程会调用这个方法,非核心线程会调用poll(delay)
// 衔接线程池的源码,这里再强调一边,核心线程和非核心线程没有本质区别,当池中线程数大于核心线程数时候,所有线程都
// 有可能(没有任务,刚好这些线程排在获任务的lock.condition等待队列的前面)被当做非核心线程按照存活时间的进行延时释放,
// 当线程数小于等于核心线程数的时候,所有的线程都是核心线程,调用take() 方法一直休眠死等
public RunnableScheduledFuture<?> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
// 可中断锁,一旦有中断标识,就会抛出异常,从而线程也会运行结束至terminated
lock.lockInterruptibly();
try {
// 死循环基本是AQS和synchronized相关的常规操作了,前提是wait阻塞方法在条件结构体{}内部
// 防止虚假唤醒
for (;;) {
// 获取队首即根节点的任务,肯定是延时时长最小的一个了(
// 在ScheduledFutureTask里是周期时间period/当前系统时间 + 上次执行时刻 -> nextRunTime(time),
// 这里的delay就是time - now())
RunnableScheduledFuture<?> first = queue[0];
if (first == null)
// 还没有任务,核心线程,当然死等了
available.await();
else {
long delay = first.getDelay(NANOSECONDS);
// 如果已经错过执行时间(任务过期),或者刚刚好,那么立即完成获取任务的动作
if (delay <= 0)
return finishPoll(first);
// 凡是还没有到时间的,必须要释放掉此时first,因为可能等线程休眠醒来,first已经另有其人,
// 可能此时的first因为被取消被remove,或者因为新的任务延时时长更短,直接上位根节点,成为队首,总是原因有很多
first = null;
// leader亚元被占位,说明前面一个线程还在延时等待它的任务到执行时间,那后面的后面的线程就更要阻塞等待了
// 所以leader不为空,那么当前线程就变成了follower,此线程阻塞住休眠。
// 对比AQS中 shouldParkAfterFailedAcquire: int ws = pred.waitStatus;
// if (ws == Node.SIGNAL) return true;就有熟悉的感觉
if (leader != null)
/**
* 一般情况下,leader线程休眠足够时间后,释放了leader, 会在上面获取到任务,除非有其他A线程CAS比它先得到锁截胡,
* 那么可能其他B线程成为新leader,它(原leader线程)也会被阻塞住休眠;否则就它会在下面的else分支中再次成为leader线程
*/
available.await();
else {
// 如果前面的线程释放leader占位,leader == null 说明要么前面的线程等待的任务到期了,
// 刚好这时候其他线程来获取任务,其他线程也可以直接获取这个任务,直接finishPoll,
// 截胡(这种情况出现的比较少,offer那里详细举例了)。或者前面leader线程唤醒后成功获取队首任务,
// 释放了leader,那么当前线程成为leader
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
// 按照任务的延时时长等待一段时间后就会被唤醒执行任务(当前任务的队首的地位没有被夺走的话,
// 否则就要重新来过,从循环体的初始步骤开始执行,它在执行finally后,也会失去leader线程的角色),
// 这就是延时任务和周期性任务可以定时执行的关键所在
available.awaitNanos(delay);
} finally {
// 等到任务的执行时刻到了,就释放leader亚元
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
// 不管如何,如果队列有任务,leader亚元也被释放,唤醒在等待队列中首个阻塞(WAITING)的线程,
// 当然不是能被立马唤醒的,如果在争用队列CLH中有排在它前面的线程,那么在它前面的线程先获取到锁,
// 执行循环体中的逻辑,反正凡是被唤醒的线程都要从循环体
// 的初始位置重新来过一遍,效果都是一样的,不必局限于某一个线程来执行
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
}
//当线程数大于核心线程数的时候就调用这个方法
public RunnableScheduledFuture<?> poll(long timeout, TimeUnit unit)
throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
RunnableScheduledFuture<?> first = queue[0];
if (first == null) {
if (nanos <= 0)
return null;
else
// 队列中无任务,不再是死等了
nanos = available.awaitNanos(nanos);
} else {
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
return finishPoll(first);
if (nanos <= 0)
// 存活时间耗尽,还是没有等到任务执行时刻,直接返回null,线程运行完毕进入terminated
return null;
first = null; // don't retain ref while waiting
// 唤醒后再次进入,此时的delay已经不再大于存活时间nanos了,说不定leader也被释放了
if (nanos < delay || leader != null)
// 亚元被占用不再死等,或者存活时间小于延时时间,先等够存活时间再看
nanos = available.awaitNanos(nanos);
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
long timeLeft = available.awaitNanos(delay);
// 存活时间减去已经休眠的时间,就是剩余的存活时间,->更新存活时间
nanos -= delay - timeLeft;
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
}
public void clear() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
for (int i = 0; i < size; i++) {
RunnableScheduledFuture<?> t = queue[i];
if (t != null) {
queue[i] = null;
setIndex(t, -1);
}
}
size = 0;
} finally {
lock.unlock();
}
}
/**
* 用于将过期的task转移到其他的集合,私有方法只用于drainTo调用,调用时候,肯定已经获取到锁
* Returns first element only if it is expired.
* Used only by drainTo. Call only when holding lock.
*/
private RunnableScheduledFuture<?> peekExpired() {
// assert lock.isHeldByCurrentThread();
RunnableScheduledFuture<?> first = queue[0];
return (first == null || first.getDelay(NANOSECONDS) > 0) ?
null : first;
}
public int drainTo(Collection<? super Runnable> c) {
if (c == null)
throw new NullPointerException();
if (c == this)
throw new IllegalArgumentException();
final ReentrantLock lock = this.lock;
lock.lock();
try {
RunnableScheduledFuture<?> first;
int n = 0;
while ((first = peekExpired()) != null) {
c.add(first); // In this order, in case add() throws.
finishPoll(first);
++n;
}
return n;
} finally {
lock.unlock();
}
}
public int drainTo(Collection<? super Runnable> c, int maxElements) {
if (c == null)
throw new NullPointerException();
if (c == this)
throw new IllegalArgumentException();
if (maxElements <= 0)
return 0;
final ReentrantLock lock = this.lock;
lock.lock();
try {
RunnableScheduledFuture<?> first;
int n = 0;
while (n < maxElements && (first = peekExpired()) != null) {
c.add(first); // In this order, in case add() throws.
finishPoll(first);
++n;
}
return n;
} finally {
lock.unlock();
}
}
}三、图解小顶堆实现延时任务队列
3.1、小顶堆的解析演示:
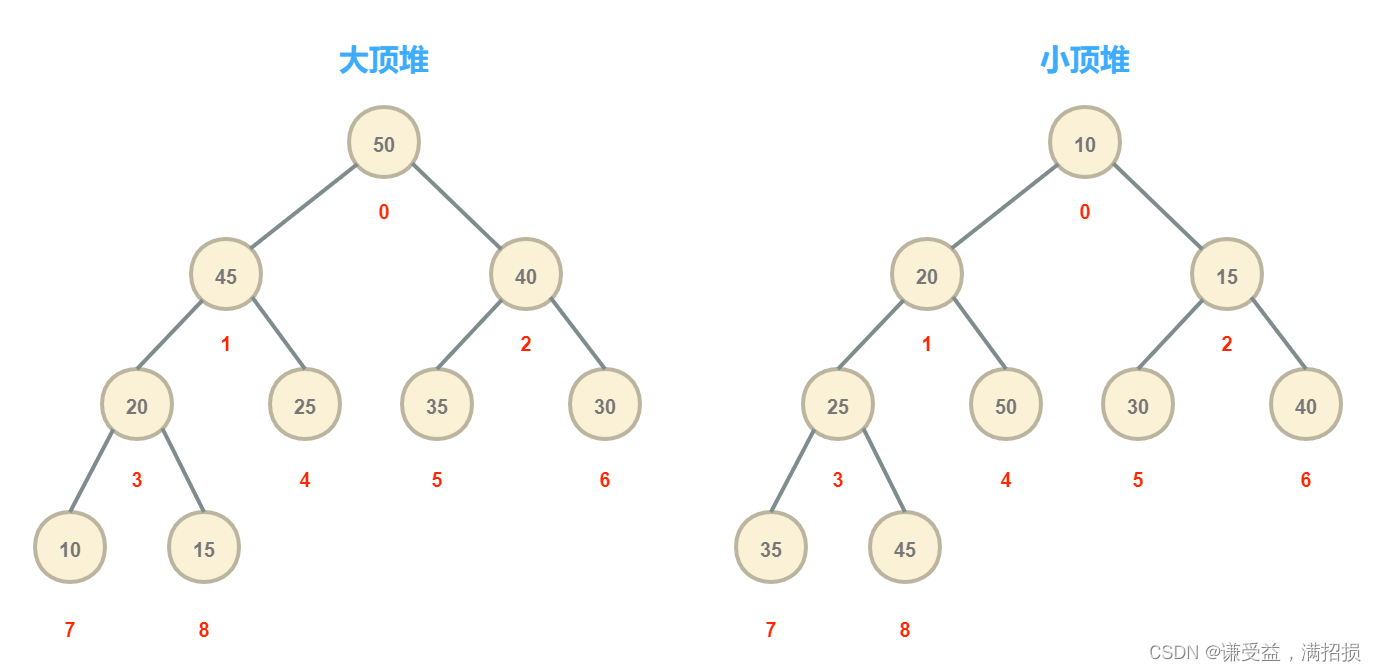
假设当前节点的索引是k,那么其父节点的索引是:(k-1)/2;左孩子节点的索引是:k*2+1;而右孩子节点的索引是k*2+2。
3.2、添加节点

如果在上面的siftUp过程中,发现某一次当前节点的值就已经大于了父节点的值,siftUp过程也就会提前终止了。同时可以看出:在上面的siftUp以及下面将要讲的siftDown操作过程中,每次都只会比较并交换当前节点和其父子节点的值,而不是整个堆都发生变动,降低了时间复杂度。
3.3、删除节点
经典的小顶堆添加和删除节点的实现,而在源码中的实现略有不同(图解删除节点和DelayedWorkQueue里面的逻辑不同在于:DelayedWorkQueue删除节点,并不是先交换该节点和最后一个节点,再删除最后一个节点,而是将被删的位置的节点index设为-1,标明该节点是被删除节点,然后取到最后一个节点后,直接释放队尾位置,再从被删除节点的位置对最后一个节点下筛,当然特殊情况最后一个节点刚好适配被删节点的位置,那么就当他们是交换位置,但是大多数情况是不会刚刚好,所以不会让程序先做一次交换的无用功,再去删除),不过核心逻辑都是一样的:
下面是拿删根节点举例,其实线程池线程去队首位置任务,就是删节点的逻辑,只不过它是根节点只用做下筛就好。

然后是删除最后一个节点的情况。删除最后一个节点是最简单的,只需要进行删除就行了,因为这并不影响小顶堆的结构,不需要进行调整。这里就不再展示了(注意:删除除了最后一个节点的其他叶子节点并不属于当前这种情况,而是属于下面第三种情况。也就是说删除这些叶子节点并不能简单地删除它们就完了的,因为堆结构首先得保证是一颗完全二叉树)。
最后是删除既不是根节点又不是最后一个节点的情况:

在删除既不是根节点又不是最后一个节点的时候,可以看到执行了一次siftDown并伴随了一次siftUp的过程。但是这个siftUp过程并不是会一定触发的,只有满足最后一个节点的值比要删除节点的父节点的值还要小的时候才会触发siftUp操作(这个很好推理:在小顶堆中如果最后一个节点值比要删除节点的父节点值要小的话,那么要删除节点的左右孩子节点值也必然是都大于最后一个节点值的(不考虑值相等的情况),那么此时就不会发生siftDown操作;而如果发生了siftDown操作,就说明最后一个节点值至少要比要删除节点的左右孩子节点中的一个要大(如果有左右孩子节点的话)。而孙子节点值是肯定要大于爷爷节点值的(不考虑值相等的情况),所以也就是说发生了siftDown操作的时候,最后一个节点值是比要删除节点的父节点值大的。这个时候孙子节点和最后一个节点siftDown交换后,依然是满足小顶堆性质的,所以就不需要附加的siftUp操作;还有一种情况是最后一个节点值是介于要删除节点的父节点值和要删除节点的左右孩子节点值中的较小者,那么这个时候既不会发生siftDown,也不会发生siftUp)。
更多资源分享,请关注我的公众号:搜索或扫码 砥砺code

四、设计模式
Leader-Follower模式
ScheduledThreadPoolExecutor中使用了Leader-Follower模式。这是一种设计思想,假如说现在有一堆等待执行的任务(一般是存放在一个队列中排好序),而所有的工作线程中只会有一个是leader线程,其他的线程都是follower线程。只有leader线程能执行任务,而剩下的follower线程则不会执行任务,它们会处在休眠中的状态。当leader线程拿到任务后执行任务前(其实还没有拿到任务,只要休眠足够时间,再次获得锁,就会释放leader),自己会变成follower线程,同时会选出一个新的leader线程,然后才去执行任务。如果此时有下一个任务,就是这个新的leader线程来执行了,并以此往复这个过程。当之前那个执行任务的线程执行完毕再回来时,会判断如果此时已经没任务了,又或者有任务但是有其他的线程作为leader线程,那么自己就休眠了;如果此时有任务但是没有leader线程,那么自己就会重新成为leader线程来执行任务。
不像ThreadPoolExecutor是需要立即执行任务的,ScheduledThreadPoolExecutor中的任务是延迟执行的,而拿取任务也是延迟拿取的。所以并不需要所有的线程都处于运行状态延时等待获取任务。而如果这么做的话,最后也只会有一个线程能执行当前任务,其他的线程还是会被再次休眠的(这里只是在说单任务多线程的情况,但对于多任务来说也是一样的,总结来说就是Leader-Follower模式只会唤醒真正需要“干事”的线程)。这是很没有必要的,而且浪费资源。所以使用Leader-Follower模式的好处是:避免没必要的唤醒和阻塞的操作,这样会更加有效,且节省资源。
五、读源码后个人设想
解读源码往往就是带着问题寻找答案,却得到了更多的问题。我将这些疑问,尽可能详尽的写在了源码注释里。如果你有更好的问题,更好的解读,欢迎评论留言交流。
现在来回答引言中的问题:如果线程池里面的任务执行时间有重合,任务过期,线程数不够,发生拥挤又怎么办呢?
多个任务执行时间重合,JDK作者给每个任务唯一的一个次序号sequenceNumber来解决,因为采用原子操作类做累加器次序号是不可能重合相等的。
任务过期,需要立即执行,等于等待时长为0,此时如果有多个任务过期(线程数不够,或者核心线程数为0,线程池中只有一个线程)也相当于执行时间重合,那么也是依靠次序号解决排序冲突的。
尽管有方案解决排序冲突,也利用了小顶堆的数据结构来做上筛或者下筛时的排序和位置交换,数组的读取效率也确实够高,但是遇到任务过期的情况,时间本来就超时了,还要做排序和移动,始终会浪费一些时间。能不能在队首做一个链表过期队列,只要是超期的任务,都放进链表,也不用排序了,谁先放进来谁先执行,FIFO,先进先出。如果要取消任务,链表也非常合适中间删除某一个节点。
如果是scheduleAtFixedRate提交的任务,而工作线程数足够情况,任务设定的周期时间,比执行时间短,任务只要被重新放入队列,就会立马被取出执行,这种情况,似乎也没有必要在意它们的次序号的顺序,反正都差不多是同时执行,如果添加的时候还要排序移动,反而更浪费时间。采用链表过期专用队列似乎也可行,但是这种情况比较极端,比较少见,大多还是线程数不够,资源数不够,导致的拥挤,那么谁先执行,肯定要取决于谁先提交的(次序号顺序),只要需要排序,位置交换,肯定还是数组的小顶堆效率更高。毕竟读取速度要甩链表好大一截,我想这就是JDK不为过期任务单独设置一个链表队列的原因。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









