






很多人可能会上来就发结论:做去重的字段相同,语义相同,有索引的情况下,二者差不多;没有索引的情况下,distinct 效率高,没有索引的情况下,group by会进行隐式排序,出发filesort,导致sql执行效率低于distinct。
可是group by在不同的数据库中语法是区别很大的:比如mysql中比较灵活,group by子句中的字段和select子句中字段关联不大,group by中的字段可以出现在select 中,也可以不出现。select子句中的字段同样可以出现在group by中,也可以不出现。
比如:
SELECT A FROM TABLE GROUP BY B;
SELECT A, B FROM TABLE GROUP BY B;但是oracle 和 pgsql 中的group by 就不是这个语法了:
SELECT A, B FROM TABLE GROUP BY B;
> 错误: 字段 "A" 必须出现在 GROUP BY 子句中或者在聚合函数中使用所以oracle和 pgsql中,group by 子句使用是有限制的,在select 列表中指定的列要么是group by 子句中指定的列,要么包含聚合函数。当然group by 指定的列可以是select 子句中别名列。group by 中的字段不一定要出现在select 中。
SELECT A FROM TABLE GROUP BY A, B;
SELECT A, number num FROM table GROUP BY A, num如此大的语法差异,自然它们实现机制差距也比较大。oracle 、pgsql这些数据库的group by 根本就不会对分组字段进行排序。
而mysql的排序还是仅限于对紧跟group by的第一个字段进行排序,多字段分组的情况下,除了第一个字段,其他的并不做排序。
这里大家可以自己尝试造数据进行尝试:
SELECT B, A FROM TABLE GROUP BY A, B;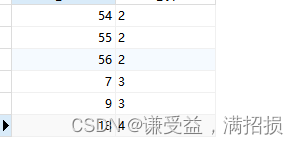
oracle、pgsql压根就不排序:
mysq还可以进行显式排序:
mysql> SELECT id, SUM(cnt) FROM t GROUP BY id DESC; --GROUP BY显式排序
+------+----------+
| id | SUM(cnt) |
+------+----------+
| 4 | 6 |
| 3 | 12 |
| 2 | 9 |
| 1 | 13 |
+------+----------+
4 rows in set (0.00 sec)当然这些排序仅限于 mysql 5.7之前的版本。mysql 8之后,隐式排序取消,显式排序会报错。其实取消这种操作也好,众多数据库中也就mysql有这种排序操作,而且只排序第一个group by 子句中的字段,对于不需要排序的查询需求,无疑是增加不必要的执行负担。如果必要排序,开发者自己用order by 进行排序会更灵活。
对于distinct ,这几个数据库的语法倒是比较一致的:
SELECT DISTINCT A, B, C... FROM table WHERE conditions;
DISTINCT 关键词用于返回唯一不同的值。放在查询语句中的第一个字段前使用,且作用于主句所有列。
如果列具有NULL值,并且对该列使用DISTINCT子句,MySQL将保留一个NULL值,并删除其它的NULL值,因为DISTINCT子句将所有NULL值视为相同的值。
distinct多列的去重,则是根据指定的去重的列信息来进行,即只有所有指定的列信息都相同,才会被认为是重复的信息。这其实和group by的逻辑是一样的。
所以多列去重,无论是group by还是distinct 其实都是无法做到某一列中完全没有重复项。
这也就是说:除了mysql 早期版本,其他数据中,这两个用作的去重的效率是一样。
不过group by相对distinct 能处理分组后的各种聚合操作,它本身也是为此而生的,仅仅只是去重的话,选二者中任何一个都可以。
mysql中的group by更加灵活,可以实现单列去重,其他非分组列,默认显示的是第一条数据。其他数据库要实现此功能就只能这样写了:
select A, B, C ... from table where id in (select id from (select A, Min(id) id from table group by A) a)相对mysql确实很麻烦。
在Mysql8.0之前,Group by会默认根据作用字段(Group by的后接字段)对结果进行排序。在能利用索引的情况下,Group by不需要额外进行排序操作;但当无法利用索引排序时,Mysql优化器就不得不选择通过使用临时表然后再排序的方式来实现GROUP BY了。且当结果集的大小超出系统设置临时表大小时,Mysql会将临时表数据copy到磁盘上面再进行操作,语句的执行效率会变得极低。这也是Mysql选择将此操作(隐式排序)弃用的原因。
从前(Mysql5.7版本之前),Group by会根据确定的条件进行隐式排序。在mysql 8.0中,已经移除了这个功能,所以不再需要通过添加order by null 来禁止隐式排序了,但是,查询结果可能与以前的 MySQL 版本不同。要生成给定顺序的结果,请按通过ORDER BY指定需要进行排序的字段。
——> GROUP BY 默认隐式排序(指在 GROUP BY 列没有 ASC 或 DESC 指示符的情况下也会进行排序)。然而,GROUP BY进行显式或隐式排序已经过时(deprecated)了,要生成给定的排序顺序,请提供 ORDER BY 子句。
顺便说一下having 子句用法和where 子句的区别:
from => join => on => where => group by => having => select => order by => limit
having、where:都是条件查询,区别在于having可以用字段别名和聚合函数。
- Having子句的作用和WHERE子句差不多,都是用来做条件筛选的,但它只能和group by组合使用,不能单独出现;
- 只是Having子句需要写在GROPY BY子句的后面,也是在group by 之后执行(from 之后的sql子句出现的顺序也代表了执行顺序);
- GROPY BY 子句执行完毕之后,才会轮到Having子句去执行;自然Having子句的执行顺序是在WHERRE子句之后的,所以在Having子句中可以使用聚合函数做条件判断。
- 在Having子句中,拿聚合函数跟具体的数据做比较是没有问题的,比如“HAVING COUNT(*)>=2;”是没有问题的;但是,拿聚合函数跟某个字段作条件判断是不行的,这个必须用表连接才能实现;
SELECT deptno
FROM emp
WHERE hiredate>="1999-01-01"
GROUP BY deptno HAVING COUNT(*)>=2 AND AVG(sal)>=2000;
SELECT id, A FROM (
SELECT * FROM table ORDER BY id desc limit 10
) as a GROUP BY a.id;
– limit需要大于最后的结果的条数
– mysql5.7之后,子查询中的排序不生效,加上limit使排序生效
如果你觉得我的博客写的还不错,请关注我的公众号吧:
更多资源分享,请关注我的公众号:搜索或扫码 砥砺code

















 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









