






 Cassandra是一款分布式NoSQL数据库,擅长处理大规模跨数据中心的数据。它采用分区行存储,提供线性可扩展性和高可用性。Cassandra通过多节点无单点故障设计、gossip协议进行节点间通信、一致性哈希数据分配、动态数据复制和故障恢复策略,确保数据的高效管理和持久化。此外,虚拟节点和Snitch策略优化了数据在集群中的分布和读写性能。
Cassandra是一款分布式NoSQL数据库,擅长处理大规模跨数据中心的数据。它采用分区行存储,提供线性可扩展性和高可用性。Cassandra通过多节点无单点故障设计、gossip协议进行节点间通信、一致性哈希数据分配、动态数据复制和故障恢复策略,确保数据的高效管理和持久化。此外,虚拟节点和Snitch策略优化了数据在集群中的分布和读写性能。
Cassandra概述
Cassandra是一个大规模可伸缩的开源NoSQL数据库,在管理大规模的跨多数据中心或者云的结构化、半结构化、非结构化数据上非常有优势。Cassandra通过不存在单点故障的多节点服务器,从而实现了持续有效性、线性可伸缩性、操作简单的性能,以及设计强大的动态数据模型来实现最大的灵活性和快速的响应时间。
Cassandra工作原理
Cassandra’s built-for-scale架构意味着它有能力处理PB级的数据以及每秒成千上万的用户操作并发。
- Cassandra是一个分区的行存储数据库;
- 数据自动同步
- 内置可定制数据库副本数量
- 线性扩展性(轻易增加节点)
Cassandra与关系型数据库的区别
Cassandra最开始就是设计成为点对点沟通的分布式数据库。作为一项最佳实践,查询应该针对一张表,数据应该非规范化才能让这个最佳实践成为可能。因此,JOINs这个概念在Cassandra表中是不存在的,不过在客户端应用中还是可以使用的(Node.js driver)。
Cassandra架构简要
Cassandra的设计目的是通过没有单点故障的多节点模式去处理海量数据工作负载,它的架构是基于理解系统和硬件故障是可以而且会发生的基础上的。Cassandra通过peer-to-peer分布式系统来解决故障问题,该系统中的节点是平等同类的,数据都分布在所有节点上。通过gossip通信协议,集群中的每一个节点频繁地交换着状态信息。每个节点上的commit log捕获写行为来确保数据的持久化。数据会被索引并写入一个名为memtable的内存结构,每当内存结构满了后,数据就会被写到一个叫SSTablede 磁盘文件中。所有的写入都是自动分区和复制的。Cassandra会通过一个叫Compaction的进程周期性的整合SSTables,准备丢 弃的过期无用数据会标记上tombstone以待删除。为了确保所有数据在集群上保持一致,各种各样的修复机制被利用;
Cassandra是一个分区的面向行存储的数据库。Cassandra的架构允许任何授权了的用户连接任何数据中心的任何节点,并使用cql访问数据。客户端的读写请求可以到达集群的任意节点。当一个客户端连接到一个节点做一个请求时,那个节点服务器就作为这个特定的客户操作的一个coordinator,coordinator扮演了客户应用和拥有用户请求的数据的节点之间的代理的角色。coordinator会根据集群中的配置决定哪些节点应该响应请求。
关键结构
- Node
- Data Center
- Cluster
- Commit Log:所有数据首先都是被写入commitlog进行持久化;最终它的数据还是会被存到SSTables中的;
- SSTable
- CQL Table
Cassandra配置的关键组件
- Gossip:一个点对点协议,用于发现和共享在Cassandra集群中别的节点的数据的状态等信息(共享数据的方式);
- Partitioner:决定了哪一个节点来存储数据的第一个备份、如何分布数据到集群的各个节点。每一行数据由主键(primary key)唯一标识,它们可能含有相同的分区键(partition key),也有可能包括其他集群列。partitioner 是一个从行的主键得到token的hash函数。The Partitioner 通过token值来决定集群中的哪些节点来存储这些行的备份。Murmur3Partitioner为默认分区;你必须为每一个节点设置Partitioner并且指定 num_tokens 值。num_tokens值大小的指定取决于系统的硬件功能。如果不使用虚拟节点,相反就得设置 initial_token。
- Replication factor:整个集群的副本数;
- Replica placement strategy: Cassandra存储数据的备份到多个节点上去来确保可用性和故障容忍。一个备份策略决定了哪些节点存放备份;
- Snitch:(只能选择性能好的节点进行读取)当你创建一个集群时必须配置一个snitch,snitch将服务器组定义为replication strategy用于放置副本的数据中心和机架。所有的snitch监控所有节点的性能然后选择最好的副本进行读操作,GossipingPropertyFileSnitch在生产中推荐使用。
- Cassandra.yaml
节点间通信gossip
Cassandra使用点对点通讯协议gossip在集群中的节点间交行位置和状态信息,gossip进程每秒运行一次,与至多3个其他节点交换信息。
gossip协议的具体表现形式就是配置文件中的seeds种子节点,一个注意点是同一个集群中的所有节点的种子节点应该一致。在多数据中心的集群中,最好在seed list中至少含有每个数据中心的一个节点,这样做有利于容错性。
失败检测与恢复
如果有任何一个节点宕机或者恢复,Cassandra能够通过gossip state and history 这些信息避免将请求路由至不可到达或者性能差的节点(后者需配置为dynamic snitch方可)。可通过配置phi_convict_threshold来调整失败检测的敏感度;对于失败的节点,其他节点会通过gossip定期与之联系以查看是否恢复而非简单将之移除。若需强制添加或者移除集群中节点需使用nodetool工具。一旦某节点被标记为失败,其错过的写操作会有其他replicas存储一段时间(需开启hinted handoff,若节点失败的事件超过max_hint_window_in_ms,错过的写不再被存储),down掉的节点经过一段时间回复后需执行repair操作,一般在所有节点运行nodetool repair以确保数据一致。
数据分配和备份
在Cassandra中,数据分配和备份是同时的;
影响数据复制的因素包括:
1. Virtual nodes
2. Partitioner
3. Replication strategy
4. Snitch
一致性哈希(Consistent hashing)
cassandra表中每行数据由primary key唯一标识,Cassandra为每个primary key分配一个hash值,集群中每个节点(vnode)拥有一个或多个hash值区间。这样便可根据primary key对应的hash值将该条数据放在包含该hash值的hash值区间对应的节点中。
Virtual nodes
如果tokens被使用了,那么以一个出色的间距跨节点分配数据将很容易就能实现,虚拟节点简化了Cassandra中的很多工作:
1. 自动计算Tokens并且分配给每一个节点
2. 当增加或者移除一个节点时自动完成集群的再平衡。当集群中增加一个节点时,它承担来自集群中其他节点的一部分同等的数据;当一个节点down了,负载会平均地传播到集群中的其他节点。
3. 可以很快地恢复一个dead节点因为它涉及到了 集群中的其他每个节点;
4. 指定给集群中的each machine的虚拟节点的比例可以自定义,因此大的小的服务器都可以用于建立集群;
数据如何在集群中分配(使用虚拟节点)
虚拟节点允许每个节点拥有大量的遍及整个集群的small partition ranges;
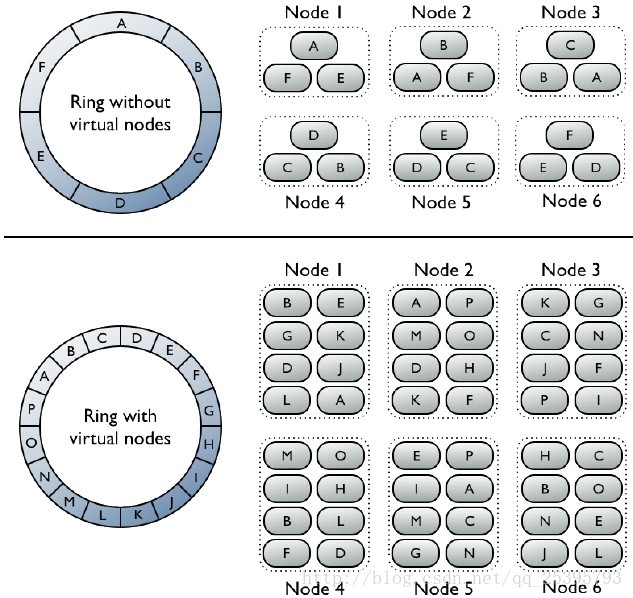
前者:每个节点都分配了代表哈希环中一段位置的一个单一的token,每个节点存储的数据取决于数据的分区键换算成的那个token值所对应的哈希环的位置。每个节点也包含其他节点的数据的备份。注意:一个节点正好拥有ring中一个连续的partition range(未使用虚拟节点的情况);
后者:虚拟节点被随机的选择并且非连续的,一个行记录的定位取决于其分区键的哈希值,每个节点拥有许多小的partition ranges.
数据复制备份
- SimpleStrategy:仅用于单数据中心,将第一个replica放在有partitioner确定的节点后,其余的replica放在上述节点顺时针方向的后续节点中;
- NetworkTopologyStrategy:可用于较复杂的多数据中心,可以指定在每个数据中心分别存储多少份relicas;
Snitch
snitch确定那个数据中心或者rack被写或者读,并且通知Cassandra有关网络拓扑的信息,使得请求能够有效地路由,并且允许Cassandra通过组合数据中心和rack中的机器来分配副本;如果你在数据已经被写入集群后,修改了snitch,你必须运行一次全修复,因为snitch影响了副本的存放位置.















 251
251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









