Hadoop的高可用集群部署
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章
2.1、IP地址和主机名称更改
提示:以下是本篇文章正文内容,下面案例可供参考
前言
Hadoop HA原理:
在一典型的HA集群中,每个NameNode是一台独立的服务器。在任一时刻,只有一个NameNode处于active状态,另一个处于standby状态。其中,active状态的NameNode负责所有的客户端操作,standby状态的NameNode处于从属地位,维护着数据状态,随时准备切换(两种切换方式,选择手动切换和自动切换)。手动切换是通过命令实现主备之间的切换,可以用HDFS升级等场合,自动切换方案基于Zookeeper。两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
Hadoop 高可用集群的搭建依赖于 Zookeeper,所以选取三台当做 Zookeeper 集群 ,这里总共准备了三台主机(可按实际规划),分别是 Hadoop01、Hadoop02、Hadoop03。其中 Hadoop01 和 Hadoop02 做 NameNode 的主备切换,Hadoop03 和 Hadoop04 做 ResourceManager 的主备切换。
将三台主机Hadoop01、Hadoop02、Hadoop03、Hadoop04,按如下HA安装方案图进行集群规划:
| HA安装方案图 | NameNode | DataNode | ResourceManager | Zookeeper | ZKFC | JournalNode | NodeManager |
|---|
| Hadoop01 | √ | | | | √ | √ | |
| Hadoop02 | √ | √ | | √ | √ | √ | √ |
| Hadoop03 | | √ | √ | √ | | √ | √ |
| Hadoop04 | | √ | √ | √ | | | √ |
一、准备:Hadoop、Hbase、Hive和zookeeper版本兼容关系
Hadoop平台中各个组件的版本匹配是非常重要的!不是所有组件下载最新版本就好,版本不匹配容易引发各种问题。
1、Hadoop
2、Hadoop和Hbase版本关系
Hadoop和Hbase的匹配关系图:
3、Hadoop和Hive
Hadoop和Hive的匹配关系查看Hive的下载页面:http://hive.apache.org/downloads.html
Hadoop和Hive的匹配关系:
| Hive第3.x.y版 | Hive第2.x.y版 | Hive第1.x.y版、第0.14.0版 | Hive第0.x.y版 |
|---|
| 适用于Hadoop 3.x.y | 适用于Hadoop2.x.y | 适用于Hadoop1.x.y,2.x.y. | 适用于Hadoop 0.20.x、0.23.x.y、1.x.y、2.x.y |
4、Hbase和Hive的匹配关系
5、Hbase与Zookeeper的匹配关系
二、安装配置模板机Hadoop01
1.在VMware安装CentOS 7系统
提示:我这里使用的是CentOS-7.5-x86_64-DVD-1804.iso
下面是CentOS 7系统的安装步骤图例:
2.Hadoop模板机IP地址和主机名称配置
2.1、IP地址和主机名称更改
su root
vim /etc/sysconfig/network-scripts/ifcfg-ens33
打开后更改下面:
#BOOTPROTO="dhcp" 默认为动态获取IP地址,改为静态获取IP地址
BOOTPROTO="static"
#在此文档添加以下命令
#IP地址
IPADDR=192.168.10.101
#网关
GATEWAY=192.168.10.2
#域名解析器
DNS1=192.168.10.2
vim /etc/hostname
改为下面名称:
hadoop01
2.2、配置 Linux 克隆机主机名称映射 hosts 文件
vim /etc/hosts
并添加以下内容:
192.168.10.101 hadoop01
192.168.10.102 hadoop02
192.168.10.103 hadoop03
192.168.10.104 hadoop04
192.168.10.105 hadoop05
192.168.10.106 hadoop06
192.168.10.107 hadoop07
192.168.10.108 hadoop08
reboot
3.安装hadoop
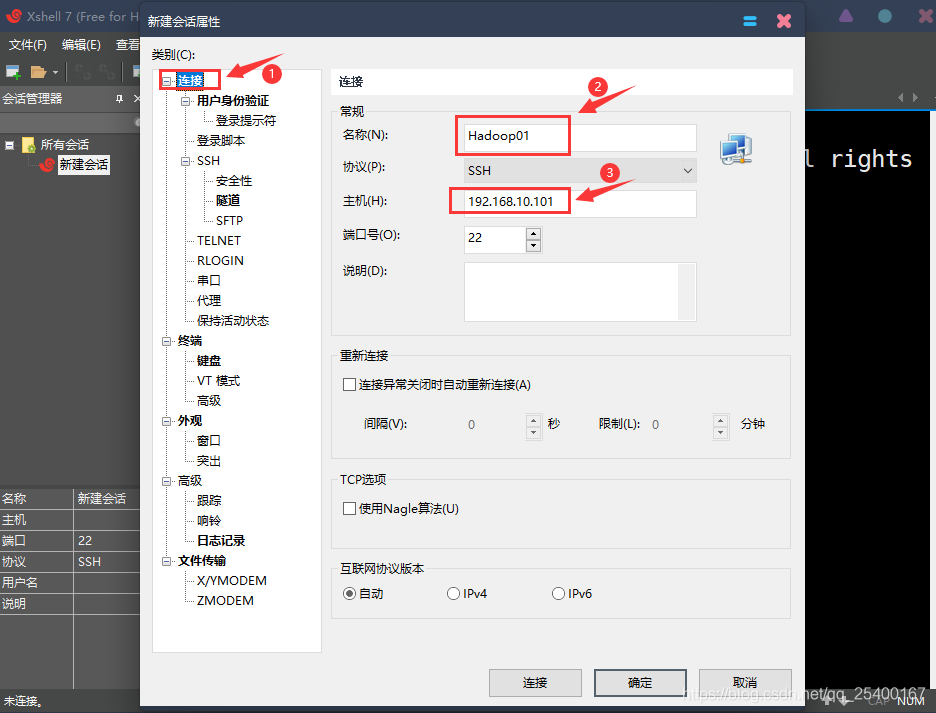
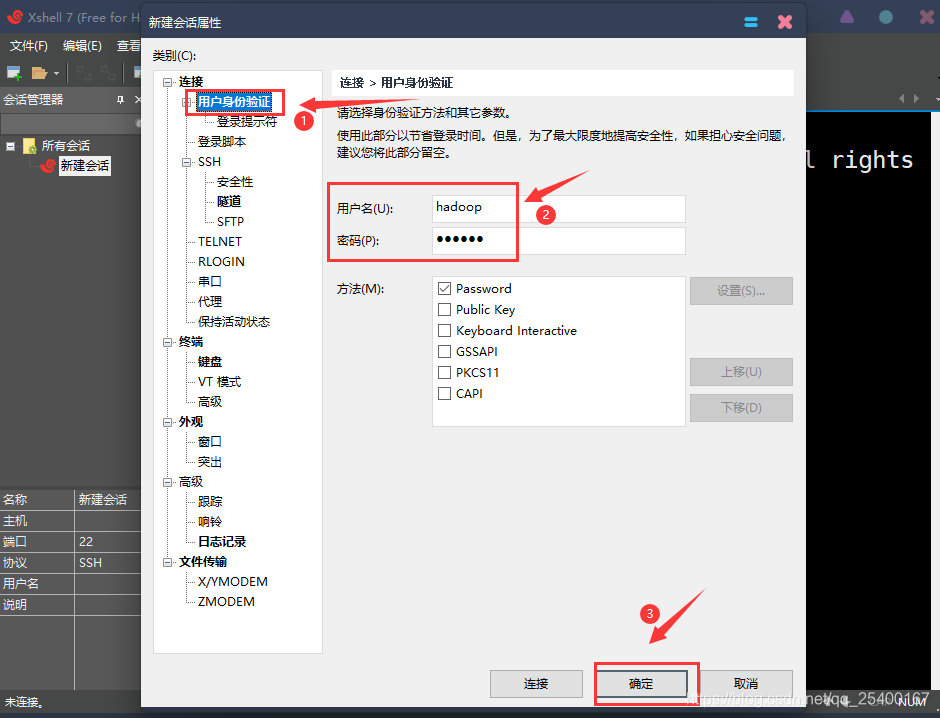
3.1、使用Xshell 链接CentOS 7
在终端输入以下命令查看IP地址
ifconfig
 |
|---|
 |
| - |
3.2、测试网络链接
在Xshelll界面输入以下命令
ping wwww.baidu.com -c 2
3.3、安装 epel-release
注:Extra Packages for Enterprise Linux 是为“红帽系”的操作系统提供额外的软件包,
适用于 RHEL、CentOS 和 Scientific Linux。相当于是一个软件仓库,大多数 rpm 包在官方
repository 中是找不到的)
切换到root用户
su root
执行以下代码
yum install -y epel-release
注意:如果 Linux 安装的是最小系统版,还需要安装如下工具;如果安装的是 Linux
桌面标准版,不需要执行如下操作:
➢ net-tool:工具包集合,包含 ifconfig 等命令
yum install -y net-tools
➢ vim:编辑器
yum install -y vim
3.4、关闭防火墙,关闭防火墙开机自启
systemctl stop firewalld
systemctl disable firewalld.service
注意:在企业开发时,通常单个服务器的防火墙时关闭的。公司整体对外会设置非常安
全的防火墙
3.5、配置Hadoop用户具有 root 权限,方便后期加 sudo 执行 root 权限的命令
vim /etc/sudoers
添加以下代码:
hadoop ALL=(ALL) NOPASSWD:ALL
3.6、在/opt 目录下创建 module、software 文件夹
cd opt
删除rh文件夹
sudo rm -rf rh/
在/opt 目录下创建 module、software 文件夹
sudo mkdir module/ software/
3.7、修改 module、software 文件夹的所有者和所属组均为hadoop用户
sudo chown hadoop:hadoop module/ software/
3.8、卸载虚拟机自带的 JDK
使用下面代码查询:
rpm -qa | grep -i java
注意:如果你的虚拟机是最小化安装不需要执行这一步。
切换至root用户
su root
卸载虚拟机自带的 JDK
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
查询是否删除
rpm -qa | grep -i java
➢ rpm -qa:查询所安装的所有 rpm 软件包
➢ grep -i:忽略大小写
➢ xargs -n1:表示每次只传递一个参数
➢ rpm -e –nodeps:强制卸载软件
卸载之后重启
reboot
3.9、配置JDK环境变量和Hadoop环境变量
3.9.1、上传JDK和Hadoop
cd /opt/software/
3.9.2、解压jdk-8u212-linux-x64.tar.gz和hadoop-3.1.3.tar.gz
使用下方命令解压jdk-8u212-linux-x64.tar.gz到/opt/module/目录
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
使用下方命令解压hadoop-3.1.3.tar.gz到/opt/module/目录
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
3.9.3、配置JDK环境变量和Hadoop环境变量
进入到jdk1.8.0_212/目录
cd /opt/module/jdk1.8.0_212/
进入到/etc/profile.d/
cd /etc/profile.d/
创建my_env.sh脚本
sudo vim my_env.sh
写入以下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
3.9.4、重新加载profile
重新加载profile
source /etc/profile
4.集群配置
4.1、切换到hadoop配置文件目录
cd /opt/module/hadoop-3.1.3/etc/hadoop/
4.2、配置 hadoop-env.sh文件
vim hadoop-env.sh
在文件结尾处添加:
export JAVA_HOME=/opt/module/jdk1.8.0_212
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
4.3、配置 core-site.xml文件
vim core-site.xml
按O插入以下内容
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs:
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
ns是集群的名称,hadoop.tmp.dir是存储临时数据的目录,ha.zookeeper.quorum下要配置zookeeper集群:主机名:2181,2181是zookeeper的默认端口,不要改。
4.3、配置 hdfs-site.xml文件
vim hdfs-site.xml
按O插入以下内容
<!-- 与前面配置的匹配-->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!--给两个namenode起别名nn1,nn2名字不固定,可以自定义 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!--nn1的rpc通信端口 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop01:8020</value>
</property>
<!-- nn1的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop01:9870</value>
</property>
<!--nn2的rpc通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop02:8020</value>
</property>
<!--nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop02:9870</value>
</property>
<!--设置共享edits文件夹:告诉集群哪些机器要启动journalNode -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal:
</property>
<!-- journalnode的edits文件存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/hadoop-3.1.3/data/journalnode</value>
</property>
<!--该配置开启高可用自动切换功能 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置切换的实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--生成的秘钥所存储的目录 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置namenode存储元数据的目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:
</property>
<!-- 配置datanode存储数据块的目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:
</property>
<!--指定block副本数为3,该数字不能超过主机数。 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置hdfs的操作权限,设置为false表示任何用户都可以在hdfs上操作并且可以使用插件 -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
4.4、配置 yarn-site.xml文件
vim yarn-site.xml
按O插入以下内容
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
4.5、配置 mapred-site.xml文件
vim mapred-site.xml
按O插入以下内容
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5.编写xsync分发脚本
5.1、在/home/hadoop/bin 目录下创建 xsync 文件
cd /home/hadoop
mkdir bin
cd bin
vim xsync
插入以下内容:
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop01 hadoop02 hadoop03 hadoop04
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
5.2、设置xsync权限
chmod 777 xsync
三、克隆三台虚拟机:Hadoop02,Hadoop03,Hadoop04
1、克隆虚拟机
注意:Hadoop03和Hadoop04也是同样的操作,这里我就只演示了Hadoop02的克隆操作
2、修改修改IP地址和主机名称
参考:二、2.1、IP地址和主机名称更改
重启
reboot
3、使用Xshell链接
参考:二、3.1、使用Xshell 链接CentOS 7
4、重新加载profile
参考:二、3.9.4、重新加载profile
四、群起集群
1、SSH免密登录配置
1.1、生成公钥和私钥
切换到家目录
cd /home/hadoop/
输入以下代码
ssh-keygen -t rsa
注:需敲三个回车,就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
注:Hadoop102、Hadoop103和Hadoop104也是同样操作
1.2、拷贝公钥到目标机器上
切换到家目录后输入以下代码
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
ssh-copy-id hadoop04
注意:
还需要在 hadoop02 上采用 hadoop 账号配置一下无密登录到 hadoop01、hadoop02、hadoop03、
hadoop04 服务器上。
还需要在 hadoop03 上采用 hadoop 账号配置一下无密登录到 hadoop01、hadoop02、hadoop03、
hadoop04 服务器上。
还需要在 hadoop04 上采用 hadoop 账号配置一下无密登录到 hadoop01、hadoop02、hadoop03、
hadoop04 服务器上。
还需要在 hadoop01 上采用 root 账号,配置一下无密登录到 hadoop01、hadoop02、hadoop03、
hadoop104;
2、配置 workers(在Hadoop01上操作)
cd /opt/module/hadoop-3.1.3/etc/hadoop/
编辑workers
vim workers
默认为localhost,删除localhost,插入以下内容:
hadoop01
hadoop02
hadoop03
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
3、格式化 NameNode
hdfs namenode -format
如果集群是第一次启动,需要在 hadoop 节点格式化 NameNode(注意:格式
化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找
不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停
止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式
化。)
4、启动 HDFS
/opt/module/hadoop-3.1.3/
sbin/start-dfs.sh
||-
.安装zookeeper
3.1、下载zookeeper
进入要下载的版本的目录,选择.tar.gz文件下载
下载链接:http://archive.apache.org/dist/zookeeper/
注意:点击进入之后,会显示zookeeper文件的下载目录,如图所示,显示了多个版本可以下载。alpha版本是内测,功能不是很完全的,能够满足一定的需要;beta是公测版本,基本上可以满足要求,可以适当的根据需要选择;如果是对稳定性要求非常高的话,最好是选择正式发布的版本。对于zookeeper版本一般来讲越新越好,也就是我们安装hbase的时候,可以使用新版本。这里我选择选择是版本是apache-zookeeper-3.6.3
3.2、上传zookeeper到Hadoop
打开Xshell,找到新建文件传输
找到已经下载的apache-zookeeper-3.6.3.tar.gz,并拖动到Hadoop窗口,完成之后关闭,并查看是否传输成功
使用下方命令解压apache-zookeeper-3.6.3.tar.gz到/opt/module/目录
tar -zxvf apache-zookeeper-3.6.3.tar.gz -C /opt/module/
3.3、配置修改
3.3.1、将/opt/module/zookeeper-3.5.7/conf这个路径下的zoo_sample.cfg修改为zoo.cfg;
cd opt/module/apache-zookeeper-3.6.3/conf/
mv zoo_sample.cfg zoo.cfg
3.3.2、打开zoo.cfg文件,修改dataDir路径:
打开zoo.cfg文件
vim zoo.cfg
修改如下内容:
dataDir=/opt/module/apache-zookeeper-3.6.3/zkData
3.3.3、在/opt/module/zookeeper-3.5.7/这个目录上创建zkData文件夹
mkdir zkData
3.4、操作Zookeeper
3.4.1、启动Zookeeper
bin/zkServer.sh start
总结
提示:这里对文章进行总结:
**




















































































































 991
991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











