







为什么需要指令重排序
其实说到底都是源于对性能的优化,CPU运行效率 相比缓存、内存、硬盘IO之间效率有着指数级的差别,CPU作为系统的宝贵资源,那么如何更好的优化和利用这个资源就能提升整个计算机系统的性能。
其实指令重排序就是一种来源于生活的优化思想,这种思想在生活中处处可见,就像平常咱们做菜,咱们会选择在炒第一个菜的同时就在洗第二个菜了, 咱们会把熟得最慢的菜放到最开始(比如煲汤),因为在等待这些菜熟的过程中(IO等待)咱们(CPU)还可以做其它事情,这就是一种时间上的优化,在计算机领域也是一样,它也会根据指令的类别做一些优化,目的就是把CPU的资源利用起来,这样就能就能提升整个计计算机的效率。
什么是指令重排序
java语言规范规定JVM线程内部维持顺序化语义。即只要程序的最终结果与它顺序化情况的结果相等,那么指令的**执行顺序可以与代码顺序不一致,此过程叫指令的重排序。**
指令重排序分类
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。
编译器优化重排序
编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序
指令级并行的重排序
现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
内存系统的重排
由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
重排序流如下图所示:
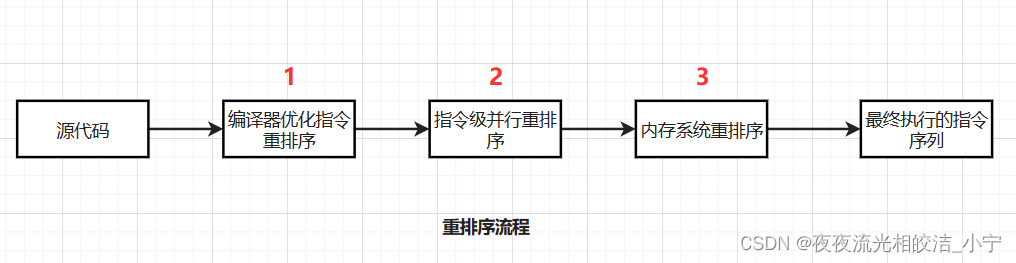
从java源代码到最终实际执行的指令序列,会分别经历下面三种重排序:
上述的1属于编译器重排序,2和3属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。
对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM的处理器重排序规则会要求java编译器在生成指令序列时,插入特定类型的内存屏障(memory barriers,intel称之为memory fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
指令重排序规范
① as-if-serial 规范
单个线程中, 指令的重排 , 不能影响程序的执行结果 ;
可以重排的情况 : 对于下面代码 , 两条指令顺序颠倒 , 执行结果相同 , 可以进行指令重排 ;
int a = 0;
int b = 10;不可以进行重排的情况 : 对于下面的代码 , 两条指令如果上下颠倒 , 结果不同 , 不可以进行指令重排 ;
int a = 0;
int b = a;不管怎么重排序,程序的执行结果不能被改变,编译器,runtime 和处理器都必须遵守as-if-serial语义。即编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作可能被编译器和处理器重排序。
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器,runtime 和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。
as-if-serial语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
② happens-before 规范
先行发生原则 。
happens-before 先行发生原则 :A happens-before B,A 先于 B 发生 , 先 A 后 B ;
Java 虚拟机在编译时和运行时 , 会对 JVM 指令进行重排优化 , 很明显 , 指令重排会对线程并发产生影响 ;
为了保证并发编程的安全性,这里规定了一些场景下 , 禁止在这些场景中 使用 指令重排 ;
happens-before 先行发生原则 适用场景 :
程序次序原则 : 在程序内 , 按照代码书写的执行顺序 , 前面的代码先执行 , 后面的代码后执行 ; 时间上 靠前 的操作先于时间上靠后 的操作执行。
管程锁规则 :不论是单线程还是多线程 , 线程 A 解锁后 , 线程 B 获取该锁 , 可以看到线程 A 的操作结果 ; 解锁的操作先于加锁的操作 ; 线程 B 要加锁 , 必须等待线程 A 解锁完毕才可以 ;
volatile 规则 :volatile 关键字修饰的变量 , 线程 A 对该变量的写操作 先于 线程 B 读取该变量的操作 , 线程 A 对该变量的写操作的结果对于线程 B 一定可见 ;
线程启动规则:线程的start()方法先于它的每一个动作,即如果线程A在执行线程B的start方法之前修改了共享变量的值,那么当线程B执行start方法时,线程A对共享变量的修改对线程B可见。
线程终止规则:线程的所有操作先于线程的终结,Thread.join()方法的作用是等待当前执行的线程终止。假设在线程B终止之前,修改了共享变量,线程A从线程B的join方法成功返回后,线程B对共享变量的修改将对线程A可见。
传递性: happens-before 规则具有传递性 ;如果 A happens-before B 和 B happens-before C ,则 A happens-before C ;
线程中断规则:对线程 interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测线程是否中断。
对象终结规则:对象的创建先于对象的终结,, 创建就是调用构造函数 , 终结就是调用finalize()方法
只要符合上述规则 , 不需要进行同步 , 就可以成立 ;
通过 " happens-before 先行发生原则 " 可以判定两个线程的操作 , 是否有发生冲突的可能 ;
重排序对于流水线的意义
现代CPU几乎都采用流水线机制加快指令的处理速度,一般来说,一条指令需要若干个CPU时钟周期处理,而通过流水线并行执行,可以在同等的时钟周期内执行若干条指令,具体做法简单地说就是把指令分为不同的执行周期,例如读取、寻址、解析、执行等步骤,并放在不同的元件中处理,同时在执行单元EU中,功能单元被分为不同的元件,例如加法元件、乘法元件、加载元件、存储元件等,可以进一步实现不同的计算并行执行。
流水线架构决定了指令应该被并行执行,而不是在顺序化模型中所认为的那样。重排序有利于充分使用流水线,进而达到超标量的效果。
如果觉得本文对您有帮助,欢迎点赞+收藏+关注!
















 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









