







数据库怎么实现的四大特性
https://www.jb51.net/article/161042.htm
- 原子性
原子性是根据undolog实现的,undo log名为回滚日志,是实现原子性的关键,当事务回滚时能够撤销所有已经成功执行的sql语句,他需要记录你要回滚的相应日志信息。同时
例如
(1)当你delete一条数据的时候,就需要记录这条数据的信息,回滚的时候,insert这条旧数据
(2)当你update一条数据的时候,就需要记录之前的旧值,回滚的时候,根据旧值执行update操作
(3)当年insert一条数据的时候,就需要这条记录的主键,回滚的时候,根据主键执行delete操作
undo log记录了这些回滚需要的信息,当事务执行失败或调用了rollback,导致事务需要回滚,便可以利用undo log中的信息将数据回滚到修改之前的样子。 - 一致性
一致性从两方面考虑,持久性首先在编码的时候要考虑,要满足一致性,其次一致性需要依赖数据库的原子性,持久性和隔离性。 - 隔离性
隔离性是通过锁和mvcc实现的,修改的时候通过锁,防止其他事务修改,快照读在一个事务内读取的数据是一致的,采用的是mvcc。 - 持久性
通过redolog实现的,redolog记录的物理日志,记录的是数据页的物理修改。force log at commit这个是redolog的罗盘策略,可以保证持久性,有三种策略,1s那个最多丢失1s的数据。
除了增加索引还有呢些数据库优化的手段
- 升级机器
- 数据量大的时候考虑分库分表
- 事务尤其是大事务,能避免就避免,因为对数据库性能影响大
- 不要用select * (因为有时候可能查询的字段在索引表上已经包含了,那么这时候就不需要回表了,其次,只查询部分字段数据库返回的数据也要少些,增加数据传输开销。还有就是首先要做解析,还有个解析的开销,所以不要用 就算查所有也不要用*)
- 尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了
count
执行效果上:
count(*):包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
count(1):包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
count(列名):只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
执行效率上:
列名为主键,count(列名)会比count(1)快;
列名不为主键,count(1)会比count(列名)快;
如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*);
如果有主键,则 select count(主键)的执行效率是最优的
如果表只有一个字段,则 select count(*)最优。
怎么优化慢sql
首先开启慢查询日志,找到对应sql,然后查看执行计划看看是否使用了索引,然后优化sql语句。
文件查找
- 从根目录开始查找所有扩展名为.log的文本文件,并找出包含”ERROR”的行,当然文件名也能找到
find / -type f -name “.log" | xargs grep “ERROR”
例子:从当前目录开始查找所有扩展名为.in的文本文件,并找出包含”thermcontact”的行
find . -name ".in” | xargs grep "thermcontact) - 总结 find 可以查找指定目录下的文件,可以模糊匹配比如用*或者?,如果想根据内容查询文件,那么用grep,grep后面加文本内容,xargs是前面的输出作为后面的输入。感觉可以不加。
- grep从文件内容查找与正则表达式匹配的行:
$ grep –e “正则表达式” 文件名
查找时不区分大小写:
$ grep –i “被查找的字符串” 文件名
查找匹配的行数:
$ grep -c “被查找的字符串” 文件名
从文件内容查找不匹配指定字符串的行:
$ grep –v “被查找的字符串” 文件名
String为什么加了final
**主要是防止strring被继承,保证String的不可变性,因为String设计就是不可变类,不可变类可以安全的被共享,保证线程安全。**同时只有当字符串是不可变的,字符串池才有可能实现,字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同一个字符串,如果字符串是可变的,当变量改变了它的值,那么其它指向这个值的变量的值也会一起改变,那么会引起很严重的安全问题。
从 安全和效率两方面考虑的
private、protected、default、public
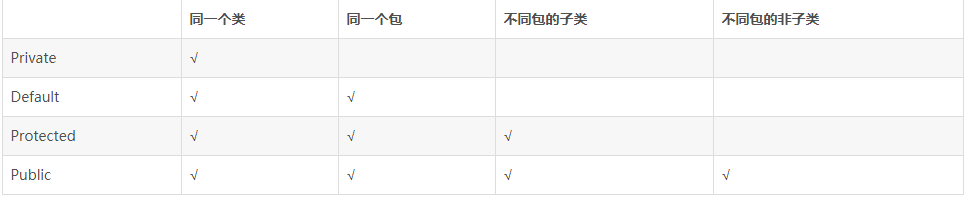
public:可以被所有其他类所访问
protected:自身、子类及同一个包中类可以访问
default:同一包中的类可以访问,声明时没有加修饰符,认为是friendly。
private:只能被自己访问和修改
关于单例模式
- 单例模式要素:
a.私有构造方法
b.私有静态引用指向自己实例
c.以自己实例为返回值的公有静态方法 - 其中私有构造方法可以防止被继承,因为继承的类如果使用要调用父类的构造方法,而父类的构造方法是私有的,无法被调用,也就防止了被继承
- 单例模式的应用场景:
主要是应用在一些共享资源,避免重复创建以及可以统一管理。例如线程池,数据库连接池,日志打印,回收站也是单例模式。
接口和抽象类
- 区别:
1.抽象类要背继承,接口要背实现
2可以实现多个接口,只能继承一个抽象类
3接口都是抽象方法且是public final abstract,抽象类可以不是抽象的方法
arraylist和linkedlist的区别
1.前者是数组实现的后者是链表实现的。
2.如果是随机访问,那么前者效率高于后者,可以通过索引随机访问
3.如果在尾部插入删除,二者效率差不多,但是如果在任意位置插入删除,后者效率高,因为arraylist可能涉及数组中元素的移动。
举个例子说说什么时候用接口什么时候用继承
接口是定义一些规范或者行为,后续实现她的类都要实现这些规范或者行为,而继承更多是继承父类的功能,在此基础上可以进行扩展。
就像自定义异常的时候,我们都是继承exception类,在此基础上实现自定义的异常,因为需要父类的一些属性和方法。还有像Runnable接口,他设计位接口就是要我们实现其中的方法,然后满足这种规范的类才能算任务。
arraylist的扩容流程
- 首先计算出原数组长度,然后扩1.5被,看看和需要的长度比是否足够,如果够了就用Arrays.copy方法把数据复制到新数组,容量就是扩容的容量。如果不够就用需要的容量当做新数组的容量,然后拷贝数据。 就是先求新数组的容量,然后拷贝数据。
add方法其实就是先判断是否需要扩容,然后直接加在尾部就行。
重载和重写
https://www.runoob.com/java/java-override-overload.html
多态好处
多态,同样一个行为有不同的表现形式。
提高了代码的扩展性,前期定义的代码可以使用后期的内容。这个重点。
linux命令
top:可以查看cpu和内存
df:查看磁盘信息,可以看已经用了多少,
du:就是看磁盘使用了多少,看某文件或某些文件的占用情况,和上面的不同,范围比上面小一半以上
netstat:查看端口占用情况,可以只显示listen,也可以显示所有。
lsof:也可以查端口
ping命令
ping使用的是网络层的ICMP协议。
ICMP协议是TCP/IP协议集中的一个子协议,属于网络层协议。
怎么跟踪路由器
windows有tracert 命令
linux traceroute
为什么使用自增id当主键
第一点:如果InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的,也就是下面这几种情况的存取效率最高:
-
使用自增列(INT/BIGINT类型)做主键,这时候写入顺序是自增的,和B+数叶子节点分裂顺序一致;
-
如果主键为自增 id 的话,mysql 在写满一个数据页的时候,直接申请另一个新数据页接着写就可以了。
如果主键是非自增 id,为了确保索引有序,mysql 就需要将每次插入的数据都放到合适的位置上。
第二点,因为非主键索引叶子节点存放的是主键值,我们应该尽量要主键占空间小,所以自增索引很合适,这样每个页存储的主键个数就增多,减少io次数。同时也减少了mysql空间占用。
大数据量表的分页查询怎么优化
如果使用传统的limit 那么会全表扫描,所以可以使用先限定出id,然后在in这些取数据,或者可以先找到那个偏移数据,找出大于他的然后排序(可选),然后直接用limit。反正就是别全表扫描和确定id范围。
spring
1.spring ioc管理的都是单例bean吗
没错,都是单例,多里的bean需要用的时候去new的。不是ioc管理的。
2.spring bean的生命周期和作用域
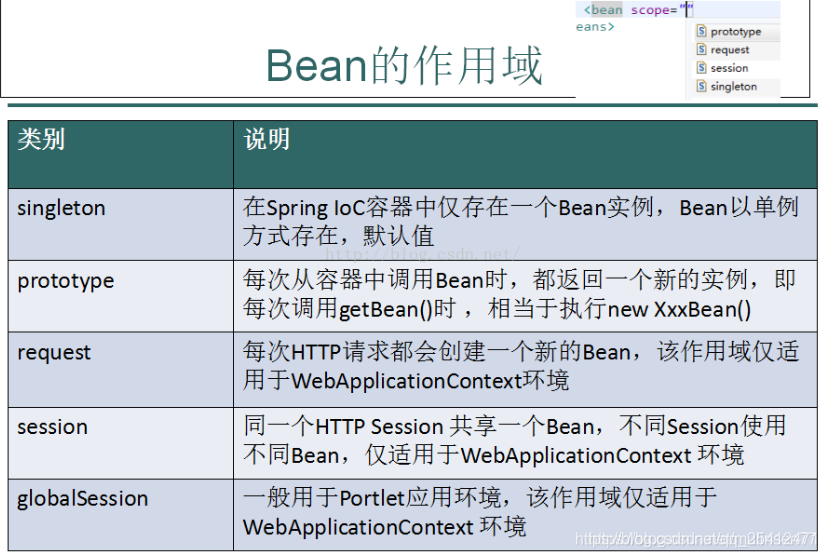
http://c.biancheng.net/view/4261.html
https://blog.csdn.net/mulinsen77/article/details/86135719
Bean 生命周期的整个执行过程描述如下。
1)根据配置情况调用 Bean 构造方法或工厂方法实例化 Bean。
2)利用依赖注入完成 Bean 中所有属性值的配置注入。
3)如果 Bean 实现了 BeanNameAware 接口,则 Spring 调用 Bean 的 setBeanName() 方法传入当前 Bean 的 id 值。
4)如果 Bean 实现了 BeanFactoryAware 接口,则 Spring 调用 setBeanFactory() 方法传入当前工厂实例的引用。
5)如果 Bean 实现了 ApplicationContextAware 接口,则 Spring 调用 setApplicationContext() 方法传入当前 ApplicationContext 实例的引用。
6)如果 BeanPostProcessor 和 Bean 关联,则 Spring 将调用该接口的预初始化方法 postProcessBeforeInitialzation() 对 Bean 进行加工操作,此处非常重要,Spring 的 AOP 就是利用它实现的。
7)如果 Bean 实现了 InitializingBean 接口,则 Spring 将调用 afterPropertiesSet() 方法。
8)如果在配置文件中通过 init-method 属性指定了初始化方法,则调用该初始化方法。
9)如果 BeanPostProcessor 和 Bean 关联,则 Spring 将调用该接口的初始化方法 postProcessAfterInitialization()。此时,Bean 已经可以被应用系统使用了。
10)如果在 中指定了该 Bean 的作用范围为 scope=“singleton”,则将该 Bean 放入 Spring IoC 的缓存池中,将触发 Spring 对该 Bean 的生命周期管理;如果在 中指定了该 Bean 的作用范围为 scope=“prototype”,则将该 Bean 交给调用者,调用者管理该 Bean 的生命周期,Spring 不再管理该 Bean。
11)如果 Bean 实现了 DisposableBean 接口,则 Spring 会调用 destory() 方法将 Spring 中的 Bean 销毁;如果在配置文件中通过 destory-method 属性指定了 Bean 的销毁方法,则 Spring 将调用该方法对 Bean 进行销毁。
Spring 为 Bean 提供了细致全面的生命周期过程,通过实现特定的接口或 的属性设置,都可以对 Bean 的生命周期过程产生影响。虽然可以随意配置 的属性,但是建议不要过多地使用 Bean 实现接口,因为这样会导致代码和 Spring 的聚合过于紧密。
@transaction注解原理
https://blog.csdn.net/qq_20597727/article/details/84868035?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.base&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.base
springboot启动原理
https://cloud.tencent.com/developer/article/1449134
myslq主从复制和延迟问题
- mysql主从复制是读写分离的基础,读写分离就是主库写,从库集群都,因为保证可用性,所以从库最好用集群,但是主从复制会有延迟的问题,
- 还有就是主从复制涉及了三个线程,分别是主库创建一个线程写binlog到从库,从库有两个线程,分别是一个io线程用于接受主库的binlog并写入realy log(中继日志),第二个是sql线程,执行binlog中的sql。
- 还有一点,主库写binlog是顺序写,从库读到中继日志也是顺序都然后顺序写入的,但是执行却是随机的,我解释一下这个随机。他是物理随机,顺序也是物理上直接顺序写。
比如现在对orderid=1和orderid=100的记录进行更新。Master写入bin log的顺序是orderid=1,orderid=100,直接向后append就可以了,Salve读取也是这个顺序,但是在实际执行更新数据时,可能就需要先去磁盘A扇区去更新orderid=1,然后再去磁盘B扇区更新orderid=100,完全是随机操作,效率会很低。 - 5.6中可以并发执行,也就是并发执行随机操作。但是前提是不同scheme 也就是不同库,5.8又改进了一下,不再是只有不同库的表可以并发执行了。
- 剩下最后一个问题,延迟问题,解决方法:
1.分库分表,提高每个库的性能。
2.提高硬件
3.就是上面的并行 - 还有一个问题,数据的一致性怎么办?
可以使用半同步复制,也就是至少写道一个salve上这个事务才算成功,这样如果主服务器挡掉,选最新事务的当主服务器就行了,同时也保证了数据的一致性,但是,他也是有延迟了。读从库还是可能有一点点延迟,所以如果对数据读取要求严格的,不要使用读写分离。但是如果改用raft那样 半数以上应该可行把。。。但是这个我也不确定了。
补充一下关于联合主键
顺序是要考虑的,区分性大的放在前面。
sql的执行顺序
- from
- join
- on
- where
- group by(开始使用select中的别名,后面的语句中都可以使用)
- avg,sum… (经过测试发现,avg 和 sum统计的时候会忽略空。。。求平均不会计算数)
- having (可以使用聚合函数,筛选的是group by分组后的每行数据)
- select
- distinct
- order by(select查出来的数据进行排序)
- limit
sql一些小东西
1.YEAR MONTH DAY函数
通过这几个函数可以获得年份 月份 天号
2.外键
- 1 被约束的表称为副表,约束别人的表称为主表,外键设置在副表上的。
- 2 主表被参考的字段通常都设置为主键
- 3 当有外键约束的时候,添加数据的顺序:先加主表,再添加副表的数据
- 4 当有外键约束的时候,修改数据的顺序:先修改副表,再修改主表的数据
- 5 当有外键约束的时候,删除数据的顺序:先删除副表,再删除主表的数据
如果想修改主表 从表也改就用级联操作:在最后加ON UPDATE CASCADE ,正常来说,是不能先修改主表的,因为被外键约束,要先修改从表。
3.union 表的连接 水平上的。
https://www.cnblogs.com/phpper/p/8035710.html
看这个就够了 主要是记住union和union all的区别,后者效率高,但是不会去重
4.各种连接
内连接 :就是我们平时用的,没啥说的
外连接:左外连接和右外连接
https://blog.csdn.net/Yeoman92/article/details/52781932 看这个 不错 尤其是为啥on和where的区别














 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









