









初学者眼中的 MySQL
对于我们中的许多人来说,MySQL是这样的:
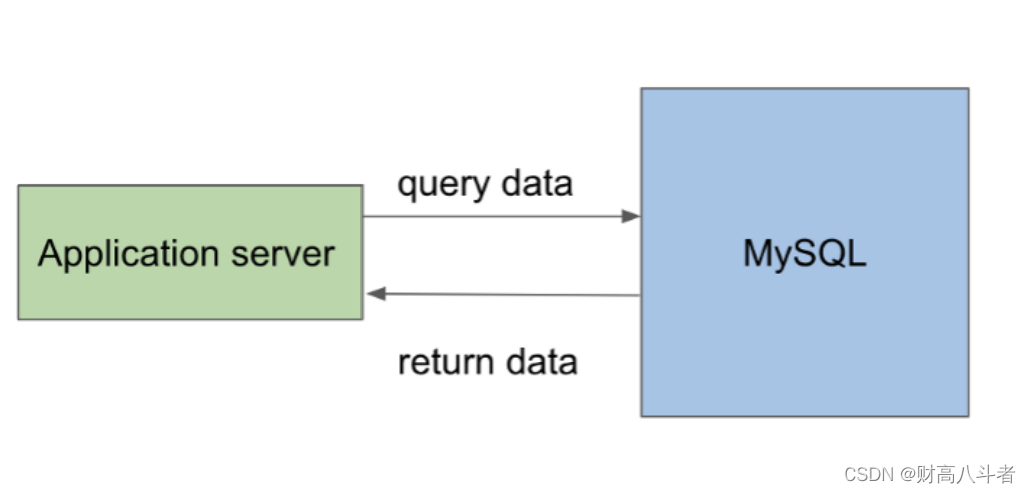
嗯,看起来很简单。MySQL 如何在后台处理 SQL 查询?换句话说,工程师和数据科学家编写的SQL查询通常以纯字符串的形式发送到MySQL。MySQL如何解释这个字符串,并知道要查找哪个表以及要获取哪些行?
连接池
就像您浏览此页面时一样,网络浏览器(chrome,safari)会保持与Medium的连接。同样,我们的应用程序服务器需要连接到 MySQL 服务器才能发送 SQL 查询字符串。连接池通常用于管理互联网连接。
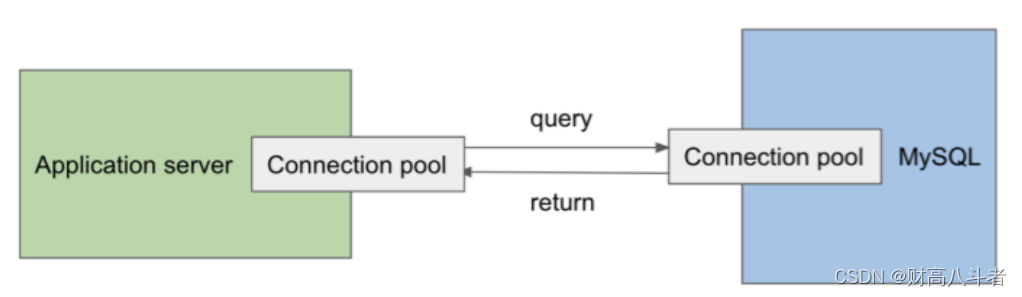
连接池允许重用现有的互联网连接,避免创建新连接的启动和清理开销成本。此外,用户身份验证也可以内置到此层中,拒绝未经授权的数据库访问。
每个连接通常映射到一个线程。处理 SQL 查询请求时,应用程序服务器中的线程将从池中取出连接,向 MySQL 服务器发送请求。MySQL 服务器中的另一个线程将接收 SQL 字符串格式的请求,并执行后续步骤。
那么后续步骤是什么?
SQL 解析器
MySQL服务器需要了解查询试图做什么。是尝试读取某些数据、更新数据还是删除数据?
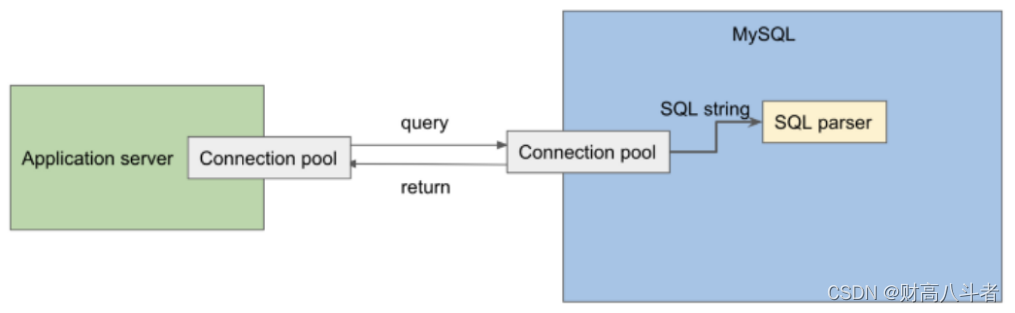
收到查询后,首先需要对其进行解析,这涉及将其从本质上是文本格式的格式转换为内部二进制结构的组合,优化程序可以轻松操作这些结构。
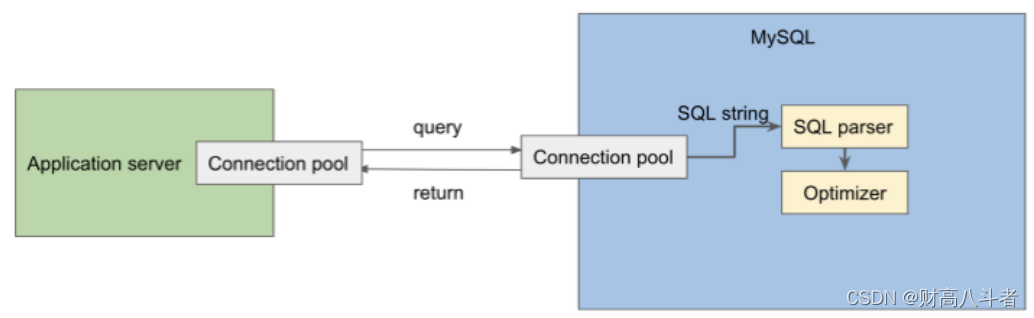
查询优化器
在MySQL执行查询之前,它确定如何完成查询,即什么是最佳方法。
例如,你要出去参加一个大家庭旅行。每个人都坐在车里,准备离开。但是你突然意识到忘了带20瓶水。你很快想起所有的瓶装水都在你的储藏室里,你真的需要尽快把它们弄到你的车上,因为人们在等你。你开始思考。每次可以用手带4瓶,来回跑5次。或者你可以随身携带一个盒子,把所有20瓶放在盒子里,然后把它们一起带到车上,没有来回。这就是优化器所做的。它分析了满足请求的不同方法,并选择了最优化的方法。
让我们看一个简单的SQL查询:
从employee_table中选择名称,其中 employee_id = 1;
假设employee_table有 10k 条员工记录。至少有两种方法(或两个使用正式术语的计划):
- 计划1:扫描名称列中的所有名称,对于每个名称,检查employee_id是否为1,并且仅在其employee_id= 1时才返回名称。
- 方案二:使用主索引查找employee_id = 1的记录,并返回名称。
解析器分析方法 2 是更快的,优化器决定使用方法 2。
下一步实际上是执行计划。
执行引擎
执行引擎将调用存储引擎的 API 来执行查询优化器确定的计划。
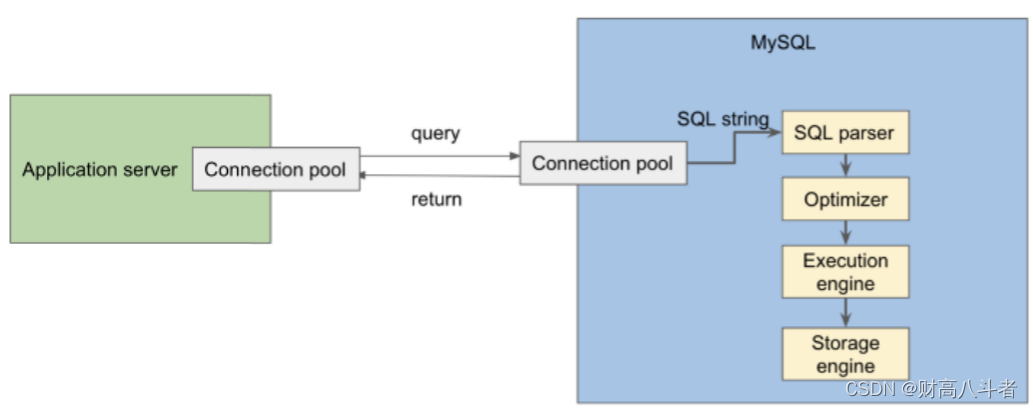
存储引擎
大多数软件系统可以分为计算层和存储层。计算层的效率在很大程度上取决于数据在存储层中的组织方式。在本节中,让我们深入了解 MySQL 的存储引擎,以及许多精心设计的优化,以加快读/写速度。
MySQL可以与许多不同的存储引擎集成。对于不同的用例,每个存储引擎都有自己的一套优缺点。换句话说,存储引擎可以被视为一个接口,并且可以具有不同的底层实现。例如,有InnoDB,MyISAM,Memory,CSV,Archive,Merge,Blackhole。
InnoDB肯定是使用最广泛的。这是自MySQL 5.5版本以来的默认设置。
就像我们的笔记本电脑一样,InnoDB将数据存储在内存和磁盘上。高级别而言,当写入InnoDB时,数据总是首先缓存在内存中,然后再保存到磁盘。
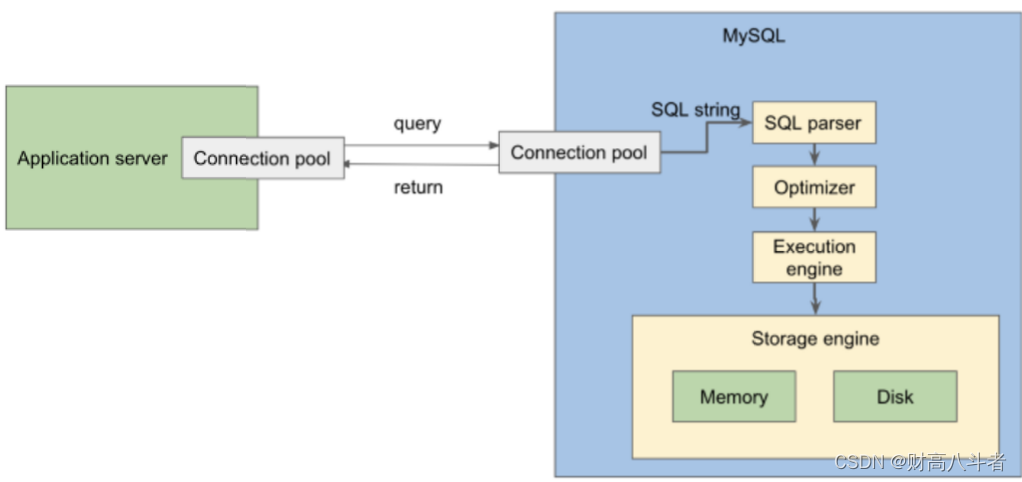
InnoDB将内存分为两个组件:
- 缓冲池
- 日志缓冲区
缓冲池对于InnoDB非常重要。MySQL在处理查询方面通常非常快,原因是数据实际上是从内存存储和提供的(在大多数情况下不是从磁盘,与许多人的想法相反)。此内存组件是缓冲池。
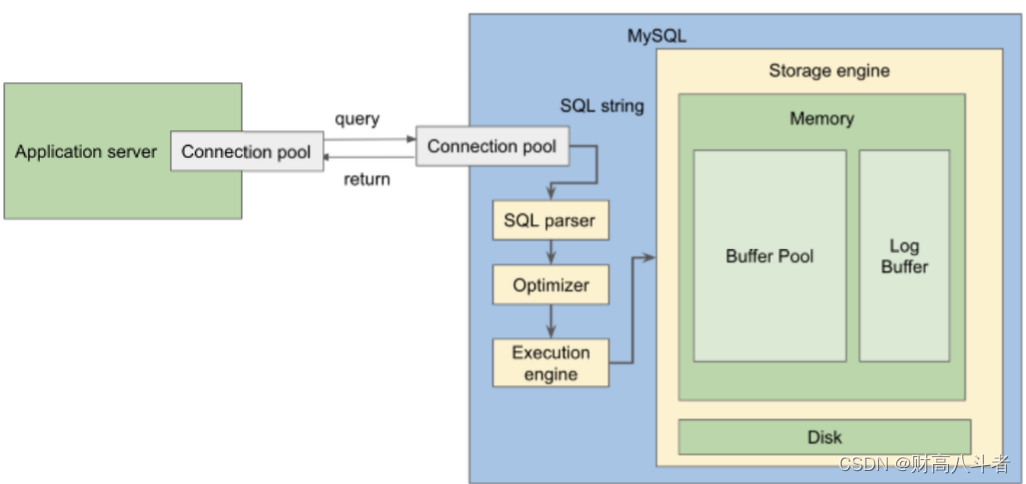
缓冲池
通常,主机的 80% 内存分配给缓冲池。更大的内存意味着更多的数据存储在内存中,因此读取速度更快。
除了简单地将数据放入内存之外,缓冲池还根据数据在内存中的组织方式进行了精心设计,以加快数据库的读取和写入速度。让我们进一步深入了解这个详细设计。
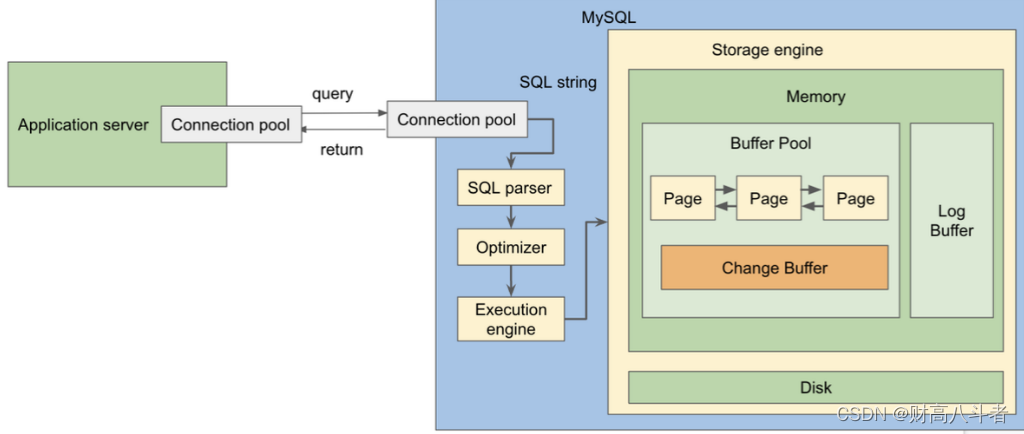
页(page)
与使用 ID 很好地组织书籍并按字母或数字顺序放置在图书馆书架上的方式类似,缓冲池以类似的顺序组织数据。
InnoDB将缓冲池划分为许多页面,以及一个更改缓冲区(稍后将说明)。所有页面都作为双向链接列表链接,也就是说,您可以轻松地从当前页面到达下一页,或者向后返回。
现在,数据如何存储在页面中?
用户记录(User Records)
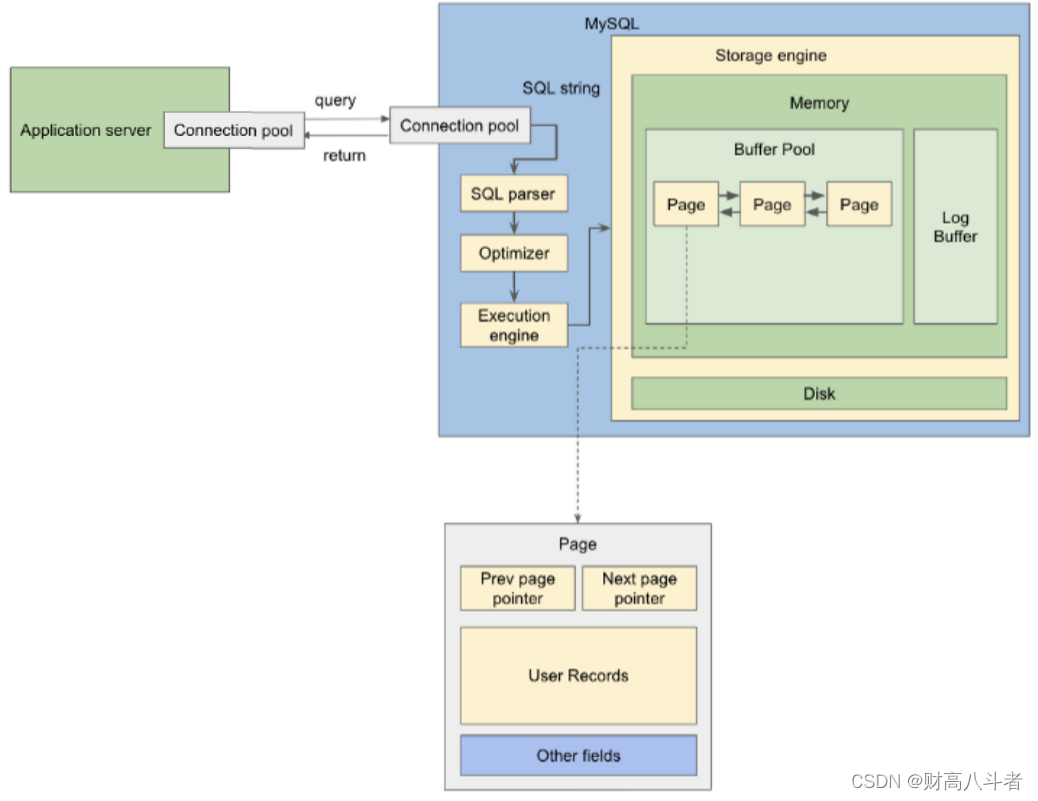
在页面中,有:
- 指向上一页的指针
- 指向下一页的指针
- 用户记录
- 其他领域
指向上一页和下一页的指针就是指针。用户记录是存储每个“行”数据的位置。每行都有一个指向下一行的下一个指针,形成一个单向链表。
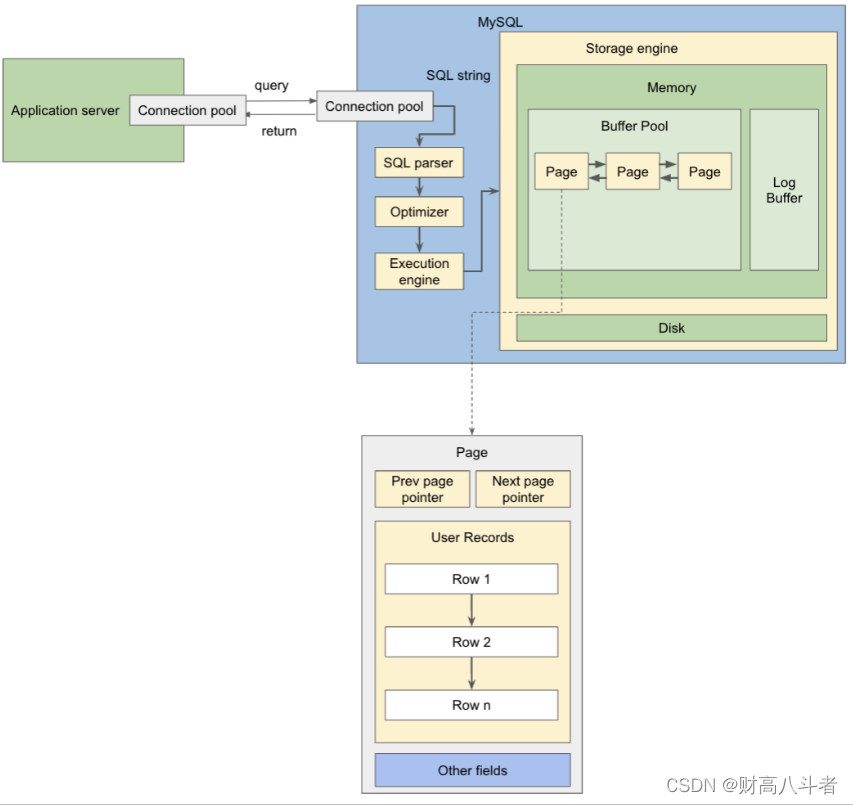
我们知道 SQL 数据库中的行通常由主键和许多其他字段组成。行通常按主键排序,以便二进制搜索等算法可用于在查找具有特定键的行时加快读取延迟。但是,如果每次我们向用户记录添加新行时,InnoDB都需要重新排列所有记录(行)以保持顺序,那将非常慢。
实际上,用户记录中的行是按其插入顺序排列的。添加新记录仅意味着追加到用户记录的末尾。主键的所需顺序是通过“next”指针实现的。每行的下一个指针根据主键顺序指向下一个逻辑行,而不是物理上指向内存上的下一行。
现在又来了一个问题。我们之前提到过,没有必要遍历所有行来查找具有特定主键的目标行。但是,如果所有行本质上都是单向链表,则单向链表的属性决定了我们只能通过遍历整个列表来找到特定的行。我们知道列表遍历列表是O(n)时间并且非常慢。那么InnoDB如何使其更快呢?
Infimum和Supremum
这两个字段分别表示页面中的最大行和最小行。换句话说,两者形成最小-最大滤波器。通过在O(1)时间内检查这两个字段,InnoDB可以决定要查找的行是否存储在此特定页面中。
例如,假设我们的主键是数字,并且对于特定页面,我们有上确界 = 1,下确界 = 99。如果我们试图寻找主键 = 101 的行,那么很明显在 O(1) 时间内,InnoDB 决定它不在此页面中,并将转到另一个页面。
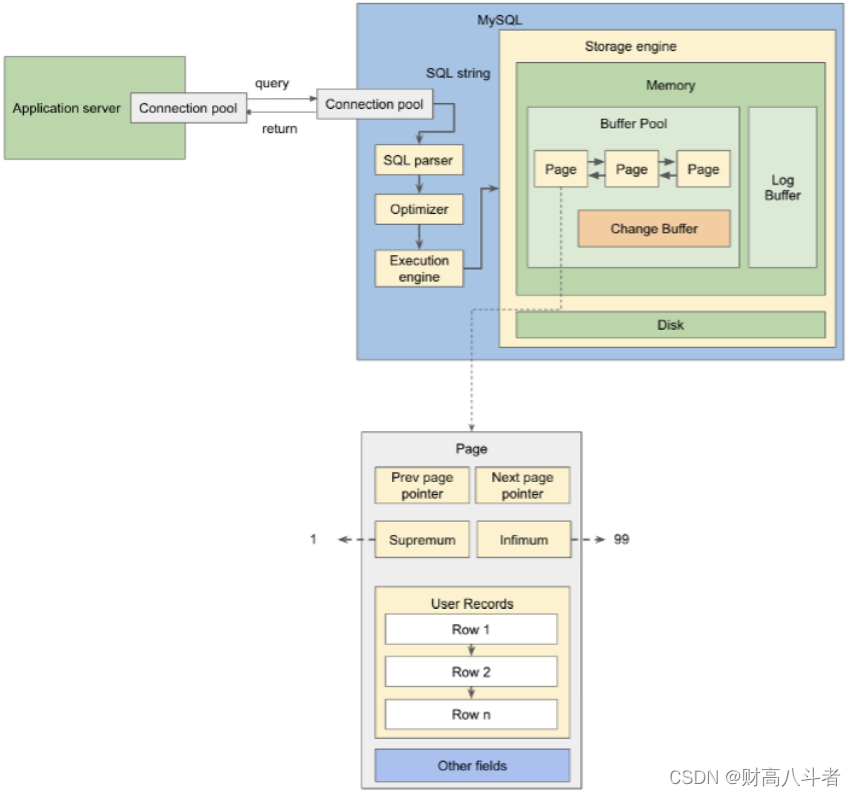
现在,如果目标行不在页面中,InnoDB 将跳过该页面。但是,如果该行实际上在页面中,InnoDB 是否仍会遍历整个列表?答案是否定的,“其他领域”再次派上用场。
页面目录(Page directory)
顾名思义,它就像一本书的“目录”。
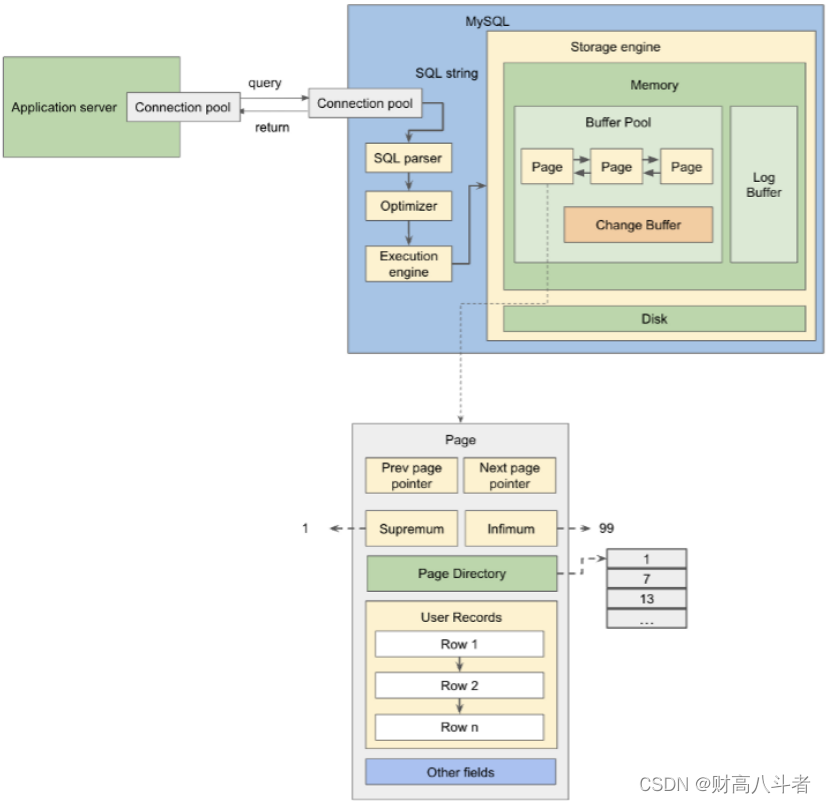
页面目录存储指向行块的指针。假设我们在用户记录中存储了第 1 到 n 行,页面目录将有指向第 1 行、第 7 行、第 13 行的指针......,块大小为 6。此设计与跳过列表非常相似。
正如您现在可以想象的那样,InnoDB首先检查页面目录,并快速确定要查找的块。然后利用指针跳转到单向链表中的相应行,并从那里开始遍历。通过这种方式,InnoDB避免遍历整个列表,并且需要遍历更小的子列表。
我们上面提到的区块正式名称为老虎机。页面目录有多个插槽,每个插槽都有一个指向用户记录中行的指针。
每次将新行插入用户记录时,InnoDB也会更新页面目录,以使两者彼此一致。InnoDB为每6行创建一个插槽。
索引(Index)
InnoDB使用B +树(读作“B加树”)进行数据存储。MySQL支持两种类型的索引:主索引和二级索引。一旦我们理解了页面的概念,索引就变得显而易见了。
主索引的叶节点存储“页面”
相反,二级索引的叶节点存储主键。当查询命中二级索引时,首先从二级索引中检索主键。一旦我们知道主键,就会使用主索引检索目标行。
关于为什么使用B+树而不是B树(B树,而不是B减树):
- B+ 树减少了所需的 IO 操作
- 查询效率更稳定
- 可以更好地支持范围查询
所有这些带有单链接用户记录,下确界和页面目录的漂亮设计主要用于加快阅读速度。当我们想要更新一行时会发生什么?现在让我们来看看MySQL如何处理数据更新。
更新数据
当我们在 MySQL 中插入一行时,比如说 id = 100,然后如果立即需要更新这一行,它通常仍保留在缓冲池中。
但是,如果我们等待相当长一段时间,然后更新此行,则此行 id = 100 可能不再位于缓冲池中。
原因是内存有限,我们不能继续向内存插入行,内存很快就会填满。清除策略(通常指定为 ttl(生存时间))用于清理内存空间。例如,Redis 通常用作缓存,Redis 中的 ttl 表示密钥被删除(标记为已删除且不会显示为已读取,然后后台进程实际上批量删除它们)。在MySQL的情况下,数据需要持久化。MySQL中的清除意味着保留到磁盘并从内存中删除。
因此,当尝试更新一行时,如果该行不在缓冲池中,InnoDB 会将数据从磁盘加载回缓冲池。这里的问题是,InnoDB 不能只加载 id=100 的单行,它需要加载包含此行的整个页面。当整个页面加载到缓冲池时,可以更新特定行。
目前为止,一切都好。但这只描述了主索引的更新,二级索引呢?
更改缓冲区
假设我们更新了行 id = 100 的某些字段。如果二级索引是在其中一个字段上构建的,则需要同时更新二级索引。但是,如果包含二级索引的页面不在缓冲池中,那么InnoDB是否也会将页面加载到缓冲池中?
如果以后不打算使用二级索引,而是每次更新相关字段时都急切地加载到缓冲池中,就会有大量随机的磁盘 I/O 操作,这不可避免地会减慢 InnoDB 的速度。
这就是更改缓冲区被设计为“懒惰地”更新二级索引的原因。
当二级索引需要更新,并且包含它的页面不在缓冲池中时,更新将临时存储在更改缓冲区中。稍后,如果页面加载到缓冲池中(由于主索引的更新),InnoDB会将更改缓冲区中的临时更改合并到缓冲池中的页面。
不过,这种更改缓冲区设计有一个缺点。如果更改缓冲区积累了大量的临时更改,并且说我们想一次将其与缓冲池合并,则可能需要数小时才能完成!!而且在这次合并过程中,会有很多磁盘 I/O,占用 CPU 周期,影响 MySQL 的整体性能。
因此,进一步进行了一些权衡。我们之前提到,当包含二级索引的页面加载回缓冲池时,会触发合并。在InnoDB设计中,合并也可以由其他事件触发,以避免可能需要几个小时的大型合并。这些事件包括事务、服务器关闭和服务器重新启动。
自适应哈希索引
自适应哈希索引旨在与缓冲池协同工作。自适应哈希索引使性能更像内存数据库。自适应哈希索引由变量启用,或在服务器启动时关闭。InnoDB
innodb_adaptive_hash_index
--skip-innodb-adaptive-hash-index















 2259
2259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









