







一、Java常见编码
在Java程序中最常见的是ISO8859-1、GBK/GB2312、unicode、UTF编码。
①. ISO8859-1:属于单字节编码,最多只能表示0~255的字符范围,主要在英文上应用。Tomcat服务默认编码方式是ISO8859-1。
②. GBK/GB2312:中文的国际编码,专门用于表示汉字,是双字节编码,如果在此中出现中文,则使用GBK。GBK表示简体中文和繁体中文,而GB2312只能表示简体中文。
③. unicode:Java中使用此编码,标准编码,使用十六进制表示,此编码不兼容ISO8859-1编码。
④. UTF:由于unicode不支持ISO8859-1编码,而且容易占用更多的空间,而且对于英文字母也需要两个字节编码,使用unicode不便于传输和存储,因此产生了UTF编码。
UTF编码是不定长编码,每个字符的长度为1~6个字节不等,一般在中文网页中使用此编码,可以节约空间。
二、得到本地的编码显示
使用System类可以取得与系统有关的信息,所以直接使用此类即可找到系统的默认编码,使用如下方法:
public static Properties getProperty().
范例:得到JVM的默认编码
System.out.println("系统默认编码:" + System.getProperty("file.encoding"));三、乱码产生
File file = new File("e:\\utf.txt");
// 使用utf-8编码写入文件
BufferedWriter out = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(file), "UTF-8"));
out.write("你好");
out.close();
// 用gbk编码进行解码,会出现乱码
BufferedReader in = new BufferedReader(new InputStreamReader(
new FileInputStream(file), "GBK"));
String line = in.readLine();
System.out.println(line);
// 在此使用utf-8编码,得到原文
byte[] bytes = line.getBytes("GBK");
System.out.println(new String(bytes, "UTF-8"));
程序中涉及编码转换过程
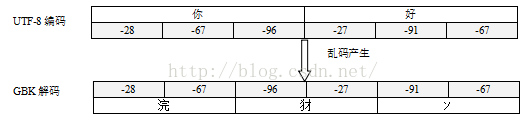
从上图可以看到,由UTF-8编码写入文件的数据通过GBK解码之后,如后产生了乱码。因为UTF-8是可变长度的,那么用UTF-8解码文件时,怎么知道几个字节表示一个字符呢?原来UTF-8编码时每个字节的高位部分都有表示头,如果一个字节高位是0开头,表示1个字节表示1个字符。如果一个字节的高位是以110开头,则表示2个字节表示一个字符,应该再往后找1个以10开头的字节。字节高位是10表示前面还有字节。如果一个字节高位是1110,则表示3个字节表示一个字符,应该再往后找2个以10开头的字节。如图所示:

程序中用GBK编码来解决UTF-8编码“你好”就会出现乱码,因为GBK编码无论是字母还是汉字都占2个字节,它在解码时就会按顺序2个字符解码为一个字符,刚好-28 -67在GBK编码中是汉字“浣”,-96 -27是“犲”,-91 -67是“ソ”,如果对应位置GBK表中没有字符可能显示“?”(ISO8859),所以用什么编码就用什么解码。
乱码还能恢复原来的内容吗?这是肯定的,因为只是解码时出现问题,文件并没有改变,还是这些01二进制。















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









