



1. 痛点:被“写放大”拖垮的数据库
在对接企业微信、3-chat 等第三方 IM 系统时,核心挑战往往不在于消息的接收,而在于如何高效地处理随之而来的海量状态更新。
业务场景中常见的一环是:每当收到一条新消息,都需要更新对应会话(Session)的 last_active_time(最后活跃时间)和 digest(最新消息摘要)。
这里存在一个隐蔽的性能杀手:
在群聊活跃或消息洪峰场景下,如果每一条消息都直接触发一次数据库 UPDATE 操作,将导致严重的写放大(Write Amplification)。例如,当成百上千个群聊同时活跃,数据库的 TPS 会瞬间飙升。然而,绝大多数的中间状态更新在业务上是冗余的——对于一个 1 秒内产生 10 条消息的群,我们其实只需要持久化最后那一瞬间的状态。
本文将介绍一种“高效且优雅”的解决方案。不依赖 Redis 等外部复杂组件,仅利用 Java 原生的 LinkedHashMap 特性配合 NATS,构建一个具备全局防抖(Global Debounce)和容量保护的写缓冲机制,将数据库的写压力降低一个数量级以上。
2. 架构设计:时空双重触发机制
为了解决高频写问题,架构上采用了**“写缓冲(Write-Behind)”**模式。我们构建了一个全局的内存缓冲区,其落库策略由“时间”和“空间”两个维度共同控制。
数据流向图
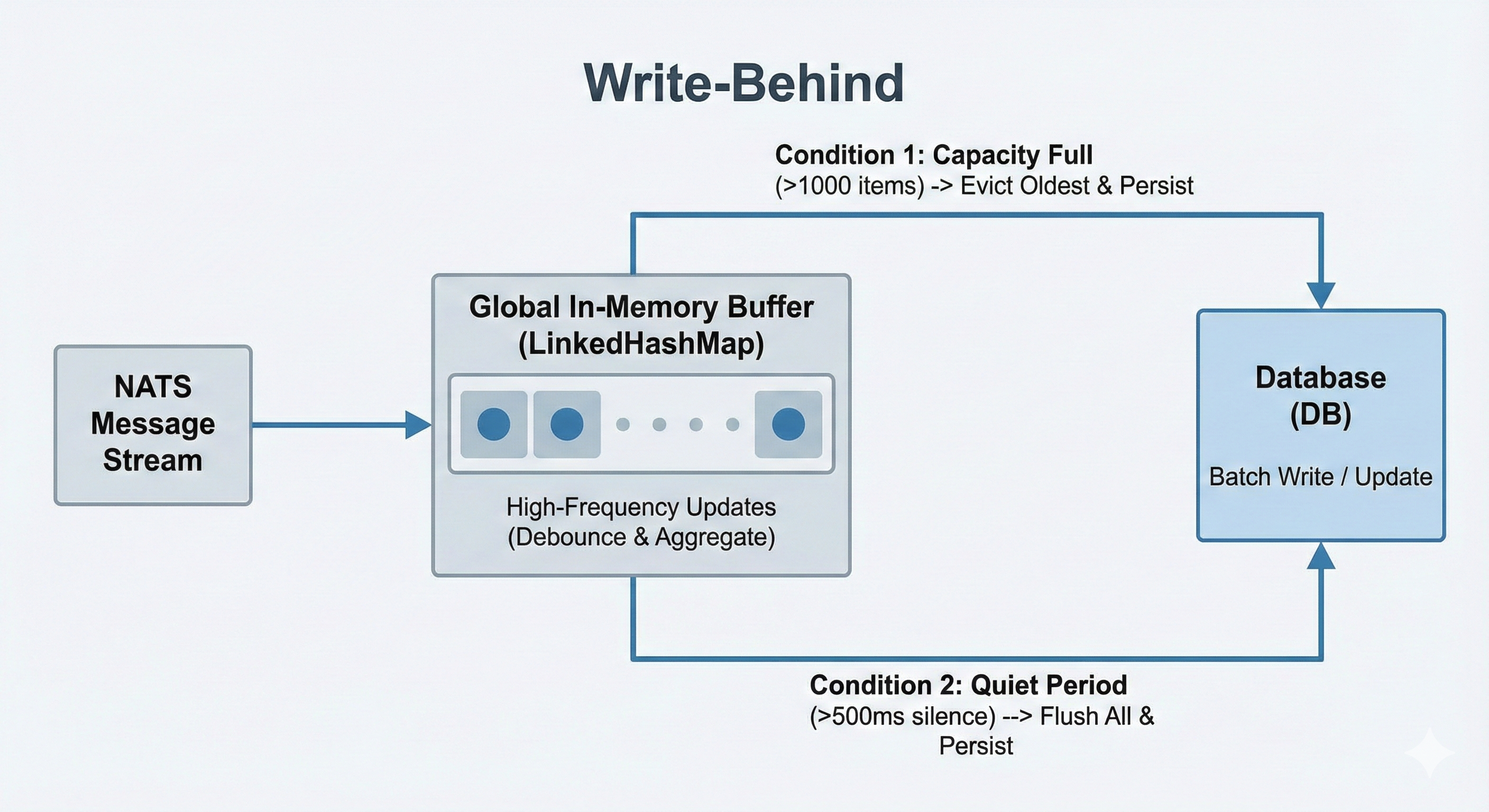
(注:实际逻辑中,时间触发是基于“静默期”的防抖)
核心策略
-
时间维度(全局防抖):
系统并不针对单个会话计时,而是维护一个全局定时器。只要有任意一条新消息进入系统,就会重置该定时器。- 忙碌期:消息源源不断,定时器无限推迟,完全依靠内存合并更新。
- 静默期:系统安静超过 500ms,触发批量落库。
-
空间维度(容量保护):
为了防止内存溢出(OOM),设置缓冲区容量上限(如 1000)。当活跃会话数超过阈值时,不再等待定时器,而是强制将最久未更新的会话“挤出”并落库。
3. 核心代码实现
以下是基于 Spring Boot 和 NATS 的完整实现逻辑。
@Slf4j
@Component
public class SessionUpdateListener implements NatsConsumer {
// === 配置常量 ===
private static final long FLUSH_INTERVAL_MS = 500; // 防抖静默时间
private static final int MAX_PENDING_SIZE = 1000; // 内存容量上限
private final SessionUpdateService sessionUpdateService;
// === 核心数据结构 ===
// LinkedHashMap(initialCapacity, loadFactor, accessOrder)
// accessOrder=true: 开启 LRU 模式,最久未访问的元素在链表头部
private final LinkedHashMap<String, SessionUpdateEvent> pendingUpdates =
new LinkedHashMap<>(16, 0.75f, true);
private final Object lock = new Object();
// 使用虚拟线程处理 I/O 密集型任务 (Java 21+)
private final ScheduledExecutorService scheduler = Executors.newSingleThreadScheduledExecutor(
Thread.ofVirtual().name("session-flush-", 0).factory());
private ScheduledFuture<?> flushTask;
// ... 构造函数 ...
@Override
public void onMessage(Message msg) {
// ... 解析 logic ...
String sessionKey = event.getSessionKey();
synchronized (lock) {
// 1. 【空间防御】容量已满?挤出最旧的!
// 如果是新 Key 且 Map 满了,先腾地儿
if (pendingUpdates.size() >= MAX_PENDING_SIZE && !pendingUpdates.containsKey(sessionKey)) {
evictOldest();
}
// 2. 【数据合并】利用 Map 特性
// accessOrder=true 会自动将该 key 移到链表尾部(表示最近活跃)
pendingUpdates.compute(sessionKey, (key, existing) -> {
// 如果内存中已有的数据比当前还要新(乱序情况),则忽略当前数据
if (existing != null && existing.getTimestamp() > event.getTimestamp()) {
return existing;
}
return event;
});
// 3. 【时间防抖】重置看门狗
resetFlushTask();
}
}
/**
* 重置刷新定时器 (Debounce 逻辑)
*/
private void resetFlushTask() {
if (flushTask != null && !flushTask.isDone()) {
flushTask.cancel(false);
}
// 只有当系统静默 FLUSH_INTERVAL_MS 后,才会执行 flushAll
flushTask = scheduler.schedule(this::flushAll, FLUSH_INTERVAL_MS, TimeUnit.MILLISECONDS);
}
/**
* 挤出最久未更新的记录入库
*/
private void evictOldest() {
Iterator<Map.Entry<String, SessionUpdateEvent>> iterator = pendingUpdates.entrySet().iterator();
if (iterator.hasNext()) {
Map.Entry<String, SessionUpdateEvent> oldest = iterator.next();
iterator.remove(); // 从内存移除
persistEvent(oldest.getValue()); // 强制入库
log.debug("Evicted oldest session: {}", oldest.getKey());
}
}
/**
* 批量刷新:将 Map 中所有数据入库并清空
*/
private void flushAll() {
List<SessionUpdateEvent> events;
synchronized (lock) {
if (pendingUpdates.isEmpty()) return;
events = new ArrayList<>(pendingUpdates.values());
pendingUpdates.clear();
}
// 注意:持久化操作必须放在锁外,避免阻塞消息接收
for (SessionUpdateEvent event : events) {
persistEvent(event);
}
}
// ... persistEvent 具体入库逻辑 ...
}
4. 深度解析:为什么这样设计?
4.1 全局聚合与 LRU 的精妙结合
代码中 new LinkedHashMap<>(16, 0.75f, true) 的 true 是点睛之笔。
- 多会话聚合:这是一个全局容器。无论系统中有多少个群组在发消息,只要
sessionKey相同,新的更新就会覆盖旧的。内存中永远只保留最新的一条。 - LRU 有序性:链表的头部始终是所有缓存会话中“最久没有动静”的那一个。当内存紧张时,优先处理它是最合理的策略。
4.2 拒绝 OOM 的“安全阀”
⚠️ 警告:无界 Map 是生产事故的温床
很多初级实现在做缓冲时,喜欢用不限制大小的 Map。一旦数据库写入变慢,或者遭遇突发流量(如万人群刷屏),生产速度远大于消费速度,内存会无限膨胀,最终导致 OOM (Out Of Memory)。
本方案通过 MAX_PENDING_SIZE = 1000 设置了绝对防线。当达到 1000 条时,不再等待定时器,而是强制将链表头部(最冷门的会话)挤出并入库。这确保了无论上游消息量多大,服务占用的堆内存始终恒定。
4.3 全局动态防抖(Global Debounce)
我们采用的是“看门狗”式的全局防抖:
- 忙碌时:在消息高峰期(间隔 < 500ms),定时器被无限推迟,永远不会触发。系统完全依靠 Map 的“合并”能力消化更新,仅靠容量限制(Step 4.2)零星落库。
- 空闲时:一旦消息流断开(静默 > 500ms),定时器立即触发
flushAll,确保数据最终一致性。
4.4 虚拟线程与锁粒度
- 锁粒度:
synchronized (lock)仅保护内存 Map 的操作(纳秒级)。 - 非阻塞 I/O:耗时的
persistEvent(数据库 I/O)被严格移至锁外执行。 - 虚拟线程:利用 Java 21+ 的
Thread.ofVirtual()执行定时任务,相比传统线程池,在处理这种 I/O 挂起型任务时更加轻量。
5. 总结
在高并发系统的设计中,“克制”比“速度”更重要。
通过结合 LinkedHashMap 的 LRU 特性、全局防抖机制以及严格的容量控制,我们实现了一个健壮的“写缓冲”层。它像一个水库,在洪水期(高并发)蓄水调峰,在枯水期(低并发)平稳排放。
这种既能大幅降低数据库负载,又能严格保证内存安全的设计,才是真正“高效且优雅”的架构实践。

















 1156
1156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









