









Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
因此,搭建solr之前,首先需要安装jdk1.8和Web 应用服务器。这里我们使用tomcat 8.0。
一、Solr单机版安装步骤
准备工作:
目前最新版本6.0.下载solr 6.0:点击下载
JDK8 下载jdk1.8:点击下载
tomcat8.0 下载:点击下载
步骤一:安装jdk,解压tomcat
步骤二:上传solr-6.0.1.tgz到服务器上并解压
scp solr-6.0.1.tgz muxiaocao@192.168.3.111:~/toolstar -zxvf solr-6.0.1.tgz步骤三:将
solr-6.0.1\server\solr-webapp下的webapp文件拷贝到apache-tomcat-8.0.35\webapps目录下.cp solr-6.0.1/server/solr-webapp apache-tomcat-8.0.35/webapps/solr
步骤四:将
solr-6.0.1\server\lib\ext下的所有jar包拷贝到apache-tomcat-8.0.35\webapps\solr\WEB-INF\libcp solr-6.0.1/server/lib/ext/*.jar apache-tomcat-8.0.35/webapps/solr/WEB-INF/lib/步骤五:在根目录下创建solrhome文件,并将
solr-6.0.1/server/solr下的所有文件拷贝到solrhomemkdir solrhomecp solr-6.0.1/server/solr/* solrhome/ -r
步骤六:修改
apache-tomcat-8.0.33\webapps\solr\WEB-INF下的web.xml文件,找到如下代码:
将他们放开注解,并将其中的value改成
/home/muxiaocao/solr/solrhome步骤七:运行tomcat,成功后访问
http://localhost:8080/solr/index.html./apache-tomcat-8.0.35/bin/startup.shtail apache-tomcat-8.0.35/logs/catalina.out
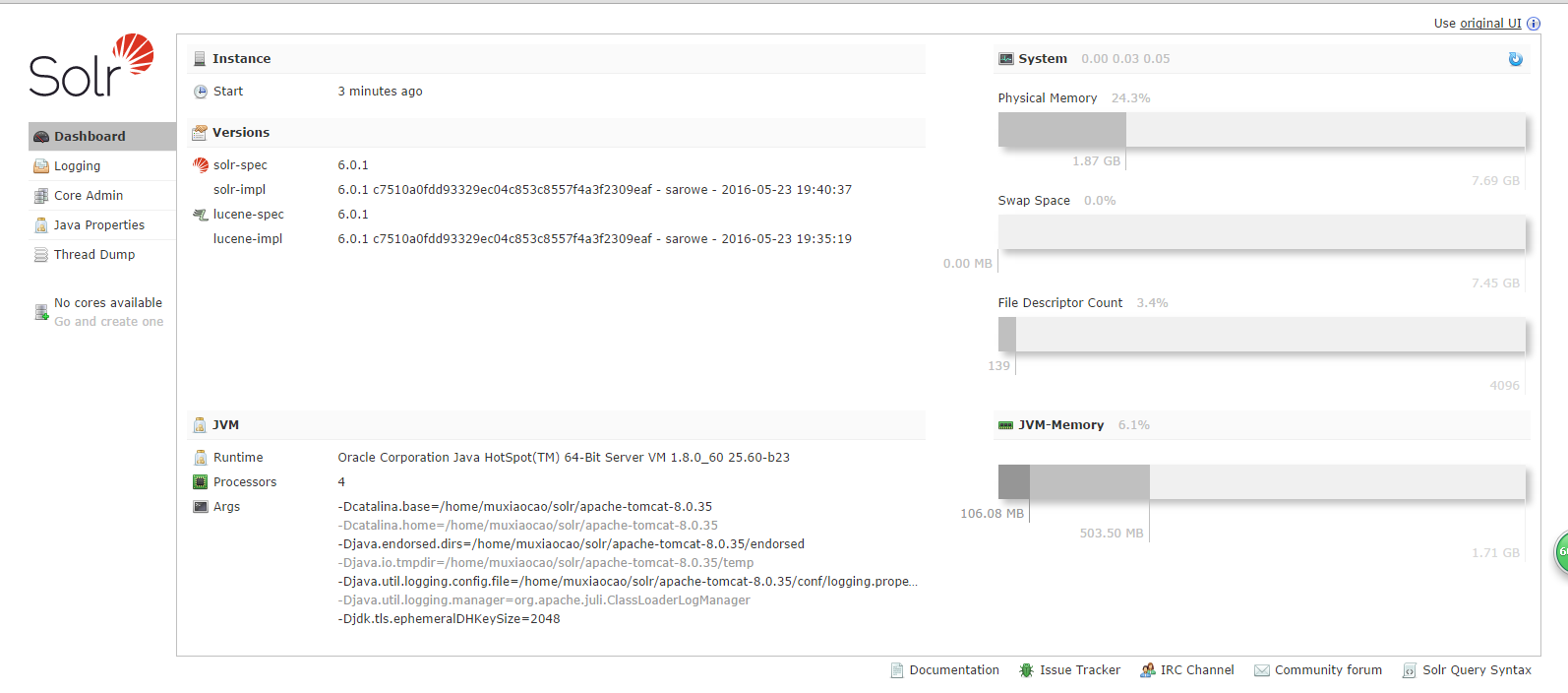
这时候访问http://localhost:8080/solr/index.html,可看到如下内容:



二、创建core
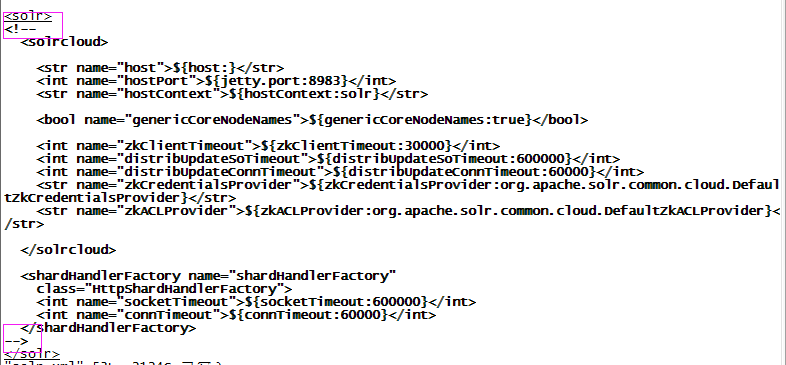
步骤一:修改solrhome下的solr.xml文件
注解掉zookeeper搭建集群配置,我们后面会采用master-slave的形式。
至于zookeeper的形式可以阅读以下这篇文章solrCloud集群配置指导
步骤二:在solrhome下创建my_solr文件夹
mkdir solrhome/my_solr- 步骤三:在my_solr文件夹下添加core.properties配置文件,并写入
name=my_solr 步骤四:将
solr-6.0.1\example\example-DIH\solr\solr下的conf文件夹拷贝到my_solr文件夹下cp solr-6.0.1/example/example-DIH/solr/solr/conf solrhome/my_solr/ -r
至此,my_solr文件夹如下:
步骤五:将
solr-6.0.1\dist下的solr-dataimporthandler-6.0.0.jar和solr-dataimporthandler-extras-6.0.0.jar
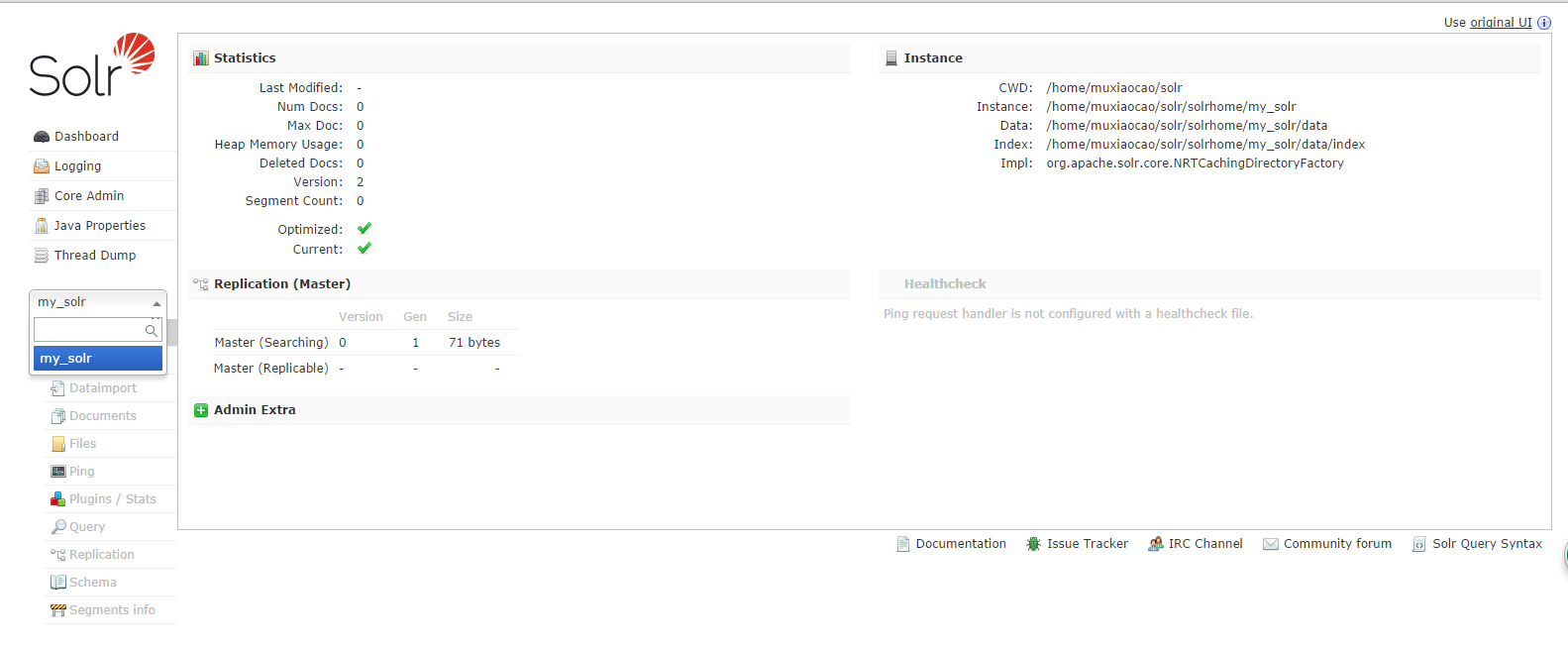
拷贝到apache-tomcat-8.0.35\webapps\solr\WEB-INF\lib下。cp solr-6.0.1/dist/solr-dataimporthandler-6.0.1.jar solr-6.0.1/dist/solr-dataimporthandler-extras-6.0.1.jar apache-tomcat-8.0.35/webapps/solr/WEB-INF/lib/步骤六:重启tomcat,访问http://127.0.0.1:8080/solr/index.html

二、配置中文分析器
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。
Solr与IKAnalyzer整合:
由于IKAnalyzer版本迟迟没有更新,所以现在原版的IKAnalyzer已经不支持Solr6.0了。会报如下错误:

所以我们需要使用更新的IK。
步骤一: IKAnalyze资源与jar包下载:
点击下载步骤二:将解压后的
ik-analyzer-solr5-5.x.jar放到
apache-tomcat-8.0.35/webapps/solr/WEB-INF/lib/下cp ikanalyzer-solr5/ik-analyzer-solr5-5.x.jar
apache-tomcat-8.0.35/webapps/solr/WEB-INF/lib/步骤三:将IKAnalyzer的配置文件和停词文件放到solr应用的classes文件夹下。
mkdir apache-tomcat-8.0.35/webapps/solr/WEB-INF/classescp ikanalyzer-solr5/ext.dic ikanalyzer-solr5/IKAnalyzer.cfg.xml ikanalyzer-solr5/stopword.dic apache-tomcat-8.0.35/webapps/solr/WEB-INF/classes/步骤四:配置solrhome的managed-schema.xml文件
vim solrhome/my_solr/conf/managed-schema +
在最后加入
步骤五:重启tomcat,效果如下:

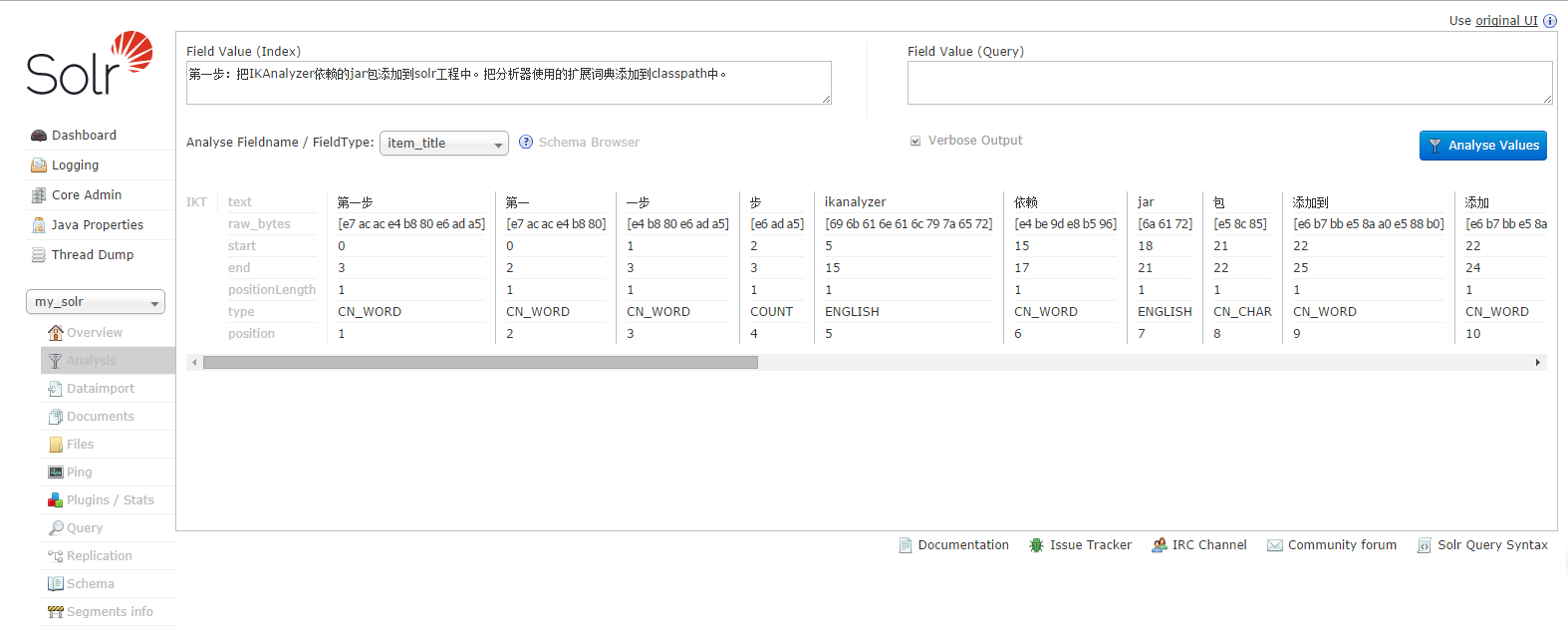
注意:转载请标明,转自itboy-木小草。
尊重原创,尊重技术。















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









