- 引入jar包
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.13</version>
</dependency>
- 编写PDF模板
- 制作word,word转pdf
- 使用 adobe Acrobat Distiller DC PDF编辑器
- 制作pdf表单,字段名选择域时图片也选择文本域,不要去使用图像域
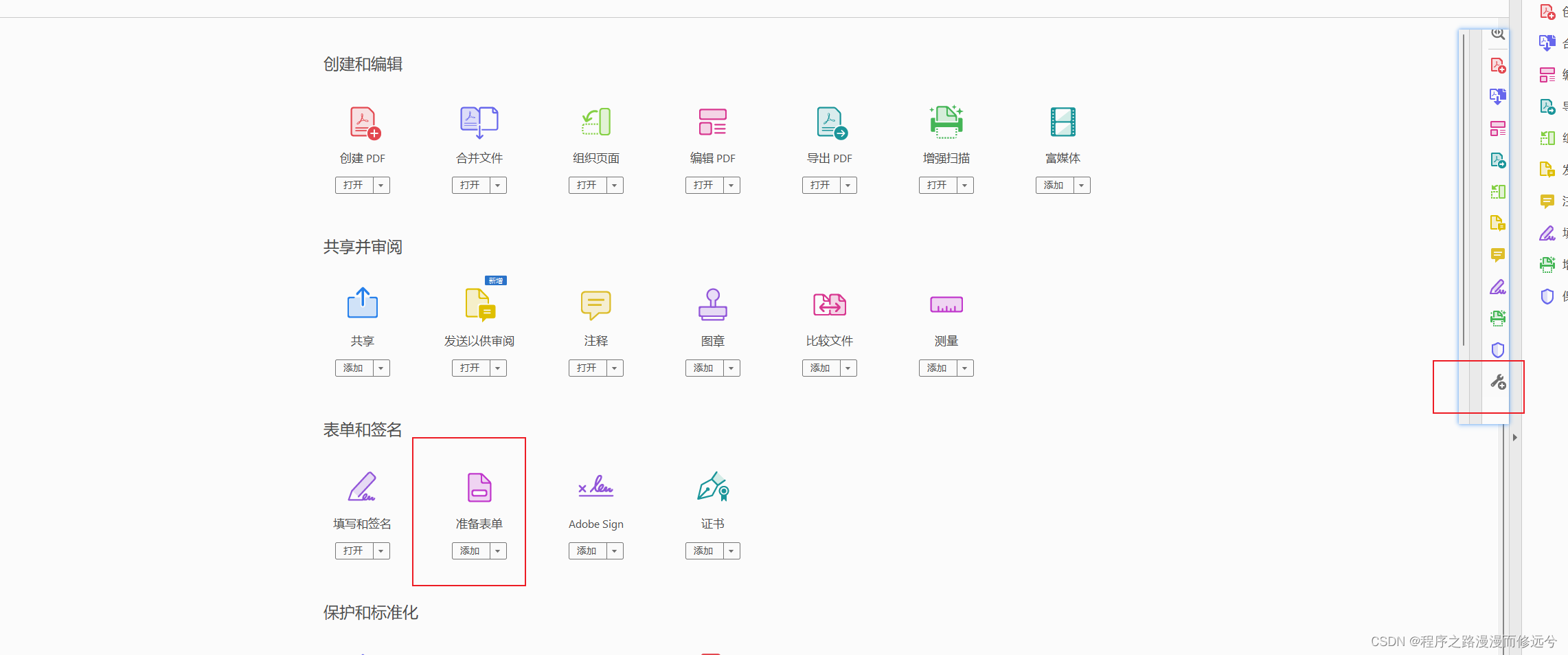
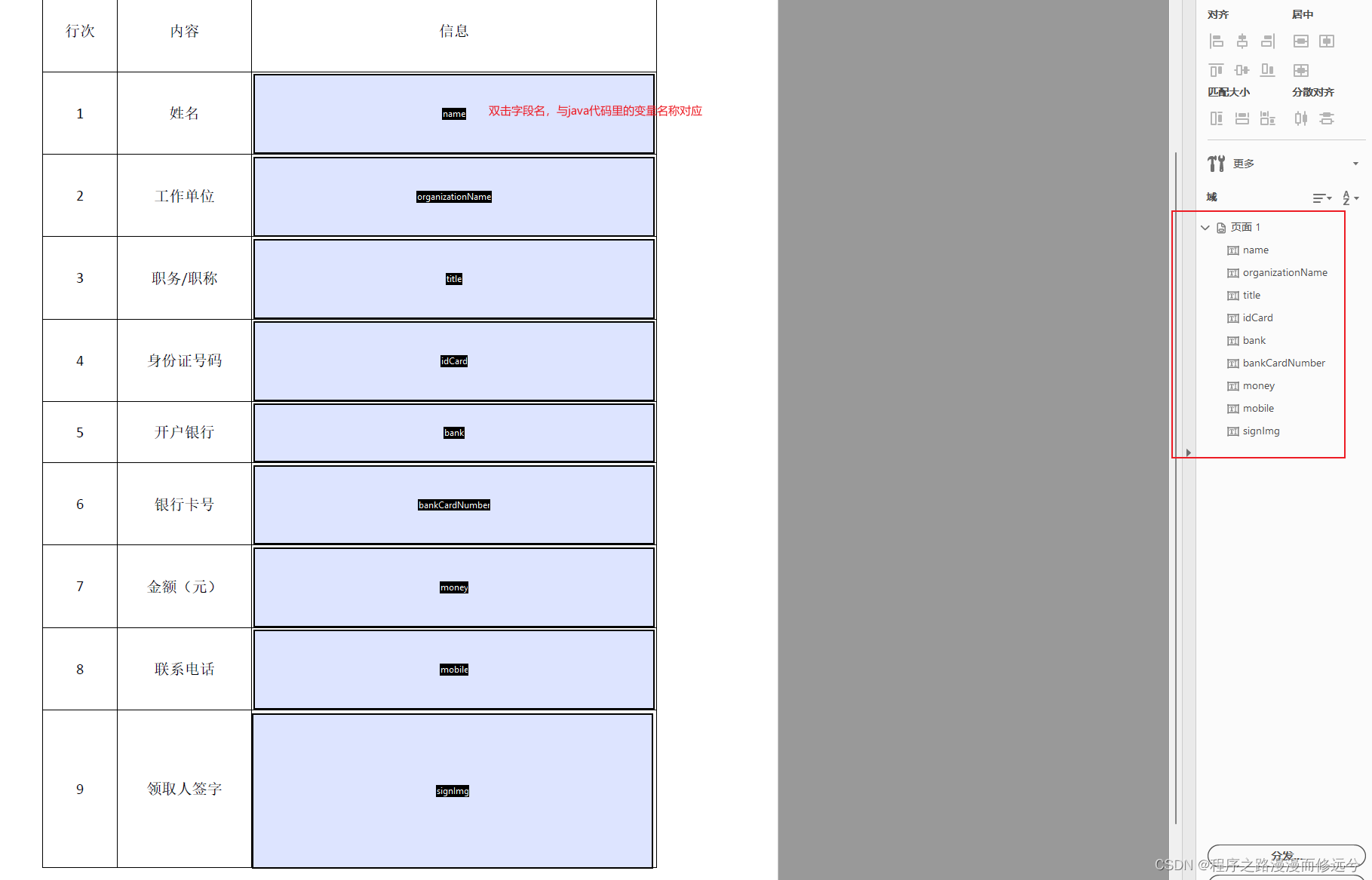
- 把编写好的pdf模板放入项目里,我这里采用的是springBoot,pdf模板放在resource文件夹下
- 由于itextpdf 包并不支持中文,网上说采用亚洲文字扩展包的形式,我这里试过了没用,因此找了windows包下的一个字体文件,也放在了resource包下
- 字体文件路径:C:\Windows\Fonts,文件名称simsunb.ttf,亲测该方法在linux环境可行
- 目录结构如下
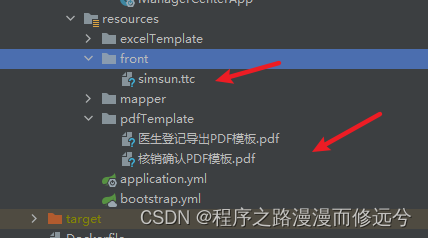
- controller 代码
@GetMapping(value = "")
public void checkoutMesPdfExport(@RequestParam(value = "id") Long id, HttpServletResponse response) {
userServicePackOrderService.checkoutMesPdfExport(id, response);
}
- service层代码,业务代码等无关代码隐去
- 参数封装,调用通用工具类PdfUtil
public void checkoutMesPdfExport(Long id, HttpServletResponse response){
// 数据取出
Map<String, String> pdfMap = new HashMap<>();
pdfMap.put("doctorName", doctorMesVo.getDoctorName());
pdfMap.put("idCard", doctorMesVo.getIdCard());
pdfMap.put("organizationName", doctorMesVo.getOrganizationName());
pdfMap.put("deptName", doctorMesVo.getDeptName());
pdfMap.put("mobile", doctorMesVo.getMobile());
pdfMap.put("bank", doctorMesVo.getBank());
pdfMap.put("bankCardNumber", doctorMesVo.getBankCardNumber());
// 签名图片字段
pdfMap.put("doctorSignature", userServicePackOrderDto.getDoctorSignature());
// pdf模板完整路径
String pdfPath = pdfUtil.appendPath("核销确认PDF模板.pdf");
String pdfName = doctorMesVo.getDoctorName() + "核销确认.pdf";
// 设置请求头
pdfUtil.setHeaders(response, pdfName);
// 导出pdf
pdfUtil.export(response, pdfPath, pdfMap, "doctorSignature");
}
- 核心,封装了PDF的工具类
- 含有一些其他工具类代码,需要稍加改动
- 工具类中有一些try-catch 需要自己对异常进行处理!!!我这里统一改成了直接抛出异常,有需要打印日志或者啥的自己处理一下。
import cn.hutool.core.collection.CollectionUtil;
import com.itextpdf.text.Document;
import com.itextpdf.text.Image;
import com.itextpdf.text.Rectangle;
import com.itextpdf.text.pdf.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.ClassPathResource;
import org.springframework.stereotype.Service;
import javax.servlet.http.HttpServletResponse;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.net.URL;
import java.net.URLEncoder;
import java.util.Collection;
import java.util.Collections;
import java.util.Map;
/**
* pdf导出工具类
*/
@Service
public class PdfUtil {
/**
* PDF 模板的路径前缀
*/
private final String Path_Prefix = "/pdfTemplate/";
/**
* 默认前缀与文件名 拼接成完整的文件路径
**/
public String appendPath(String fileName){
return new StringBuilder(Path_Prefix).append(fileName).toString();
}
/**
* 设置响应头
**/
public void setHeaders(HttpServletResponse response, String fileName) {
try {
response.setCharacterEncoding("UTF-8");
response.setHeader("content-Type", "Application/pdf");
response.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(fileName, "UTF-8"));
} catch (IOException e) {
// 异常处理
throw new RuntimeException(e);
}
}
public void export(HttpServletResponse response, String templatePath, Map<String, String> pdfMap, String imgFiledName) {
this.export(response, templatePath, pdfMap, Collections.singletonList(imgFiledName));
}
/**
* PDF导出工具类 封装
* 需要制作PDF 模板,采用字段填充的方式
* 参考文档 {https://blog.csdn.net/L28298129/article/details/118732743}
* @param response 响应头
* @param templatePath Pdf模板完整路径
* @param pdfMap pdf填充数据键值对
* @param imgFiledNames 字段内容是图片的字段名的集合,如果是其中的字段,会将该字段内容的url获取图片资源
**/
public void export(HttpServletResponse response, String templatePath, Map<String, String> pdfMap, Collection<String> imgFiledNames) {
// 字节流 pdf相关
PdfReader pdfReader = null;
OutputStream outputStream = null;
try {
// 获取模板的数据
ClassPathResource resource = new ClassPathResource(templatePath);
// 读取PDF模板表单
pdfReader = new PdfReader(resource.getInputStream());
// 字节数组流,用来缓存文件流
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
// 根据模板表单生成一个新的PDF
PdfStamper pdfStamper = new PdfStamper(pdfReader, byteArrayOutputStream);
// 获取新生成的PDF表单
AcroFields acroFields = pdfStamper.getAcroFields();
// 给表单生成中文字体,这里采用系统字体,不设置的话,中文显示会有问题
String frontPath = new ClassPathResource("/front/simsun.ttc").getPath();
// 我也不知道为啥加个 ",1" ,用的本地字体不加不行;(评论里有个哥们说是这个是字体文件中指定的具体的文字类型的索引)
BaseFont baseFont = BaseFont.createFont(frontPath + ",1", BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
acroFields.addSubstitutionFont(baseFont);
// 图片字段不为空
boolean imgFiledNamesNotEmpty = CollectionUtil.isNotEmpty(imgFiledNames);
pdfMap.forEach((fieldName, value) -> {
// 图片要单独处理
if (imgFiledNamesNotEmpty && imgFiledNames.contains(fieldName)) {
// 图片处理
try {
int pageNo = acroFields.getFieldPositions(fieldName).get(0).page;
Rectangle signRect = acroFields.getFieldPositions(fieldName).get(0).position;
//根据Url读取图片
Image image = Image.getInstance(new URL(value));
//图片大小自适应
image.scaleToFit(signRect.getWidth(), signRect.getHeight());
image.setAbsolutePosition(signRect.getLeft(), signRect.getBottom());
//获取图片页面
PdfContentByte pdfContentByte = pdfStamper.getOverContent(pageNo);
//添加图片
pdfContentByte.addImage(image);
} catch (Exception e) {
// 异常处理
throw new RuntimeException(e);
}
}else{
// 设置普通文本数据
try {
acroFields.setField(fieldName,value);
} catch (Exception e) {
// 异常处理
throw new RuntimeException(e);
}
}
});
// 表明该PDF不可修改
pdfStamper.setFormFlattening(true);
// 关闭资源
pdfStamper.close();
// 响应头的输出流
outputStream = response.getOutputStream();
// 将ByteArray字节数组中的流输出到out中(即输出到浏览器)
Document doc = new Document();
PdfCopy copy = new PdfCopy(doc, outputStream);
doc.open();
PdfImportedPage importPage = copy.getImportedPage(new PdfReader(byteArrayOutputStream.toByteArray()), 1);
copy.addPage(importPage);
doc.close();
} catch (Exception e) {
// 异常处理
throw new RuntimeException(e);
} finally {
try {
if (outputStream != null) {
outputStream.flush();
outputStream.close();
}
if (pdfReader != null) {
pdfReader.close();
}
} catch (Exception e) {
// 异常处理
throw new RuntimeException(e);
}
}
}
}
- 留言:码字不易,大佬们觉得文章有帮助,动动小手点个赞支持一下,蟹蟹!
- 亲测PDF工具类很通用,感谢百度大佬们的资源以及思路,主要是参考了这位大佬的文章,地址:
- Java如何实现Pdf的导出?_执笔画红颜丶的博客-CSDN博客_java导出pdf文件
# 留言:老婆做了一个小红书账号,全是瓷砖方面的干货,大佬们如果有需求或者有兴趣可以移步了解一下,嘻嘻~
小红书地址 GO GO GO ! ! !

























 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









