







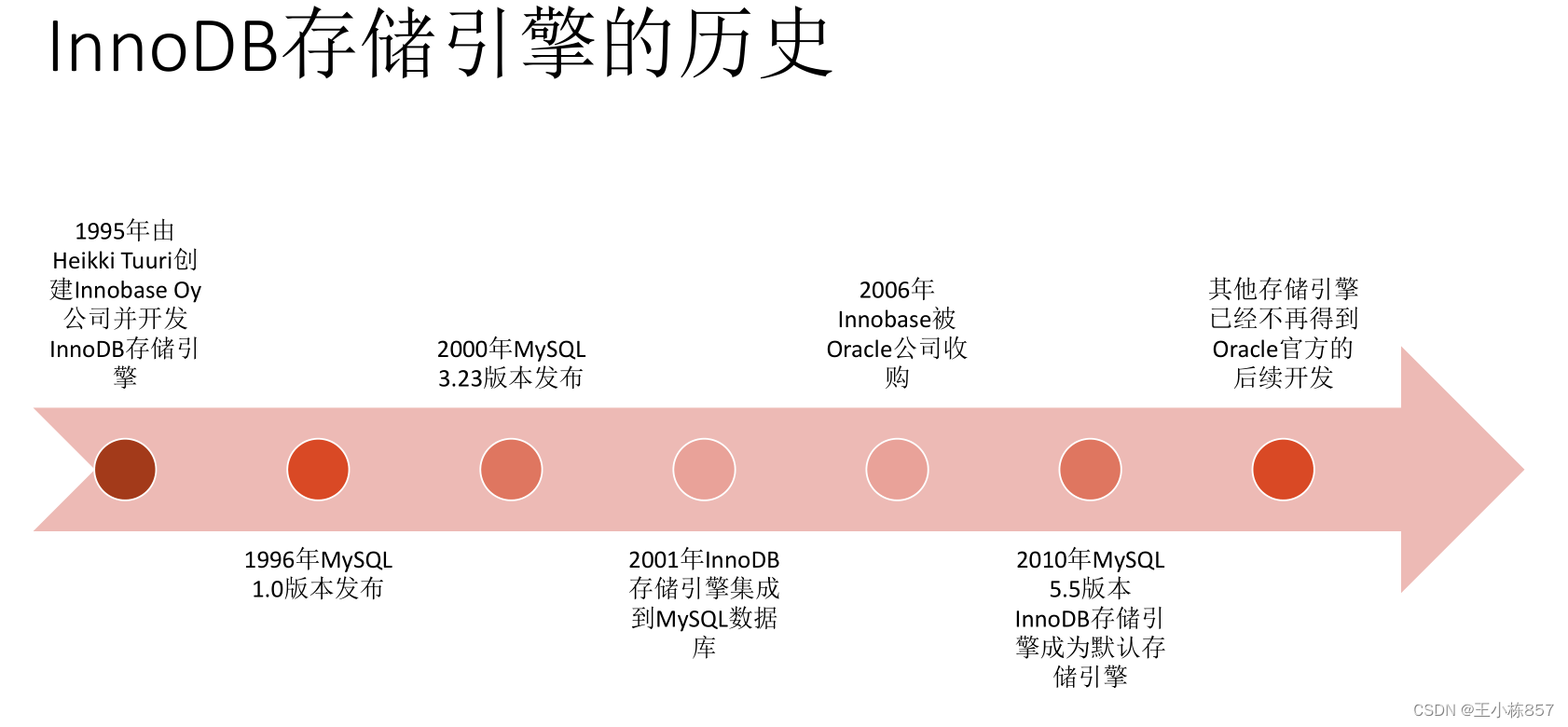
历史
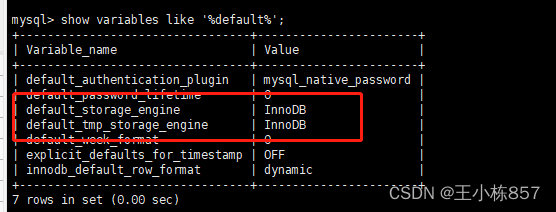
查看使用的默认引擎
InnoDB存储引擎的文件
表空间是一个逻辑的概念,由多个文件组成,支持裸设备
分类:
系统表空间:
存储元数据,undo信息,change buffer信息等。最初只有系统表空间所有的表和索引都存储在其中,随后做了改进可以使用独立的表空间了
独立表空间:
需要开启,每张用户表对应一个独立的idb文件。分区表对应多个文件
开启:
innodb-file-per-table=1
undo表空间:
5.6版本后支持undo表空间。需要进行开启
用来保存事务中的DML语句的undo信息,也就是来保存数据在被修改之前的值。 在MySQL5.6中开始支持把undo log分离到独立的表空间,并放到单独的文件目录下。这给部署不同IO类型的文件位置带来便利,对于并发写入型负载,可以把undo文件部署到单独的高速存储设备上。
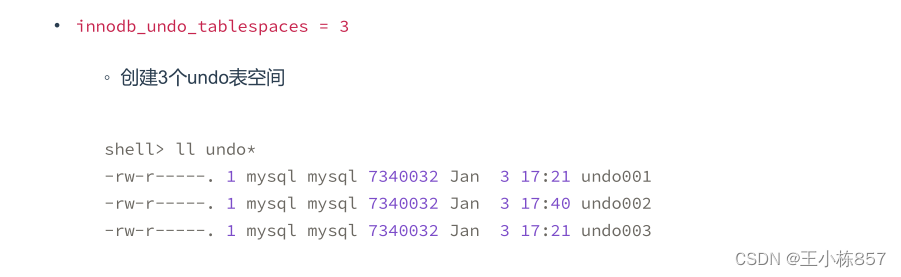
innodb_undo_tablespaces = 3
用于设定创建的undo表空间的个数,在mysql_install_db时初始化后,就再也不能被改动了;默认值为0,表示不独立设置undo的tablespace,默认记录到ibdata中;否则,则在undo目录下创建这么多个undo文件,例如假定设置该值为4,那么就会创建命名为undo001~undo004的undo tablespace文件,每个文件的默认大小为10M。修改该值会导致Innodb无法完成初始化,数据库无法启动,但是另两个参数可以修改;
临时表空间:
MySQL5.7增加了临时表空间(ibtmp1)通过把查询保存成临时表,存到临时表空间
配置临时表空间:
innodb_temp_data_file_path
同一个表空间(ibdata1) 存储和 独立表空间 存储就 性能 上而言没有区别,删除表时系统表空间中数据删除但是空间不会立即释放,删除独立的表空间会立即释放空间。独立表空间更加直观。

 查看表空间的元数据信息
查看表空间的元数据信息
select * from information_schema.innodb_sys_tablespaces
General表空间:
创建一个通用表空间,指定存储路径。创建表指定其表空间为通用表空间,可改变数据存储的位置。一个通用表空间可以对应多张表 。可以简单的理解为把多个表的 ibd 文件合并在一起了
注意,如果设置了innodb_page_size,且大小不是file_block_size,那么在创建表的时候会报错。
重做日志文件:
data目录下会有两个名为ib_logfile0和ib_logfile1的文件,每个大小48M。这个文件就是InnoDB存储引的redo log(叫做重做日志)。在MySQL官方手册中将其称为InnoDB存储引擎的日志文件,不过更准确的定义应该是重做日志文件(redo log file)。重做日志文件对于InnoDB存储引擎至关重要,它们记录了InnoDB存储引擎的事务日志。这种日志和磁盘配合的整个过程,其实就是 MySQL 里的 WAL 技术(Write-Ahead Logging),关键点就是先写日志,再写磁盘。当事务提交(COMMIT)时,必须先将该事务的所有日志写入到重做日志文件进行持久化,待事务的COMMIT操作完成才算完成。这里的日志是指重做日志,redo log用来保证事务的持久性
表空间内部组织结构
内部结构:
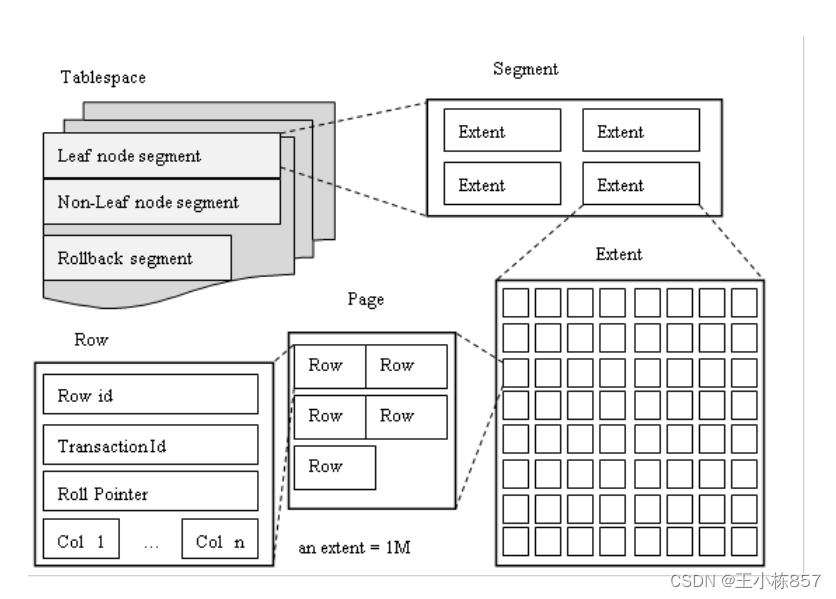
表空间(tablespace) -> 段(segment, 逻辑概念)-> 区 (extent)-> 页(page)->行(row)
表空间-区
区是最小的空间申请单位,固定大小为1M,如果页(page_size)大小为16K,一个区内存放1024/16个页,通常来说空间申请时会一次申请4个区(特殊情况也会申请5个)。一个区内中的物理上是连续的。
表空间-页
页是最小的IO单元,data的最小单元是页中的记录(row)
设置页的大小:
innodb_page_size = 16K (默认16K)
如何快速定位到一个页?
每个 表空间 都 对应 一个 SpaceID ,而 表空间 又对应一个 ibd文件 ,那么一个 ibd文件 也对应一个 SpaceID,每一个表空间都有对应的唯一自增的spaceID,每个表空间中的页都有唯一自增的pageID(唯一范围本空间),通过spaceID+pageID的方法快速定位到页。
压缩表
# 定义压缩后的存储的页的大小
key_block_size=16
# 开启压缩
row_format=compressed
# `key_block_size`的设置`不影响压缩`本身*(只和数据本身以及zlib算法有关)*,只是确定`压缩后的数据`存放的`页大小`,字段类型如果是`varchar`,`text`等类型的数据,压缩的效果还是比较明显的innodb_page_size=16k 的的数据设置 key_block_size=16 是可以压缩的,且效果比较明显;
并不是 key_block_size 设置的越小,压缩率就越高;
在启用压缩后,16K 和 8K 的插入性能要好于原来未压缩的插入性能,所以启用了压缩,性能不一定会变差 ;
在I/O Bound(IO密集型)的业务场景下,减少I/O操作的次数对性能提升比较明显。
key_block_size 的设置的值( 经验值 )通常为 innodb_page_size 的 1/2
在MySQL的官方文档中,上面(包括之前谈的)都称之为 InnoDB Table Compression ,其实不够准确,因为他是基于页的压缩.
透明表空间压缩
没有指定页大小 ,而是使用了文件系统(filesystem)层中 稀疏文件 的特性,来达到压缩的目的
压缩后,原来16K的数据压缩成了4K;
剩余的12K空间用特殊的孒符填充(比如说是0);
在写入文件系统时调用 Punching holes 写入,实则只写入4K的数据;
被填充的12K的空间,可以提供给后序的插入,更新等使用;
从innodb的角度看还是16K的页大小,只是文件系统知道该页只需要4K就能够孓储(对innodb是透明的);
SpaceID 和 PageNumber 的读取方式没有改变(细节由文件系统屏蔽);
由于文件系统的快大小是4K,所以压缩后孓储的空间也是4K对齐的
比如16K压缩成了 10K ,那就需要 3个4K 去孓储没有实验成功
索引组织表
在InnoDB存储引擎中,表都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table),或者叫聚集索引(clustered index)
每张表都必须有一个主键
根据主键的值构造一颗B+树
这颗B+树的叶子节点(leaf page)存放所有记录
非叶子节点存放的主键和指针(若干个{主键,指针} 组成一个非页节点)
指针指的就是pagenumber (这里 不需要SpaceID ,因为SpaceID对应的是 ibd文件 ,我们现在是在 ibd文件内部 查找数据)
主键:
如果创建表的时候 没有显示指定主键 ,则InnoDB会按照如下方式选择或创建主键:
1. 判断表中是否有 非空的唯一索引 ,如果有该列即为主键 ;
◦ 如果存在多个非空唯一索引,以创建表时 第一个定义 的非空唯一 索引 为准,而 不是(columns)定义的顺序
2. 如果上述条件都不符合,则InnoDB自动创建一个6字节大小的指针;
索引组织表与堆表
堆表索引和数据分开了,索引中存放了数据的位置而不是数据的本身
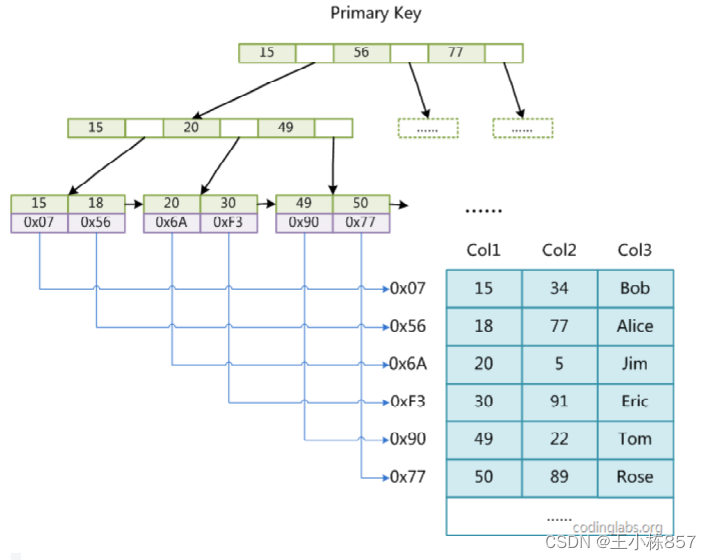
索引组织表将索引和数据放在了一起,索引的叶子节点(leaf page)存放了所有完整的记录(Row)。
索引即数据,数据即索引
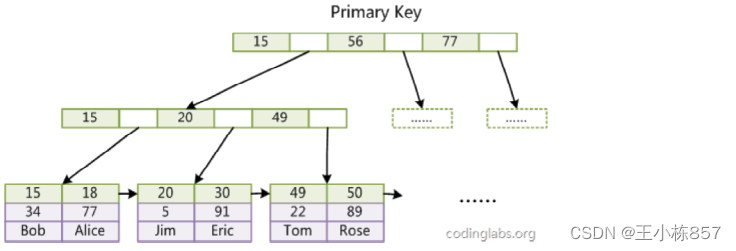
注意:
1. 非叶子节点(Non-leaf page)中不会孓放所有的数据(Row)的 {主键, PageNumber},而是从叶子节点(leaf page)中选出一个数据的主键,将这个主键和该页的PageNumber填入到非叶节点(Non-leaf page)中
2. 从逻辑上看,是一棵B+树,但是从物理上看都是每个页(非叶子节点和叶子节点)通过指针串在一起,使得逻辑有序。
二级索引中的叶子节点不存放数据本身,而是存放主键。
Double Write
MySQL的数据页默认是16K,而文件系统的数据页是4K,IO操作是按页为单位就行读写的。这就可能出现数据库对一个16k的数据页修改后,操作系统开始进行写磁盘,但是在这个过程中数据库宕机导致没有完全将16K数据页写到磁盘上。数据库重启后,校验数据页,发现有数据页不完整,就起不来了(redo是基于完整数据页进行的恢复)。
为了解决这个问题,MySQL引入了double write这个特性。double write针对的是脏数据,提高innodb的可靠性,用来解决部分写失败(partial page write)。为了数据的持久性,脏数据需要刷新到磁盘上,而double write就产生在将脏数据刷盘的过程中。刷盘是一份脏数据写到共享表空间ibdata中,一份写到真正的数据文件永久的保存。写了两次脏数据,就叫double wriete
Double Write的目的是为了保证数据写入的可靠性, 避免partial write 的情况
◦ partial write( 部分写 )
◾ 16K的页只写入了4K,6K,8K,12K的情况(桮时是不完整、不干净的页);
◾ 不可以 通过redo log进行恢复;
◾ redo恢复的前提是该 页 必须是 完整、干净 的;
• Double Write是 全局 的
• 共享表空间存在一个 段对象 double write,然后这个段 由2个区(1M)组成
• 2M固定大小(both file and memory)
• 页在刷新时,首先 顺序 的写入到double write
• 然后再刷回磁盘(ibd)
# double wirte buffer -1-> double write(ibdata1)
# |-2-> ibd
# 有点类似 RAID-1 的机制,总有一份数据是正确的
# 简单说来,就是在脏页刷新到磁盘前,先要有个地方记录这个脏页的副本
1. 将脏页copy到Double Write Buffer对象中,默认2M大小;
2. 将Double Write Buffer中的对象 先写入 到共享表空间(ibdata1)中的Double Write;
◦ 2M循环覆盖
◦ 顺序 写入(一档IO)
3. 再根据(space,page_no)写入到原来的ibd文件中;
4. 如果是在写到ibdata1中的Double Write时,发生宕机;桮刻原来的ibd file 仍然是完整、干净的 ,下档启动后是可以用redo文件进行恢复的。
5. 如果是写到ibd文件时,发生了宕机;桮刻在原来的 ibdata1中存在副本 ,可以直接覆盖到ibd文件(对应的页)中去,然后再进行redo进行恢复
redo是 物理逻辑 的, 物理 表示记录的日志针对的是 页(page) 的修改, 逻辑 表示记录日志的内容是逻辑的。
change buffer
提高辅助索引的插入性能,开启后有30%的性能提升(默认开启)

• 对于 主键 (a 列 ),每档插入都要立即插入对应的 聚集索引 页中(在内存中就直接插入,不在内存就先读取到内存)
• 对于 二级索引 (secondary index)(b 列 )
1. 在 没有 Change Buffer时,每档插入一条记录,就要读取一档页(读取内存,或者从磁盘读到内存),然后将记录插入到页中;
2. 在 有 Change Buffer时,当插入一条记录时, 先判断 记录对应要插入的 二级索引 (secondary index)页 是否 在Buffer Pool中:
◾ 如果该 二级索引 (secondary index)页 已经在Buffer Pool中 ,则 直接插入 ;
◾ 反之,先将其 Cache 起来,放到 Change Buffer中,等到该 二级索引 (secondary index)页被 读到 时,将Change Buffer中该页对应的记录 合并 (Merge)进去,从而减少I/O操作;
Change Buffer就是用来 提升二级索引插入的性能 。
使用空间换时间,批量插入的方式(二级索引可以不急着插入,只要主键已经插入了即可)二级索引缓存加快插入速度,
Flush Neighbor Page
• 刷新 脏页所在区 (extent)的 所有脏页 ,合并IO,随机转顺序的优化;
◦ 写入的数据太多
◦ 如果业务确实是频繁更新,那刷新也会很频繁
• 对传统机桋磁盘有意义;
◦ innodb_flush_neighbors={0|1|2} (>=MySQL 5.6)
◦ 0:表示关闭该功能
◦ 1:表示刷新一个区内的脏页
◦ 2:表示刷新几个 连续 的脏页
• SSD建议关闭档功能;















 656
656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









