







 本文通过innodb-java-reader项目,以实例演示了如何使用Java调试InnoDB数据库的内部结构,包括页布局、索引、用户记录和行读取,适合不想学习C++但想了解MySQL存储原理的读者。
本文通过innodb-java-reader项目,以实例演示了如何使用Java调试InnoDB数据库的内部结构,包括页布局、索引、用户记录和行读取,适合不想学习C++但想了解MySQL存储原理的读者。
概述
想深入了解mysql存储机制,但又不懂C++,更不想背八股文。有一天在github上看到大佬的innodb-java-reader,完美地满足我对InnoDB 的内部机制源码调式的渴望
演示
在分析之前,首先看一下项目的运行效果
- 查看mysql数据库存储位置
show global variables like '%datadir%';
1.1 idb文件一般存放在mysql/data/databasename下
- 按照文档的步骤,创建表,执行存储过程建数据
CREATE TABLE `t` (`id` int(11) NOT NULL, `a` bigint(20) NOT NULL, `b` varchar(64) NOT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB; delimiter ;; drop procedure if EXISTS idata; create procedure idata() begin declare i int; set i=1; while(i<=5)do insert into t values(i, i * 2, REPEAT(char(97+((i - 1) % 26)), 8)); set i=i+1; end while; end;; delimiter ; call idata(); - 执行一下代码,观察运行结果是否和直接在mysql客户端执行一致
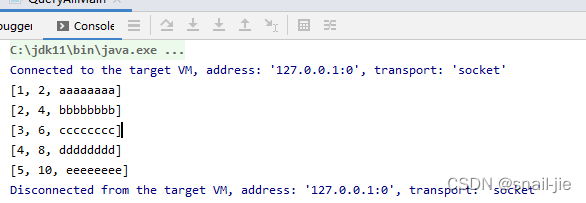
3.1 运行结果展示public static void main(String[] args) { String createTableSql = "CREATE TABLE `tb11`\n" + "(`id` int(11) NOT NULL ,\n" + "`a` bigint(20) NOT NULL,\n" + "`b` varchar(64) NOT NULL,\n" + "PRIMARY KEY (`id`),\n" + "KEY `key_a` (`a`))\n" + "ENGINE=InnoDB;"; String ibdFilePath = "C:\\ProgramData\\MySQL\\MySQL Server 5.7\\Data\\test\\t.ibd"; try (TableReader reader = new TableReaderImpl(ibdFilePath, createTableSql)) { reader.open(); // ~~~ query all records List<GenericRecord> recordList = reader.queryAll(); for (GenericRecord record : recordList) { Object[] values = record.getValues(); System.out.println(Arrays.asList(values)); assert record.getPrimaryKey() == record.get("id"); } } }
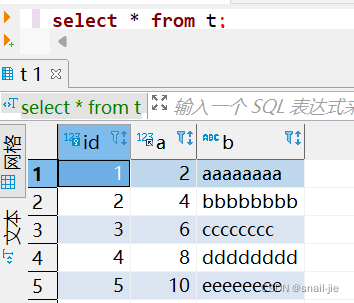
探索InnoDB内部机制
演示结果无误后,对照源码以及Jeremy Cole的InnoDB介绍进行学习,源码调式的入口在IndexServiceImpl#traverseBPlusTree
- 通过FileChannelStorageServiceImpl#loadPage加载指定页(FilHeader、FilTrailer),详情见下面的InnoDB页的物理结构
- 通过Index构造函数加载索引页,详情见下面的InnoDB 索引页的物理结构
Index index = new Index(page, tableDef); - 将指针指向第一条数据记录开始的位置,开始读取记录,直到最后一条记录(supremum)。详情见下面的读取用户记录
GenericRecord infimum = index.getInfimum(); int nextRecPos = infimum.nextRecordPosition(); sliceInput.setPosition(nextRecPos);
InnoDB页的物理结构
- 页的文件布局(如下图)
1.1 每个空间被分成页面,通常每个页面 16 KiB
1.2 每个页面都有一个 38 字节的FIL头和 8 字节的FIL 尾(FIL是“文件”的缩写形式)

- FIL头部和尾部的结构布局
2.1 FIL头部读取的代码对应于FilHeader#fromSlice
2.2 在读取FIL尾部时,首先把position移到FIL尾部开始的位置,再开始读取:FilTrailer#fromSlice

InnoDB 索引页的物理结构
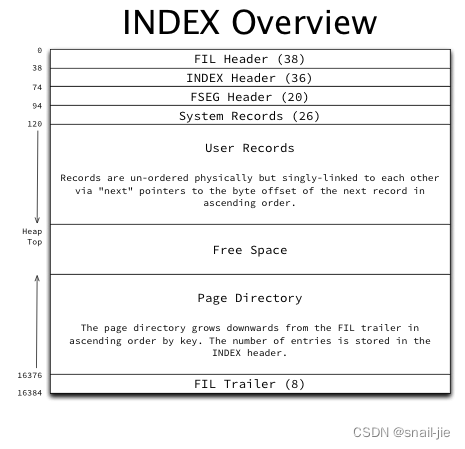
-
System records(系统记录):InnoDB每个页面有两条系统记录,分别称为infimum和supremum
1.1 infimum和supremum位于页面内固定位置(offset分别为99和102)
1.2 infimum 记录表示一个低于页面中任何可能键的值,"next record"指针指向页面中键值最低的用户记录
1.3 supremum 记录表示比页面中任何可能的键都高的键。它的“next record”指针总是0

注意图中的单位,譬如Info Flags(4比特) + Number of Records Owned = 1字节;infimun占8个字节 -
在innodb-java-reader中的实现在Index的构造函数中
public Index(InnerPage innerPage, TableDef tableDef) { // 包括上面的FIL Header/Trailer super(innerPage); // 36 bytes index header this.indexHeader = IndexHeader.fromSlice(sliceInput); // 20 bytes fseg header this.fsegHeader = FsegHeader.fromSlice(sliceInput); // infimum处理 RecordHeader infimumHeader = RecordHeader.fromSlice(sliceInput); this.infimum = new GenericRecord(infimumHeader, tableDef, innerPage.getPageNumber()); this.infimum.setPrimaryKeyPosition(sliceInput.position()); // supremum处理 RecordHeader supremumHeader = RecordHeader.fromSlice(sliceInput); this.supremum = new GenericRecord(supremumHeader, tableDef,innerPage.getPageNumber()); this.supremum.setPrimaryKeyPosition(sliceInput.position()); } -
页面目录(page directory)
3.1 页面目录从FIL尾部开始,并从那里向用户记录“向下”增长。页面目录包含一个指针,每4-8条记录,除了总是包含一个下至上的条目

3.2 从indexHeader中获取Page directory中的slot个数int dirSlotNum = this.indexHeader.getNumOfDirSlots();3.3 从FIL尾部开始(页大小16K - 页尾大小8B - slot目录数 * 目录大小2B)
sliceInput.setPosition(SIZE_OF_PAGE - SIZE_OF_FIL_TRAILER - dirSlotNum * SIZE_OF_PAGE_DIR_SLOT);3.4 从下往上读取目录
for (int i = 0; i < dirSlotNum; i++) { dirSlots[dirSlotNum - i - 1] = sliceInput.readUnsignedShort(); }3.5 页面目录读取完之后,将指针移到endOfSupremum位置,开始读取用户记录
读取用户记录
源码入口在IndexServiceImpl#readRecord,下图展示叶子节点的结构
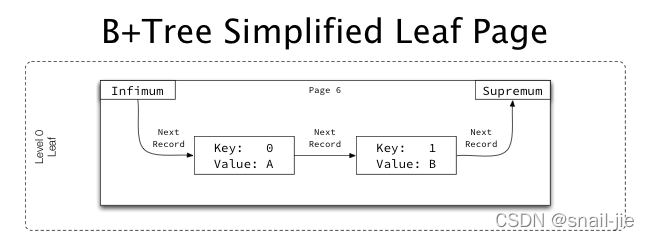
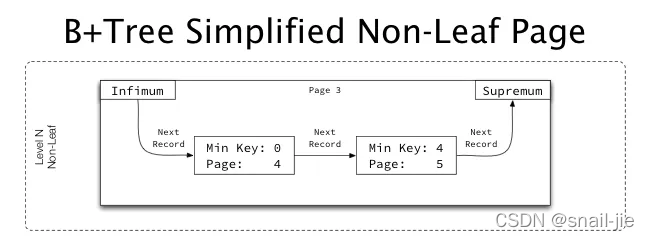
非叶子节点指向的子页面上的最小键
- 将指针移到用户记录开始的位置
GenericRecord infimum = index.getInfimum(); int nextRecPos = infimum.nextRecordPosition(); sliceInput.setPosition(nextRecPos); - 从用户记录开始位置开始遍历,直到用户记录结尾的位置supremum
2.1 如果为叶子节点,则加入记录集合,否则以深度优先的方式从根页面递归地遍历b+树while (nextRecPos != supremum.getPrimaryKeyPosition()) { GenericRecord record = readRecord(tableDef, index.getPageNumber(), sliceInput, index.isLeafPage(), projection); if (record.isLeafRecord()) { recordList.add(record); } else { traverseBPlusTree(tableDef, record.getChildPageNumber(), recordList, recordPredicate, projection); } nextRecPos = record.nextRecordPosition(); recCounter++; }
行读取
- 读取用户记录头(占5个字节)
1.1 根据下面的图与源码对着看,清晰明了RecordHeader#fromSlice

- 聚集索引
2.1 Cluster Key Fileds:代表聚集索引的值
2.2 Roll Pointer:包含最近修改该记录的事务的undo记录在回滚段的位置
(1)Roll Pointer字段有:1bit的"is_insert"的标记 ;7bit的的回滚段ID;2bit的undo log偏移量

2.3 读取非聚集索引的值(IndexServiceImpl#putColumnValueToRecord)
2.4 所有的列都读取完毕后,将指针指向下一条记录的位置
(1)下一条记录位置 = 主键索引位置 + 头中下一条记录的偏移量bodyInput.setPosition(record.nextRecordPosition()); // 下一条记录位置 public int nextRecordPosition() { return primaryKeyPosition + header.getNextRecOffset(); }
束语
第一次接触调式只是对整个流程一次梳理,里面一些细节还未分析。后续会逐步去学习,如果有误的地方,欢迎大家指正讨论


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









