







科普:
什么是爬虫:
- 百度百科:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫
什么是反爬虫:
百度百科:很多网站开始保护他们的数据,他们根据ip访问频率,浏览网页速度,账户登录,输入验证码,flash封装,ajax混淆,js加密,图片,css混淆等五花八门的技术,来对反网络爬虫

爬虫带来的安全风险:
安全侧:
1.数据资产泄漏
2.竞争对手竞品分析
3.恶意扫描
4.渗透测试
后端服务侧:
1.服务压力上升
2.服务能力下降
运营侧:
1.业务价值输出降低
2.羊毛党褥羊毛成本降低
3.运营统计数据失真
爬虫攻击角度:
网络安全界向来就有“不知攻焉知防”的说法,因此想要理解反爬虫,有必要先学习爬虫,熟悉爬虫攻击手法,便于更好的防御。爬虫的目的通常是以较低的成本和较高的效率获取信息
相关技术:
1.Apache Nutch 分布式爬虫
2.Java爬虫:Crawler4j、WebMagic、WebController
3.python爬虫:scrapy、selenium+phantomJS (HeadlessBrowsers)、截图+OCR、
4.在 Headless Browser 运行时里预注入一些js逻辑,伪造浏览器的特征
爬虫特征:
1.User-Agent 没有携带 或者User-Agent 为某些特殊的值 或者有一定的规律
2.Referer 没有 或者Referer 错误
3.同一IP短时间内多次访问同一页面
4.同一账户短时间内多次进行相同操作
5.同一页面短时间内访问量突增并且有规律
爬虫通用架构:
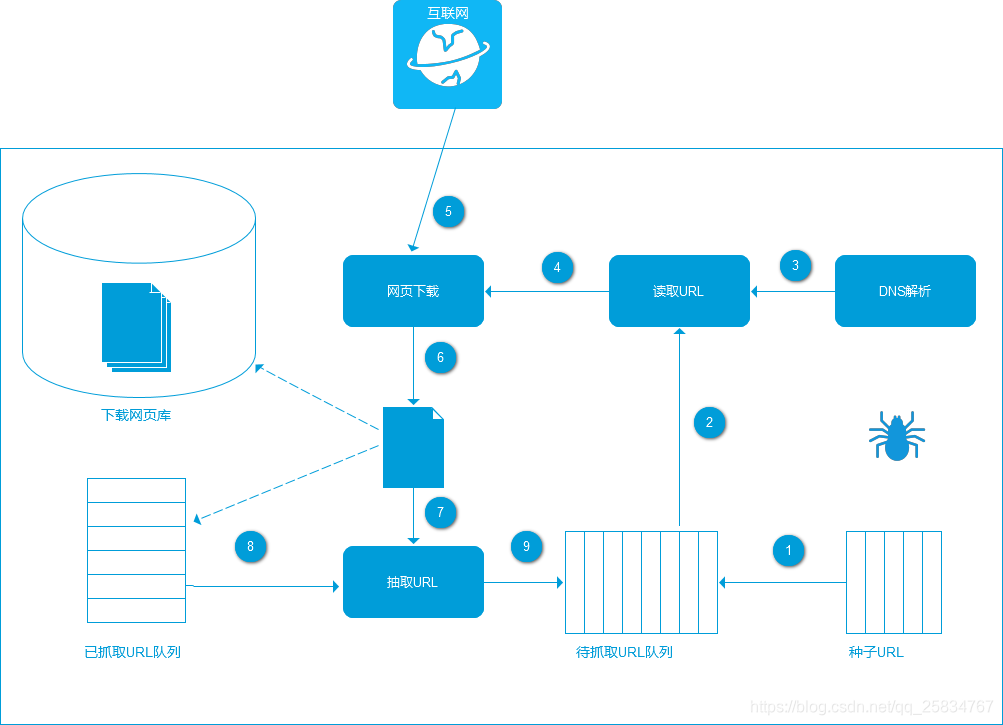 爬虫从待抓取URL队列依次读取,并将URL通过DNS解析,把链接地址转换为网站服务器对应的IP地址。然后将其和网页相对路径名称交给网页下载器,网页下载器负责页面的下载。对于下载到本地的网页,一方面将其存储到页面库中,等待建立索引等后续处理;另一方面将下载网页的URL放入已抓取队列中,这个队列记录了爬虫系统已经下载过的网页URL,以避免系统的重复抓取。对于刚下载的网页,从中抽取出包含的所有链接信息,并在已下载的URL队列中进行检查,如果发现链接还没有被抓取过,则放到待抓取URL队列的末尾,在之后的抓取调度中会下载这个URL对应的网页。如此这般,形成循环,直到待抓取URL队列为空
爬虫从待抓取URL队列依次读取,并将URL通过DNS解析,把链接地址转换为网站服务器对应的IP地址。然后将其和网页相对路径名称交给网页下载器,网页下载器负责页面的下载。对于下载到本地的网页,一方面将其存储到页面库中,等待建立索引等后续处理;另一方面将下载网页的URL放入已抓取队列中,这个队列记录了爬虫系统已经下载过的网页URL,以避免系统的重复抓取。对于刚下载的网页,从中抽取出包含的所有链接信息,并在已下载的URL队列中进行检查,如果发现链接还没有被抓取过,则放到待抓取URL队列的末尾,在之后的抓取调度中会下载这个URL对应的网页。如此这般,形成循环,直到待抓取URL队列为空
反爬虫防御角度:
相关技术:
1.前端反爬虫:
只是提高了恶意爬虫拿到真实数据的难度,并不能起到禁止爬虫的作用。截图+OCR的爬虫无法防御
1.1 方案一
页面使用font-face重新定义了字符集,并通过unicode去映射展示,爬虫者必须同时爬取字符集,才能识别出数字,每次刷新页面,字符集的url刷新。使爬虫的难度大大增加
优势:前端通过一些复杂的转换可以大大提高chromium爬虫的难度
缺陷: 1…前端需要对数字运算的场景无法使用
1.2 方案二
和上面的重新定义字符集类似。可以不采用unicode去映射。而是采用重新定义数字的方案。不影响前端进行数字运算(去哪儿网APP端方案)
1.3方案三
利用css样式替换文字
1.4 方案四
Headless Chrome 特性检测
Headless Chrome由于其自身就是一个chrome浏览器,因此支持各种新的css渲染特性和js运行时语法。基于这样的手段,爬虫作为进攻的一方可以绕过几乎所有服务端校验逻辑,但是这些爬虫在客户端的js运行时中依然存在着一些破绽,诸如:
基于plugin对象的检查
if(window.navigator.webdriver) {
console.log(‘It may be Chrome headless’);
}
基于language的检查
if(window.navigator.languages.length == 2) {
console.log(‘Chrome headless detected’);
}
“navigator.plugins.length”此参数可以检测selenium的headless模式,headless模式下为0
if(window.navigator.plugins.length == 0) {
console.log(‘Chrome headless detected’);
}
基于以上的一些浏览器特性的判断,基本可以通杀市面上大多数 Headless Browser 程序。在这一层面上,实际上是将网页抓取的门槛提高,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器
这些特性有些也是可以伪造的,那么如何防止伪造浏览器特征呢?有一个方案是在代码执行前判断调用的方法是否是浏览器原生的
1.5 方案五:
基于浏览器的 UserAgent 字段描述的浏览器品牌、版本型号信息,对js运行时、DOM和BOM的各个原生对象的属性及方法进行检验,观察其特征是否符合该版本的浏览器所应具备的特征(浏览器指纹检查)
1.6 方案六:
前端反调试
[ ] 通过对浏览器禁止调试从而达到别人无法分析请求接口的目的,场景为打开控制台查看Network,不断的debugger使其无法被查看
- 不停地打断,页面跳到source页面,阻止查看代码
- 断点产生不可回收的对象,占据你的内存,造成内存泄漏,没过多久浏览器就会卡顿
2.中间层反爬虫:
在客户端与服务器之间设置拦截过滤,有效减少服务器端的压力 (实现方式类似nginx-waf)
中间层反爬虫取代了后端反爬虫,在一些简单系统里反爬虫可能直接后端实现了。但是将反爬虫做成平台化还是要和后端做解耦
2.1 对Headers的User-Agent进行检测
(根据User-Agent 来鉴别你的http header中的各个字段是否符合该浏览器的特征)
缺点:UA可以伪造,而且比较难校验
2.2 设备指纹
Fingerprint.js 是最先进的开源欺诈检测JS库
useragent用户代理language语言种类colordepth目标设备或缓冲器上的调色板的比特深度devicememory设备内存pixelratio设备像素比hardwareconcurrency可用于运行在用户计算机上的线程的逻辑处理数量screenresolution当前屏幕分辨率availablescreenresolution屏幕宽高timezoneoffset本地时间与GMT时间差timezone时区sessionstorage是否会话存储localtorage是否具有本地存储addbehaviorIE是否指定AddBehavioropendatabase是否有打开的DBcpuclass浏览器系统cpu等级platform运行浏览器的操作系统donottrackdo-not-track设置plugins浏览器插件信息canvas使用Canvas 绘图webglWEBGL指纹信息webglvendorandrenderer具有大量熵的WebGL指纹的子集adblock是否安装AdBlockhasliedlanguages用户是否篡改了屏幕分辨率hasLiedOs是否篡改了操作系统hasliedbrowser用户是否篡改了浏览器touchsupport触摸屏检测fonts字体列表fontsflash已安装的flash字体列表audio音频处理enumeratedevices可用的多媒体输入和输出设备的信息
2.3 cookie检测
将设备指纹,服务端下发认证 set进cookie,对cookie的访问频率 限制
cookie可以有效解决用户标识问题
2.4 IP检测
通过IP风险库判断是恶意IP进行黑名单,IP策略无法有效防御动态切换IP的场景
缺点:IP防御误封率高
2.5 接口频率控制
比较初级的爬虫常常通过快速的访问某一些页面,获取其中的关键信息。通过对页面设置访问频率基线,可以对此类爬虫起到一定的防御作用
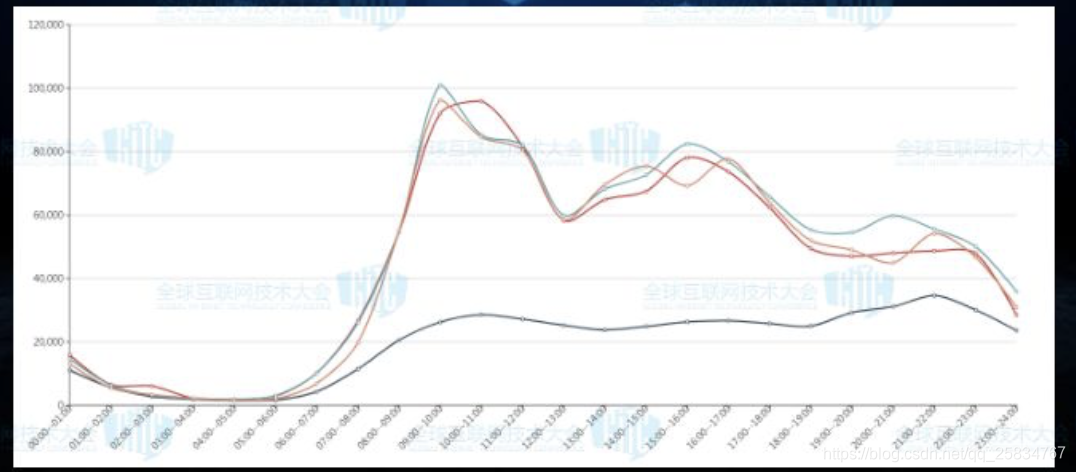
几乎所有业务接口的访问量都是随着时间变化的,如何设定访问频率阈值,这将是一项巨大的挑战。对于没有分时段阈值的系统,为了避免业务受到影响,通常会根据业务峰值数据上调10%-20%,做为阈值上限,但在非业务高峰时段,爬虫行为很难触发这个域值。另外,周期性的业务变化和非周期性的业务变化也需要考虑。对应的阈值必须能够与业务保持同步变化,才能较好的保证阈值的有效性。总体来说频率限制的特点是初期的上线成本较低,但后期阈值的运营成本会不断上升,且防御效果也比较有限。
2.6 JS-Injection
这个方法也是目前业界广泛使用的,在第一次访问请求时,返回注入的js,js执行一些计算逻辑,并将其放入cookie,再次发起请求验证,验证成功后,server向client发放一个token放在cookie里,以后的所有请求都需要携带该cookie标识已认证为非bot身份
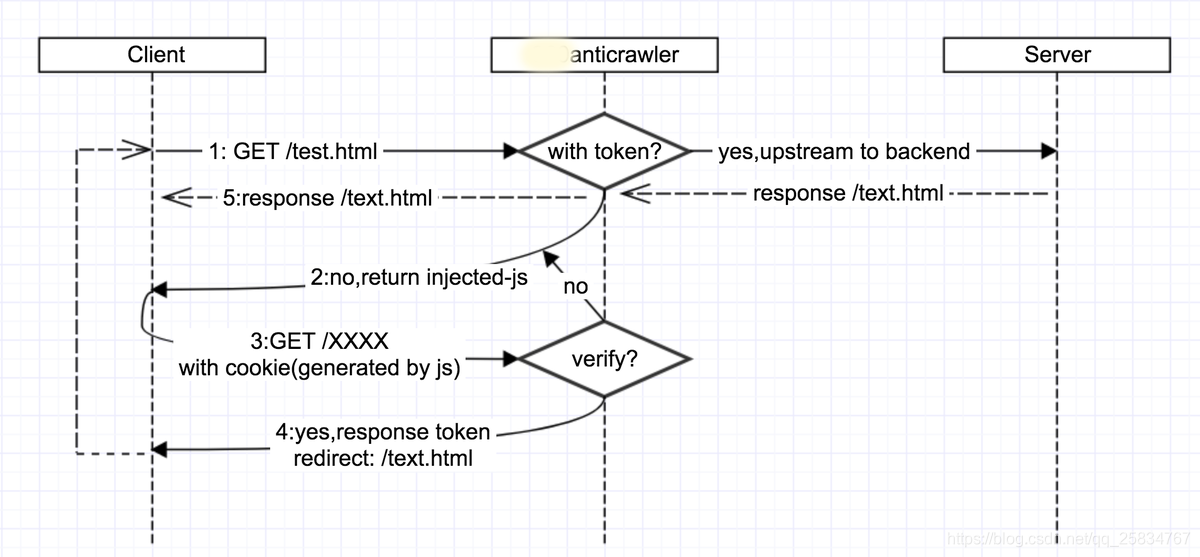
2.7 加密ajax参数
对请求接口返回的json数据进行加密也是一种防爬虫的手法
2.8 部分功能部分封装到接口中
缺陷:chromium 爬虫防范效果差一些,不过chromium爬虫效率低下,需要配合前端对chromium的检测
2.9 轨迹模型
对用户浏览网页过程中产生的轨迹 进行机器学习判断是人还是机器,轨迹+CNN算法判断
2.10 ZoombieCookie
僵尸cookie是指那些删不掉的,删掉会自动重建的cookie。僵尸cookie是依赖于其他的本地存储方法,例如flash的share object,html5的local storages等,当用户删除cookie后,自动从其他本地存储里读取出cookie的备份,并重新种植。
zoombie cookie + 设备指纹 = 唯一用户
使用ZoombieCookie 持久化存储Cookie 增加用户伪造难度,解决设备指纹无法完全标识用户问题
2.11 用户画像
通过用户注册信息,结合用户的历史行为数据,对用户进行画像。从而分析用户的异常行为
2.12 反爬虫蜜罐
威胁情报一方面可以依靠反爬虫蜜罐,一个设置巧妙的蜜罐会极大的提升反爬虫系统的效率和准确性,反之,不仅起不到什么作用甚至可能会影响正常用户
2.13 Canvas 的指纹
Canvas是HTML5中动态绘图的标签。基于Canvas绘制特定内容的图片,使用canvas.toDataURL()方法返回该图片内容的base64编码字符串。对于PNG文件格式,以块(chunk)划分,最后一块是一段32位的CRC校验,提取这段CRC校验码便可以用于用户的唯一标识。
测试结果表明,同一浏览器访问该域时生成的CRC校验码总是不变,基于HTML Canvas生成的UUID可以有效的用于用户追踪技术
风险拦截:
对已经确定为爬虫的请求进行防御操作
1.验证码
各种各样、千奇百怪的验证码。数字、字母加干扰线、噪点,字母重叠摆放,文字点选,滑动拼图,图片选择,点击验证,鼠标轨迹等等,无论何种形式的验证码,其根本目的都是为了实现人机识别,通过交互来验证发起请求的是人还是机器
2.短信(邮件)
其目的和方式与图形(点选)验证码基本相同,只是在实现方法上略有差异,用户需要通过第三方平台(手机号或邮箱)进行用户身份验证,短信邮件独立拿出来说一下。是因为一般情况下,使用图形(点选)验证码,用户可以在3-5秒内完成验证动作。短信验证验证码的验证时间在10-15秒左右,邮件和短信验证码的验证时都会在30秒以上。因此,这类验证方式对用户体验有相对较大的影响,防御效果总体优于图形验证码
3.假数据:
针对恶意用户制造假数据
4.封禁
直接封禁恶意用户
5.监控:
监控恶意用户,进行恶意分析
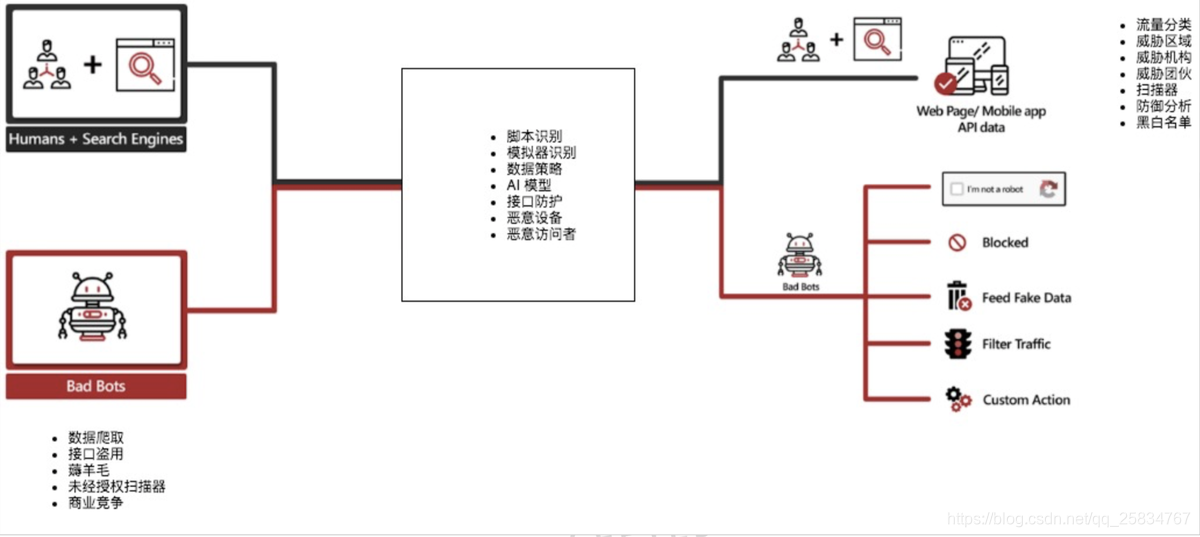
反爬虫系统设计:
分析了3个反爬虫架构,架构大体上都非常的相似,其实和waf的实现雷同。这是其中一个架构图
法律层面:
数据安全管理办法(征求意见稿)
第十六条 网络运营者采取自动化手段访问收集网站数据,不得妨碍网站正常运行;此类行为严重影响网站运行,如自动化访问收集流量超过网站日均流量三分之一,网站要求停止自动化访问收集时,应当停止。
反爬厂商:
瑞数,百度,极验,白山,知道创宇,邦盛科技,岂安
写在最后
对网页内容的抓取与反制,注定是一个魔高一尺道高一丈的猫鼠游戏,你永远不可能以某一种技术彻底封死爬虫程序的路,你能做的只是提高攻击者的抓取成本,并对于未授权的抓取行为做到较为精确的获悉。

















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









