







查询优化,不涉及修改应用、数据库配置、架构等
1、发现慢查询SQL
1.1、增加mysql慢查询配置
vim /etc/my.cnf
[mysqld]
# 开启慢查询功能
slow_query_log = ON
# 慢查询日志
slow_query_log_file = /usr/local/mysql/data/izwz9f6ny09ico7zccpy51z-slow.log
# 超过2秒的SQL即为慢查询
long_query_time = 2
1.2、数据库连接池使用druid
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.6</version>
</dependency>
# 超过2秒即为慢查询,可通过ip:port/driud/index.html查看
spring.datasource.druid.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=2000
1.3、切面耗时统计

2、优化实战
2.1、表结构
前言:表数据皆为随机生成,身份证号、手机号、姓名、微信号等若有相同,纯属巧合。生成的数据仅用于测试说明问题,不必理会合理性。
2.1.1、【用户表】t_user
数据量:150w
| 名 | 类型 | 注释 |
|---|---|---|
| id | varchar | 用户标识,主键 |
| name | varchar | 姓名 |
| nick_name | varchar | 昵称 |
| id_card_no | varchar | 身份证号 |
| sex | tinyint | 性别 |
| phone | varchar | 手机号 |
| varchar | 邮件 | |
| varchar | 微信号 |
2.1.2、【用户详情】t_user_detail
说明:体现和表t_user的一对一关系,数据量:150w
| 名 | 类型 | 注释 |
|---|---|---|
| id | varchar | 用户详情标识,主键 |
| user_id | varchar | 用户id |
| height | double | 身高,单位米,两位小数 |
| live_address | varchar | 居住地 |
| birth_address | varchar | 出生地 |
| marital | tinyint | 婚否 |
| school | varchar | 毕业院校 |
| company | varchar | 公司 |
2.1.3、【收货地址】t_delivery_address
说明:体现和表t_user的一对多关系,数据量:150w
| 名 | 类型 | 注释 |
|---|---|---|
| id | varchar | 标识,主键 |
| user_id | varchar | 用户id |
| tag | varchar | tag:公司,家等 |
| address | varchar | 地址详情 |
| default_flag | tinyint | 是否是默认的地址 |
| receiver | varchar | 收件人名字 |
| phone | varchar | 收件人手机号 |
2.1.4、【就读院校】t_school
说明:体现和表t_user的多对多关系,关系由2.1.5表t_user_school_rel维护,数据量:100
| 名 | 类型 | 注释 |
|---|---|---|
| id | varchar | 标识,主键 |
| name | varchar | 名称 |
| level | tinyint | 院校等级,一本,二本,三本。。。 |
| total | int | 总人数 |
| address | varchar | 坐落地址 |
2.1.5、【用户与就读院校关系表】t_user_school_rel
数据量:150w
| 名 | 类型 | 注释 |
|---|---|---|
| id | varchar | 标识,主键 |
| user_id | varchar | 用户id |
| school_id | tinyint | 院校id |
2.2、优化查询的建议
2.2.1、列出所需的列名,不要使用select * from table
Q1: 查询1万个江苏省连云港市海州区出生的用户
SQL1:select * from t_user where id_card_no like '320706%' limit 10000;
SQL1 耗时:8.028s
SQL2: select id, name, id_card_no, phone from t_user where id_card_no like '320706%' limit 10000;
SQL2 耗时:4.539s
<--------------------------------------------------------------------------------------------------------------------->
Q2:查询以“求大学”为后缀毕业的用户
SQL3:select * from t_user u inner join (select * from t_user_detail where school like '%求大学') detail on u.id = detail.user_id;
SQL3耗时:30.035s
SQL4:select * from t_user u inner join (select user_id from t_user_detail where school like '%求大学') detail on u.id = detail.user_id
SQL4耗时:16.422s
一般列表查询,不会返回1万条数据,但是在联表查询时,会形成中间表或者子表,这些中间表或字表的数据量有时比较大,select少一个字段,就会有明显效果。
2.2.2、用联表代替in操作
当in的数据量较大时(in中的数据量占总数据量30%左右),可能会导致索引失效,故使用联表的方式,仍可能存在优化空间,尽量使用inner join代替left/right join。
Q2:查询以“求大学”为后缀毕业的用户
SQL5:select * from t_user where id in (select user_id from t_user_detail where school like '%求大学') limit 1000;
SQL5耗时:1.426s
SQL6:select * from t_user u inner join (select user_id from t_user_detail where school like '%求大学') detail on u.id = detail.user_id limit 1000;
SQL3耗时:0.246s
2.2.3、合理使用in和exists
1> 使用in:外表大,内表小
2> 使用exists:外表小,内表大
Q3:查询被用户使用且有效的院校详情
SQL7:select SQL_NO_CACHE * from t_school s where EXISTS (select 1 from t_user_detail d where s.name = d.school)
SQL7耗时:0.408s
SQL8:select SQL_NO_CACHE * from t_school where name in (select school from t_user_detail)
SQL8耗时:5.247s
此处t_user_detail(150w条数据)为内表,t_school(100条数据)为外表
<--------------------------------------------------------------------------------------------------------------------->
SQL9:select distinct school from t_user_detail d where exists (select 1 from t_school s where s.name = d.school)
SQL9耗时:36.618s
SQL10:select distinct school from t_user_detail where school in (select name from t_school)
SQL10耗时:15.949s
此处t_user_detail(150w条数据)为外表,t_school(100条数据)为内表
2.2.4、尽量使用union all代替union
union会去除重复行,union all不会,而有些集合,已知是不重复的,就可以使用union all,以提高效率。
注:union并不是很有效的方式
1、每个被合并的SQL集合,是串行执行的
SQL11:select sleep(2) from dual union all select sleep(4) from dual;
SQL11耗时:6.247s
2、当对应的列类型不一致,但又可以转换时,MySQL会隐式转换
sex是tinyint,name是varchar,从结果看,是将sex转成了name所属的类型,如果SQL还要对和并后的结果做条件查询,由于存在隐式转换时,索引将会失效
SQL12:
select sex from t_user where id = '0025699572a44bcd89eeb98f7cd0c1bc'
union all
select name from t_user where id = '002550a6309f4dbd88268d8207e78a76'
返回结果:
sex
0
刁瑗
说明:如果集合的对应的列名不一致,返回结果将使用第一行的列名
2.2.5、分页优化
由于3.1中的表数据都只有150万,分页还看不出明显的差异,此处生成了15000000数据量的订单表t_order
| 名 | 类型 | 注释 |
|---|---|---|
| id | bigint | 标识,主键 |
| user_id | bigint | 用户id |
| price | decimal | 价格 |
| sign_time | varchar | 时间 |
Q4:订单分页查询,pageNum=14000000,pageSize=10
SQL13: select * from t_order limit 14000000, 10
SQL13耗时:2.738s
SQL14:select * from t_order where id >= (select id from t_order limit 14000000, 1) limit 10
SQL14耗时:2.066s
SQL15:select o1.* from t_order o1 inner join (select id from t_order limit 14000000, 10) o2 on o1.id = o2.id
SQL15耗时:2.036s
说明:由于查询条件比较简单,且有索引,所以需要较大的数据量才能看出一些的差异,从结果上看,SQL14和SQL15的效率比SQL13高,如果id是自增类型,且没有删除数据,还存在更加简单和高效的方式
2.2.6、尽量使用distinct代替group by
distinct和group by都可以去重,但是在没有索引时,distinct效率比group by高些,原因是distinct不需要进行排序
Q5: 查询用户有多少种性别
SQL16:select count(distinct sex) from t_user
SQL16耗时:0.976s
SQL17: select count(1) from (select sex from t_user group by sex) a
SQL17耗时:1.152s
2.2.7、如果确定只有一条数据,添加限制limit 1
如果添加了limit 1,只要找到了满足条件的数据,就不会再往后寻找。如果条件是唯一索引,可能没有差异,如果有索引,但索引不唯一,差异可能不明显,但如果没有索引,就会存在较为明显的差异。
Q6:查询身份证号为530600200807144236的用户详情(身份证号无索引)
SQL18: select * from t_user where id_card_no = '530600200807144236'
SQL18耗时:1.355s
SQL19: select * from t_user where id_card_no = '530600200807144236' limit 1
SQL19耗时:0.382s
注:如果身份证号没有创建唯一索引,当存在相同身份证号的用户信息时,不加limit 1时,会返回一个对象集合,而mybatis使用一个对接接收,也会抛出异常
说明:暂时想到这么多,若有新增,后续再补充
2.3、索引的优化查询
2.2中的优化建议,都没有涉及到索引,而要高效查询,索引必不可少
2.3.1、索引是什么
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库的表结构。如果数据库是一本字典,那字典前面,按照拼音查字,按照笔画查字,就是字典的索引。如果数据库是通讯录,那通讯录的A,B,C…Z就是索引。如果数据库是一本书,那目录就是索引。总之,索引就是帮助快速查询的,但并不是所有的索引,都会提高查询效率,所以如何创建索引,也很重要。
2.3.2、常见索引类型
1、按照唯一性分
1.1、主键索引
具有唯一性,可以是多列组合而成,也可以是单独的某一列,索引和数据是放在一起的,也称聚簇索引。
1.2、唯一索引
主键索引是一种特殊的唯一索引,唯一索引在入库前,都会检查索引数据的唯一性。
1.3、普通索引
基本的索引类型,没有特别特性,可以为空,没有唯一性控制,适用于快速查询
2、按照列数量分
2.1、单列索引
索引由一列组成
2.2、组合索引
索引由多列组成,如a,b,c,d组成索引
3、按照数据和索引的位置分
3.1、聚簇索引
数据和索引存放在一起,命中索引,即可取出数据,不用进行回表查询。mysql默认主键就是聚簇索引,如果没有主键,会找从列中找一个非空唯一的列作为聚簇索引
3.2、非聚簇索引
数据和索引是分开存放的,命中索引后,要到聚簇所在的地方取数据,才能查看整条完整的数据。
说明:索引是经过排序的,有索引的表,在插入数据时,速度会慢一些。3.2.6章节中,如果去重的字段是索引,group by即使要排序,效率和distinct差不多,是因为索引已经排好序了。这也是为什么使用自增的主键,效率是最高的,因为插入时,不需要找寻当前插入数据的位置。
2.3.3、索引的长度
1、各字符集占用空间
latin1:
1 character=1byte, 1汉字=2 character,
也就是说一个字段定义成 varchar(100),则它可以存储50个汉字或者100个字母。
utf8:
1 character=3bytes, 1汉字=1 character
也就是说一个字段定义成 varchar(100),则它可以存储100个汉字或者100个字母。
gbk:
1 character=2bytes,1汉字=1 character
也就是说一个字段定义成 varchar(100),则它可以存储100个汉字或者100个字母。
2、各类型占用空间
| 数据类型 | 占用空间(byte) |
|---|---|
| TINYINT | 1 |
| SMALLINT | 2 |
| MEDIUMINT | 3 |
| INT, INTEGER | 4 |
| BIGINT | 8 |
| FLOAT | 4 |
| TIME | 3 + 小数秒存储 |
| DATETIME | 5 + 小数秒存储 |
| TIMESTAMP | 4 + 小数秒存储 |
| NULL | 1,2 |
| ”“ | 0 |
| 小数秒精度 | 占用空间(byte) |
|---|---|
| 0 | 0 |
| 1, 2 | 1 |
| 3, 4 | 2 |
| 5, 6 | 3 |
2.1、如3.2.5订单表t_order
CREATE TABLE t_order (
id bigint(20) NOT NULL DEFAULT ‘0’,
user_id bigint(20) DEFAULT NULL,
price decimal(10,2) DEFAULT NULL,
sign_time varchar(20) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
通过explain查看key_len的长度为8
2.2、如3.1用户表t_user
CREATE TABLE t_user (
id varchar(32) COLLATE utf8_bin NOT NULL COMMENT ‘用户标识’,
name varchar(20) COLLATE utf8_bin DEFAULT NULL COMMENT ‘姓名’,
nick_name varchar(40) COLLATE utf8_bin DEFAULT NULL COMMENT ‘昵称’,
id_card_no varchar(20) COLLATE utf8_bin DEFAULT NULL COMMENT ‘身份证号’,
sex tinyint(1) DEFAULT NULL COMMENT ‘性别’,
phone varchar(15) COLLATE utf8_bin DEFAULT NULL COMMENT ‘手机号’,
email varchar(40) COLLATE utf8_bin DEFAULT NULL COMMENT ‘邮件’,
wechat varchar(20) COLLATE utf8_bin DEFAULT NULL COMMENT ‘微信号’,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT=‘用户’
通过explain查看key_len的长度为:32 * 3 + 2 = 98;
utf-8一个字符占用3个字节,长度可变+2,如果是普通索引,可以为空+1。
故索引长度 = 字符集占用空间*列长度 + 是否为空 + 是否可变
结论:
1、数值类型的索引,比字符串更节省空间,且在插入数据时,需要根据主键的值找到合适的位置,又数值类型比较,快于字符串类型,所以选择数值类型作为主键,优于字符串类型。
2、字段也尽量选择占用空间小的,这样相同的空间,可以存放更多的索引和数据。如果你不知道如何优化列类型,可借助PROCEDURE ANALYSE()帮你完成。如下图所示,最后一列就是mysql建议的列类型。从建议可以看出,如果没有空值,就建议显示声明,长度不变的,尽量声明为不可变的,这样可以节省空间。

2.3.4、创建索引的建议
1、尽可能创建唯一索引
唯一索引的搜索,快于普通索引,但插入数据时的效率稍慢于普通索引
Q7: 根据用户敖武武的身份证号查询用户详情
SQL20:select * from t_user where id_card_no = '320706195205031112'
SQL20耗时:1.388s
-- 将身份证号设置为普通索引
alter table t_user add index(id_card_no)
SQL20耗时:0.387s
-- 由于入库时,没有将身份证号设置为唯一,导致存在一些重复的,删除重复数据,并将普通索引改为唯一索引, 数据量1497292
alter table t_user add unique(id_card_no)
SQL20耗时:0.243s
2、尽量不要在重复值较多的列创建索引
如性别,只有男,女,未知等少数值,并不适合创建索引
3、在联表字段添加索引
在数据量较大时,索引的效果会非常显著
Q8:根据用户敖武武的id查询毕业院校详情
SQL21:select * from t_user u left join t_user_school_rel rel on u.id = rel.user_id left join t_school s on rel.school_id = s.id where u.id = '0000bc017fc14cda9bd3ea0bd8f733ab'
SQL21耗时:0.974s
-- 添加联表字段索引
alter table t_user_school_rel add index user_school_idx (user_id, school_id);
SQL21耗时:0.241s
4、单表索引数量建议不超过5个
5、尽量创建组合索引
6、在一些特定位置的列创建索引
6.1、出现在 SELECT、UPDATE、DELETE 语句的 WHERE 从句中的列创建索引
6.2、在 ORDER BY、GROUP BY、DISTINCT 中的列创建索引
并不要将符合 6.1 和 6.2 中的字段的列都建立一个索引, 通常将两处的列建立联合索引效果更好。如查询列表时,需要按照创建时间排序,则可以将该字段添加为索引。
2.4、索引失效的场景
2.4.1、存在隐私或显示转换
1、隐私转换,当列类型和值的类型不一致时,容易发生隐私转换,如id_card_no是字符串类型,220281197710263190是数值类型,此时会导致隐私转换
select * from t_user where id_card_no = 220281197710263190;
2、显示转换,将索引字段进行运算后再参与比较,这种运算包括函数
select * from t_user where id_card_no + "" = '220281197710263190';
select * from t_user where id_card_no = '220281197710263190' + '';
注意:在联表查询时,on中条件的列类型不一致,但是执行没有报错,也是发生了隐私转换,索引也会失效
2.4.2、不符合最左原则
单列索引和组合索引,都有从左匹配的特性。最左匹配原则:一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配
1、单列索引
单列索引就好比在字典中根据拼音查字,中:zhong,如果第一个字母z不知道,那可能是chong,既然无法确定,只能全部都找一遍,就这样索引失效了。
2、组合索引
组合索引就好比在字典中根据拼音查词语,泪水,如果不知道第一个字泪,那词语可能是眼泪,既然不确定,也只好全部都找一遍。
这种不确定性,可以是%,也可以是_,%表示多个未知的,_表示一个未知的
-- 索引失效
select * from t_user where id_card_no like '_20000197307088297';
-- 索引生效
select * from t_user where id_card_no like '12000019730708%'
2.4.3、!= 、<> 、is not null
select * from t_user where id_card_no <> ‘120000197307088297’ 会导致索引失效
2.4.4、in数据量较大、not in回表
以下sql可通过explain + sql查看是否走索引
-- 【走索引】in的数据量较少时,走索引
select * from t_user where id in ('00006f5053ff4dd1aaa6ea812f7cccc0')
-- 【不走索引】in的数据量较大时,不走索引,大约多余总数据量的30%
select * from t_user where id in (select user_id from t_user_detail)
-- 【走索引】根据id查出数据后,因为id是聚簇索引,故数据和索引是放在一起的,不需要回表查询,not in会走索引
select * from t_user where id not in ('00006f5053ff4dd1aaa6ea812f7cccc0')
-- 【不走索引】根据id_card_no查出数据,因为id_card_no是非聚簇索引,需要回表,才能查出详情,not in不走索引
select * from t_user where id_card_no not in ('320706195909232131')
-- 【走索引】根据id_card_no查出数据,select的列只有id_card_no,,即使id_card_no是非聚簇索引,是不需要回表查询的,not in走索引
select id_card_no from t_user where id_card_no not in ('320706195909232131');
2.4.5、or连接的条件存在不是索引的列
-- 【走索引】 id_card_no和id都是索引,索引生效
select * from t_user where id_card_no= '320706195909232131' or id = '000063437bc140928d7eae38b8f3a1b2';
-- 【不走索引】name不是索引,索引失效
select name from t_user where id_card_no= '320706195909232131' or name = '张三';
3、相关名词
3.1、索引覆盖和回表查询
了解回表查询之前,先了解聚簇索引和非聚簇索引的结构。假设表格t_test有如下数据
| column1 | column2 | column3 | column4 |
|---|---|---|---|
| 1 | sj | m | A |
| 3 | zs | m | A |
| 5 | ls | m | A |
| 9 | ww | f | B |
1、如下图所示为聚簇索引,特点是数据和索引,放在一起,命中索引,即可取出对应的数据
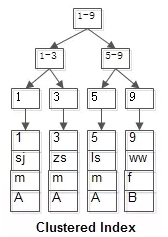
2、如下图所示为非聚簇索引,特点是只有索引,没有整行数据,索引的叶子节点,存放的是数据的主键。
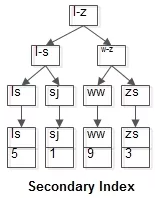
3、回表查询
-- 查询column2='ww'的详情
select * from t_test where column2 = 'ww';
1、根据非聚簇索引column2,找到column2='ww'所在数据的非聚簇索引,即column1=9
2、由于返回的是”*“,代表返回所有的列,即column1、column2、column3、column4,但在非聚簇索引的叶子节点,只有column1
3、所以通过column1=9,再去聚簇索引中找到column1=9的数据,从而查询出整条数据"column1=9、column2=ww、column3=f、column4=B"
说明:第三步也称回表查询,所以为了提高效率,应该尽量避免回表查询。单列索引在非聚簇索引的叶子节点存放的数据只有一列,如果是组合索引,就是多列,很容易避免回表查询,所以返回需要的列,代替”*“也很关键。
4、索引覆盖
select column2 from t_test where column2 not in ('ww');
由3可知,非聚簇索引的叶子节点,存放的数据就是column2,返回的列也只有column2,这种返回结果已经存在于索引上的情况,就是索引覆盖
3.2、索引下推
SQL1: select * from t_user where name = '钟义新' and phone = '13708817332';
SQL1耗时:1.358s
SQL2: select * from t_user where name like '钟%' and phone = '13708817332';
SQL2耗时:1.358s
-- 创建组合索引
create index name_phone on t_user (name, phone);
-- 会索引下推
SQL3: select * from t_user where name like '钟%' and phone = '13702220393';
SQL3耗时:0.390s
SQL4: select SQL_NO_CACHE * from t_user where name like '钟%' and phone like '1370222039%';
SQL4耗时: 0.388s
-- 不会索引下推
SQL5:select SQL_NO_CACHE * from t_user where name = '钟义新' and phone = '13702220393'
SQL5耗时:0.389s
SQL6: select SQL_NO_CACHE * from t_user where name = '钟义新' and phone = '13702220393';
SQL6耗时:0.389s
索引下推,只会出现在组合索引中,且只有存在失效的组合索引列。
| name | phone |
|---|---|
| 钟世和 | 13105241923 |
| 钟世奇 | 13702220393 |
| 钟世心 | 13806577640 |
| 钟世敬 | 13106004535 |
| 钟世震 | 13603427576 |
| 钟世东 | 13708817332 |
eg: select * from t_user where name like ‘钟%’ and phone = ‘13702220393’
select * from t_user where name like ‘钟%’ 由于name是范围查询,根据最左匹配原则(3.4.2章节),phone列查询将不会生效。条件查询有多条记录。
在5.6版本之前,拿到所有符合条件的数据,进行回表查询,然后将结果返回到server层,server层再根据phone的条件进行过滤。
在5.6版本之后,由于索引下推,server层将phone的过滤条件,交给了存储引擎层判断,这样可以过滤掉一些不符合条件的数据,从而减少回表查询的数量。存储引擎层可以对下推的索引进行判断,前提是组合索引中存在phone值,不然无法拿到phone值进行判断/过滤。
3.3、前缀索引
索引不一定要具体的某一个列,也可以是某个列的一部分,如身份证号的前6位,即可快速查找到同县人。
aler table t_user add index county(id_card_no(6));
3.4、驱动表
连接查询时,原则是小表驱动大表。
左连接,驱动表为左边的表,右连接,驱动表为右边的表,故如果有条件,应该先通过条件过滤,缩小驱动表的数据范围。
内连接时,mysql会自动选择小表为驱动表。驱动表可通过explain查看,id相同时,上面为驱动表,id不同时,id大的为驱动表。















 117
117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









