









更新时间:2022年12月16日
本文中使用的操作系统为 RockyLinux 8.7
本文中所有操作均以 Kubernetes 1.24.9 为基准
kubeadm 简介
官网简介:Kubeadm | Kubernetes
Kubeadm 是快速创建 Kubernetes 集群的官方工具。它不仅提供了 kubeadm init 和 kubeadm join 命令用于创建、加入集群,还可以用于在线升级、管理证书等应用
kubeadm 通过执行必要的操作来启动和运行最小可用集群。 按照设计,它只关注启动引导,而非配置机器。同样的, 安装其他的扩展,例如 Kubernetes Dashboard、 监控方案、以及特定云平台的扩展,都不在 kubeadm 使用范围内
理想情况下,使用 kubeadm 作为所有部署工作的基准将会更加易于创建一致性集群
安装 kubeadm 及相关组件
kubeadm 官方安装参考:安装 kubeadm | Kubernetes
Kubernetes 版本选择
Kubernetes 最近发布版本列表:Releases | Kubernetes
Kubernetes 所有发布版本列表:Releases · kubernetes/kubernetes (github.com)
本文选择安装 Kubernetes 1.24.9
注意事项
- 一台兼容的 Linux 主机。Kubernetes 项目为基于 Debian 和 Red Hat 的 Linux 发行版以及一些不提供包管理器的发行版提供通用的指令
- 每台机器 2 GB 或更多的 RAM(如果少于这个数字将会影响你应用的运行内存)
- 2 CPU 核或更多
- 集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)
- 节点之中不可以有重复的主机名、MAC 地址或 product_uuid
- 允许 iptables 检查桥接流量
- 禁用交换分区。为了保证 kubelet 正常工作,你 必须 禁用交换分区
- 启用一些必要的端口,详见 附录-防火墙端口与协议,测试环境可以直接关闭防火墙以放行端口
主机设置
检查 MAC 与 product_uuid
- 使用命令
ip link或ifconfig -a来获取网络接口的 MAC 地址 - 使用
sudo cat /sys/class/dmi/id/product_uuid命令对 product_uuid 校验
一般来讲,硬件设备会拥有唯一的地址,但是有些虚拟机的地址可能会重复。 Kubernetes 使用这些值来唯一确定集群中的节点。 如果这些值在每个节点上不唯一,可能会导致安装失败
允许 iptables 检查桥接流量
确保 br_netfilter 模块被加载。这一操作可以通过运行 lsmod | grep br_netfilter 来完成。若要显式加载该模块,可执行 sudo modprobe br_netfilter。
为了让你的 Linux 节点上的 iptables 能够正确地查看桥接流量,你需要确保在你的 sysctl 配置中将 net.bridge.bridge-nf-call-iptables 设置为 1。例如:
# 加载 br_netfilter 模块(系统启动时加载)
$ cat > /etc/modules-load.d/kubernetes.conf <<EOF
br_netfilter
EOF
# 加载 br_netfilter 模块(立刻加载,重启依旧生效)
$ sudo modprobe br_netfilter
# 配置允许 iptables 检查桥接流量
$ cat > /etc/sysctl.d/kubernetes.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-arptables = 1
EOF
# 应用配置
$ sudo sysctl --system
禁用交换分区
临时禁止
# 临时禁止,重启后恢复,适用于不能重启的主机
$ swapoff -a
永久禁止
# 永久禁止,注释 /etc/fstab 中与 swap 相关的行,重启依旧有效
$ sed -ri '/^[^ ].*swap/ s/(.*)/# \1/g' /etc/fstab
防火墙设置
firewalld 设置参考:附录-防火墙端口与协议,新手建议直接关闭
SELinux 建议禁用
# 禁用 SELinux
$ setenforce 0 && sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
优化参数
优化内核参数及资源限制参数,详见 附录-参数优化
IPVS 模式设置
参考:run-kube-proxy-in-ipvs-mode
IPVS 拥有比 iptables 更好的网络转发性能,生产中推荐使用 IPVS 模式
安装依赖软件
ipset RockyLinux 8.7 默认已经安装
ipvsadm 方便查看规则,推荐安装
dnf -y install ipset ipvsadm
加载内核模块
注:在标准 Linux kernel 4.19 之后,使用 nf_conntrack 替代 nf_conntrack_ipv4;RockyLinux 8.7 预更新了后续内核的部分内容,所以也使用 nf_conntrack
# 配置系统启动时加载模块
$ cat > /etc/modules-load.d/kube-ipvs.conf <<EOF
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
EOF
# 立刻加载模块
$ modprobe -- ip_vs
$ modprobe -- ip_vs_rr
$ modprobe -- ip_vs_wrr
$ modprobe -- ip_vs_sh
$ modprobe -- nf_conntrack
# 检查是否已加载
$ lsmod | grep -e ip_vs -e nf_conntrack
安装容器运行时
kubernetes 集群的每个节点均需要安装容器运行时
容器运行时官方详解:容器运行时 | Kubernetes
注:在 Kubernetes 1.24 版本往后,Kubernetes 不再包含 dockershim,若使用 docker 作为容器运行时,则需手动安装 cri-docker,cri-docker 地址:GitHub - Mirantis/cri-dockerd
选择容器运行时
目前 Kubernetes 支持几种通用容器运行时
本文使用 containerd 1.4.12 作为容器运行时,其他容器运行时并无太大区别
容器运行时版本选择需要参考 Kubernetes 的版本兼容情况,可以在 Kubernetes 最近版本列表页面 或 Kubernetes 所有版本列表页面 点击对应的版本的 Changelog 进行查看(如果没有找到版本信息则表示与上一版本支持情况相同)。
安装容器运行时
操作系统以 Rocky Linux release 8.7 为例
安装 containerd
# 下载 containerd 二进制包
$ curl -LO https://github.com/containerd/containerd/releases/download/v1.4.12/containerd-1.4.12-linux-amd64.tar.gz
# 解压
$ tar Cxzvf /usr/local containerd-1.4.12-linux-amd64.tar.gz
bin/
bin/ctr
bin/containerd
bin/containerd-shim
bin/containerd-stress
bin/containerd-shim-runc-v2
bin/containerd-shim-runc-v1
# 创建 service 目录
$ mkdir -p /usr/local/lib/systemd/system/
# 下载 service 文件
$ curl -o /usr/local/lib/systemd/system/containerd.service https://raw.githubusercontent.com/containerd/containerd/main/containerd.service
# 重新加载 service 文件
$ systemctl daemon-reload
# 配置开机启动
$ systemctl enable --now containerd
安装 runc
# 下载 runc
$ curl -LO https://github.com/opencontainers/runc/releases/download/v1.1.4/runc.amd64
# 安装 runc
$ install -m 755 runc.amd64 /usr/local/sbin/runc
安装 cni 插件
# 下载
$ curl -LO https://github.com/containernetworking/plugins/releases/download/v1.1.1/cni-plugins-linux-amd64-v1.1.1.tgz
# 创建目录
$ mkdir -p /opt/cni/bin
# 解压
$ tar Cxzvf /opt/cni/bin cni-plugins-linux-amd64-v1.1.1.tgz
其他配置
注:不同版本的 containerd 默认配置略有不同,请根据实际生成的默认配置进行修改
配置 DockerHub 的镜像加速(推荐配置)、存储驱动(可选,必须在初始化集群前配置)等参数
# 生成默认配置
$ mkdir -p /etc/containerd/
$ containerd config default > /etc/containerd/config.toml
# 设置 sandbox_image 镜像源设置为阿里云 google_containers 镜像源
$ sed -ri "s#registry.k8s.io#registry.aliyuncs.com/google_containers#g" /etc/containerd/config.toml
$ sed -ri "s#k8s.gcr.io#registry.aliyuncs.com/google_containers#g" /etc/containerd/config.toml
# 添加 Systemdcgroup 设置
$ sed -ri '/runtimes\.runc\.options/a\ SystemdCgroup = true' /etc/containerd/config.toml
# 修改镜像加速地址
$ sed -ri 's@( +endpoint) =.*@\1 = ["https://sqr9a2ic.mirror.aliyuncs.com"]@g' /etc/containerd/config.toml
# 重启使配置生效
$ sudo systemctl restart containerd
配置 crictl 命令
$ cat > /etc/crictl.yaml << EOF
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 2
debug: false
pull-image-on-create: true
EOF
安装 kubeadm、kubelet 和 kubectl
操作系统以 Rocky Linux release 8.7 为例
建议三个工具版本一致,如果工具版本不能够一致,参考版本差异文档进行选择:Version Skew Policy | Kubernetes
Kubernetes 集群的每个节点均需要安装 kubeadm、kubelet、kubectl
-
kubelet 原则上不需要在控制面节点上运行。但是 kubeadm 构建集群时,apiserver、controller-manager、scheduler、etcd 等服务是运行在容器上的,需要由 kubelet 进行调度,所以需要在控制面节点安装 kubelet
-
kubectl 原则上可以只在需要与集群通信的节点(一般为控制面节点)安装,但 kubeadm 命令依赖于 kubectl,故所有节点均需安装
软件作用
kubeadm:用于初始化集群的管理指令kubelet:用于在集群中的每个节点上用来启动 Pod 和容器等kubectl:用来与集群通信的命令行工具
安装
由于官网镜像在国内下载较慢,此处使用阿里云镜像站,安装方法参考:kubernetes安装教程-阿里巴巴开源镜像站 (aliyun.com)
添加仓库
添加阿里云的 Kubernetes YUM 仓库
$ cat > /etc/yum.repos.d/kubernetes.repo <<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
安装
注:由于 kubernetes 官网未开放同步方式, 可能会有索引 gpg 检查失败的情况,可以在使用 dnf 时忽略 gpg 检查
# 查看版本
$ dnf list kubeadm --showduplicates --nogpgcheck | sort -r
# 安装 kubelet kubeadm kubectl 指定版本( node 节点可以不安装 kubectl )
$ dnf install -y --nogpgcheck \
kubelet-1.24.9-0.x86_64 \
kubeadm-1.24.9-0.x86_64 \
kubectl-1.24.9-0.x86_64
# 配置 kubelet 开机启动
$ systemctl enable kubelet
检查版本
$ kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"24", GitVersion:"v1.24.9", GitCommit:"9710807c82740b9799453677c977758becf0acbb", GitTreeState:"clean", BuildDate:"2022-12-08T10:13:36Z", GoVersion:"go1.18.9", Compiler:"gc", Platform:"linux/amd64"}
安装完成后,kubelet 每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环
配置驱动(重要)
由于 kubeadm 把 kubelet 视为一个系统服务来管理,所以对基于 kubeadm 的安装 k8s 时, 官方推荐使用 systemd 作为 cgroup 的驱动,不推荐 cgroupfs 。但是容器运行时(此处为 containerd)默认的 cgroup 的驱动一般都是 cgroupfs。两者的 cgroup 驱动不一致时,会出现如下错误,导致 kubelet 运行异常
kubelet cgroup driver: “systemd” is different from docker cgroup driver: “cgroupfs”
需要修改容器运行时与 kubelet 的 cgroup 驱动保持一致,推荐修改容器运行时的 cgroup 驱动为 systemd
方式一:配置容器运行时的 cgroup 驱动
其他容器运行时配置的方法,请参考官方文档:容器运行时 | Kubernetes
在 containerd 的配置文件中配置 cgroup 驱动
# 添加 Systemdcgroup 设置
$ sed -ri '/runtimes\.runc\.options/a\ SystemdCgroup = true' /etc/containerd/config.toml
重启 containerd 使配置生效
sudo systemctl daemon-reload
sudo systemctl restart containerd
方式二:配置 kubelet 的 cgroup 驱动
参考官方文档:配置 cgroup 驱动 | Kubernetes
kubelet 默认 cgroup 的驱动为 systemd ,不推荐修改
使用配置文件初始化时,可以在配置文件中进行设置
# kubeadm-config.yaml
kind: ClusterConfiguration
apiVersion: kubeadm.k8s.io/v1beta3
kubernetesVersion: v1.21.0
---
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
cgroupDriver: systemd
使用配置文件初始化
kubeadm init --config kubeadm-config.yaml
其他依赖软件
tc (Traffic Control)是一款网络和流量控制和模拟工具,kubernetes 集群会用它做一些流量模拟。建议安装(不安装不影响使用)
$ dnf -y install iproute-tc
kubeadm 命令介绍
kubeadm 常用命令
kubeadm init用于搭建控制平面节点kubeadm join用于搭建工作节点并将其加入到集群中kubeadm upgrade用于升级 Kubernetes 集群到新版本kubeadm config如果你使用了 v1.7.x 或更低版本的 kubeadm 版本初始化你的集群,则使用kubeadm upgrade来配置你的集群kubeadm token用于管理kubeadm join使用的令牌kubeadm reset用于恢复通过kubeadm init或者kubeadm join命令对节点进行的任何变更kubeadm certs用于管理 Kubernetes 证书kubeadm kubeconfig用于管理 kubeconfig 文件kubeadm version用于打印 kubeadm 的版本信息kubeadm alpha用于预览一组可用于收集社区反馈的特性
全局选项
全局选项适用于 kubeadm 的所有命令,多为日志相关选项
--add-dir-header # 如果为 true,将在日志头部添加日志目录
--log-file string # 指定输出的日志文件
--log-file-max-size uint # 定义日志文件的最大大小,单位 MB,如果设置为 0,则不限制。默认为 1800
--one-output # 如果为 true,则只写入严重级别的日志
--rootfs string # 指定宿主机路径作为根路径
--skip-headers # 如果为 true,则日志里不显示标题前缀
--skip-log-headers # 如果为 true,则日志里不显示标题
-v, --v Level # 指定日志级别,0 ~ 5
kubeadm init 命令简介
查看帮助
$ kubeadm init --help
常用选项
# 选项较多,此处仅列出较常用的选项
--apiserver-advertise-address string # (重要)API Server 监听的 IP 地址
--apiserver-bind-port int32 # (重要)API Server 绑定的端口,默认为 6443
--apiserver-cert-extra-sans strings # 用于 API Server 服务 SANs 扩展的证书。可以是 IP 地址和 DNS 名称
--cert-dir string # 指定证书存放路径,默认为 "/etc/kubernetes/pki"
--certificate-key string # 指定一个用于加密 kubeadm certs Secret 中的控制平面证书的密钥
--config string # 指定 kubeadm 配置文件路径
--control-plane-endpoint string # (重要)为控制平面指定一个稳定的 IP 地址或 DNS 名称。常用于多 master 时指定统一的 VIP 地址
--cri-socket string # 要连接的 CRI socket 路径。如果为空,kubeadm 将自动检测;仅当安装了多个 CRI 或非标准 CRI socket 时,才会使用此选项
--dry-run # 测试运行,不会应用任何的更改
--feature-gates string # 一组 key=value 键值对,用于开关一些当前版本特有的功能,支持选项如下
PublicKeysECDSA=true|false (ALPHA - default=false)
RootlessControlPlane=true|false (ALPHA - default=false)
UnversionedKubeletConfigMap=true|false (ALPHA - default=false)
--ignore-preflight-errors strings # (重要)是否忽略检查过程中出现的错误信息,例如: 'IsPrivilegedUser'、'Swap'。如果设置为 'all',则忽略所有错误信息
--image-repository string # (重要)指定容器镜像仓库,用于拉取控制面镜像,默认为 "k8s.gcr.io"
--kubernetes-version string # (重要)指定安装的 Kubernetes 版本,默认为 "stable-1"
--node-name string # 指定 node 节点名称
--pod-network-cidr string # (重要)指定 pod 网络的 IP 地址范围。如果设置,控制平面将自动为每个节点分配 CIDR,注意不要与主机网络重叠
--service-cidr string # (重要)指定 service 网络的 IP 地址范围,默认为 "10.96.0.0/12",注意不要与主机网络重叠
--service-dns-domain string # (重要)为服务指定替代域名( k8s 的内部域名),默认为 "cluster.local",会由相应的 DNS 服务(kube-dns/coredns)解析生成的域名记录
--skip-certificate-key-print # 不打印用于加密控制平面证书的密钥信息
--skip-phases strings # 要跳过哪些阶段
--skip-token-print # 跳过打印 'kubeadm init' 生成的默认 token 信息
--token string # 指定用于 node 节点和控制平面节点之间建立双向信任的 token
--token-ttl duration # token 过期时间,例如:1s、2m、3h。如果设置为“0”,令牌将永远不会过期。默认为 24h0m0s
--upload-certs # 将控制平面证书加载到 kubeadm certs Secret,更新证书
创建单节点集群
kubeadm 命令选项和帮助:Kubeadm | Kubernetes
kubeadm 创建集群参考:使用 kubeadm 创建集群 | Kubernetes
主机列表
| 主机名 | 配置 | IP | 角色 | 安装服务 |
|---|---|---|---|---|
| kube-cp.skynemo.cn | 2 核 4 G | 192.168.1.181 | 控制面节点、工作节点 | containerd 1.4.12 kubeadm : 1.24.9 kubelet : 1.24.9 kubectl : 1.24.9 |
安装过程省略,详见:安装 kubeadm 及相关组件
下载镜像
kubeadm 在初始化节点时会从镜像仓库下载镜像,默认镜像仓库由 google 提供(早期仓库地址为:k8s.gcr.io;现仓库地址为:registry.k8s.io),国内无法访问或访问速度较慢。推荐使用阿里云提供的镜像仓库(registry.aliyuncs.com/google_containers),提前下载好所需的镜像,防止在构建过程中因镜像下载异常而导致部署失败
查看所需镜像
# 查看官方镜像
$ kubeadm config images list --kubernetes-version=1.24.9
registry.k8s.io/kube-apiserver:v1.24.9
registry.k8s.io/kube-controller-manager:v1.24.9
registry.k8s.io/kube-scheduler:v1.24.9
registry.k8s.io/kube-proxy:v1.24.9
registry.k8s.io/pause:3.7
registry.k8s.io/etcd:3.5.6-0
registry.k8s.io/coredns/coredns:v1.8.6
# 检查镜像在阿里云是否同样有
$ kubeadm config images list --kubernetes-version=1.24.9 --image-repository registry.aliyuncs.com/google_containers
# 显示镜像列表
registry.aliyuncs.com/google_containers/kube-apiserver:v1.24.9
registry.aliyuncs.com/google_containers/kube-controller-manager:v1.24.9
registry.aliyuncs.com/google_containers/kube-scheduler:v1.24.9
registry.aliyuncs.com/google_containers/kube-proxy:v1.24.9
registry.aliyuncs.com/google_containers/pause:3.7
registry.aliyuncs.com/google_containers/etcd:3.5.6-0
registry.aliyuncs.com/google_containers/coredns:v1.8.6
下载镜像
# 指定 kubernetes 版本、指定仓库进行镜像下载
$ kubeadm config images pull --kubernetes-version=v1.24.9 --image-repository registry.aliyuncs.com/google_containers
查看下载的镜像
配置 crictl 连接信息
$ cat > /etc/crictl.yaml << EOF
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 2
debug: false
pull-image-on-create: true
EOF
查看镜像
$ crictl images
IMAGE TAG IMAGE ID SIZE
registry.aliyuncs.com/google_containers/coredns v1.8.6 a4ca41631cc7a 13.6MB
registry.aliyuncs.com/google_containers/etcd 3.5.6-0 fce326961ae2d 103MB
registry.aliyuncs.com/google_containers/kube-apiserver v1.24.9 ae6cdd144f9d7 33.8MB
registry.aliyuncs.com/google_containers/kube-controller-manager v1.24.9 16e04a3cf5de3 31.1MB
registry.aliyuncs.com/google_containers/kube-proxy v1.24.9 ca65e238774be 39.5MB
registry.aliyuncs.com/google_containers/kube-scheduler v1.24.9 affce73c10985 15.5MB
registry.aliyuncs.com/google_containers/pause 3.7 221177c6082a8 311kB
初始化节点
初始化节点有两种方式
-
基于命令行初始化:适合一些配置简单的场景
-
基于配置文件初始化:适合做一些复杂复杂的场景(命令行未提供的配置,例如配置 kube-proxy 的网络模式,目前只可以通过配置文件进行修改,或者安装后手动修改 kube-proxy 的
configmap)
两种方式不可以同时使用,例如一些配置使用命令行,一些配置使用配置文件;一些命令行选项(非配置类型)可以用在配置文件初始化方式
方式一:基于命令行初始化配置
需要注意以下参数的设置:
apiserver-advertise-address:设置为当前节点的 IPapiserver-bind-port:设置为当前节点 apiserver 绑定的端口control-plane-endpoint:设置 api-server 负载均衡器的 VIP--upload-certs:将在所有控制平面实例之间的共享证书上传到集群
$ kubeadm init \
--apiserver-advertise-address=192.168.111.181 \
--apiserver-bind-port=6443 \
--kubernetes-version=v1.24.9 \
--pod-network-cidr=10.100.0.0/16 \
--service-cidr=10.200.0.0/16 \
--service-dns-domain=skynemo.cn \
--image-repository=registry.aliyuncs.com/google_containers \
--upload-certs \
--ignore-preflight-errors=swap
方式二:基于配置文件初始化配置(推荐)
生成配置文件
# 生成配置文件,并生成 kube-proxy 和 kubelet 的配置
$ kubeadm config print init-defaults --component-configs KubeProxyConfiguration,KubeletConfiguration --kubeconfig '/etc/kubernetes/admin.conf' > kubeadm-init.yaml
修改配置
# 此处只列出主要的配置
$ vim kubeadm-init.yaml
---
apiVersion: kubeadm.k8s.io/v1beta3
......
# 配置本地 api server 地址和端口
localAPIEndpoint:
advertiseAddress: 192.168.111.181
bindPort: 6443
# 配置 kubernetes 节点名称,建议使用主机名
nodeRegistration:
name: kube-cp.skynemo.cn
---
apiServer:
......
# 集群名称
clusterName: kubernetes.skynemo.cn
# 配置镜像下载地址
imageRepository: registry.aliyuncs.com/google_containers
# 配置安装的 kubernetes 版本
kubernetesVersion: 1.24.9
# 网络相关配置
networking:
dnsDomain: skynemo.cn
podSubnet: 10.100.0.0/16
serviceSubnet: 10.200.0.0/16
controlPlaneEndpoint: "192.168.111.181:6443"
---
# 配置 kube-proxy 网络模式
apiVersion: kubeproxy.config.k8s.io/v1alpha1
......
mode: "ipvs"
---
# 配置 kubelet 连接的 dns 地址
apiVersion: kubelet.config.k8s.io/v1beta1
......
clusterDNS:
- 10.200.0.10
clusterDomain: skynemo.cn
初始化
# 使用配置文件初始化
$ kubeadm init --config kubeadm-init.yaml --upload-certs
初始化后的检查
初始化时,可能会有一些警告信息
# 防火墙放行警告
[WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly
# tc 若未安装,会提示警告
[WARNING FileExisting-tc]: tc not found in system path
# kubelet 没有配置开机启动,会提示警告
[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
初始化成功,会输出一些配置指导信息
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.111.181:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:c8033d7a55e783a424117b32da6f9337993b420b054a80bf651e0869a6e0c66d \
--control-plane --certificate-key 11d8f63b51a64384ce34b443678e7c498480cd62f03fc8d2a35e9ae905b1b4d9
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.111.181:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:c8033d7a55e783a424117b32da6f9337993b420b054a80bf651e0869a6e0c66d
验证 kube-proxy 使用的网络模式
# 使用 ipvsadm 查看规则,会有一些与 kubernetes 相关的规则
$ ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.200.0.1:443 rr
-> 192.168.111.181:6443 Masq 1 0 0
TCP 10.200.0.10:53 rr
TCP 10.200.0.10:9153 rr
UDP 10.200.0.10:53 rr
# 或者使用以下命令查看日志(需要先配置使用 kubectl)
$ kubectl get pods -A | grep kube-proxy
kube-system kube-proxy-4ztbg 1/1 Running 0 13m
$ kubectl logs kube-proxy-4ztbg -n kube-system
# 出现如下日志
I1213 11:40:27.006847 1 server_others.go:269] "Using ipvs Proxier"
I1213 11:40:27.006888 1 server_others.go:271] "Creating dualStackProxier for ipvs"
配置使用 kubectl
若要使非 root 用户可以运行 kubectl,请运行以下命令, 它们是 kubeadm init 输出的一部分配置,包含了请求的证书、密钥等信息
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
如果你是 root 用户,则可以配置环境变量 KUBECONFIG=/etc/kubernetes/admin.conf
# 配置永久环境变量
$ cat > /etc/profile.d/kubeconfig.sh << EOF
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
# 加载环境变量
$ source /etc/profile
允许在控制平面节点上调度 Pod
默认情况下,出于安全原因,集群不会在控制平面节点上调度 Pod。 如果希望能够在控制平面节点上调度 Pod, 例如用于开发的单机 Kubernetes 集群,请运行
$ kubectl taint nodes --all node-role.kubernetes.io/control-plane- node-role.kubernetes.io/master-
# 检查污点移除情况
$ kubectl describe node kube-cp.skynemo.cn
这将从任何拥有 node-role.kubernetes.io/control-plane:NoSchedule 标记(污点)的节点中移除该标记, 包括控制平面节点,这意味着调度程序将能够在任何地方调度 Pods
部署网络插件
支持的网络插件列表:集群网络系统 | Kubernetes
在安装网络之前,集群 DNS (CoreDNS) 不会启动
# 查看当前的 pod 状态,会发现 coredns 没有启动
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-74586cf9b6-mznvs 0/1 Pending 0 14m
kube-system coredns-74586cf9b6-r5w94 0/1 Pending 0 14m
kube-system etcd-kube-cp.skynemo.cn 1/1 Running 0 14m
kube-system kube-apiserver-kube-cp.skynemo.cn 1/1 Running 0 14m
kube-system kube-controller-manager-kube-cp.skynemo.cn 1/1 Running 0 14m
kube-system kube-proxy-4ztbg 1/1 Running 0 14m
kube-system kube-scheduler-kube-cp.skynemo.cn 1/1 Running 0 14m
部署网络插件
注:每个集群只能使用 Pod 网络插件,kubernetes 支持的网络插件参考:安装扩展(Addons) | Kubernetes
本文安装网络插件以 Calico 为例
Calico 安装参考:Quickstart for Calico on Kubernetes (tigera.io)
Calico 官方 github 地址:projectcalico/calico: Cloud native networking and network security (github.com)
可以在 Calico 官方 github 项目的 manifests/calico.yaml 找到完整的 yaml 文件
# 下载 yaml 文件
$ curl -o calico-v3.24.5.yaml https://raw.githubusercontent.com/projectcalico/calico/v3.24.5/manifests/calico.yaml
# 直接使用 kubectl 应用部署
$ kubectl apply -f calico-v3.24.5.yaml
检验集群 DNS (CoreDNS) 是否启动
等待几分钟后,验证 pod 状态
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-84c476996d-r6dgp 1/1 Running 0 4m35s
kube-system calico-node-vv6s9 1/1 Running 0 4m35s
kube-system coredns-74586cf9b6-mznvs 1/1 Running 0 21m
kube-system coredns-74586cf9b6-r5w94 1/1 Running 0 21m
kube-system etcd-kube-cp.skynemo.cn 1/1 Running 0 21m
kube-system kube-apiserver-kube-cp.skynemo.cn 1/1 Running 0 21m
kube-system kube-controller-manager-kube-cp.skynemo.cn 1/1 Running 0 21m
kube-system kube-proxy-4ztbg 1/1 Running 0 21m
kube-system kube-scheduler-kube-cp.skynemo.cn 1/1 Running 0 21m
测试 Pod 的使用
查看节点状态
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
kube-cp.skynemo.cn Ready control-plane 21m v1.24.9 192.168.111.181 <none> Rocky Linux 8.7 (Green Obsidian) 4.18.0-425.3.1.el8.x86_64 containerd://1.4.12
测试创建 pod
创建 Pod 并暴露端口
$ kubectl create deployment nginx --image=nginx:1.22
deployment.apps/nginx created
$ kubectl expose deployment nginx --port=80 --type=NodePort
service/nginx exposed
查看 Pod 和 service 状态
$ kubectl get pod,svc
NAME READY STATUS RESTARTS AGE
pod/nginx-c4bf8d669-2j8vl 1/1 Running 0 3m35s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.200.0.1 <none> 443/TCP 150m
service/nginx NodePort 10.200.111.5 <none> 80:30434/TCP 123m
测试访问 nginx
$ curl 192.168.111.181:30434 -I
HTTP/1.1 200 OK
Server: nginx/1.22.1
Date: Wed, 14 Dec 2022 13:59:04 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Wed, 19 Oct 2022 08:02:20 GMT
Connection: keep-alive
ETag: "634faf0c-267"
Accept-Ranges: bytes
测试域名解析
$ kubectl run busybox --rm -it --image=busybox:1.28.4 sh
If you don't see a command prompt, try pressing enter.
/ # nslookup nginx.default.svc.skynemo.cn
Server: 10.200.0.10
Address 1: 10.200.0.10 kube-dns.kube-system.svc.skynemo.cn
Name: nginx.default.svc.skynemo.cn
Address 1: 10.200.111.5 nginx.default.svc.skynemo.cn
/ # nslookup kubernetes
Server: 10.200.0.10
Address 1: 10.200.0.10 kube-dns.kube-system.svc.skynemo.cn
Name: kubernetes
Address 1: 10.200.0.1 kubernetes.default.svc.skynemo.cn
高可用集群拓扑
参考文档:高可用拓扑选项 | Kubernetes
高可用(HA) Kubernetes 集群拓扑通常可以分成两个选项
- 使用堆叠(stacked)控制平面节点,其中 etcd 节点与控制平面节点共存
- 使用外部 etcd 节点,其中 etcd 在与控制平面不同的节点上运行
堆叠(Stacked) etcd 拓扑
拓扑图
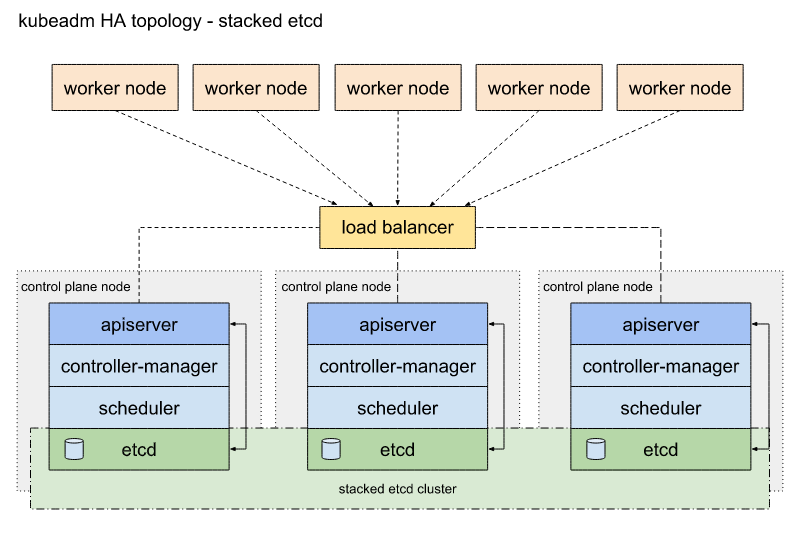
堆叠(Stacked) HA 集群最主要的特点:etcd 分布式数据存储集群堆叠在 kubeadm 管理的控制平面节点上,作为控制平面的一个组件运行
每个控制平面节点运行 kube-apiserver,kube-scheduler 和 kube-controller-manager 实例。其中,kube-apiserver 使用负载均衡器暴露给工作节点
此外,每个控制平面节点会创建一个本地 etcd 成员(member),这个 etcd 成员只与该节点的 kube-apiserver 通信。这同样适用于本地 kube-controller-manager 和 kube-scheduler 实例
这是 kubeadm 中的默认拓扑。当使用 kubeadm init 和 kubeadm join --control-plane 时,在控制平面节点上会自动创建本地 etcd 成员
优缺点
-
优点:这种拓扑将控制平面和 etcd 成员耦合在同一节点上。相对使用外部 etcd 集群,设置起来更简单,而且更易于副本管理。
-
缺点:堆叠集群存在耦合失败的风险。如果一个节点发生故障,则 etcd 成员和控制平面实例都将丢失,并且冗余会受到影响。您可以通过添加更多控制平面节点来降低此风险
因此,如果使用堆叠(Stacked) etcd 拓扑,则至少应该为 HA 集群运行三个堆叠的控制平面节点
外部 etcd 拓扑
拓扑图
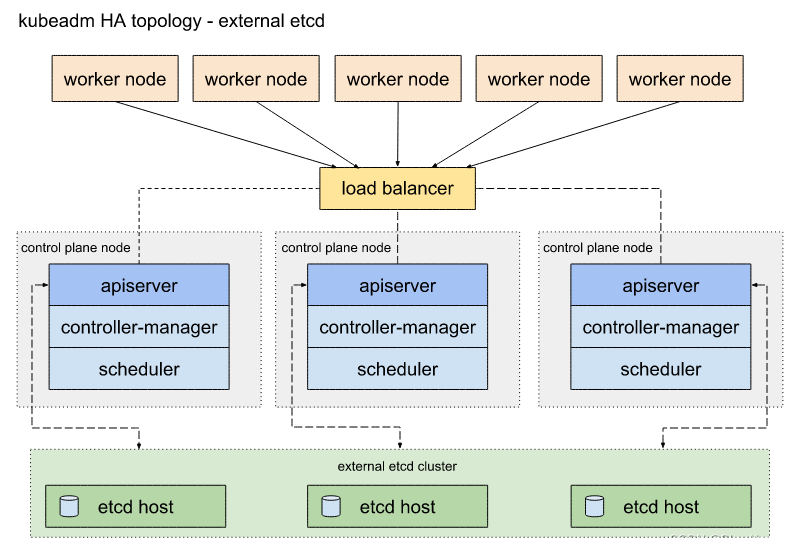
外部 etcd 的 HA 集群最主要的特点: etcd 分布式数据存储集群在独立于控制平面节点的其他节点上运行
每个控制平面节点都运行 kube-apiserver,kube-scheduler 和 kube-controller-manager 实例。同样, kube-apiserver 使用负载均衡器暴露给工作节点。
与堆叠(Stacked) etcd 拓扑不同的是,在外部 etcd 拓扑中,etcd 成员在非控制平面节点主机上运行,每个 etcd 主机与每个控制平面节点的 kube-apiserver 通信
优缺点
- 优点:这种拓扑结构解耦了控制平面和 etcd 成员。在失去控制平面实例或者 etcd 成员时,产生影响较小,并且不会像堆叠的 HA 拓扑那样影响整个集群冗余
- 缺点:此拓扑需要两倍于堆叠 HA 拓扑的主机数量
因此,如果使用外部 etcd 拓扑,则 HA 集群至少需要三个用于控制平面节点的主机和三个用于 etcd 节点的主机
创建高可用集群
堆叠(Stacked) etcd 拓扑的高可用集群构建可以参考:利用 kubeadm 创建高可用集群 | Kubernetes
外部 etcd 拓扑的高可用集群构建可以参考:利用 kubeadm 创建高可用集群 | Kubernetes
本文选用堆叠(Stacked) etcd 拓扑的高可用集群
准备
使用 7 台主机,其中 2 台作为负载均衡使用;k8s 集群共 5 台, 3 台作为控制面节点,2 台作为工作节点
拓扑结构
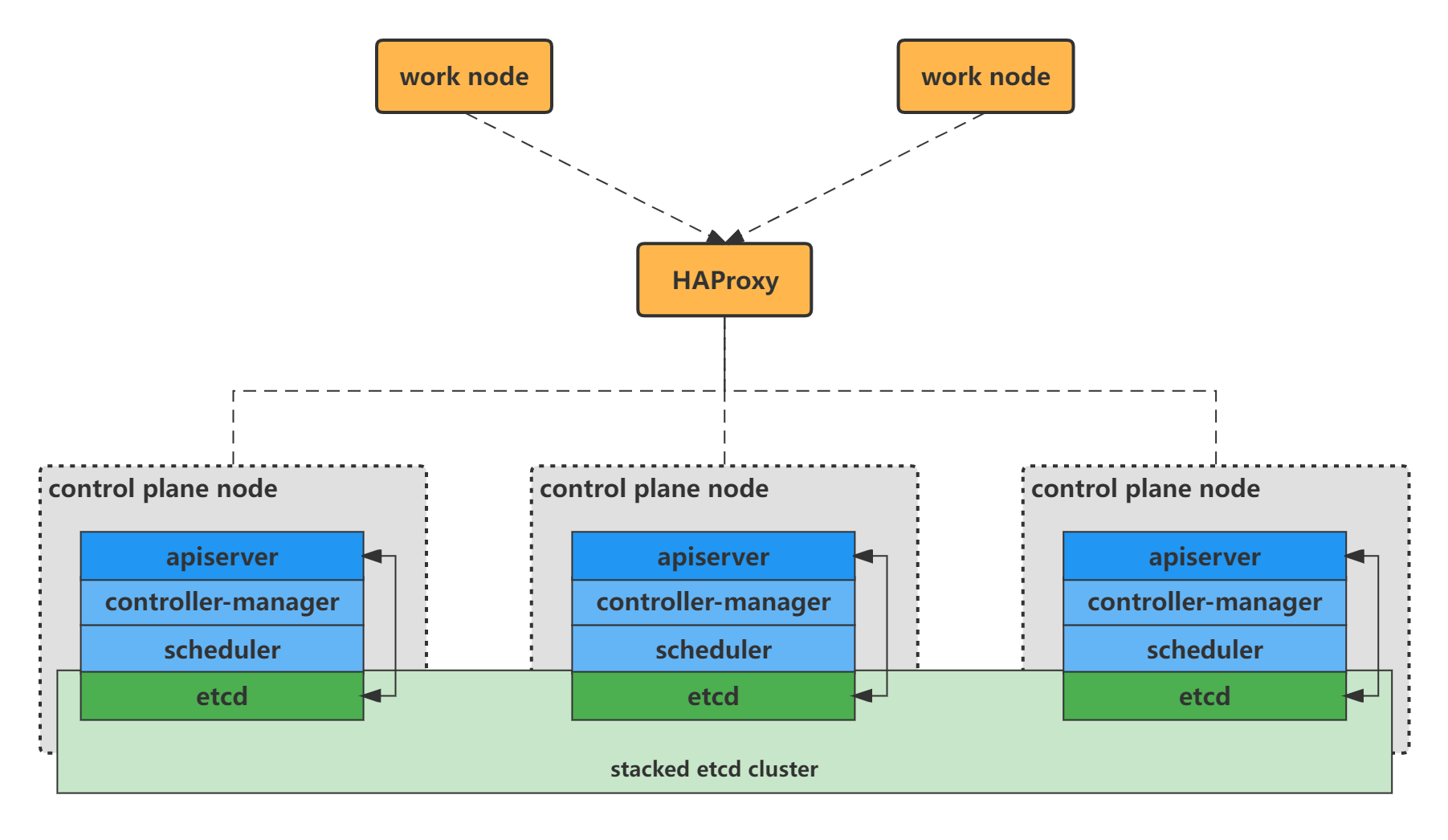
主机列表
| 主机 | IP | 角色 | 安装服务 |
|---|---|---|---|
| kube-cp-1.skynemo.cn | 192.168.111.181 | 控制面节点-1 | containerd 1.4.12 kubeadm : 1.24.9 kubelet : 1.24.9 kubectl : 1.24.9 |
| kube-cp-2.skynemo.cn | 192.168.111.182 | 控制面节点-2 | containerd 1.4.12 kubeadm : 1.24.9 kubelet : 1.24.9 kubectl : 1.24.9 |
| kube-cp-3.skynemo.cn | 192.168.111.183 | 控制面节点-3 | containerd 1.4.12 kubeadm : 1.24.9 kubelet : 1.24.9 kubectl : 1.24.9 |
| kube-node-1.skynemo.cn | 192.168.111.184 | 工作节点-1 | containerd 1.4.12 kubeadm : 1.24.9 kubelet : 1.24.9 |
| kube-node-2.skynemo.cn | 192.168.111.185 | 工作节点-2 | containerd 1.4.12 kubeadm : 1.24.9 kubelet : 1.24.9 |
| haproxy-1.skynemo.cn | 192.168.111.186 VIP:192.168.111.253 | 负载均衡 | HAProxy 2.6 Keepalived 2.2.7 |
| haproxy-2.skynemo.cn | 192.168.111.187 VIP:192.168.111.253 | 负载均衡 | HAProxy 2.6 Keepalived 2.2.7 |
注:所有节点配置了时间同步
Kubeadm 相关安装过程省略,详见:安装 Kubeadm
HAProxy 及 Keepalived 安装过程省略
配置相互域名解析
所有主机(包括 HAProxy)配置相互的域名解析
$ cat >> /etc/hosts << EOF
192.168.111.181 kube-cp-1.skynemo.cn
192.168.111.182 kube-cp-2.skynemo.cn
192.168.111.183 kube-cp-3.skynemo.cn
192.168.111.184 kube-node-1.skynemo.cn
192.168.111.185 kube-node-2.skynemo.cn
192.168.111.186 haproxy-1.skynemo.cn
192.168.111.187 haproxy-2.skynemo.cn
EOF
下载镜像
默认镜像仓库由 google 提供(地址为:
k8s.gcr.io),国内无法访问,推荐使用阿里云提供的镜像仓库(registry.aliyuncs.com/google_containers)
提前下载好所需的镜像,防止在构建过程中因镜像下载异常而导致部署失败
控制面节点下载镜像
所有控制面节点下载如下镜像
# 指定 kubernetes 版本、指定仓库进行镜像下载
$ kubeadm config images pull --kubernetes-version=v1.24.9 --image-repository registry.aliyuncs.com/google_containers
# 查看下载的镜像
$ crictl images
IMAGE TAG IMAGE ID SIZE
registry.aliyuncs.com/google_containers/coredns v1.8.6 a4ca41631cc7a 13.6MB
registry.aliyuncs.com/google_containers/etcd 3.5.6-0 fce326961ae2d 103MB
registry.aliyuncs.com/google_containers/kube-apiserver v1.24.9 ae6cdd144f9d7 33.8MB
registry.aliyuncs.com/google_containers/kube-controller-manager v1.24.9 16e04a3cf5de3 31.1MB
registry.aliyuncs.com/google_containers/kube-proxy v1.24.9 ca65e238774be 39.5MB
registry.aliyuncs.com/google_containers/kube-scheduler v1.24.9 affce73c10985 15.5MB
registry.aliyuncs.com/google_containers/pause 3.7 221177c6082a8 311kB
工作节点下载镜像
工作节点只需要下载 kube-proxy 镜像
# 下载 kube-proxy 镜像
$ crictl pull registry.aliyuncs.com/google_containers/kube-proxy:v1.24.9
# 查看下载的镜像
$ crictl images
IMAGE TAG IMAGE ID SIZE
registry.aliyuncs.com/google_containers/kube-proxy v1.24.9 ca65e238774be 39.5MB
HAProxy 与 Keepalived 配置
HAProxy 配置
两台 HAProxy 配置一致
$ vim /etc/haproxy/haproxy.cfg
global
maxconn 100000
chroot /apps/haproxy/empty
stats socket /var/lib/haproxy/haproxy.sock mode 600 level admin
user haproxy
group haproxy
daemon
pidfile /var/lib/haproxy/haproxy.pid
log 127.0.0.1 local2 info
defaults
option http-keep-alive
option forwardfor
maxconn 100000
mode http
timeout connect 300000ms
timeout client 300000ms
timeout server 300000ms
# errorfile 404 /etc/haproxy/errors/404.http
# 配置状态页面,方便查看代理情况
listen stats
mode http
bind 192.168.111.253:9999
log global
stats enable
stats hide-version
stats uri /haproxy-status # haproxy 状态页 URL
stats realm HAProxy\ Statistics
stats auth haadmin:520123 # Haproxy 状态页用户名/密码
stats refresh 30s
# 配置控制面节点的代理
listen kube-apiserver
bind 192.168.111.253:6443
mode tcp
log global
balance source
server kube-cp-1 192.168.111.181:6443 check inter 3000 fall 2 rise 5
server kube-cp-2 192.168.111.182:6443 check inter 3000 fall 2 rise 5
server kube-cp-3 192.168.111.183:6443 check inter 3000 fall 2 rise 5
重启 haproxy 使配置生效
$ systemctl restart haproxy
注意:haproxy 所在的节点需要防火墙放开监听的端口(此处为 6443)
# 添加所有相关服务到 public zone
firewall-cmd --zone=public --add-service=kube-apiserver
# 运行时配置写入永久配置
firewall-cmd --runtime-to-permanent
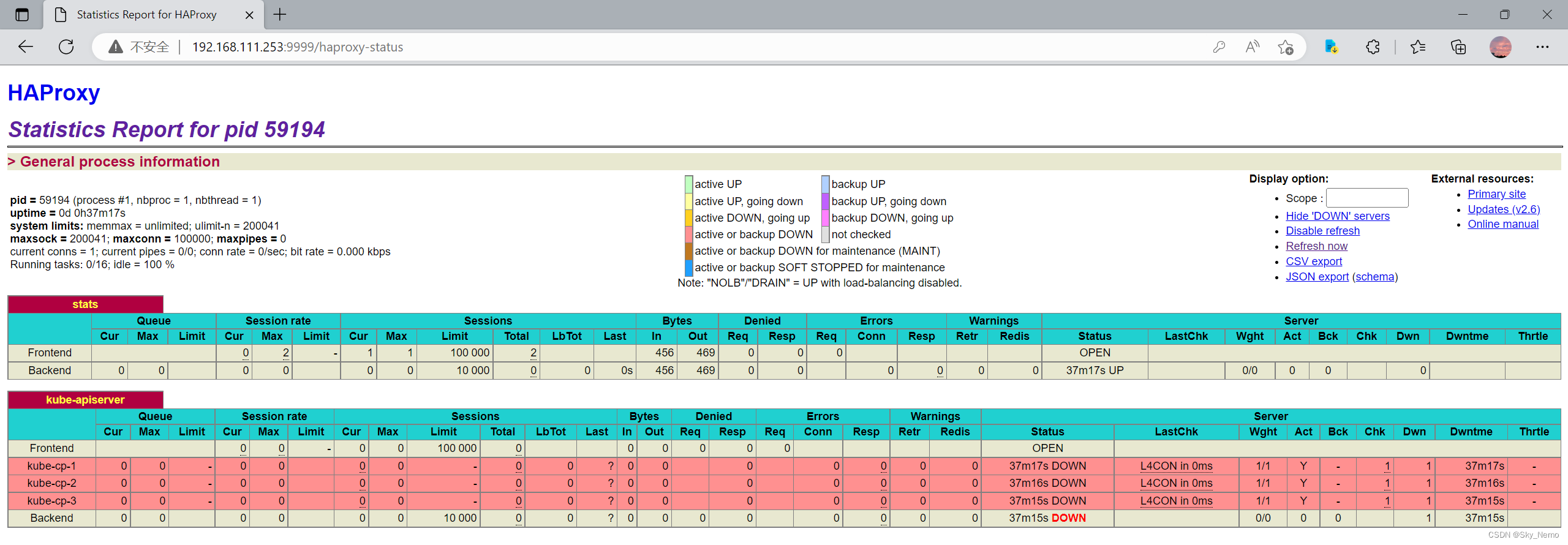
查看 HAProxy 状态页面
在初始化或加入控制面节点后,可以检查 HAProxy 状态页面,看代理是否正常,未初始化时显示红色
Keepalived 配置
两个节点只有 不一样
节点 haproxy-1.skynemo.cn 配置
$ vim /etc/keepalived/keepalived.conf
# 全局配置
global_defs {
# 当前节点唯一标识
route_id KA-HA-VS-1
vrrp_skip_check_adv_addr
}
# 定义 vrrp_script
vrrp_script check_haproxy {
script "/etc/keepalived/check_script/check_haproxy.sh"
interval 2
weight 10
rise 3
fall 2
# 执行脚本或命令的用户和用户组
user haproxy haproxy
}
# 定义 vrrp_instance
vrrp_instance VI_HAPROXY {
state BACKUP
# 心跳网口
interface ens160
# 虚拟路由器 ID
virtual_router_id 253
# 初始优先级
priority 50
# vrrp 通告时间间隔(心跳检测间隔时间)
advert_int 1
# vrrp 通告认证
authentication {
auth_type PASS
auth_pass 1234
}
# 虚拟 IP 配置,可配置多个
virtual_ipaddress {
192.168.111.253/24 dev ens160 label ens160:0
}
# 调用 vrrp_script
track_script {
check_haproxy
}
}
节点 haproxy-2.skynemo.cn 配置
$ vim /etc/keepalived/keepalived.conf
# 全局配置
global_defs {
# 当前节点唯一标识
route_id KA-HA-VS-2
vrrp_skip_check_adv_addr
}
# 定义 vrrp_script
vrrp_script check_haproxy {
script "/etc/keepalived/check_script/check_haproxy.sh"
interval 2
weight 10
rise 3
fall 2
# 执行脚本或命令的用户和用户组
user haproxy haproxy
}
# 定义 vrrp_instance
vrrp_instance VI_HAPROXY {
state BACKUP
# 心跳网口
interface ens160
# 虚拟路由器 ID
virtual_router_id 253
# 初始优先级
priority 50
# vrrp 通告时间间隔(心跳检测间隔时间)
advert_int 1
# vrrp 通告认证
authentication {
auth_type PASS
auth_pass 1234
}
# 虚拟 IP 配置,可配置多个
virtual_ipaddress {
192.168.111.253/24 dev ens160 label ens160:0
}
# 调用 vrrp_script
track_script {
check_haproxy
}
}
检查脚本配置
$ vim /etc/keepalived/check_script/check_haproxy.sh
#!/bin/bash
# 此处仅用进程判断,生产环境请根据需要编写脚本
# 过滤 haproxy 的进程
/usr/bin/pgrep -f haproxy -l | /usr/bin/grep -v 'check' &> /dev/null
if [ $? -eq 0 ];then
HAPROXY_STATUS=0
else
HAPROXY_STATUS=1
fi
初始化第一个控制面节点
方式一:基于命令初始化
需要注意以下参数的设置:
apiserver-advertise-address:设置为当前节点的 IPapiserver-bind-port:设置为当前节点 apiserver 绑定的端口control-plane-endpoint:设置 api-server 负载均衡器的 VIP--upload-certs:将在所有控制平面实例之间的共享证书上传到集群
$ kubeadm init \
--apiserver-advertise-address=192.168.111.181 \
--apiserver-bind-port=6443 \
--control-plane-endpoint=192.168.111.253 \
--kubernetes-version=v1.24.6 \
--pod-network-cidr=10.100.0.0/16 \
--service-cidr=10.200.0.0/16 \
--service-dns-domain=skynemo.cn \
--image-repository=registry.aliyuncs.com/google_containers \
--upload-certs
方式二:基于配置文件初始化(推荐)
基于配置文件初始化适合于复杂的配置(命令行不具备的配置),例如配置 kube-proxy 的网络模式
生成配置文件
# 生成配置文件,并生成 kube-proxy 和 kubelet 的配置
$ kubeadm config print init-defaults --component-configs KubeProxyConfiguration,KubeletConfiguration --kubeconfig '/etc/kubernetes/admin.conf' > kubeadm-init.yaml
修改配置
# 此处只列出主要的配置
$ vim kubeadm-init.yaml
---
apiVersion: kubeadm.k8s.io/v1beta3
......
# 配置本地 api server 地址和端口
localAPIEndpoint:
advertiseAddress: 192.168.111.181
bindPort: 6443
# 配置 kubernetes 节点名称,建议使用主机名
nodeRegistration:
name: kube-cp-1.skynemo.cn
---
apiServer:
......
# 集群名称
clusterName: kubernetes.skynemo.cn
# 配置镜像下载地址
imageRepository: registry.aliyuncs.com/google_containers
# 配置安装的 kubernetes 版本
kubernetesVersion: 1.24.9
# 网络相关配置,controlPlaneEndpoint 需要与 haproxy 的 VIP 配置一致
networking:
dnsDomain: skynemo.cn
podSubnet: 10.100.0.0/16
serviceSubnet: 10.200.0.0/16
controlPlaneEndpoint: "192.168.111.253:6443"
---
# 配置 kube-proxy 网络模式
apiVersion: kubeproxy.config.k8s.io/v1alpha1
......
mode: "ipvs"
---
# 配置 kubelet 连接的 dns 地址
apiVersion: kubelet.config.k8s.io/v1beta1
......
clusterDNS:
- 10.200.0.10
clusterDomain: skynemo.cn
初始化
$ kubeadm init --config kubeadm-init.yaml --upload-certs
初始化信息
需要记录初始化时的输出信息,这些信息可以用来将控制平面节点和工作节点加入集群
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.111.253:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:34f396f32030dd01753b53e20c487bb5c051ff19ab65c52bee44faf3507e4816 \
--control-plane --certificate-key 5a0ca6ae7adeabf5f7fa54e1a4426322fb3217f6c33b8c1fc03cdd0c693cdb1f
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.111.253:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:34f396f32030dd01753b53e20c487bb5c051ff19ab65c52bee44faf3507e4816
证书操作
查看证书有效期
$ kubeadm certs check-expiration
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Dec 16, 2023 21:21 UTC 364d ca no
apiserver Dec 16, 2023 21:21 UTC 364d ca no
apiserver-etcd-client Dec 16, 2023 21:21 UTC 364d etcd-ca no
apiserver-kubelet-client Dec 16, 2023 21:21 UTC 364d ca no
controller-manager.conf Dec 16, 2023 21:21 UTC 364d ca no
etcd-healthcheck-client Dec 16, 2023 21:21 UTC 364d etcd-ca no
etcd-peer Dec 16, 2023 21:21 UTC 364d etcd-ca no
etcd-server Dec 16, 2023 21:21 UTC 364d etcd-ca no
front-proxy-client Dec 16, 2023 21:21 UTC 364d front-proxy-ca no
scheduler.conf Dec 16, 2023 21:21 UTC 364d ca no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Dec 13, 2032 21:21 UTC 9y no
etcd-ca Dec 13, 2032 21:21 UTC 9y no
front-proxy-ca Dec 13, 2032 21:21 UTC 9y no
更新证书有效期
需要重启 kube-apiserver、 kube-controller-manager、 kube-scheduler 、etcd 后才会生效,kubeadm 管理的集群可以选择 重启 kubelet
在所有控制面节点依次执行以下命令
# 更新证书
$ kubeadm certs renew all
# 重启使证书生效
$ systemctl restart kubelet
Token 操作
当使用 --upload-certs 调用 kubeadm init 时,主控制平面的证书被加密并上传到 kubeadm-certs Secret 中,生成 Token。其他节点加入集群时,需要提供 Token 和密钥(由 --certificate-key 选项指定)
查看 Token有效期
$ kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
abcdef.0123456789abcdef 23h 2022-12-17T21:22:09Z authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
gtww2a.w64atfieeb822v2q 1h 2022-12-16T23:22:08Z <none> Proxy for managing TTL for the kubeadm-certs secret <none>
可以看到有两个 token
- 第一个 Token 用于其他节点加入集群,默认有效期为 24 小时
- 第二个 Token 用来管理
kubeadm-certsSecret 中的证书有效时间,默认有效期为 1 小时(初始化时--upload-certs参数控制上传的 Token)
重新上传证书
如果 kubeadm-certs Secret 中的证书已过期,可以重新上传证书并生成新的解密密钥,需要在已加入集群的控制平面节点上运行命令
$ kubeadm init phase upload-certs --upload-certs
# 输出信息包含 certificate key
重新生成 Token
默认 Token 有效期为24小时,当过期之后,该 Token 就不可用了。这时就需要重新创建 Token
方式一
# 生成 token
$ kubeadm token create
p28vsh.p9jsja0q4pncwbtn
# 获取CA 证书的 hash 值
$ openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt \
| openssl rsa -pubin -outform der 2>/dev/null \
| openssl dgst -sha256 -hex | sed 's/^.* //'
e61f9d225786478692201f31dc96620303e1d246d2b9bd9c934ced8c3c5e0a7c
# 工作节点加入集群
kubeadm join 192.168.111.253:6443 --token p28vsh.p9jsja0q4pncwbtn \
--discovery-token-ca-cert-hash sha256:e61f9d225786478692201f31dc96620303e1d246d2b9bd9c934ced8c3c5e0a7c
方式二
# 直接生成工作节点加入集群的命令(包含 token 和 hash 值)
$ kubeadm token create --print-join-command
kubeadm join 192.168.111.253:6443 --token 3uemx2.g4x8m8cbe2gjrxkg \
--discovery-token-ca-cert-hash sha256:e61f9d225786478692201f31dc96620303e1d246d2b9bd9c934ced8c3c5e0a7c
配置使用 kubectl
若要使非 root 用户可以运行 kubectl,请运行以下命令, 它们是 kubeadm init 输出的一部分配置,包含了请求的证书、密钥等信息
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
如果你是 root 用户,则可以配置环境变量 KUBECONFIG=/etc/kubernetes/admin.conf
# 配置永久环境变量
$ cat > /etc/profile.d/kubeconfig.sh << EOF
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
# 加载环境变量
$ source /etc/profile
部署网络插件
支持的网络插件列表:集群网络系统 | Kubernetes
在安装网络之前,集群 DNS (CoreDNS) 不会启动
# 查看当前的 pod 状态,会发现 coredns 没有启动
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-74586cf9b6-g4bsn 0/1 Pending 0 4m20s
kube-system coredns-74586cf9b6-qgczn 0/1 Pending 0 4m20s
kube-system etcd-kube-cp-1.skynemo.cn 1/1 Running 1 4m22s
kube-system kube-apiserver-kube-cp-1.skynemo.cn 1/1 Running 1 4m21s
kube-system kube-controller-manager-kube-cp-1.skynemo.cn 1/1 Running 1 4m21s
kube-system kube-proxy-jrr4g 1/1 Running 0 4m20s
kube-system kube-scheduler-kube-cp-1.skynemo.cn 1/1 Running 1 4m22s
部署网络插件
注:每个集群只能使用 Pod 网络插件,kubernetes 支持的网络插件参考:安装扩展(Addons) | Kubernetes
本文安装网络插件以 Calico 为例
Calico 安装参考:Quickstart for Calico on Kubernetes (tigera.io)
Calico 官方 github 地址:projectcalico/calico: Cloud native networking and network security (github.com)
可以在 Calico 官方 github 项目的 manifests/calico.yaml 找到完整的 yaml 文件
# 下载 yaml 文件
$ curl -o calico-v3.24.5.yaml https://raw.githubusercontent.com/projectcalico/calico/v3.24.5/manifests/calico.yaml
# 直接使用 kubectl 应用部署
$ kubectl apply -f calico-v3.24.5.yaml
检验集群 DNS (CoreDNS) 是否启动
等待 4~5 分钟后,验证 pod 状态
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-84c476996d-n4v6v 1/1 Running 0 5m58s
kube-system calico-node-s7fqd 1/1 Running 0 5m58s
kube-system coredns-74586cf9b6-g4bsn 1/1 Running 0 11m
kube-system coredns-74586cf9b6-qgczn 1/1 Running 0 11m
kube-system etcd-kube-cp-1.skynemo.cn 1/1 Running 1 11m
kube-system kube-apiserver-kube-cp-1.skynemo.cn 1/1 Running 1 11m
kube-system kube-controller-manager-kube-cp-1.skynemo.cn 1/1 Running 1 11m
kube-system kube-proxy-jrr4g 1/1 Running 0 11m
kube-system kube-scheduler-kube-cp-1.skynemo.cn 1/1 Running 1 11m
加入其他控制面节点
其余两个控制面节点均操作
从 kubeadm 1.15 版本开始,你可以并行加入多个控制平面节点。 在此版本之前,你必须在第一个节点初始化后才能依序的增加新的控制平面节点
执行先前由第一个节点上的 kubeadm init 命令初始化时输出信息的 join 命令
# 如果重新加载过证书,则使用新的 token 和 certificate-key
$ kubeadm join 192.168.111.253:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:34f396f32030dd01753b53e20c487bb5c051ff19ab65c52bee44faf3507e4816 \
--control-plane --certificate-key 5a0ca6ae7adeabf5f7fa54e1a4426322fb3217f6c33b8c1fc03cdd0c693cdb1f
# 加入成功提示信息
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.
--control-plane标志通知kubeadm join创建一个新的控制平面。--certificate-key ...将从集群中的kubeadm-certsSecret 下载控制平面证书并使用给定的密钥进行解密
注:如果需要在其他控制面节点使用 kubectl 命令,则需要在其他控制面节点配置使用
kubectl
加入工作节点
在工作节点上操作
使用之前保存的 kubeadm init 命令初始化时输出信息的 join 命令,将工作节点加入集群中:
# 加入集群
$ kubeadm join 192.168.111.253:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:34f396f32030dd01753b53e20c487bb5c051ff19ab65c52bee44faf3507e4816
# 加入成功时输出信息
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
验证
查看当前 Node 状态
$ kubectl get node
NAME STATUS ROLES AGE VERSION
kube-cp-1.skynemo.cn Ready control-plane 17m v1.24.9
kube-cp-2.skynemo.cn Ready control-plane 4m47s v1.24.9
kube-cp-3.skynemo.cn Ready control-plane 3m26s v1.24.9
kube-node-1.skynemo.cn Ready <none> 2m39s v1.24.9
kube-node-2.skynemo.cn Ready <none> 118s v1.24.9
查看当前证书状态
$ kubectl get csr
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
csr-82rn2 5m32s kubernetes.io/kube-apiserver-client-kubelet system:bootstrap:abcdef <none> Approved,Issued
csr-8wnpd 4m11s kubernetes.io/kube-apiserver-client-kubelet system:bootstrap:abcdef <none> Approved,Issued
csr-d2npx 2m43s kubernetes.io/kube-apiserver-client-kubelet system:bootstrap:abcdef <none> Approved,Issued
csr-mt6sg 3m24s kubernetes.io/kube-apiserver-client-kubelet system:bootstrap:abcdef <none> Approved,Issued
测试 Pod 的可用性
测试创建 pod
创建 Pod 并暴露端口
$ kubectl create deployment nginx --image=nginx:1.22
deployment.apps/nginx created
$ kubectl expose deployment nginx --port=80 --type=NodePort
service/nginx exposed
查看 Pod 和 service 状态
$ kubectl get pod,svc
NAME READY STATUS RESTARTS AGE
pod/nginx-c4bf8d669-j442c 1/1 Running 0 57m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.200.0.1 <none> 443/TCP 115m
service/nginx NodePort 10.200.14.96 <none> 80:32156/TCP 57m
查看 ipvs 规则
# 可以看到 ipvs 将本机的 32156 端口转发到 10.100.119.193 这个 pod 的 80 端口
$ ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.111.181:32156 rr
-> 10.100.119.193:80 Masq 1 0 0
测试访问 nginx
# IP 为任意一个节点的 IP
$ curl 192.168.111.181:32156 -I
HTTP/1.1 200 OK
Server: nginx/1.22.1
Date: Fri, 16 Dec 2022 23:42:26 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Wed, 19 Oct 2022 08:02:20 GMT
Connection: keep-alive
ETag: "634faf0c-267"
Accept-Ranges: bytes
测试域名解析
$ kubectl run busybox --rm -it --image=busybox:1.28.4 sh
If you don't see a command prompt, try pressing enter.
/ # nslookup nginx.default.svc.skynemo.cn
Server: 10.200.0.10
Address 1: 10.200.0.10 kube-dns.kube-system.svc.skynemo.cn
Name: nginx.default.svc.skynemo.cn
Address 1: 10.200.14.96 nginx.default.svc.skynemo.cn
/ # nslookup kubernetes
Server: 10.200.0.10
Address 1: 10.200.0.10 kube-dns.kube-system.svc.skynemo.cn
Name: kubernetes
Address 1: 10.200.0.1 kubernetes.default.svc.skynemo.cn
删除并清理节点
标识即将删除
使用适当的凭证与控制平面节点通信,运行以下命令
kubectl drain <node name> --delete-emptydir-data --force --ignore-daemonsets
清理节点配置
然后在要清理的节点上重置 kubeadm 安装的状态
kubeadm reset
重置过程不会重置或清除 iptables 规则或 IPVS 表。如果你希望重置 iptables,则必须手动进行
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
如果要重置 IPVS 表,则必须运行以下命令
ipvsadm -C
删除节点
kubectl delete node <node name>
附录
防火墙端口与协议
当你在一个有严格网络边界的环境里运行 Kubernetes,例如拥有物理网络防火墙或者拥有公有云中虚拟网络的自有数据中心,了解 Kubernetes 组件使用了哪些端口和协议是非常有用的
控制面
| 协议 | 方向 | 端口范围 | 目的 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 6443 | Kubernetes API server | 所有 |
| TCP | 入站 | 2379-2380 | etcd server client API | kube-apiserver, etcd |
| TCP | 入站 | 10250 | Kubelet API | 自身, 控制面 |
| TCP | 入站 | 10259 | kube-scheduler | 自身 |
| TCP | 入站 | 10257 | kube-controller-manager | 自身 |
尽管 etcd 的端口也列举在控制面的部分,但你也可以在外部自己托管 etcd 集群或者自定义端口
防火墙 firewalld 配置
设置服务及端口
# RockyLinux 8.7 默认已经存在 kube-apiserver、etcd-client、etcd-server 服务
# 只需要添加其他未添加的服务即可
firewall-cmd --permanent --new-service=kubelet
firewall-cmd --permanent --service=kubelet --add-port=10250/tcp
firewall-cmd --permanent --new-service=kube-scheduler
firewall-cmd --permanent --service=kube-scheduler --add-port=10259/tcp
firewall-cmd --permanent --new-service=kube-controller-manager
firewall-cmd --permanent --service=kube-controller-manager --add-port=10257/tcp
# 加载永久配置到运行时
firewall-cmd --reload
设置到区域
# 此处以设置到 public zone (default zone)为例,如果有其他的 active zone,添加方法相同
$ firewall-cmd --get-default-zone
public
# 添加所有相关服务到 public zone
firewall-cmd --zone=public --add-service=kube-apiserver
firewall-cmd --zone=public --add-service=etcd-client
firewall-cmd --zone=public --add-service=etcd-server
firewall-cmd --zone=public --add-service=kubelet
firewall-cmd --zone=public --add-service=kube-scheduler
firewall-cmd --zone=public --add-service=kube-controller-manager
# 运行时配置写入永久配置
firewall-cmd --runtime-to-permanent
检查
# 检查相关服务是否添加完成
$ firewall-cmd --info-zone=public
public (active)
target: default
icmp-block-inversion: no
interfaces: ens160
sources:
services: cockpit dhcpv6-client etcd-client etcd-server kube-apiserver kube-controller-manager kube-scheduler kubelet ssh
ports:
protocols:
forward: no
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
工作节点
| 协议 | 方向 | 端口范围 | 目的 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 10250 | Kubelet API | 自身, 控制面 |
| TCP | 入站 | 30000-32767(默认) | NodePort Services | 所有 |
所有默认端口都可以重新配置。当使用自定义的端口时,你需要打开这些端口来代替这里提到的默认端口
一个常见的例子是 API 服务器的端口有时会配置为 443。或者你也可以使用默认端口,把 API 服务器放到一个监听 443 端口的负载均衡器后面,并且路由所有请求到 API 服务器的默认端口
防火墙 firewalld 配置
设置服务及端口
firewall-cmd --permanent --new-service=kubelet
firewall-cmd --permanent --service=kubelet --add-port=10250/tcp
firewall-cmd --permanent --new-service=kube-nodeport
firewall-cmd --permanent --service=kube-nodeport --add-port=30000-32767/tcp
# 加载永久配置到运行时
firewall-cmd --reload
设置到区域
# 此处以设置到 public zone (default zone)为例,如果有其他的 active zone,添加方法相同
$ firewall-cmd --get-default-zone
public
# 添加所有相关服务到 public zone
firewall-cmd --zone=public --add-service=kubelet
firewall-cmd --zone=public --add-service=kube-nodeport
# 运行时配置写入永久配置
firewall-cmd --runtime-to-permanent
检查
# 检查相关服务是否添加完成
$ firewall-cmd --info-zone=public
public (active)
target: default
icmp-block-inversion: no
interfaces: ens160
sources:
services: cockpit dhcpv6-client kube-nodeport kubelet ssh
ports:
protocols:
forward: no
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
其他端口
IPVS 端口
所有 kubernetes 控制面节点均需要设置
| 协议 | 方向 | 端口范围 | 目的 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 443 | Kubelet API(经过 ipvs 规则映射) | 网络插件(calico 等) |
kube-proxy 使用 ipvs 模式时,会创建一个名为 kubernetes 的 service,并使用 ipvs,将 Kubernetes API server 的宿主机 IP 和 6443 端口,映射到其在 pod 网段 ip 端的 443 端口,如下所示
$ ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.200.0.1:443 rr
-> 192.168.111.181:6443 Masq 1 7 0
# 其中 10.200.0.1 为宿主机在 POD 网段的 IP ,192.168.111.181 为宿主机自身网段的 IP
防火墙 firewalld 配置
# 将 443 端口的 https 服务添加到 public 区域
firewall-cmd --zone=public --add-service=https
# 运行时配置写入永久配置
firewall-cmd --runtime-to-permanent
DNS 端口
所有 kubernetes 控制面节点均需要设置
| 协议 | 方向 | 端口范围 | 目的 | 使用者 |
|---|---|---|---|---|
| TCP/UDP | 入站 | 53 | CoreDNS 的 DNS 端口 | 集群内需要域名解析的服务 |
| TCP | 入站 | 9153 | CoreDNS 的 Metric 收集 | 监控服务(例如:prometheus) |
如下所示
$ ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.200.0.1:443 rr
-> 192.168.111.181:6443 Masq 1 0 0
TCP 10.200.0.10:53 rr
TCP 10.200.0.10:9153 rr
UDP 10.200.0.10:53 rr
防火墙 firewalld 配置
设置服务及端口
# RockyLinux 8.7 默认已经存在 dns 服务
# 只需要添加 CoreDNS 的 Metric 收集端口服务即可
firewall-cmd --permanent --new-service=coredns-metric
firewall-cmd --permanent --service=coredns-metric --add-port=9153/tcp
# 加载永久配置到运行时
firewall-cmd --reload
设置到区域
# 服务添加到 public 区域
firewall-cmd --zone=public --add-service=dns
firewall-cmd --zone=public --add-service=coredns-metric
# 运行时配置写入永久配置
firewall-cmd --runtime-to-permanent
Calico 端口
所有 kubernetes 节点均需要设置,根据选择的网络策略进行设置,新手建议全部网络策略端口均放行
| Configuration | Host(s) | Connection type | Port/protocol |
|---|---|---|---|
| Calico networking (BGP) | All | Bidirectional | TCP 179 |
| Calico networking with IP-in-IP enabled (default) | All | Bidirectional | IP-in-IP, often represented by its protocol number 4 |
| Calico networking with VXLAN enabled | All | Bidirectional | UDP 4789 |
| Calico networking with Typha enabled | Typha agent hosts | Incoming | TCP 5473 (default) |
| Calico networking with IPv4 Wireguard enabled | All | Bidirectional | UDP 51820 (default) |
| Calico networking with IPv6 Wireguard enabled | All | Bidirectional | UDP 51821 (default) |
| flannel networking (VXLAN) | All | Bidirectional | UDP 4789 |
防火墙 firewalld 配置
设置服务及端口
# RockyLinux 8.7 默认已经存在 bgp 服务
firewall-cmd --permanent --new-service=vxlan
firewall-cmd --permanent --service=vxlan --add-port=4789/udp
firewall-cmd --permanent --new-service=typha
firewall-cmd --permanent --service=typha --add-port=5473/tcp
firewall-cmd --permanent --new-service=ipv4-wireguard
firewall-cmd --permanent --service=ipv4-wireguard --add-port=51820/udp
firewall-cmd --permanent --new-service=ipv6-wireguard
firewall-cmd --permanent --service=ipv6-wireguard --add-port=51821/udp
# 加载永久配置到运行时
firewall-cmd --reload
设置到区域
# 服务添加到 public 区域
firewall-cmd --zone=public --add-service=bgp
firewall-cmd --zone=public --add-service=vxlan
firewall-cmd --zone=public --add-service=typha
firewall-cmd --zone=public --add-service=ipv4-wireguard
firewall-cmd --zone=public --add-service=ipv6-wireguard
# 运行时配置写入永久配置
firewall-cmd --runtime-to-permanent
其他防火墙放行规则
所有 kubernetes 节点均配置
配置 pod CIDR 网络和 server CIDR 网络均放行
$ firewall-cmd --zone=trusted --add-source=10.100.0.0/16
$ firewall-cmd --zone=trusted --add-source=10.200.0.0/16
$ firewall-cmd --runtime-to-permanent
参数优化
Kubernetes 与 Containerd 运行时需要各种系统底层配置支持,推荐按以下参数设置系统
PAM 模块 pam_limits 设置
$ cat > /etc/security/limits.d/kubernetes.conf << EOF
* - core 0
* - nproc unlimited
* - nofile 1048576
* - memlock unlimited
* - msgqueue unlimited
EOF
setrlimit 设置
systemd 有独立于 PAM 的资源限制(setrlimit),若服务通过 systemd 启动也需要设置
修改用户级设置
$ mkdir -p /etc/systemd/user.conf.d
$ cat > /etc/systemd/user.conf.d/kubernetes.conf << EOF
[Manager]
DefaultLimitCORE=0
DefaultLimitNPROC=infinity
DefaultLimitNOFILE=1048576
DefaultLimitMEMLOCK=infinity
DefaultLimitMSGQUEUE=infinity
EOF
修改系统级设置
# 备份原有的配置
$ cp /etc/systemd/system.conf /etc/systemd/system.conf.bak`date +"%Y%m%d"`
# 修改配置
$ grep -q '^#* *DefaultLimitCORE.*' /etc/systemd/system.conf && sed -ri 's@^#* *(DefaultLimitCORE).*@\1=0@' /etc/systemd/system.conf || echo "DefaultLimitCORE=0" >> /etc/systemd/system.conf
$ grep -q '^#* *DefaultLimitNPROC.*' /etc/systemd/system.conf && sed -ri 's@^#* *(DefaultLimitNPROC).*@\1=infinity@' /etc/systemd/system.conf || echo "DefaultLimitNPROC=infinity" >> /etc/systemd/system.conf
$ grep -q '^#* *DefaultLimitNOFILE.*' /etc/systemd/system.conf && sed -ri 's@^#* *(DefaultLimitNOFILE).*@\1=1048576@' /etc/systemd/system.conf || echo "DefaultLimitNOFILE=1048576" >> /etc/systemd/system.conf
$ grep -q '^#* *DefaultLimitMEMLOCK.*' /etc/systemd/system.conf && sed -ri 's@^#* *(DefaultLimitMEMLOCK).*@\1=infinity@' /etc/systemd/system.conf || echo "DefaultLimitMEMLOCK=infinity" >> /etc/systemd/system.conf
$ grep -q '^#* *DefaultLimitMSGQUEUE.*' /etc/systemd/system.conf && sed -ri 's@^#* *(DefaultLimitMSGQUEUE).*@\1=infinity@' /etc/systemd/system.conf || echo "DefaultLimitMSGQUEUE=infinity" >> /etc/systemd/system.conf
重启 systemd
# 重启 systemd 生效
$ systemctl daemon-reexec
系统参数 sysctl.conf
项目中请根据实际情况配置,此处仅作为示例
$ cat >> /etc/sysctl.conf <<EOF
###### TCP 连接快速释放设置 ######
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_time = 1200
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 3
###### TIME_WAIT 过多时设置 ######
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_max_tw_buckets=5000
###### 防 SYNC 攻击设置 ######
net.ipv4.tcp_syncookies=1
net.ipv4.tcp_syn_retries=3
net.ipv4.tcp_synack_retries=2
net.ipv4.tcp_max_syn_backlog=8192
####### nf_conntrack 相关设置(k8s、docker 防火墙的 nat) #######
net.netfilter.nf_conntrack_max = 262144
net.nf_conntrack_max = 262144
net.netfilter.nf_conntrack_tcp_timeout_established = 43200
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
####### socket 相关设置 ######
net.core.somaxconn = 16384
net.core.netdev_max_backlog = 16384
###### 其他设置 #######
net.ipv4.conf.default.rp_filter=0
net.ipv4.conf.default.accept_source_route=0
net.ipv4.ip_forward = 1
net.ipv4.ip_nonlocal_bind = 1
###### 内存相关设置 #######
vm.swappiness = 0
vm.max_map_count = 262144
###### 文件相关 #######
fs.file-max = 1048576
fs.nr_open = 1048576
EOF
应用参数
$ sysctl -p















 3478
3478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









