







 本文详细介绍了如何编写一个针对凯里学院官网的爬虫,包括使用第三方库处理加密、获取验证码、模拟登录过程,以实现自动抢课和数据抓取。
本文详细介绍了如何编写一个针对凯里学院官网的爬虫,包括使用第三方库处理加密、获取验证码、模拟登录过程,以实现自动抢课和数据抓取。
免责声明:本文章涉及到的应用仅供学习交流使用,不得用于任何商业用途,数据来源于互联网公开内容,没有获取任何私有和有权限的信息(个人信息等)。由此引发的任何法律纠纷与本人无关!禁止将本文技术或者本文所关联的Github项目源码用于任何目的。
1. 爬虫内容简介
全网没几个完整的正方抢课,我自己写了个供大家参考,关于正方系统的学校官网爬虫的学习,以凯里学院为例子分析网站的结构,完成抢课,提取学习成绩等操作。

2. 使用的第三方库
import execjs # 用来执行js脚本
import requests # 用来请求网页,获取网页内容
from bs4 import BeautifulSoup # 用来解析网页内容
import csv # 用来写入csv文件
import re # 用来匹配内容
import time # 用来延时
import ddddocr # 用来识别验证码
import os # 用来文件操作
3. 主页请求内容分析结果(我这个带了加密,看自己学校的带不带)
1. 随便输入几个请求看看提交数据
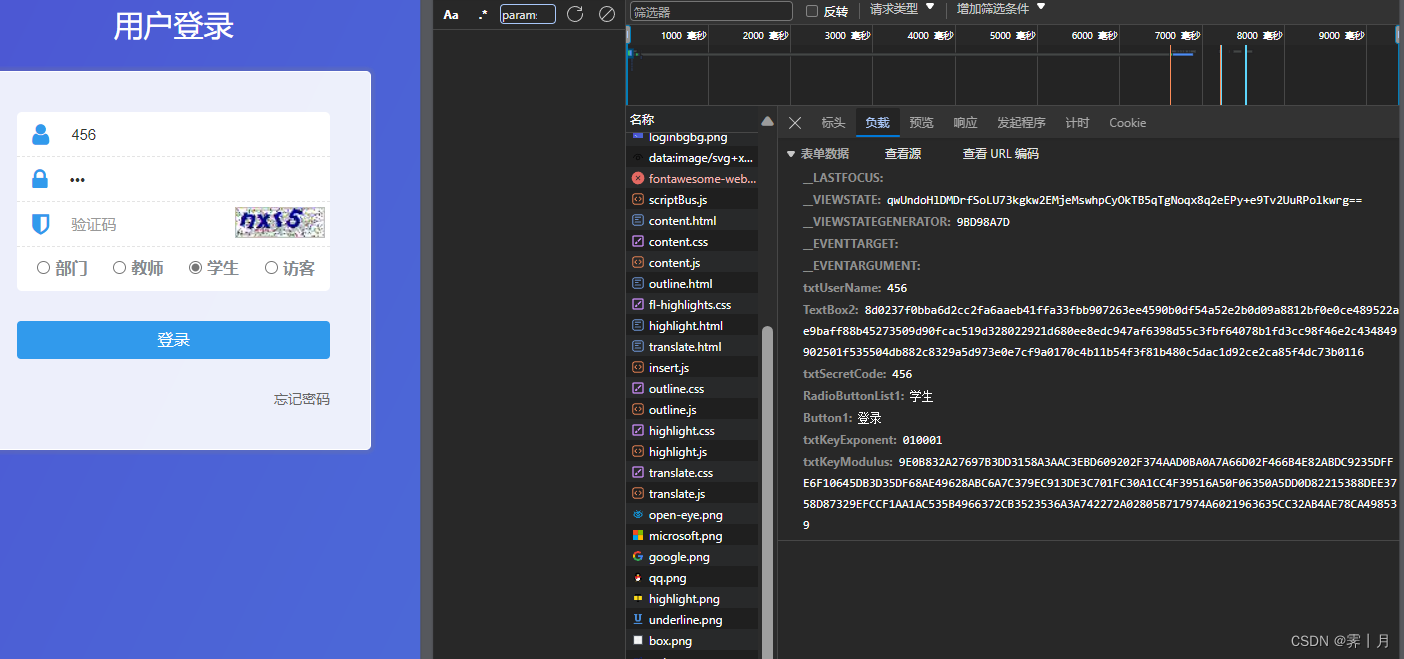
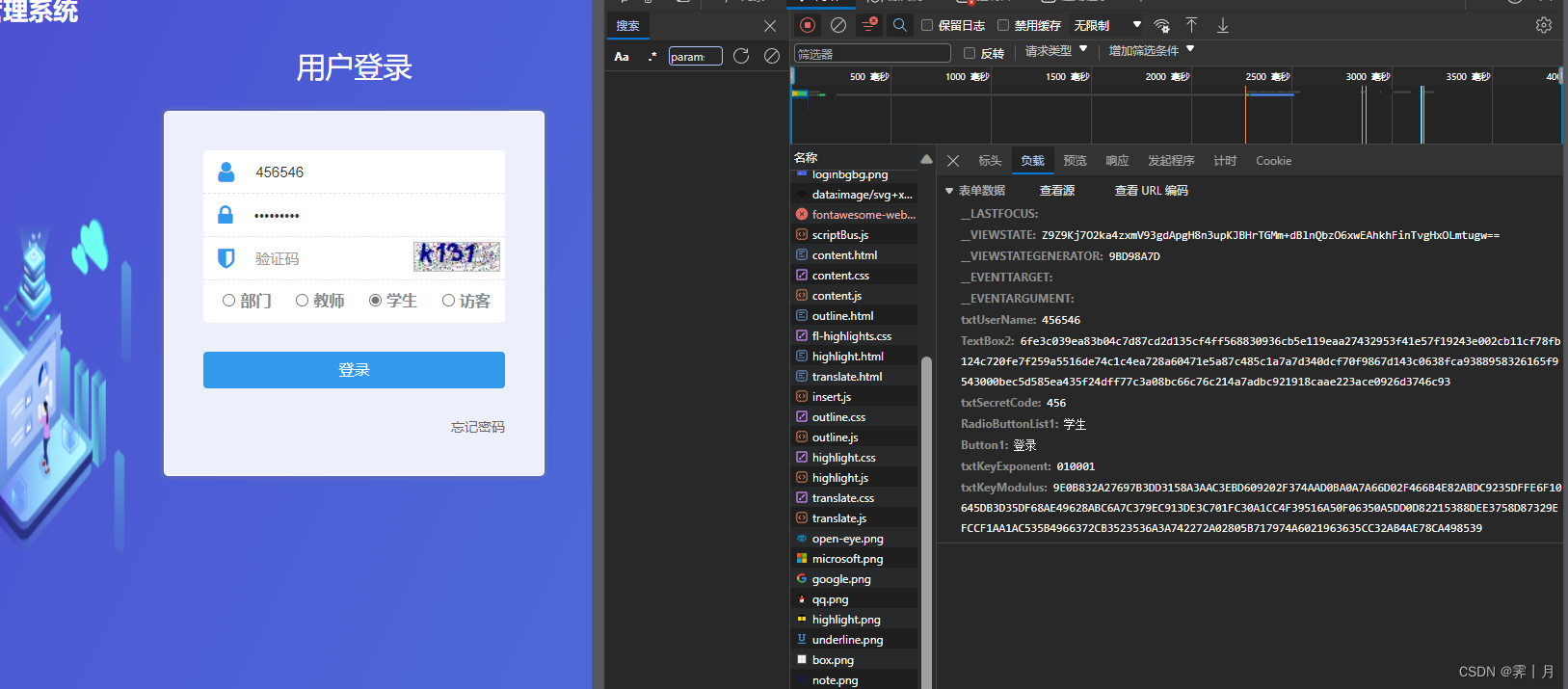
# 第一次请求
__LASTFOCUS:
__VIEWSTATE: qwUndoHlDMDrfSoLU73kgkw2EMjeMswhpCyOkTB5qTgNoqx8q2eEPy+e9Tv2UuRPolkwrg==
__VIEWSTATEGENERATOR: 9BD98A7D
__EVENTTARGET:
__EVENTARGUMENT:
txtUserName: 456
TextBox2: 8d0237f0bba6d2cc2fa6aaeb41ffa33fbb907263ee4590b0df54a52e2b0d09a8812bf0e0ce489522ae9baff88b45273509d90fcac519d328022921d680ee8edc947af6398d55c3fbf64078b1fd3cc98f46e2c434849902501f535504db882c8329a5d973e0e7cf9a0170c4b11b54f3f81b480c5dac1d92ce2ca85f4dc73b0116
txtSecretCode: 456
RadioButtonList1: 学生
Button1: 登录
txtKeyExponent: 010001
txtKeyModulus: 9E0B832A27697B3DD3158A3AAC3EBD609202F374AAD0BA0A7A66D02F466B4E82ABDC9235DFFE6F10645DB3D35DF68AE49628ABC6A7C379EC913DE3C701FC30A1CC4F39516A50F06350A5DD0D82215388DEE3758D87329EFCCF1AA1AC535B4966372CB3523536A3A742272A02805B717974A6021963635CC32AB4AE78CA498539
# 第二次请求
__LASTFOCUS:
__VIEWSTATE: Z9Z9Kj7O2ka4zxmV93gdApgH8n3upKJBHrTGMm+dBlnQbzO6xwEAhkhFinTvgHxOLmtugw==
__VIEWSTATEGENERATOR: 9BD98A7D
__EVENTTARGET:
__EVENTARGUMENT:
txtUserName: 456546
TextBox2: 6fe3c039ea83b04c7d87cd2d135cf4ff568830936cb5e119eaa27432953f41e57f19243e002cb11cf78fb124c720fe7f259a5516de74c1c4ea728a60471e5a87c485c1a7a7d340dcf70f9867d143c0638fca9388958326165f9543000bec5d585ea435f24dff77c3a08bc66c76c214a7adbc921918caae223ace0926d3746c93
txtSecretCode: 456
RadioButtonList1: 学生
Button1: 登录
txtKeyExponent: 010001
txtKeyModulus: 9E0B832A27697B3DD3158A3AAC3EBD609202F374AAD0BA0A7A66D02F466B4E82ABDC9235DFFE6F10645DB3D35DF68AE49628ABC6A7C379EC913DE3C701FC30A1CC4F39516A50F06350A5DD0D82215388DEE3758D87329EFCCF1AA1AC535B4966372CB3523536A3A742272A02805B717974A6021963635CC32AB4AE78CA4985392. 我这直接说结果,随便请求两次看请求的值有没有变化
一共3个变值,其他的都是固定的。
__VIEWSTATE: 加密
txtUserName: 用户名
TextBox2: 加密
txtSecretCode: 密码
txtKeyModulus: 固定
3. 分析加密使用逆向,查看源代码。看到他调用的库,经典的rsa加密

- 看见他的js代码,逆向一般就是js,每个学校的不一样,一般不会很难,复制就可以。
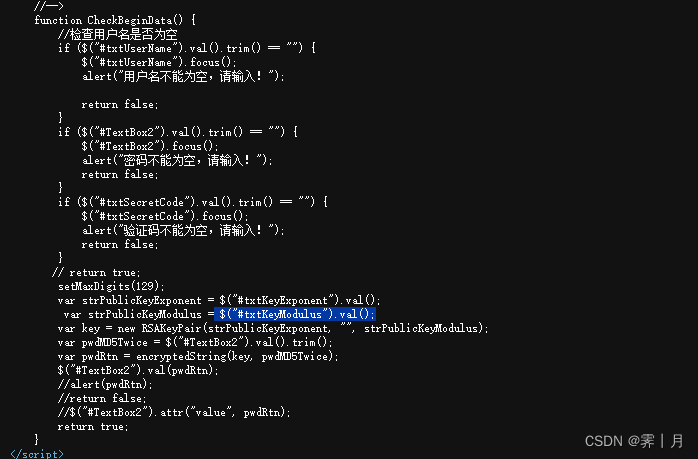
- 将他使用的加密代码和依赖的库复制到py项目文件夹中
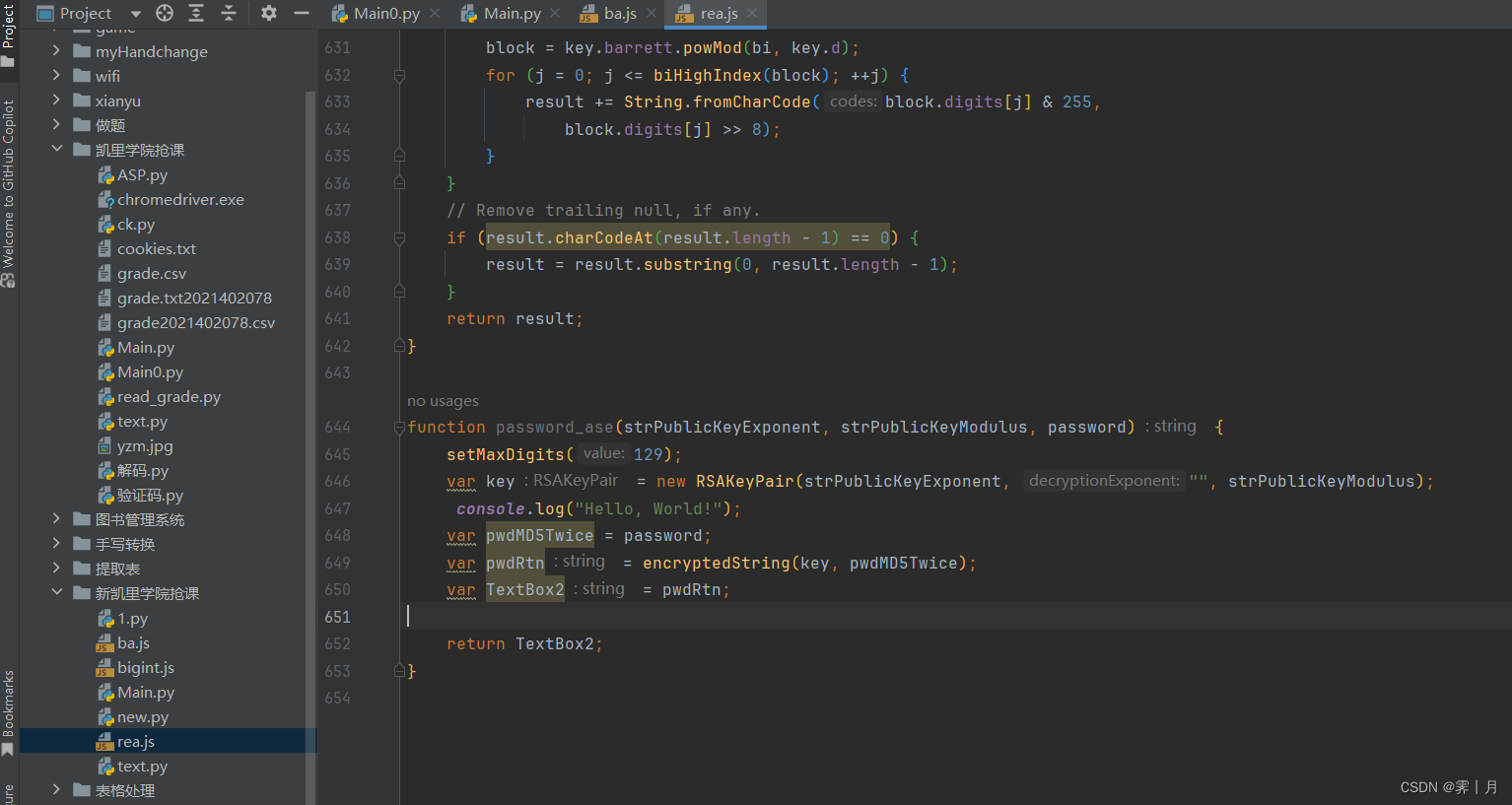
在源代码看看变值, 最后要的TextBox2 加密内容 需要的strPublicKeyExponent 和 strPublicKeyModulus也在页面源代码
__VIEWSTATE: 每次页面生成
txtUserName: 用户名
TextBox2: 加密
txtSecretCode: 密码
txtKeyModulus: 固定
4.分析完毕,开始写代码
1. 用session.get方法获取请求,拿到页面源代码,获取所需要的__VIEWSTATE
strPublicKeyExponent
strPublicKeyModulus
index_url = "http://sys.kluniv.edu.cn:8003/"
session = requests.session()
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 "
"Safari/537.36 Edg/121.0.0.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,"
"application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding": "gzip, deflate",
"Cookie": "_gscu_670124149=805331319upx0619; _ga=GA1.1.202793893.1685956507; "
"_ga_QYKCGTHFGK=GS1.1.1685956507.1.1.1685956952.0.0.0; "
"ASP.NET_SessionId=sekouqhtdlhnftj0rzj5ezwe",
"Host": "sys.kluniv.edu.cn:8003",
}
resp = session.get(index_url, headers=header)
print(resp.status_code)
soup = BeautifulSoup(resp.text, 'lxml')
viewState = soup.find('input', attrs={'name': '__VIEWSTATE'})['value']
public_key_exponent = soup.find('input', attrs={'name': 'txtKeyExponent'})['value']
public_key_modulus = soup.find('input', attrs={'name': 'txtKeyModulus'})['value']
yzm_url = soup.find()2. 将复制的js代码用 execjs 库读取运行(不会的自己查)
with open("rea.js", "r", encoding="utf-8") as file:
result = file.read()
file.close()
js = execjs.compile(result)
TextBox2 = js.call("password_ase", public_key_exponent, public_key_modulus, password)
rea.js包括了这4个js库的所有代码,一个不少的复制到自己创建的rea.js中,加入加密方法。
加密方法 password_ase 是分析源代码来的写为下面截图。返回的就是textbox2.

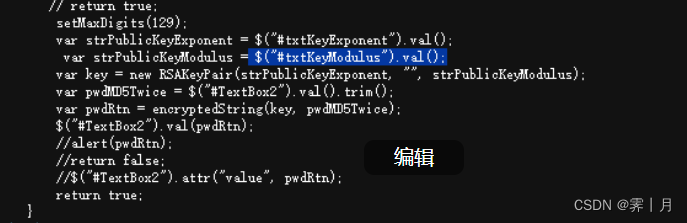
function password_ase(strPublicKeyExponent, strPublicKeyModulus, password) {
setMaxDigits(129);
var key = new RSAKeyPair(strPublicKeyExponent, "", strPublicKeyModulus);
console.log("Hello, World!");
var pwdMD5Twice = password;
var pwdRtn = encryptedString(key, pwdMD5Twice);
var TextBox2 = pwdRtn;
return TextBox2;
}3. 加密的逆向做完了,现在就是请求登录,还需要解决验证码。
找到url,这个也在源代码中,一样获取img_url ,其中get需要带有safekey参数,在url中用split获取。


resp = session.get(index_url, headers=header)
print(resp.status_code)
soup = BeautifulSoup(resp.text, 'lxml')
viewState = soup.find('input', attrs={'name': '__VIEWSTATE'})['value']
public_key_exponent = soup.find('input', attrs={'name': 'txtKeyExponent'})['value']
public_key_modulus = soup.find('input', attrs={'name': 'txtKeyModulus'})['value']
img_url = soup.find('img', attrs={'id': 'icode'})['src']
SafeKey = img_url.split("=")[-1]获取验证码并保存
# 发送请求 获取图片
img_url_total = index_url + img_url
print(img_url_total)
data_img = {
"SafeKey": SafeKey
}
resp_img = session.get(img_url_total, headers=header, stream=True, data=data_img)
print(resp_img.status_code)
with open(r'yzm.jpg', 'wb') as f:
f.write(resp_img.content)
f.close()获取成功后使用循环判断,图片是否保存成功,这个函数挺多余的,不要也一样。这样验证码也到手了,登录需要的数据就全部齐全了。
def one_sleep():
time.sleep(1)
# 识别验证码 识别之前以防图片还没有下载完成 判断文件是否存在 不存在时休眠1s
while not os.path.exists("yzm.jpg"):
one_sleep()
ocr = ddddocr.DdddOcr()
with open('yzm.jpg', 'rb') as f:
img_bytes = f.read()
yzm = ocr.classification(img_bytes)4. 开始登录,发送post请求,请求完成,在带着需要的参数get登陆后的页面,查看返回数据,返回成功我们就完成了登录,剩下的就是请求需要爬的页面获取数据或者请求。
data = {
"__VIEWSTATE": viewState,
"__VIEWSTATEGENERATOR": "9BD98A7D",
"txtUserName": user_id,
"TextBox2": TextBox2,
"txtSecretCode": yzm,
"RadioButtonList1": "学生",
"Button1": "登录",
"txtKeyExponent": "010001",
"txtKeyModulus": public_key_modulus
}
# print(data)
_resp = session.post(index_url, headers=header, data=data)
login_data = {
"xh": user_id
}
login_resp = session.get(index_url + f"/xs_main.aspx?xh={user_id}", headers=header, data=login_data)
print(login_resp.status_code)
print(login_resp.text)
5. 这是一个非常简单的逆向爬虫,做为初学者是非常容易的,后面的爬取成绩等具体功能会慢慢完善,大部分都是倒在了登录的逆向。
6. 完整代码
"""
新凯里学院官网
"""
import execjs # 用来执行js脚本
import requests # 用来请求网页,获取网页内容
from bs4 import BeautifulSoup # 用来解析网页内容
import csv # 用来写入csv文件
import re # 用来匹配内容
import time # 用来延时
import ddddocr # 用来识别验证码
import os # 用来判断文件是否存在
def one_sleep():
time.sleep(1)
index_url = "http://sys.kluniv.edu.cn:8003"
session = requests.session()
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 "
"Safari/537.36 Edg/121.0.0.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,"
"application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding": "gzip, deflate",
"Cookie": "_gscu_670124149=805331319upx0619; _ga=GA1.1.202793893.1685956507; "
"_ga_QYKCGTHFGK=GS1.1.1685956507.1.1.1685956952.0.0.0; "
"ASP.NET_SessionId=sekouqhtdlhnftj0rzj5ezwe",
"Host": "sys.kluniv.edu.cn:8003",
}
resp = session.get(index_url, headers=header)
print(resp.status_code)
soup = BeautifulSoup(resp.text, 'lxml')
viewState = soup.find('input', attrs={'name': '__VIEWSTATE'})['value']
public_key_exponent = soup.find('input', attrs={'name': 'txtKeyExponent'})['value']
public_key_modulus = soup.find('input', attrs={'name': 'txtKeyModulus'})['value']
img_url = soup.find('img', attrs={'id': 'icode'})['src']
SafeKey = img_url.split("=")[-1]
yzm_url = soup.find()
user_id = 2021402078
password = ""
# print(img_url)
# js逆向 textbox2
with open("rea.js", "r", encoding="utf-8") as file:
result = file.read()
file.close()
js = execjs.compile(result)
TextBox2 = js.call("password_ase", public_key_exponent, public_key_modulus, password)
# 发送请求 获取图片
img_url_total = index_url + img_url
# print(img_url_total)
data_img = {
"SafeKey": SafeKey
}
resp_img = session.get(img_url_total, headers=header, stream=True, data=data_img)
print(resp_img.status_code)
with open(r'yzm.jpg', 'wb') as f:
f.write(resp_img.content)
f.close()
# 识别验证码 识别之前以防图片还没有下载完成 判断文件是否存在 不存在时休眠1s
while not os.path.exists("yzm.jpg"):
one_sleep()
ocr = ddddocr.DdddOcr()
with open('yzm.jpg', 'rb') as f:
img_bytes = f.read()
yzm = ocr.classification(img_bytes)
data = {
"__VIEWSTATE": viewState,
"__VIEWSTATEGENERATOR": "9BD98A7D",
"txtUserName": user_id,
"TextBox2": TextBox2,
"txtSecretCode": yzm,
"RadioButtonList1": "学生",
"Button1": "登录",
"txtKeyExponent": "010001",
"txtKeyModulus": public_key_modulus
}
# print(data)
_resp = session.post(index_url, headers=header, data=data)
login_data = {
"xh": user_id
}
login_resp = session.get(index_url + f"/xs_main.aspx?xh={user_id}", headers=header, data=login_data)
print(login_resp.status_code)
print(login_resp.text)
resp.close()
login_resp.close()















 1838
1838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









