







HBase过滤器是一种在读取HBase数据时进行数据过滤的机制。它允许用户根据定义的条件对数据进行过滤,以便仅获取满足条件的数据。
HBase过滤器使用HBase过滤器语言进行配置和使用。HBase过滤器语言是一种用于配置和定义HBase过滤器的语言。它允许用户使用一组操作符和关键字来定义过滤器条件。
目录
17)SingleColumnValueExcludeFilter
一. 环境准备
-
Ubuntu 虚拟机
-
Hadoop 2.10.1
-
Hbase 2.3.5
-
jdk 1.8.0 (java 8)
二. 作业步骤
1. 设计作业需要用到的表和数据
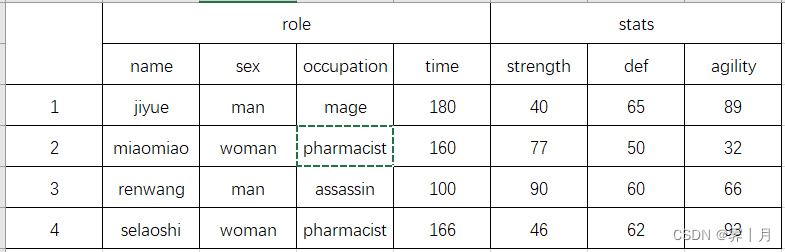
首先创建一个名为 “game” 的游戏表。此表为《逆水寒手游》帮派成员属性图,如下。
2. 创建表
使用命令创建我们要使用的表格
create 'game','role','stats'
3. 插入数据
根据设计好的表格编写插入数据命令。
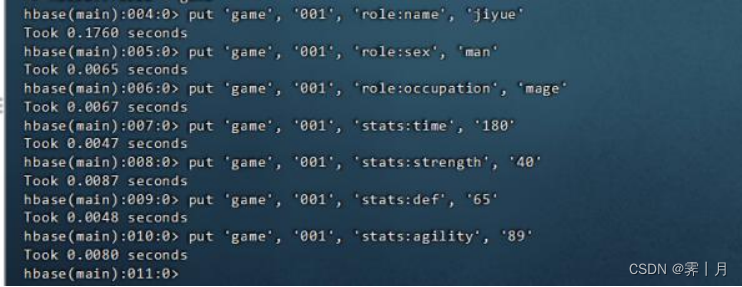
# 插入第一行数据
put 'game', '001', 'role:name', 'jiyue'
put 'game', '001', 'role:sex', 'man'
put 'game', '001', 'role:occupation', 'mage'
put 'game', '001', 'stats:time', '180'
put 'game', '001', 'stats:strength', '40'
put 'game', '001', 'stats:def', '65'
put 'game', '001', 'stats:agility', '89'
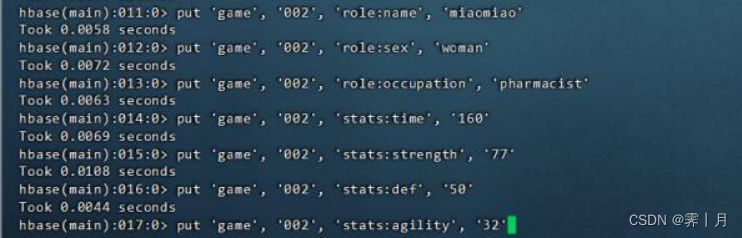
# 插入第二行数据
put 'game', '002', 'role:name', 'miaomiao'
put 'game', '002', 'role:sex', 'woman'
put 'game', '002', 'role:occupation', 'pharmacist'
put 'game', '002', 'stats:time', '160'
put 'game', '002', 'stats:strength', '77'
put 'game', '002', 'stats:def', '50'
put 'game', '002', 'stats:agility', '32'
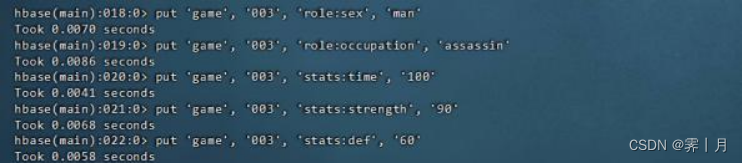
# 插入第三行数据
put 'game', '003', 'role:name', 'renwang'
put 'game', '003', 'role:sex', 'man'
put 'game', '003', 'role:occupation', 'assassin'
put 'game', '003', 'stats:time', '100'
put 'game', '003', 'stats:strength', '90'
put 'game', '003', 'stats:def', '60'
put 'game', '003', 'stats:agility', '66'
# 插入第四行数据
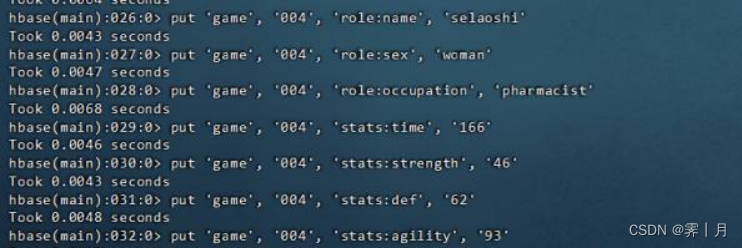
put 'game', '004', 'role:name', 'selaoshi'
put 'game', '004', 'role:sex', 'woman'
put 'game', '004', 'role:occupation', 'pharmacist'
put 'game', '004', 'stats:time', '166'
put 'game', '004', 'stats:strength', '46'
put 'game', '004', 'stats:def', '62'
put 'game', '004', 'stats:agility', '93'插入第一行数据
插入第二行数据
插入第三行数据
插入第四行数据
4. 查看数据
使用 scan “表名” 的命令查看表数据,检查一边,全部都是插入成功了
scan 'game'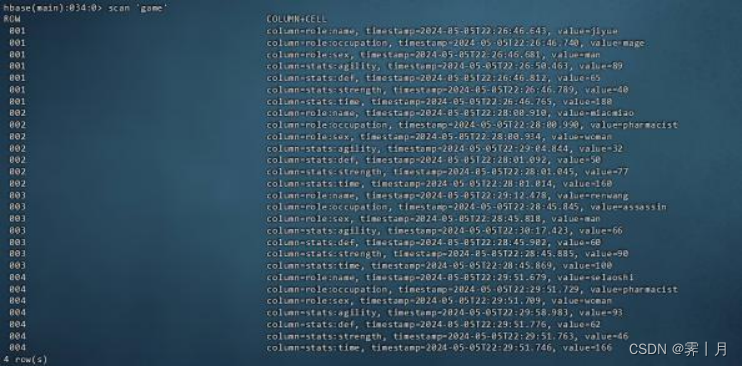
5. 编写18个filter的demo
1)KeyOnlyFilter
行过滤器的一种,它允许你只获取行键(row keys)而不获取与这些行键关联的任何列值。这在只需要行键的列表,而不需要额外的列数据时非常有用。运行命令后发现,和 scan “ game ” 的区别就是,value的具体数值是没有打印出来的。
具体命令如下:
scan 'game', {FILTER => "KeyOnlyFilter()"}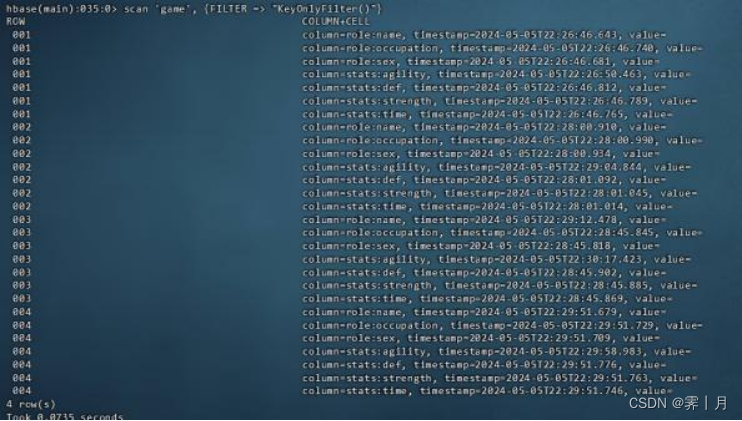
2)FirstKeyOnlyFilter
行过滤器的一种,他用于在扫描(scan)表时仅返回每行中的第一个 key-value 对。
scan 'game', {FILTER => "FirstKeyOnlyFilter()"}

3)PrefixFilter
行过滤器的一种,这个可以扫描那些行键以特定前缀开头的行。
scan 'game', {FILTER => "PrefixFilter('001')"}
scan 'game', {FILTER => "PrefixFilter('002')"}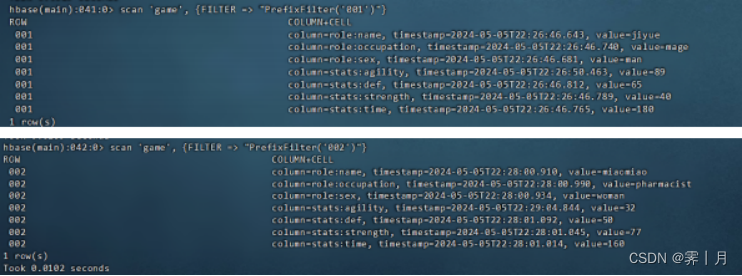
4) ColumnPrefixFilter
列过滤器的一种,扫描那些列名(包括列族和列限定符)以特定前缀开头的列的键值对。
比如查看 “name” 列 或者 “def
scan 'game', {FILTER => "ColumnPrefixFilter('name')"}
scan 'game', {FILTER => "ColumnPrefixFilter('def')"}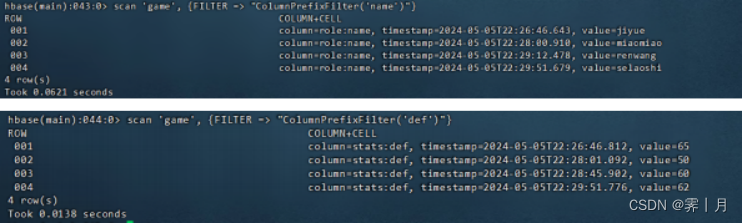
5)MultipleColumnPrefixFilter
列过滤器的一种,正如Multiple这个名字,他可以指定多个前缀
比如同时查看 “name” 列 和 “time”列。
scan 'game', {FILTER => "MultipleColumnPrefixFilter('name', 'time')"}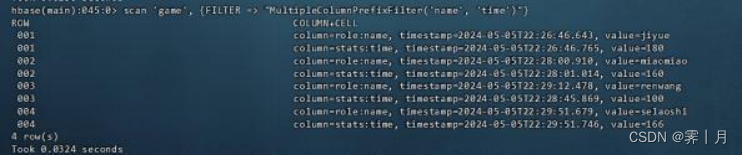
6)ColumnCountGetFilter
列过滤器的一种,该过滤器带1个参数—limit。它返回表中(各行的)前limit列。
比如查看每一行的前三列,查看002行的前三列。
scan 'game', {FILTER => "ColumnCountGetFilter(3)"}
get 'game','002',{FILTER =>"ColumnCountGetFilter(3)"}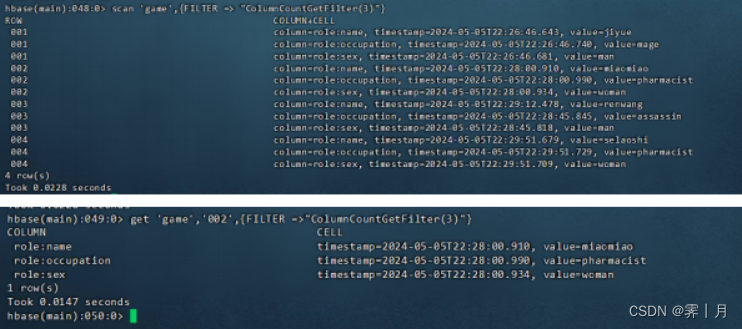
7) PageFilter
基于行的分页过滤器,设置返回行数。表game中有rowkey为“001”,“002”,“003”,“004”的4行记录。那么执行完 PageFilter(3)之后的结果是rowkey为“001”,“002”,“003”这3行的记录。
scan 'game',FILTER=>"PageFilter(1)"
8) ColumnPaginationFilter
基于列的进行分页过滤器,需要设置偏移量与返回数量 。偏移量:就是从什么地方开始。
显示每行第2列之后的2个键值对
scan 'game',FILTER=>"ColumnPaginationFilter(2,2)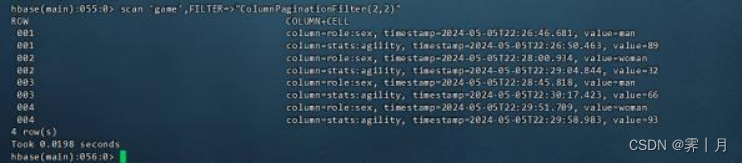
9) InclusiveStopFilter
行键过滤器的一种,可以指定扫描应该停止的行键,但默认情况下,这个行键是不被包含在结果中的。
比如:扫描显示行键001到002范围内的键值对
scan 'game', {STARTROW =>'001',FILTER =>"InclusiveStopFilter('002')"}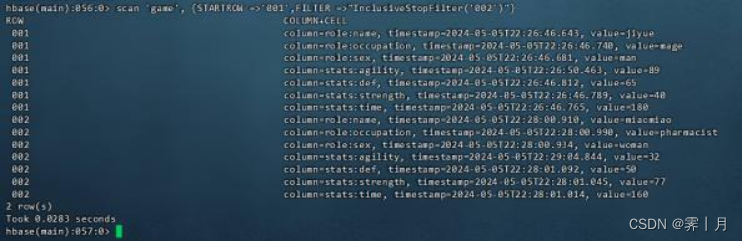
10)TimestampsFilter
这个是以时间戳为参数的过滤器,它返回以给定这一组时间戳中任意 一个匹配的时间戳所对应的键值对。
因为hbase shell上面的timestamp是ISO 8601格式的。但是这玩意用不了,我们需要毫秒级的timestamp。所以我们可以java或者其他的去远程读取一下,我们读取了第一行第一列的数据时间戳为 “ 1714919206643 ”, 第二行第一列的数据时间戳为 "1714919280910"。
scan 'game',FILTER=>"TimestampsFilter(1714919206643,1714919280910)"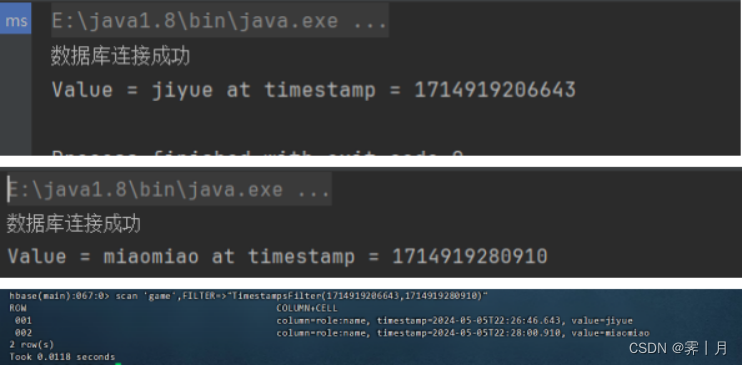
11) RowFilter
他是属于行键过滤器,针对行键进行过滤。但是他可以带一个比较运算符和一个比较器(作为参数)。它通过使用 比较运算符将(表中)每一行键与比较器进行比较,如果返回true,则将 (满足条件的那一行)所有的键值对返回。
比如查看行键字节顺序大于002的键值对 或者 查看行键字节顺序等于003的键值对
scan 'game',FILTER=>"RowFilter(>,'binary:002')"
scan 'game',FILTER=>"RowFilter(=,'binary:003')"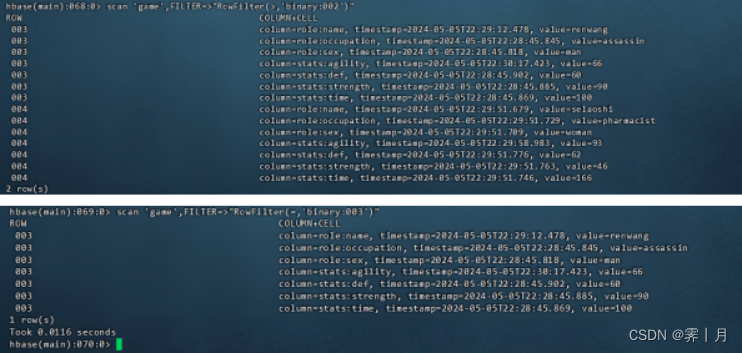
12)FamilyFilter
这是一个列族过滤器,通过列族进行比较和过滤。该过滤器带一个比较运算符和一个比较器(作为参数)。它通过使用 比较运算符将(表中)每一个列标识符名与比较器进行比较,如果返回 true,则将(满足条件的那一列族中的所有列)所有的键值对返回
比如查看带有stats这个列族的数据
scan 'game',FILTER=>"FamilyFilter(=,'substring:stats')"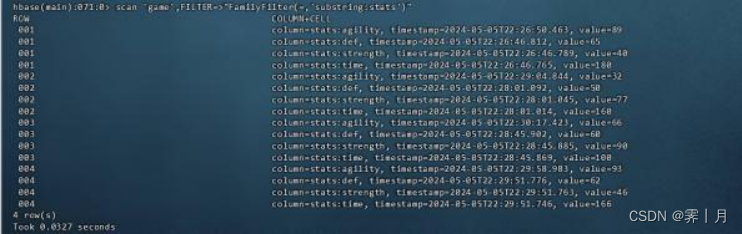
13)QualifierFilter
这也是一个列过滤器。该过滤器带一个比较运算符和一个比较器(作为参数)。它通过使用 比较运算符将(表中)每一个列标识符名与比较器进行比较,如果返回 true,则将(满足条件的每一行中的列)所有的键值对返回
比如查看 等于带有 ”strength“ 这一列
scan 'game',FILTER=>"QualifierFilter(=,'substring:strength')"
14)ValueFilter
这是值过滤器,该过滤器带一个比较运算符和一个比较器(作为参数)。它通过使用 比较运算符将(表中)每一个(单元格的)值与比较器进行比较,如果返回 true,则将(满足条件的单元格对应的)所有的键值对返回。
比如查看值带有”man“的所有键值对 和 查询值等于带有pharmacist的所有键值对
scan 'game',FILTER=>"ValueFilter(=,'substring:man')"
scan 'game',FILTER=>"ValueFilter(=,'substring:pharmacist')"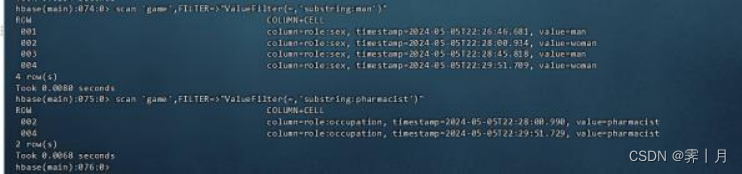
15)DependentColumnFilter
这个过滤器以指定列的时间戳 去与表中其它的行中相同列各个单元格的时间戳进行比对,若时间戳小于或 者等于指定列的时间戳,则返回。这个指定的列我们就称为Dependent Column(依赖列)。
这个是查看列族为 role and 列为name and 值为 renwang这一行,对比他的时间戳,如果比他小,返回false的结果,也就是返回时间戳比它大的。

16)SingleColumnValueFilter
指定的列族和列中进行值过滤器。这个过滤器带1个列族,1个列标识符,1个比较运算符以及1个比较 器(作为参数)。如果指定的列没有找到则对应行中的列所有均返回。如果 指定列找到且与比较器比较结果返回true,则该行对应的所有列均返回。如 果不满足条件,对应行将不返回。
比如 查询stats列族def列中值大于60的所有键值对 (如果不指定列将输出,带有这个列的列族所有内容)
scan'game',FILTER=>"DependentColumnFilter('role','name',false,>,'binary:renwang')"scan 'game',
{COLUMN=>'stats:def',FILTER=>"SingleColumnValueFilter('stats','def',>,'binary:60 ')"}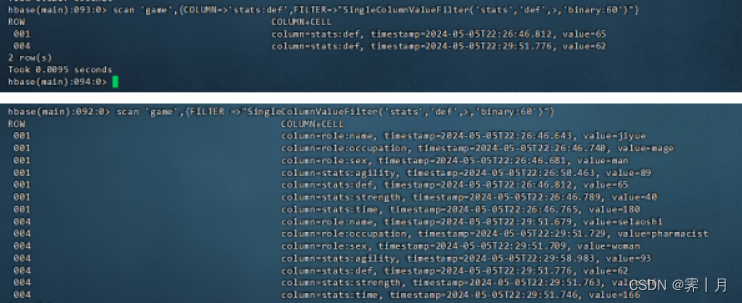
17)SingleColumnValueExcludeFilter
该过滤器与SingleColumnValueFilter 所带的参数及行为是一样的。 然而,如果指定列找到且满足条件,则对应行中除指定列外的左右列均返 回。
如上案例,不同的是他是返回除了 'stats:def'的所有列。
scan 'game',{FILTER=>"SingleColumnValueExcludeFilter('stats','def',>,'binary:60')"}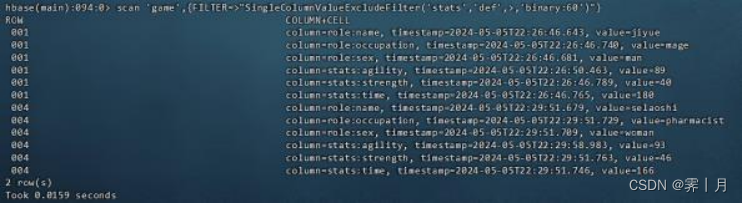
18)ColumnRangeFilter
设置范围按字典序对列名进行过滤,该过滤器仅用来对minColumn和maxColumn之间的键进行选择(操 作)。它还可以带有两个布尔变量作为参数表示是否包含aminColumn和 maxColumn。
比如扫描 'game' 表中所有列限定符在 'se'和 'ti'之间的列
scan 'game', {FILTER=>"ColumnRangeFilter('se', true, 'ti', true)"}















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









