







1.简介
文件操作,也称为IO操作,IO指的是Input/Output,就是输入和输出的意思。通常程序完成IO操作会有Input和Output两个流。当然也有只有一个的情况,比如,从磁盘读取文件到内存,就只有Input操作。而把数据写到磁盘文件里,就只有一个Output操作。
在IO操作中,分为同步IO和异步IO。
同步IO的意思是Output或Input,快的一方必须等待慢的一方完成才会继续往下走。比如当要把100M数据写入磁盘,CPU输出100M的数据只需要0.01秒,而磁盘接收这100M数据可能需要10秒。此时,CPU的速度快,而磁盘速度慢,CPU就会挂起自己,等待磁盘完成后,再继续往下走。这就是同步IO。
异步IO的意思是Output或Input,快的一方不需要等待,直接跳过去做自己的事情,留下慢的一方慢慢完成动作。完成后,产生一个信号告诉快的一方。此时快的一方会告诉慢的一方接下来该干什么。还是上边的例子,CPU在告诉磁盘要写之后,就去做其他事情了。磁盘自己慢慢写,写完后,告诉CPU。CPU再告诉磁盘接下来的动作。
2.文件读写
读写文件是最常见的IO操作。Python内置了读写文件的函数,用法与C语言是兼容的。
读文件
open
操作系统是不允许普通的程序直接操作磁盘的读写功能。所以,读写文件就是请求操作系统打开一个文件对象(通常称为文件描述符),然后通过操作系统提供的接口对这个文件进行读/写操作。
文件描述符 = open("文件路径(包括文件名)","属性")
例如:
f = open("c:/python/test",'r')"属性"值介绍。带b的参数表示操作二进制文件,不带b的操作文本文件。
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
如果打开的文件不存在,open函数则会抛出一个IOError的错误,并且给出错误码和详细的信息,提示文件不存在。
open("d:/python/test.txt",'r')当文件不存在时:

在Python中将Open()函数返回的对象称为file-like Object。除了file外,还可以是内存的字节流,网络流,自定义等等。file-like Object不要求从特定类继承,只要写个read()方法就行。
read
如果文件打开成功,则可以通过调用read()函数,读取文件的全部内容。python是把内容读到内存中,输出为str类型。
在d:/python/目录下创建一个test.txt文件,文件内容为"this is a IO test file"
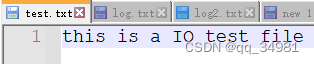
f = open("d:/python/test.txt",'r')
print("d:/python/test.txt,data>>>>>>>%s" %f.read())结果:
![]()
如果说,不想读全部内容,只想读部分内容,可以通过传入参数来实现。比如现在只想读6个字节。就可以通过read(6)来实现。
f = open("d:/python/test.txt",'r')
print("d:/python/test.txt,data>>>>>>>%s" %f.read(6))结果:
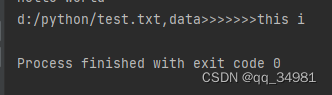
可以看到 ,此时就只读了该文件的前6个字节。
如果希望一行一行读,可以通过readlines来实现,
例如,现在创建一个文件,内容如下:
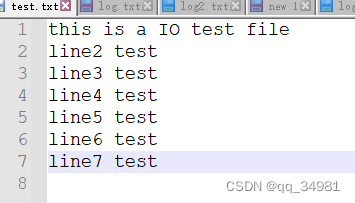
现在要把每一行都打印出来,可以通过如下代码实现:
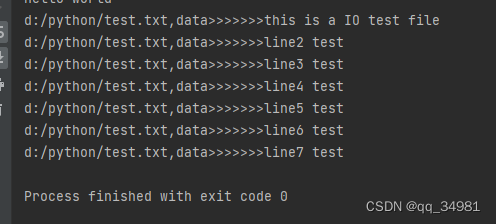
with open('d:/python/test.txt', 'r') as f:
for line in f.readlines():
print("d:/python/test.txt,data>>>>>>>%s" %line)结果如下:

但是发现行与行之间有一个空行,那是因为在打印的时候,将每一行后边的“\n”换行符也打印了出来。如果不希望打印出来,可以通过strip函数来实现。
with open('d:/python/test.txt', 'r') as f:
for line in f.readlines():
print("d:/python/test.txt,data>>>>>>>%s" %line.strip()) # 把末尾的'\n'删掉结果:
write
“w”和“wb”
写文件和读文件是一样的,唯一区别是在调用open()函数时,传入的标识符为"w"或"wb",来表示表示写文本文件或写二进制文件

with open('d:/python/test.txt', 'w') as f:
f.write("hello world")
如果想写完之后读出文件内容。需要在操作完之后,重新打开文件,并读取。
with open('d:/python/test.txt', 'w') as f:
f.write("hello world")
with open('d:/python/test.txt', 'r') as f:
print("data:%s" %f.read())结果:

需要注意的是“w”标识符的意思是在写之前,将源文件的内容覆盖掉。例如我们之前的文件内容是“123456789”。在运行完程序后,文件内容就会变成“hello world”。所以,需要谨慎使用。
“w+”
标识符如果设置为"w+"的话,是可读可写的意思。那既然是可读可写。代码是不是可以这么写。
![]()
with open('d:/python/test1.txt', 'w+') as f:
f.write("hello world")
print("data:%s" %f.read())这样写法感觉可以写完之后读出来,但是运行结果却跟期望不同。
结果:
![]()
发现读出来的内容为空。为什么会这样呢。那再添加测试代码试一下。
with open('d:/python/test1.txt', 'w+') as f:
f.write("hello world")
print("data:%s" %f.read())
with open('d:/python/test.txt', 'r') as f:
print("data:%s" %f.read())结果:

由此可见,在“w+”标识符的作用下,必须关闭文件后,才能再次读取。否则是读不到数据的。
“r+”
标识符“r+”也有读写的意思,那么“r+”和“w+”有什么区别呢?
![]()
看如下代码:
with open('d:/python/test.txt', 'r+') as f:
print("data:%s" % f.read())
f.write("hello world")
print("data:%s" %f.read())
with open('d:/python/test.txt', 'r') as f:
print("data:%s" %f.read())结果:

可以看到,“r+”标识符在一开始的时候,是可以读取数据内容的,并且在调用wrtie()函数之后,并没有将原文件内容覆盖,而是在文件结尾处进行追加写入。这就是“r+”与“w+”最本质的区别。
“a”
“a”标识符是追加的意思,但是这个追加只能写,而不能读。

创建一个txt文件,内容为123,使用如下代码。
with open('d:/python/test.txt', 'a') as f:
print("data:%s" % f.read())
f.write("hello world")
print("data:%s" %f.read())
with open('d:/python/test.txt', 'r') as f:
print("data:%s" %f.read())结果:
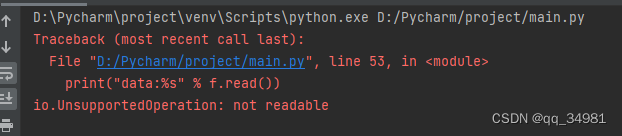
由此可见,“a”标识符,只有写属性,不能读。修改代码:
with open('d:/python/test.txt', 'a') as f:
f.write("hello world")
with open('d:/python/test.txt', 'r') as f:
print("data:%s" %f.read())结果:

可见,“a”标识符是将写的内容追加到文件后边。
“a+”

“a+”是提供读写的属性,那跟“r+”有什么区别呢?
看如下测试代码:
with open('d:/python/test.txt', 'a+') as f:
print("data:%s" %f.read())
f.write("hello world")
print("data:%s" %f.read())
with open('d:/python/test.txt', 'r') as f:
print("data:%s" %f.read())结果:

发现,虽然“a+”是有读写属性的,但是在文件打开后,却不能读。而“r+”是可以直接读取的。
通过以上代码,可能会很疑惑,为什么在写的时候不能读呢?那是因为当在执行写操作时,操作系统往往不会立刻把数据写入磁盘,而是先放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。如果没有调用close方法,那么可能会造成数据只写入磁盘了一部分,出现数据丢失的情况。所以,最好的方法,就是使用with语句来保证文件写的可靠性。
close
在IO操作完成后,需要调用close来关闭文件。该操作是必须执行的,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的。
由于文件读写时都有可能会产生IOError,一旦出错,后边的close就不会被执行。所有,为了保证无论是否出错都能正确地关闭文件,可以使用try--finally来实现。
try:
f = open('d:/python.test.txt', 'r')
print(f.read())
finally:
if f:
f.close()但是每次都这么写是在太麻烦,所以,python引入了with语句来自动帮我们调用close方法。
with open('d:/python/test.txt', 'r') as f:
print(f.read())with语句实现的功能与try finally是一样的,只不过with的写法更加简洁,并且不必调用f.close()方法。
3.二进制文件的读写
什么是二进制文件
通常情况下,扩展名为.bin的文件就是一个二进制文件(binary)。不同于文本文件,二进制文件用记事本、notepad++等打开都是乱码。

二进制文件可以使用VSCode软件打开,但是需要下载扩展程序“Hex Editor”。

注:以前可以用hexdump for VSCode,但是最近好像因为某些原因,被VSCODE给下架了。
那这里就以Hex Editor软件为例。打开我们要查看的二进制文件。因为VSCODE默认是不支持二进制文件,所以会报错。
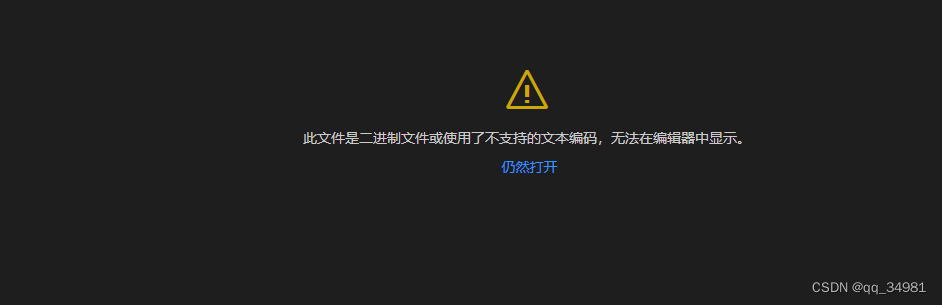
按F1,选择Hex Editor: Open active File in Hex Editor.

此时可以查看二进制文件内容。
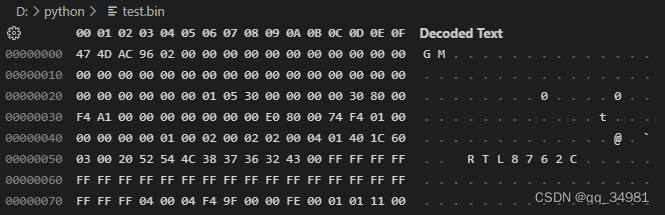
二进制文件相比于文本文件的优点是,节约存储空间、读写速度快、有一定的加密保护作用。
二进制文件的读
![]()
对二进制文件的读取,需要使用“rb”标识符。
with open('d:/python/test.bin', 'rb') as f:
print("data:%s" %f.read())结果:

这里可以看到,read()函数是可以直接输出二进制文件的。但是内容前都有\x的标志,该标志表示当前内容为十六进制。
如果不想要看十六进制,想要直接得到十进制,那就需要使用struct.unpack()函数进行格式转换了。
函数原型为:unpack(fmt,string)。Unpack可以按照给定的格式(fmt)解析字节流string,返回解析出来的tuple。fmt的类型有如下:
| FORMAT | C TYPE | PYTHON TYPE | STANDARD SIZE | NOTES |
|---|---|---|---|---|
| x | pad byte | no value | ||
| c | char | string of length 1 | 1 | |
| b | signed char | integer | 1 | (3) |
| B | unsigned char | integer | 1 | (3) |
| ? | _Bool | bool | 1 | (1) |
| h | short | integer | 2 | (3) |
| H | unsigned short | integer | 2 | (3) |
| i | int | integer | 4 | (3) |
| I | unsigned int | integer | 4 | (3) |
| l | long | integer | 4 | (3) |
| L | unsigned long | integer | 4 | (3) |
| q | long long | integer | 8 | (2), (3) |
| Q | unsigned long long | integer | 8 | (2), (3) |
| f | float | float | 4 | (4) |
| d | double | float | 8 | (4) |
| s | char[] | string | ||
| p | char[] | string | ||
| P | void * | integer | (5), (3) |
当需要将二进制文件的内容转换为十进制,就需要设置fmt参数为“B”,即将C语言中的unsigned char类型(uint8_t),转化为python能识别的integer(int)类型(注:该参数是区分大小写的)。那么上边的代码就可以修改为如下:
with open('d:/python/test.bin', 'rb') as f:
binary = f.read()
dec = struct.unpack(len(binary)*"B",binary)
print(f"data:{dec}")结果:
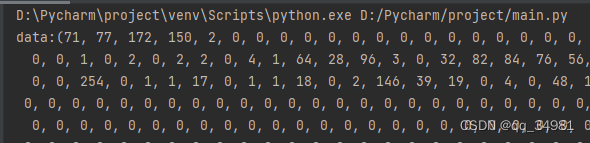
也可以将代码该为如下:
with open('d:/python/test.bin', 'rb') as f:
size = os.path.getsize("d:/python/test.bin") #获取文件大小
for i in range(size):
bin = f.read(1)
dec = struct.unpack("B",bin)
print(f"data:{dec}")结果:
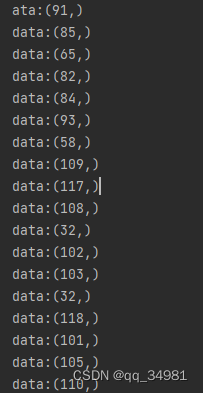
从上述代码中可以看到,struct.unpack()函数输出的最终结果是一个tuple(元组)。所以输出的内容都是(XX,)。如果不希望看到这个,只想要一个值的话,可以这么修改。
with open('d:/python/test.bin', 'rb') as f:
size = os.path.getsize("d:/python/test.bin") #获取文件大小
for i in range(size):
bin = f.read(1)
dec = struct.unpack("B",bin)
print(f"data:{dec[0]}") #输出元组有效数据结果:
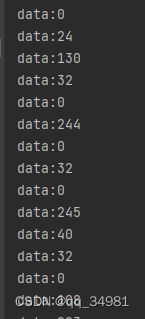
二进制文件的写

对于二进制文件的写,不能直接写入内容,需要将要写入的值转换为bytes类型才可以。可以看如下代码。
content_int = 100
print("type:%s" %type(content_int))
content_byte = content_int.to_bytes(1,'big')
print("type:%s" %type(content_byte))
with open('d:/python/test.bin', 'wb') as f:
f.write(content_int)
with open('d:/python/test.bin', 'rb') as f:
binary = f.read()
dec = struct.unpack(len(binary)*"B",binary)
print(f"data:{dec}")程序报错:
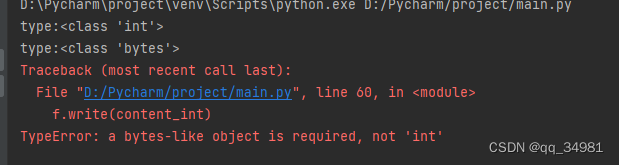
可以看到,最开始的时候,类型为int,经过转换后,结果就是bytes型了。那将代码修改一下。
content_int = 100
print("type:%s" %type(content_int))
content_byte = content_int.to_bytes(1,'big')
print("type:%s" %type(content_byte))
with open('d:/python/test.bin', 'wb') as f:
f.write(content_byte)
with open('d:/python/test.bin', 'rb') as f:
binary = f.read()
dec = struct.unpack(len(binary)*"B",binary)
print(f"data:{dec}")结果:

这时候,程序就能完整输出了。 输出的结果仍然是一个元组tuple
这里需要介绍.to_bytes函数,该函数有三个参数。
1.要转换的值占了几个字节。
2.big大端,little 小端
3.有符号、无符号。可不写
4.进阶操作
很多时候,对文件进行操作时,我们需要更快的方式找到文件。那么就需要能更快的知道目标文件的路径。此时就需要用到进阶的函数来帮忙了。
os.path.abspath 当前绝对路径
函数原型;def abspath(path: AnyStr) -> AnyStr: ...
该函数用来获取当前工程文件所在的绝对路径。
t_path = os.path.abspath('.') # 当前绝对路径
print(t_path)结果:

可以看到,该函数将当前文件的绝对路径打印了出来。当前文件就是编写py的文件。
os.listdir() 列出目录
函数原型:def listdir(*args, **kwargs):
当参数为 "." 时,则列出当前目录列表
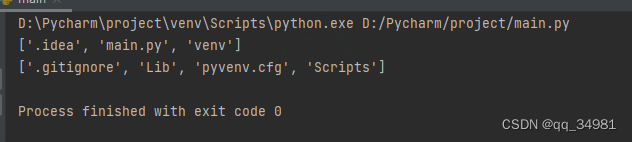
t_path = os.listdir('.') #列出当前目录列表
print(t_path)结果:

可以看到跟本身的文件目录是对应的。
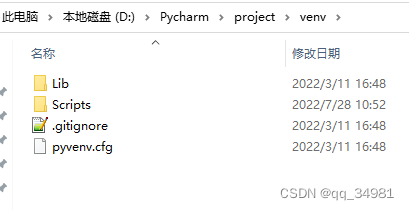
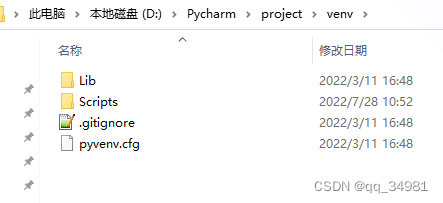
如果想要列出“venv”文件夹的目录,则可以将代码修改为:
t_path = os.listdir('./venv') #列出当前目录列表
print(t_path)结果:

os.path.join 添加绝对路径
函数原型:def join(path: BytesPath, *paths: BytesPath) -> bytes: ...
有时,当前操作的路径需要改变时,就可以通过该函数来进行操作。例如,当我们需要打印该文件夹下的另一个文件夹的目录,此时就可以调用os.path.join来改变当前的路径。
t_path = os.listdir('.')
print(t_path)
new_path = os.path.join('.','venv')
t_path = os.listdir(new_path)
print(t_path)结果:


可以看到,我们通过os.path,join函数,组合出了一个新的路径,从而打印出该路径下的目录、
那有没有更方便的操作呢?有!可以这样写。
t_path = os.listdir('.')
print(t_path)
t_path = os.listdir('.' + "\\" + 'venv')
print(t_path)结果:
这里我们直接使用" +"\\" " 的方式,组装出了新的路径。与os.path.join组装出来的路径是完全相同的。
注:这里“\\”转义为"/"。
所以,上述代码我们也可以这么写:
os.listdir('.' + "/" + 'venv')
或
os.listdir('./venv')效果是相同的。
os.path.split 拆分路径
函数原型:def split(p: AnyStr) -> tuple[AnyStr, AnyStr]: ...
有添加路径,自然也有拆分路径。该函数将路径进行拆封,分离出路径的最后一个文件。见如下代码:
t_path = os.path.abspath('.') #获取当前绝对路径
print(f"path:{t_path}")
print(os.path.split(t_path)) #打印
print(os.path.split("D:/Pycharm/project/venv/test.txt"))结果:
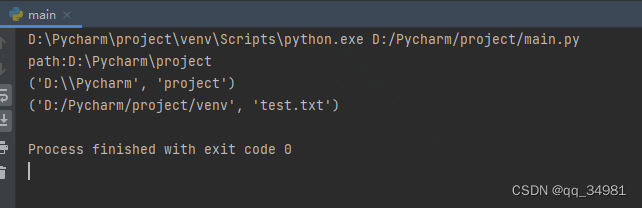
可以看到,该函数将路径进行了分离,将路径的最后一个参数分离出来,不管该参数是文件夹还是文件。
注:从函数原型可以看出,该函数最终得到的结果是一个元组tuple类型。
os.path.splitext 拆分扩展名
函数原型:def splitext(p: AnyStr) -> tuple[AnyStr, AnyStr]: ...
有时候需要文件的扩展名进行相关操作时,就需要先得到文件的扩展名,此时,该函数就起作用了。看如下代码:
t_path = os.path.abspath('.') #获取当前绝对路径
print(f"path:{t_path}")
print(os.path.splitext(t_path)) #打印
print(os.path.splitext("D:/Pycharm/project/venv/test.txt"))
t_tuple = os.path.splitext("D:/Pycharm/project/venv/test.txt")
print(t_tuple[0])
print(t_tuple[1])结果:
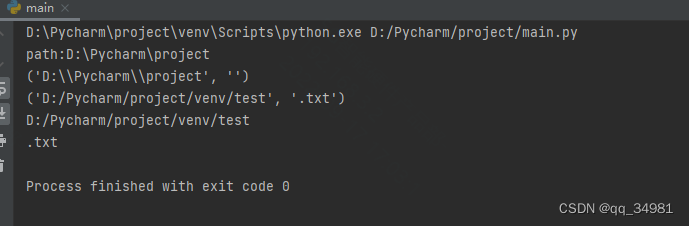
可以看到,该函数将扩展名分离出来。如果最后一个参数是一个文件夹,即没有扩展名时,则打印为空。
注:从函数原型可以看出,该函数最终得到的结果是一个元组tuple类型。
那如果根据扩展名来进行文件查找或过滤呢?看如下代码:
t_path = os.listdir('.')
print(t_path)
for file in t_path:
if os.path.splitext(file)[1] == '.py':
print(file)结果:
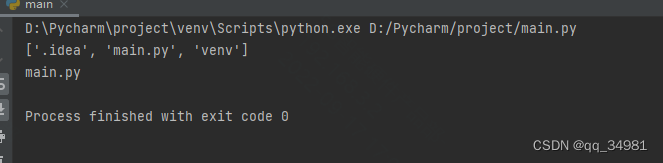
当需要某个特定扩展名的文件时,就可以通过该函数来进行过滤。
需要注意的是,该函数只会过滤后缀名,但是不会区分该文件性质,所以如果发生如下情况,就可能会出现意料之外的事情。
当在执行刚才的代码后,结果如下:
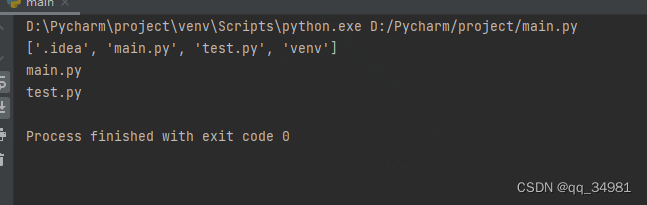
发现连test.py都打印出来了,实际上test.py只是一个文件夹,并不是一个文件。如果此时我们根据结果去分析的话,就可能会把test.py当成一个文件进行分析,那就可能会出错。所以,需要再加一个过滤条件,os.path.isfile。该函数在下面有说明。那代码修改为如下:
t_path = os.listdir('.')
print(t_path)
for file in t_path:
if os.path.splitext(file)[1] == '.py' and os.path.isfile(file):
print(file)结果:
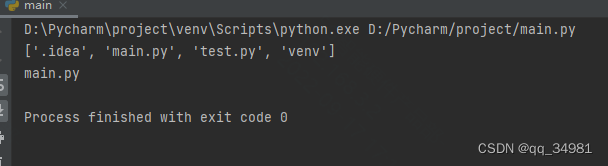
结果正常。
os.path.isdir 判断是否为文件夹
函数原型:def isdir(s: StrOrBytesPath) -> bool: ...
该函数是用来判断传参是否为文件夹,是则返回true,否则返回false。
t_path = os.listdir('.') #获取当前目录
print(t_path) #打印目录
for file in t_path: #遍历目录
if os.path.isdir(file): #是否为文件夹
print(f"is folder:{file}") #打印结果:
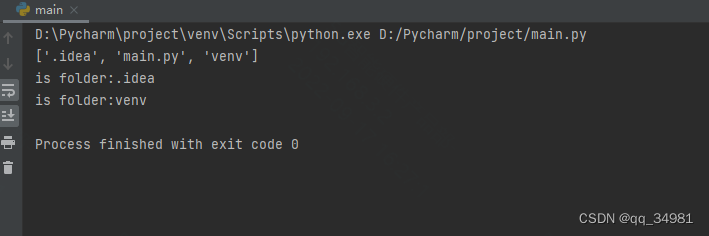
注:该函数的传参理论上应该是一个绝对地址。否则,该函数会认为要判定的文件在当前目录下。见如下代码:
t_path = os.listdir('./venv') #获取目录
print(t_path) #打印目录
for file in t_path: #遍历目录
if os.path.isdir(file): #是否为文件夹
print(f"is folder:{file}") #打印结果:


可以看到,该函数并没有识别到“Lib”和"Scripts"文件夹。在这种情况下,就必须添加更完整的路径给参数,该函数才能起作用。例如:
t_path = os.listdir('./venv') #获取目录
print(t_path) #打印目录
for file in t_path: #遍历目录
if os.path.isdir('./venv' + "/" + file): #添加更详细的路径。是否为文件夹
print(f"is folder:{file}") #打印结果:
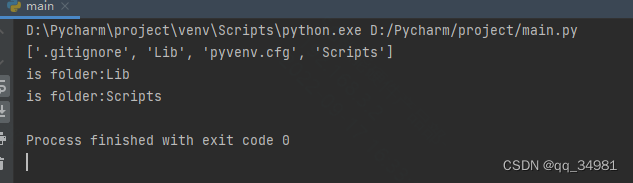
在添加了更清楚的路径后,该函数成功起作用。
os.path.isfile 判断是否为文件
函数原型:def isfile(path: StrOrBytesPath) -> bool: ...
该函数是用来判断传参是否为文件夹,是则返回true,否则返回false。
t_path = os.listdir('.') #获取目录
print(t_path) #打印目录
for file in t_path: #遍历目录
if os.path.isfile(file): #是否为文件
print(f"is file:{file}") #打印结果:
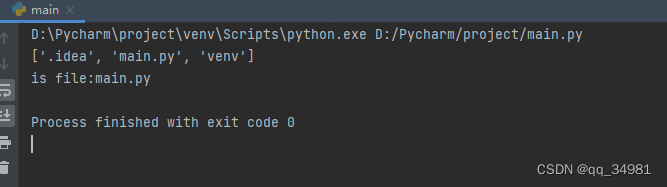
用法与isdir相同。
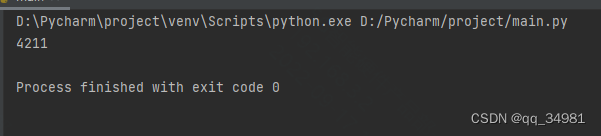
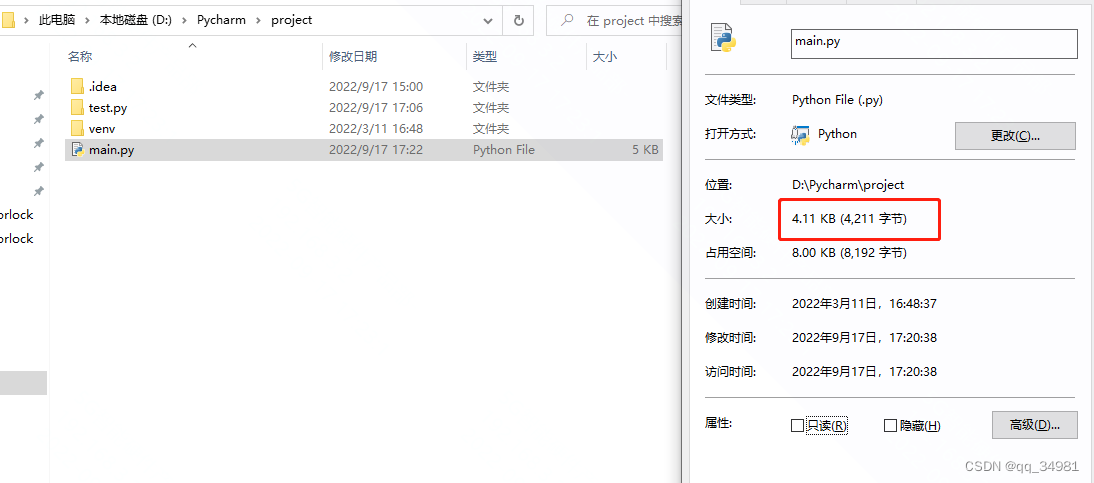
os.path.getsize
函数原型:def getsize(filename: StrOrBytesPath) -> int: ...
该函数用来获取文件的大小,结果是以字节为单位。如果文件不存在,则抛出OSError异常。
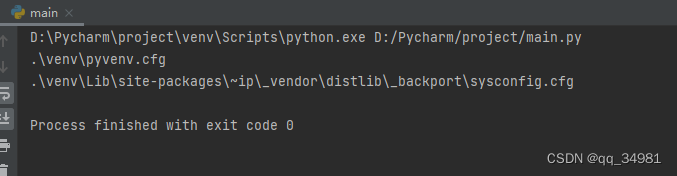
print(os.path.getsize('./main.py'))结果:
os.walk()
函数原型:def walk(top, topdown=True, οnerrοr=None, followlinks=False):
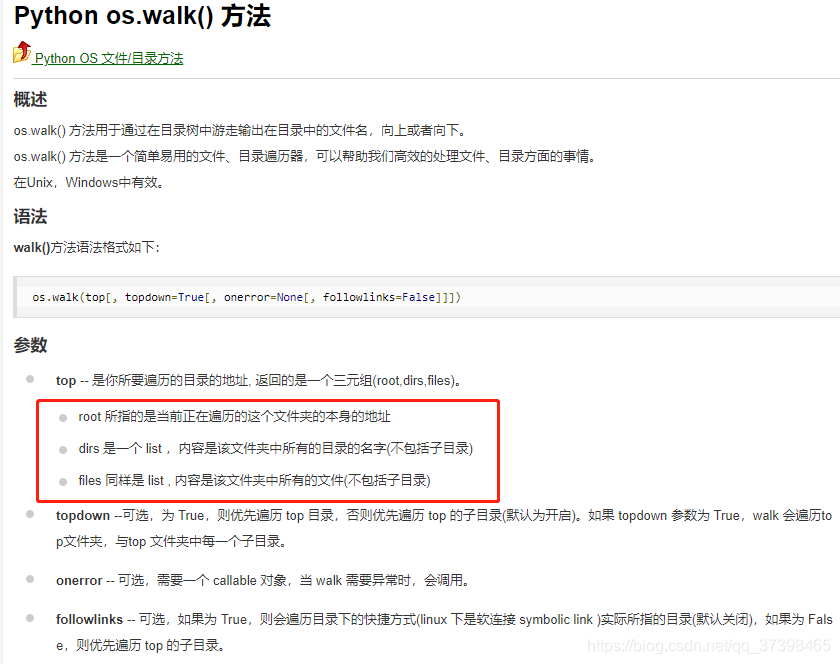
os.walk(path)方法返回的是一个迭代器。迭代器每次会生成一个元组:(root,dirs,files)
生成多少个元组,取决于path路径下有多少个子目录。见如下代码:
for root,dirs,files in os.walk('.'):
print(f"root:{root},dirs:{dirs},files:{files}")结果:
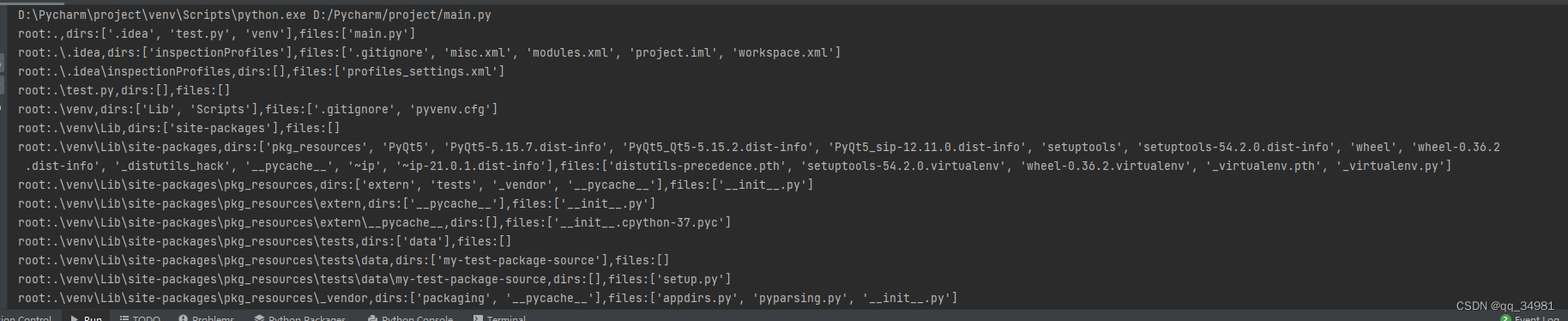
而对于topdown参数来说,默认值是True,如果设置成False,则优先遍历子目录。见如下代码:
for root,dirs,files in os.walk('.',topdown=False):
print(f"root:{root},dirs:{dirs},files:{files}")结果:
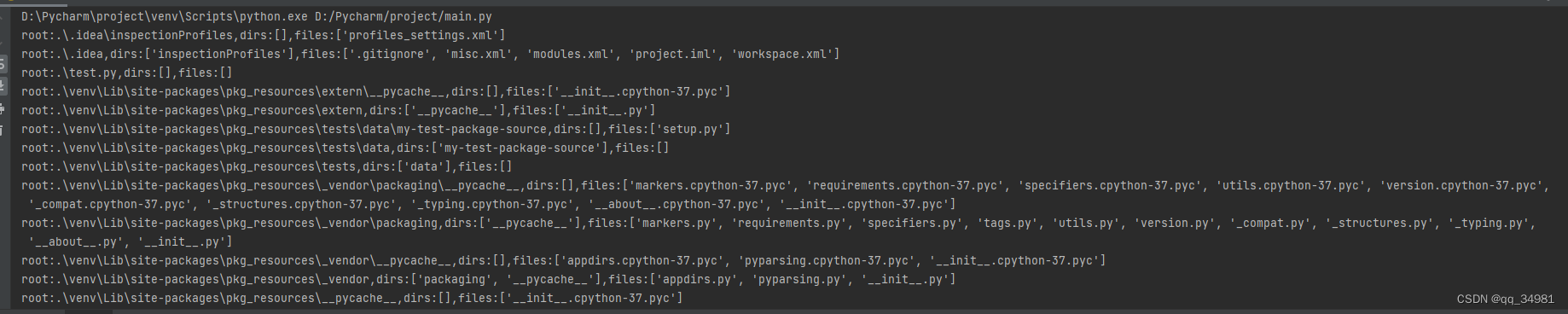
当需要对文件夹里的文件进行遍历,并且寻找到需要的文件时,使用os.walk就相当方便了。例如我们想要找到文件夹中以.cfg结尾的文件,找到后打印出来,就可以通过如下代码实现:
for root,dirs,files in os.walk('.'):
for path in files:
if os.path.splitext(path)[1] == '.cfg':
print(f"root:{root},dirs:{dirs},files:{files}")结果:

如果觉得输出结果这样不好看,可以修改为
for root,dirs,files in os.walk('.'):
for path in files:
if os.path.splitext(path)[1] == '.cfg':
print(os.path.join(root,path))结果:
不使用os.walk遍历文件夹下的所有文件
在不使用os.walk函数的情况下,也可以通过上边的函数进行操作。见下方代码:
def traverse_file(path):
t_path = os.listdir(path) #获取当前路径
for file in t_path: #遍历
if os.path.isdir(path + "\\" + file): #是文件夹
print(f"if folder[{path}:{file}]")
new_path = os.path.join(path,file) #添加路径
traverse_file(new_path) #递归查询
elif os.path.isfile(path + "\\" + file): #是文件
print(f"if file[{path}:{file}]")
else:
print(f"unknow {path}:{file}")
if __name__ == '__main__':
traverse_file('.')结果:
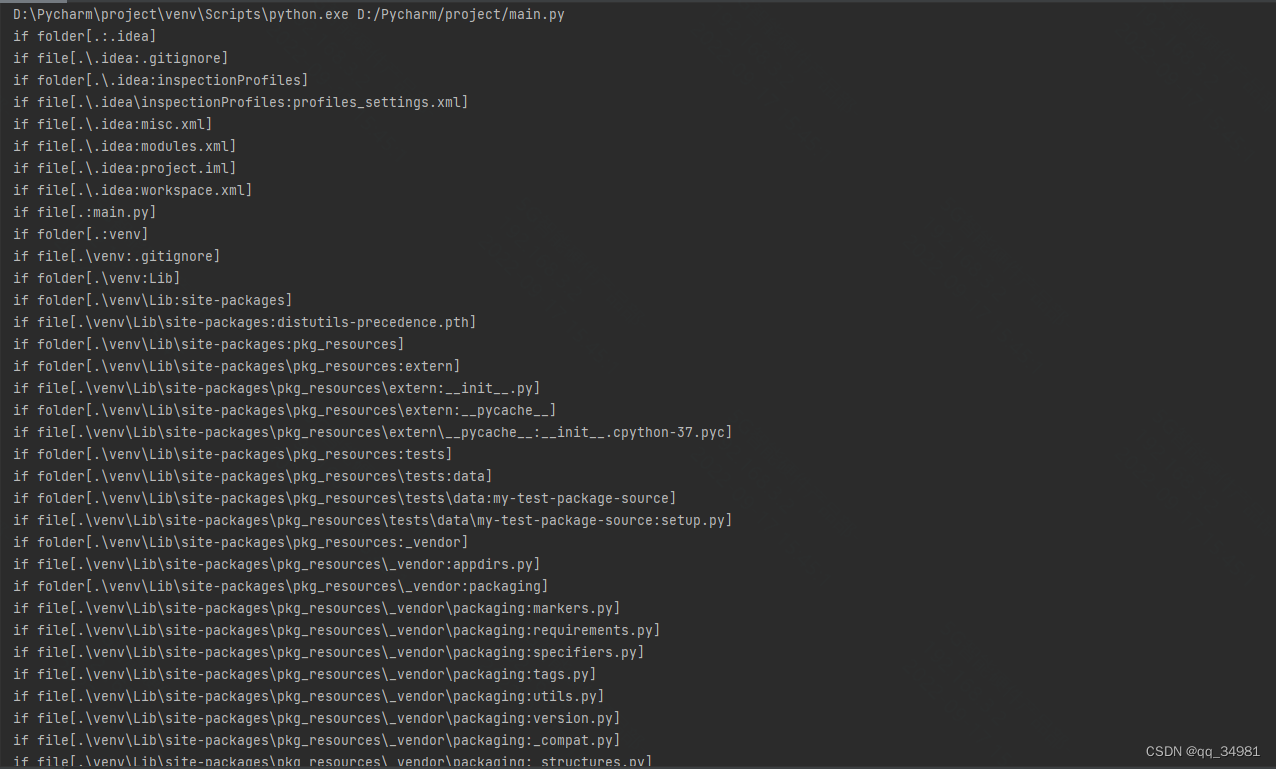
这里使用递归的方式,当检测到是文件夹的时候,就添加路径后,继续递归查询。这里需要注意的是,os.path.isdir()和os.path.isfile()函数,如果传参只传入列表下的名字,在递归函数中,是无法识别的。例如,将代码修改:
def traverse_file(path):
t_path = os.listdir(path) #获取当前路径
for file in t_path: #遍历
if os.path.isdir(file): #是文件夹
print(f"if folder[{path}:{file}]")
new_path = os.path.join(path,file) #添加路径
traverse_file(new_path) #递归查询
elif os.path.isfile(file): #是文件
print(f"if file[{path}:{file}]")
else:
print(f"unknow {path}:{file}")结果:

















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









